Recognition: unknown
Locating acts of mechanistic reasoning in student team conversations with mechanistic machine learning
Pith reviewed 2026-05-08 12:46 UTC · model grok-4.3
The pith
An interpretable machine learning model locates acts of mechanistic reasoning in student team conversations by embedding domain-aligned inductive bias.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Incorporating an inductive bias into a probabilistic model for detecting mechanistic reasoning improves generalization performance on transcripts involving unseen students and a novel discussion context, thereby showing that interpretability can be built directly into the model for this task.
What carries the argument
A probabilistic model that outputs time-varying probabilities of individual students engaging in mechanistic reasoning, steered by an intentionally-designed inductive bias toward domain-aligned probabilistic dynamics.
If this is right
- STEM researchers can use the model to identify high-concentration segments of mechanistic reasoning without exhaustive manual review of all transcripts.
- The time-varying probability outputs enable nuanced analysis of when and how reasoning develops during discussions.
- Practical recommendations follow for education researchers adopting the tool and for machine learning researchers extending the model design.
- The work encourages development of mechanistically interpretable models that remain understandable and controllable for end users in STEM education.
Where Pith is reading between the lines
- Similar inductive-bias techniques could apply to detecting other forms of student reasoning in non-STEM subjects or different group settings.
- Embedding such models in classroom software might enable real-time alerts for instructors monitoring discussion quality.
- Further validation would involve testing the model against human-coded annotations on larger or more diverse conversation datasets.
Load-bearing premise
The observed improvement in generalization on unseen students and novel contexts is due to the inductive bias creating built-in interpretability and domain alignment, rather than other aspects of the model architecture or data labeling.
What would settle it
A direct comparison experiment where models with and without the inductive bias achieve equivalent generalization accuracy on held-out transcripts from new students and contexts would challenge the central claim.
Figures




read the original abstract
STEM education researchers are often interested in identifying moments of students' mechanistic reasoning for deeper analysis, but have limited capacity to search through many team conversation transcripts to find segments with a high concentration of such reasoning. We offer a solution in the form of an interpretable machine learning model that outputs time-varying probabilities that individual students are engaging in acts of mechanistic reasoning, leveraging evidence from their own utterances as well as contributions from the rest of the group. Using the toolkit of intentionally-designed probabilistic models, we introduce a specific inductive bias that steers the probabilistic dynamics toward desired, domain-aligned behavior. Experiments compare trained models with and without the inductive bias components, investigating whether their presence improves the desired model behavior on transcripts involving never-before-seen students and a novel discussion context. Our results show that the inductive bias improves generalization -- supporting the claim that interpretability is built into the model for this task rather than imposed post hoc. We conclude with practical recommendations for STEM education researchers seeking to adopt the tool and for ML researchers aiming to extend the model's design. Overall, we hope this work encourages the development of mechanistically interpretable models that are understandable and controllable for both end users and model designers in STEM education research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents an interpretable probabilistic ML model, built with intentionally-designed components and a domain-aligned inductive bias, that outputs time-varying probabilities of individual students engaging in mechanistic reasoning during team conversations. It reports experiments ablating the inductive bias and claims that its presence improves generalization to unseen students and novel discussion contexts, thereby supporting that interpretability is built into the model rather than imposed post hoc. The work concludes with recommendations for STEM education researchers and ML model designers.
Significance. If the central claim holds after addressing the noted gaps, the model could serve as a practical tool for locating mechanistic reasoning in educational transcripts, reducing manual search effort for STEM education researchers while providing controllable, domain-aligned outputs. The emphasis on intentionally-designed probabilistic models with explicit inductive bias is a strength that could encourage similar mechanistically interpretable approaches in education research.
major comments (2)
- [Abstract] Abstract: The central claim that 'the inductive bias improves generalization -- supporting the claim that interpretability is built into the model for this task rather than imposed post hoc' is not supported by the reported experiments. The ablation compares versions of the proposed model with and without the bias components but provides no baseline using a standard (non-domain-aligned) model followed by separate post-hoc interpretability techniques, so any performance gain cannot be attributed specifically to built-in interpretability versus other effects such as regularization or task-specific dynamics.
- [Abstract] Abstract and experiments section: No details are provided on the labeling protocol for acts of mechanistic reasoning, the precise evaluation metrics (e.g., precision-recall, AUC, or segment-level F1), statistical significance testing, or controls for confounds such as inter-rater reliability in labeling, transcript length variations, or differences in model capacity. These omissions leave the reported generalization improvement only partially supported and undermine assessment of the inductive bias's contribution.
minor comments (1)
- [Abstract] The abstract refers to 'practical recommendations' for adoption and extension but does not preview their content, which would help readers assess the paper's applied value.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We address each major comment below and have revised the manuscript to moderate claims, add missing methodological details, and improve the overall support for our results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'the inductive bias improves generalization -- supporting the claim that interpretability is built into the model for this task rather than imposed post hoc' is not supported by the reported experiments. The ablation compares versions of the proposed model with and without the bias components but provides no baseline using a standard (non-domain-aligned) model followed by separate post-hoc interpretability techniques, so any performance gain cannot be attributed specifically to built-in interpretability versus other effects such as regularization or task-specific dynamics.
Authors: We agree that the reported ablation does not include a direct comparison to post-hoc interpretability techniques applied to a standard non-domain-aligned model, and therefore the results cannot isolate the contribution of built-in interpretability from other possible factors such as regularization. The experiments do show that including the domain-aligned inductive bias improves generalization to unseen students and novel contexts. In the revised manuscript we have updated the abstract to remove the specific claim that the results support interpretability being 'built into the model rather than imposed post hoc.' We now state only that the inductive bias improves generalization while enabling domain-aligned, controllable outputs. We have also added a limitations paragraph in the discussion that explicitly notes the absence of a post-hoc baseline comparison and suggests this as a direction for future work. revision: yes
-
Referee: [Abstract] Abstract and experiments section: No details are provided on the labeling protocol for acts of mechanistic reasoning, the precise evaluation metrics (e.g., precision-recall, AUC, or segment-level F1), statistical significance testing, or controls for confounds such as inter-rater reliability in labeling, transcript length variations, or differences in model capacity. These omissions leave the reported generalization improvement only partially supported and undermine assessment of the inductive bias's contribution.
Authors: We acknowledge that these methodological details were insufficiently reported. In the revised manuscript we have substantially expanded the methods and experiments sections to include: (1) a full description of the labeling protocol, including the operational definition of mechanistic reasoning acts, the annotation guidelines, and the number of annotators; (2) the exact evaluation metrics employed (segment-level F1, AUC-ROC, and precision-recall curves); (3) results of statistical significance testing between model variants; and (4) explicit controls and reporting for inter-rater reliability, normalization for transcript length, and verification that model capacities were comparable across ablations. These additions allow readers to better evaluate the generalization improvements and the role of the inductive bias. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper defines an intentionally-designed probabilistic model with an added inductive bias for domain alignment, then reports an ablation comparing versions with and without that bias on held-out transcripts from unseen students and novel contexts. Generalization performance is measured via independent evaluation on external data rather than being defined in terms of the fitted parameters or the bias itself. No step reduces by construction to its inputs, no self-citation is invoked as the sole justification for a uniqueness claim, and the central empirical result (improved generalization) is not equivalent to the model definition. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Vinck and ´E
D. Vinck and ´E. Blanco,Everyday Engineering: An Ethnography of Design and Innovation(The MIT Press, Cambridge, MA, 2003)
2003
-
[2]
D. A. Dickerson, S. Masta, M. W. Ohland, and A. L. Pawley, Is carla grumpy? analysis of peer evaluations to explore microaggressions and other marginalizing behav- iors in engineering student teams, Journal of Engineering Education113, 603 (2024)
2024
-
[3]
R. E. Scherr and D. Hammer, Student behavior and epis- temological framing: Examples from collaborative active- learning activities in physics, Cognition and Instruction 27, 147 (2009)
2009
-
[4]
M. D. Koretsky, E. J. Nefcy, S. B. Nolen, and A. B. Champagne, Connected epistemic practices in laboratory-based engineering design projects for large- course instruction, Science Education107, 510 (2023). 16
2023
-
[5]
Machamer, L
P. Machamer, L. Darden, and C. F. Craver, Thinking about mechanisms, Philosophy of Science67, 1 (2000)
2000
-
[6]
van Eck, Mechanisms and engineering science, inThe Routledge Handbook of Mechanisms and Mechanical Phi- losophy, edited by S
D. van Eck, Mechanisms and engineering science, inThe Routledge Handbook of Mechanisms and Mechanical Phi- losophy, edited by S. Glennan and P. Illari (Routledge,
-
[7]
de Andrade, Y
V. de Andrade, Y. Shwartz, S. Freire, and M. Baptista, Students’ mechanistic reasoning in practice: Enabling functions of drawing, gestures and talk, Science Educa- tion106, 199 (2022)
2022
-
[8]
R. S. Russ, R. E. Scherr, D. Hammer, and J. Mikeska, Recognizing mechanistic reasoning in student scientific inquiry: A framework for discourse analysis developed from philosophy of science, Science Education92, 499 (2008)
2008
-
[9]
T. O. B. Odden and R. S. Russ, Sensemaking epistemic game: A model of student sensemaking processes in in- troductory physics, Phys. Rev. Phys. Educ. Res.14, 020122 (2018)
2018
-
[10]
Y. Long, H. Luo, and Y. Zhang, Evaluating large lan- guage models in analysing classroom dialogue., npj Sci. Learn. (2024)
2024
-
[11]
Z. He, S. Naphade, and T.-H. K. Huang, Prompting in the dark: Assessing human performance in prompt en- gineering for data labeling when gold labels are absent, inProceedings of the 2025 CHI Conference on Human Factors in Computing Systems, CHI ’25 (Association for Computing Machinery, New York, NY, USA, 2025)
2025
-
[12]
Subramonyam, R
H. Subramonyam, R. Pea, C. Pondoc, M. Agrawala, and C. Seifert, Bridging the gulf of envisioning: Cognitive challenges in prompt based interactions with llms, inPro- ceedings of the 2024 CHI Conference on Human Factors in Computing Systems, CHI ’24 (Association for Com- puting Machinery, New York, NY, USA, 2024)
2024
-
[13]
C. Rudin, Stop explaining black box machine learn- ing models for high stakes decisions and use inter- pretable models instead, Nature Machine Intelligence1, 206 (2019), received 30 Dec 2018; accepted 26 Mar 2019; published 13 May 2019
2019
-
[14]
Zschech, S
P. Zschech, S. Weinzierl, and M. Kraus, Inherently in- terpretable machine learning: A contrasting paradigm to post-hoc explainable ai, Business & Information Systems Engineering , 1 (2025), received 17 Dec 2024; accepted 24 Jul 2025; published 15 Sep 2025
2025
-
[15]
Ghahramani and G
Z. Ghahramani and G. E. Hinton, Variational learning for switching state-space models, Neural computation12 (2000)
2000
-
[16]
Farnoosh, B
A. Farnoosh, B. Azari, and S. Ostadabbas, Deep switch- ing auto-regressive factorization: Application to time se- ries forecasting, Proceedings of the AAAI Conference on Artificial Intelligence35, 7394 (2021)
2021
-
[17]
M. T. Wojnowicz, K. Gili, P. Rath, E. Miller, J. Miller, C. Hancock, M. O’Donovan, S. Elkin-Frankston, T. T. Bruny´ e, and M. C. Hughes, Discovering group dynam- ics in coordinated time series via hierarchical recurrent switching-state models (2024)
2024
-
[18]
R. W. Bachtiar, R. F. G. Meulenbroeks, and W. R. van Joolingen, Stimulating mechanistic reasoning in physics using student-constructed stop-motion animations, Jour- nal of Science Education and Technology30, 777 (2021), published 28 Apr 2021; issue date Dec 2021
2021
-
[19]
M. H. Wilkerson-Jerde, B. E. Gravel, and C. A. Macran- der, Exploring shifts in middle school learners’ modeling activity while generating drawings, animations, and com- putational simulations of molecular diffusion, Journal of Science Education and Technology24, 396 (2015)
2015
-
[20]
Wendell, M
K. Wendell, M. S. Top¸ cu, and C. Andrews, Mechanistic reasoning: How cause-and-effect thinking supports engi- neering design problem-solving, Science and Children62, 44 (2025)
2025
-
[21]
Melsky, I
K. Melsky, I. Stuopis, K. Wendell, and E. C. Kemmerling, Personalized problems and student discourse in thermal fluid transport courses, International Journal of Mechan- ical Engineering Education52, 457 (2024)
2024
-
[22]
Devlin, M.-W
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, Bert: Pre-training of deep bidirectional transformers for lan- guage understanding (2019)
2019
-
[23]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozi` ere, N. Goyal, E. Ham- bro, F. Azhar, A. Rodriguez, A. Joulin, E. Grave, and G. Lample, Llama: Open and efficient foundation lan- guage models, arXiv preprint arXiv:2302.13971 (2023)
work page internal anchor Pith review arXiv 2023
-
[24]
A. Q. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. S. Chaplot, D. de las Casas, F. Bressand, G. Lengyel, G. Lample, L. Saulnier, L. R. Lavaud, M.-A. Lachaux, P. Stock, T. L. Scao, T. Lavril, T. Wang, T. Lacroix, and W. E. Sayed, Mistral 7b (2023)
2023
-
[25]
Campbell, K
J. Campbell, K. Ansell, and T. Stelzer, Evaluating ibm’s watson natural language processing artificial intelligence as a short-answer categorization tool for physics educa- tion research, Phys. Rev. Phys. Educ. Res.20, 010116 (2024)
2024
-
[26]
Wilson, B
J. Wilson, B. Pollard, J. M. Aiken, M. D. Caballero, and H. J. Lewandowski, Classification of open-ended re- sponses to a research-based assessment using natural language processing, Phys. Rev. Phys. Educ. Res.18, 010141 (2022)
2022
-
[27]
D. Wang, D. Shan, Y. Zheng, K. Guo, G. Chen, and Y. Lu, Can chatgpt detect student talk moves in class- room discourse? a preliminary comparison with bert, in Proceedings of the 16th International Conference on Ed- ucational Data Mining, edited by M. Feng, T. K ˜A¤ser, and P. Talukdar (International Educational Data Mining Society, Bengaluru, India, 2023)...
2023
-
[28]
R. K. Fussell, M. Flynn, A. Damle, M. F. J. Fox, and N. G. Holmes, Comparing large language models for su- pervised analysis of students’ lab notes, Phys. Rev. Phys. Educ. Res.21, 010128 (2025)
2025
- [29]
-
[30]
Ullmann, Automated analysis of reflection in writing: Validating machine learning approaches, Int J Artif Intell Educ29, 217–257 (2019)
T. Ullmann, Automated analysis of reflection in writing: Validating machine learning approaches, Int J Artif Intell Educ29, 217–257 (2019)
2019
-
[31]
H. Auby, N. Shivagunde, V. Deshpande, A. Rumshisky, and M. D. Koretsky, Analysis of student under- standing in short-answer explanations to concept questions using a human-centered ai approach, Jour- nal of Engineering Education114, e70032 (2025), https://onlinelibrary.wiley.com/doi/pdf/10.1002/jee.70032
-
[32]
Zamfirescu-Pereira, R
J. Zamfirescu-Pereira, R. Y. Wong, B. Hartmann, and Q. Yang, Why johnny can’t prompt: How non-ai ex- perts try (and fail) to design llm prompts (Association for Computing Machinery, New York, NY, USA, 2023)
2023
-
[33]
Jiang, F
Z. Jiang, F. F. Xu, J. Araki, and G. Neubig, How Can We Know What Language Models Know?, Transactions of the Association for Computational Linguistics8, 423 17 (2020)
2020
-
[34]
J. Liu, D. Shen, Y. Zhang, B. Dolan, L. Carin, and W. Chen, What Makes Good In-Context Examples for GPT-3?, inProceedings of Deep Learning Inside Out (DeeLIO 2022): The 3rd Workshop on Knowledge Ex- traction and Integration for Deep Learning Architectures, edited by E. Agirre, M. Apidianaki, and I. Vuli´ c (Associ- ation for Computational Linguistics, Dub...
2022
-
[35]
E. M. Bender, T. Gebru, A. McMillan-Major, and S. Shmitchell, On the dangers of stochastic parrots: Can language models be too big?, inProceedings of the 2021 ACM Conference on Fairness, Accountability, and Trans- parency, FAccT ’21 (Association for Computing Machin- ery, New York, NY, USA, 2021) p. 610–623
2021
-
[36]
F. M. Watts, A. J. Dood, and G. V. Shultz, Developing machine learning models for automated analysis of or- ganic chemistry students’ written descriptions of organic reaction mechanisms, inStudent Reasoning in Organic Chemistry(The Royal Society of Chemistry, 2022)
2022
-
[37]
Moreau-Pernet, Y
B. Moreau-Pernet, Y. Tian, S. Sawaya, P. Foltz, J. Cao, B. Milne, and T. Christie, Classifying tutor discursive moves at scale in mathematics classrooms with large language models, inProceedings of the Eleventh ACM Conference on Learning @ Scale (L@S ’24)(Association for Computing Machinery, Atlanta, GA, USA, 2024) pp. 361–365
2024
-
[38]
Schechter, H
V. Schechter, H. Dua, S. Dua, B. Zhang, D. Salz, R. Mullins, S. R. Panyam, S. Smoot, I. Naim, J. Zou, F. Chen, D. Cer, A. Lisak, M. Choi, L. Gonzalez, O. San- seviero, G. Cameron, I. Ballantyne, K. Black, K. Chen, W. Wang, Z. Li, G. Martins, J. Lee, M. Sherwood, J. Ji, R. Wu, J. Zheng, J. Singh, A. Sharma, D. Sreepat, A. Jain, A. Elarabawy, A. Co, A. Doum...
2025
-
[39]
Kusupati, G
A. Kusupati, G. Bhatt, A. Rege, M. Wallingford, A. Sinha, V. Ramanujan, W. Howard-Snyder, K. Chen, S. Kakade, P. Jain, and A. Farhadi, Matryoshka represen- tation learning, inAdvances in Neural Information Pro- cessing Systems (NeurIPS), Vol. 35 (2022) pp. 36005– 36018
2022
-
[40]
T. O. B. Odden and R. S. Russ, Defining sensemaking: Bringing clarity to a fragmented theoretical construct, Science Education103, 187 (2019)
2019
-
[41]
M. J. Beal,Variational algorithms for approximate Bayesian inference(University of London, University College London (United Kingdom), 2003)
2003
-
[42]
D. M. Blei, A. Kucukelbir, and J. D. McAuliffe, Varia- tional inference: A review for statisticians, Journal of the American Statistical Association112, 859–877 (2017)
2017
- [43]
-
[44]
D. J. C. MacKay, Bayesian interpolation, Neural Compu- tation4, 415 (1992), https://direct.mit.edu/neco/article- pdf/4/3/415/812340/neco.1992.4.3.415.pdf
1992
-
[45]
Ac- cessed: 2026-04-03
tufts-ml, Mech4mech (2026), gitHub repository. Ac- cessed: 2026-04-03
2026
-
[46]
it’s scary but it’s also exciting
L. Z. J. Jennifer Radoff and D. Hammer, “it’s scary but it’s also exciting”: Evidence of meta-affective learning in science, Cognition and Instruction37, 73 (2019)
2019
-
[47]
Bergeron, D
K. Bergeron, D. Pamuk Turner, and D. Hammer, Rea- soning through uncertainty: expert chemists’ analogical thinking on a novel problem, Chemistry Education Re- search and Practice26, 1031 (2025)
2025
-
[48]
O. Weller, K. Ricci, M. Marone, A. Chaffin, D. Lawrie, and B. V. Durme, Seq vs seq: An open suite of paired encoders and decoders (2025), arXiv:2507.11412 [cs.CL]
-
[49]
L. R. Rabiner, A Tutorial on Hidden Markov Models and Selected Applications in Speech Recognition, Proc. of the IEEE77, 257 (1989)
1989
-
[50]
[Not mentioned by the students]
F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cour- napeau, M. Brucher, M. Perrot, and E. Duchesnay, Scikit-learn: Machine learning in Python, Journal of Ma- chine Learning Research12, 2825 (2011). A. Thermo-Fluid mechanics problems & codes Below, ...
2011
-
[51]
Alright. Also I’m concerned. Is this a pure sub- stance? Do we have to worry about that? The fact that it’s air and water mixed together?
Classifier selection details. We considered various pre-trained and need-to-train clas- sifiers, and selected based on task alignment and the amount of computational resource requirements for de- ployment (e.g. the number of parameters stored and used during inference). Task alignment refers to the extent to which the pre-training objective is congruent w...
-
[52]
Training data selection. We first selected 2 problems (2A and 2B) as a test set for the adapted-HSRDM, which left 8 problems for train- ing the supervised feedback mechanism classifier and the CAVI training. As we did not want our feedback mecha- nism to be trained on the exact same data as the CAVI training, we used the smallest sub-set believed possible...
-
[53]
Method details. Method justification.To avoid needing a validation set, we utilized a recent Bayesian variational inference approach put forth in [43] for model selection, where one can minimize a negative data-emphasized ELBO (DE- ELBO) as a method of implicitly choosing the model with the optimal prior parameters over neural network parameters (i.e. the...
-
[54]
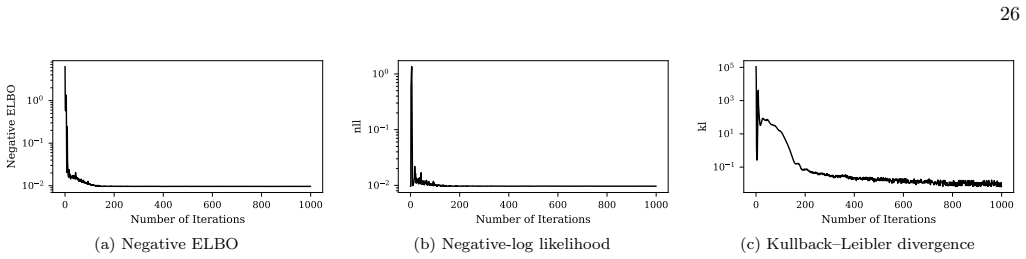
Training Algorithm Overview the HSRDM is trained in a fully unsupervised fashion via Bayesian variational inference techniques [41, 42]. One can utilize a structured distributionq ϕi(zi,j 0:T , si 0:T ) pa- rameterized byϕ i that can be trained to approximate 26 0 200 400 600 800 1000 Number of Iterations 10 2 10 1 100 Negative ELBO (a) Negative ELBO 0 20...
-
[55]
ELBO derivation Starting from our joint distribution over our observed data{x i,1:J 0:T }N i=1 and our latent variables{z i,1:J 0:T }N i=1, {s0:T }N i=1, given our parametersθ, we derive the Evi- dence Lower Bound (ELBO) for unsupervised training of the model. First, we factorize the joint into the following form: NY i=1 p(xi,1:J 0:T , zi,1:J 0:T , si 0:T...
-
[56]
This allows us to take derivatives of the ELBO with respect to qϕi1 (zi,1:J 0:T ) andq ϕi2 (si 0:T ) separately
CAVI update rule derivations To utilize the CAVI updates proposed in [42], we make amean field approximation, meaning that qϕi(zi,1:J 0:T , si 0:T ) =q ϕi1 (zi,1:J 0:T )qϕi2 (si 0:T ). This allows us to take derivatives of the ELBO with respect to qϕi1 (zi,1:J 0:T ) andq ϕi2 (si 0:T ) separately. First, we disentan- gle these two posterior terms in the EL...
-
[57]
CAVI update rule algorithms VEZ and VES forward-backwards algorithm.Re- call that we have some optimalq ∗ ϕi functions that we can compute directly. q∗ ϕi1 (zi,1:J 0:T )∝expE qϕi2 [logp(x i,1:J 0:T , zi,1:J 0:T , si 0:T |θ)] (F21) q∗ ϕi2 (si 0:T )∝expE qϕi1 [logp(x i,1:J 0:T , zi,1:J 0:T , si 0:T |θ)] (F22) To compute each function, we hold the other dist...
-
[58]
We used the k-means algorithm as implemented in scikit-learn [50] to cluster the EmbeddingGemma vectors intoK=4 groups
K-means initializations We include the adapted-HSRDM training results across different random k-means initializations. We used the k-means algorithm as implemented in scikit-learn [50] to cluster the EmbeddingGemma vectors intoK=4 groups. Then, using only the data assigned to each cluster, we fit an autoregressive linear model over time to estimate theA k...
-
[59]
III E, and compare them to the best-performing k-means model
Model ablation study with training data We report adapted-HSRDM training results across mul- tiple ablations using the informed initialization from Sec. III E, and compare them to the best-performing k-means model. We include the following metrics: H(i) results in Table XXV, H(ii) results in Table XXVI, H(iii) silent to silent results in Table XXVII, and ...
-
[60]
5 for the best seed 17 based on the speaker correlation metric for the k-means initialization
ELBO results We include the ELBO training plot in Fig. 5 for the best seed 17 based on the speaker correlation metric for the k-means initialization. We observe the ELBO increase over the 15 CAVI iterations. 0 2 4 6 8 10 12 14 Iteration 10000 15000 20000 25000 30000 35000ELBO +3.6874e9 ELBO Over Iterations FIG. 5: The ELBO training curve over 15 CAVI iterations
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.