Recognition: unknown
Vista4D: Video Reshooting with 4D Point Clouds
Pith reviewed 2026-05-09 22:04 UTC · model grok-4.3
The pith
Vista4D grounds video reshooting in 4D point clouds to support new camera trajectories while preserving original dynamics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
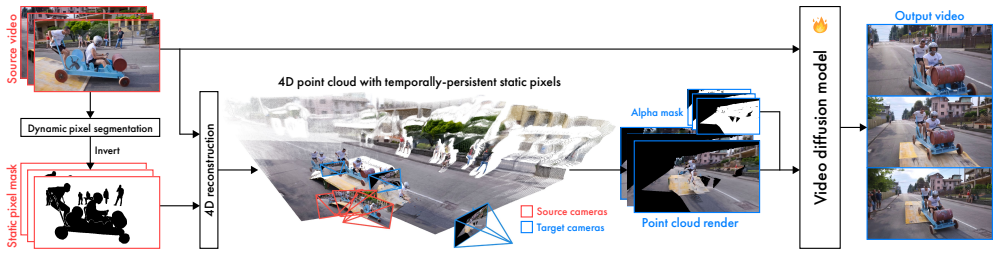
Vista4D builds a 4D point cloud from the input video with static pixel segmentation and 4D reconstruction to preserve seen content and supply precise camera signals, then trains on reconstructed multiview dynamic data so the model stays robust when point cloud artifacts appear at inference time on real videos.
What carries the argument
4D-grounded point cloud representation built from static pixel segmentation and 4D reconstruction, which explicitly preserves content and provides camera control signals.
Load-bearing premise
Training on reconstructed multiview dynamic data supplies enough robustness against point cloud artifacts and depth estimation errors when the method runs on real-world videos with difficult trajectories.
What would settle it
A real video with complex motion and inaccurate depth maps where the output exhibits more 4D inconsistencies or visual artifacts than the state-of-the-art baselines.
Figures

















read the original abstract
We present Vista4D, a robust and flexible video reshooting framework that grounds the input video and target cameras in a 4D point cloud. Specifically, given an input video, our method re-synthesizes the scene with the same dynamics from a different camera trajectory and viewpoint. Existing video reshooting methods often struggle with depth estimation artifacts of real-world dynamic videos, while also failing to preserve content appearance and failing to maintain precise camera control for challenging new trajectories. We build a 4D-grounded point cloud representation with static pixel segmentation and 4D reconstruction to explicitly preserve seen content and provide rich camera signals, and we train with reconstructed multiview dynamic data for robustness against point cloud artifacts during real-world inference. Our results demonstrate improved 4D consistency, camera control, and visual quality compared to state-of-the-art baselines under a variety of videos and camera paths. Moreover, our method generalizes to real-world applications such as dynamic scene expansion and 4D scene recomposition. See our project page for results, code, and models: https://eyeline-labs.github.io/Vista4D
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Vista4D, a video reshooting framework that constructs a 4D point cloud representation from an input video using static pixel segmentation and 4D reconstruction. This representation grounds the scene dynamics and provides camera signals, allowing re-synthesis from new trajectories. The method trains on reconstructed multiview dynamic data to gain robustness against point cloud artifacts at inference time on real monocular videos. It claims superior 4D consistency, camera control, and visual quality over baselines across varied videos and paths, plus generalization to applications such as dynamic scene expansion and 4D scene recomposition.
Significance. If the robustness and generalization claims hold, the work would advance practical 4D video editing and novel-view synthesis for dynamic real-world scenes by explicitly addressing depth artifacts and camera control failures that plague prior methods. The training strategy on multiview reconstructions to mitigate monocular failure modes represents a concrete engineering contribution that could influence downstream applications in film, VR, and content creation.
major comments (2)
- [Abstract] Abstract and results: The central generalization claim—that training exclusively on reconstructed multiview dynamic data confers robustness to the artifact distribution arising from monocular depth estimation on real-world videos with challenging trajectories—lacks supporting quantitative evidence such as ablations on noise level, trajectory difficulty, or failure-case breakdowns. This assumption is load-bearing for the headline result of improved 4D consistency on real inputs.
- [Abstract] Abstract: The assertions of 'improved 4D consistency, camera control, and visual quality' and generalization to real-world applications are presented without reference to specific metrics, error bars, statistical controls, or baseline comparisons, preventing verification of the data-to-claim link.
minor comments (1)
- [Abstract] The project page link is referenced for results, code, and models; ensure the manuscript itself contains sufficient self-contained quantitative tables or figures so that claims can be assessed without external resources.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review. We address each major comment below and have revised the manuscript to strengthen the presentation of our claims and supporting evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract and results: The central generalization claim—that training exclusively on reconstructed multiview dynamic data confers robustness to the artifact distribution arising from monocular depth estimation on real-world videos with challenging trajectories—lacks supporting quantitative evidence such as ablations on noise level, trajectory difficulty, or failure-case breakdowns. This assumption is load-bearing for the headline result of improved 4D consistency on real inputs.
Authors: We agree that the abstract would benefit from more direct quantitative support for the generalization claim. The manuscript demonstrates robustness via comprehensive evaluations on real monocular videos with varied trajectories and point cloud artifacts, but we acknowledge the value of targeted ablations. We have added new quantitative ablations on point cloud noise levels, trajectory difficulty variations, and failure-case breakdowns in the revised manuscript to directly substantiate the contribution of multiview training. revision: yes
-
Referee: [Abstract] Abstract: The assertions of 'improved 4D consistency, camera control, and visual quality' and generalization to real-world applications are presented without reference to specific metrics, error bars, statistical controls, or baseline comparisons, preventing verification of the data-to-claim link.
Authors: We concur that the abstract's high-level claims would be strengthened by explicit links to the underlying evidence. The detailed metrics, error bars, statistical controls, and baseline comparisons are provided in the Experiments section. We have revised the abstract to reference these specific results and comparisons more directly, improving the connection between claims and data. revision: yes
Circularity Check
No circularity: empirical pipeline with independent training and evaluation claims
full rationale
The paper describes Vista4D as an empirical framework that builds a 4D point cloud from input video via static segmentation and 4D reconstruction, then trains a model on reconstructed multiview dynamic data to achieve robustness at inference time on real videos. No equations, derivations, or parameter-fitting steps are presented that reduce the claimed 4D consistency, camera control, or generalization performance to quantities defined by the authors' own fitted values or self-citations. The central claims rest on the training distribution providing robustness, which is an empirical assumption rather than a self-referential reduction; the method is presented as a practical pipeline whose success is measured against external baselines and real-world applications, not by construction from its inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Video generation models as world simulators
Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Li Jing, David Schnurr, Joe Taylor, Troy Luhman, Eric Luhman, Clarence Ng, Ricky Wang, and Aditya Ramesh. Video generation models as world simulators. 2024. 2
2024
-
[2]
Wan: Open and advanced large-scale video gen- erative models, 2025
Team Wan. Wan: Open and advanced large-scale video gen- erative models, 2025. 4, 13, 15, 17, 20
2025
-
[3]
Video models are zero-shot learners and reasoners, 2025
Thadd¨aus Wiedemer, Yuxuan Li, Paul Vicol, Shixiang Shane Gu, Nick Matarese, Kevin Swersky, Been Kim, Priyank Jaini, and Robert Geirhos. Video models are zero-shot learners and reasoners, 2025
2025
-
[4]
Hunyuanvideo: A systematic framework for large video generative models, 2025
Weijie Kong et al. Hunyuanvideo: A systematic framework for large video generative models, 2025
2025
-
[5]
World simulation with video foundation models for physical ai, 2025
NVIDIA. World simulation with video foundation models for physical ai, 2025
2025
-
[6]
Mochi 1, 2024
Genmo Team. Mochi 1, 2024. 2
2024
-
[7]
Trajec- toryCrafter: Redirecting camera trajectory for monocular videos via diffusion models
Mark Yu, Wenbo Hu, Jinbo Xing, and Ying Shan. Trajec- toryCrafter: Redirecting camera trajectory for monocular videos via diffusion models. InICCV, 2025. 2, 3, 4, 5, 6, 13, 14, 15, 18, 22, 23
2025
-
[8]
GEN3C: 3d-informed world-consistent video generation with precise camera con- trol
Xuanchi Ren, Tianchang Shen, Jiahui Huang, Huan Ling, Yifan Lu, Merlin Nimier-David, Thomas M¨uller, Alexander Keller, Sanja Fidler, and Jun Gao. GEN3C: 3d-informed world-consistent video generation with precise camera con- trol. InCVPR, 2025. 2, 4, 5, 6, 13, 14, 15
2025
-
[9]
EX-4D: Extreme viewpoint 4d video synthesis via depth watertight mesh, 2025
Tao Hu, Haoyang Peng, Xiao Liu, and Yuewen Ma. EX-4D: Extreme viewpoint 4d video synthesis via depth watertight mesh, 2025. 2, 4, 5, 6, 13, 14, 15
2025
-
[10]
ReCamMaster: Camera-controlled generative rendering from a single video
Jianhong Bai, Menghan Xia, Xiao Fu, Xintao Wang, Lianrui Mu, Jinwen Cao, Zuozhu Liu, Haoji Hu, Xiang Bai, Pengfei Wan, et al. ReCamMaster: Camera-controlled generative rendering from a single video. InICCV, 2025. 3, 4, 5, 6, 13, 14, 15, 17, 21
2025
-
[11]
Stream3r: Scalable sequential 3d reconstruction with causal transformer, 2025
Yushi Lan, Yihang Luo, Fangzhou Hong, Shangchen Zhou, Honghua Chen, Zhaoyang Lyu, Shuai Yang, Bo Dai, Chen Change Loy, and Xingang Pan. Stream3r: Scalable sequential 3d reconstruction with causal transformer, 2025. 3, 5, 13, 14
2025
-
[12]
Reangle-a- video: 4d video generation as video-to-video translation
Hyeonho Jeong, Suhyeon Lee, and Jong Chul Ye. Reangle-a- video: 4d video generation as video-to-video translation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 11164–11175, October 2025. 2
2025
-
[13]
NVS- solver: Video diffusion model as zero-shot novel view synthe- sizer
Meng YOU, Zhiyu Zhu, Hui LIU, and Junhui Hou. NVS- solver: Video diffusion model as zero-shot novel view synthe- sizer. InICLR, 2025
2025
-
[14]
Wristworld: Generating wrist-views via 4d world models for robotic manipulation, 2025
Zezhong Qian, Xiaowei Chi, Yuming Li, Shizun Wang, Zhiyuan Qin, Xiaozhu Ju, Sirui Han, and Shanghang Zhang. Wristworld: Generating wrist-views via 4d world models for robotic manipulation, 2025. 2
2025
-
[15]
Video depth anything: Consistent depth estimation for super-long videos
Sili Chen, Hengkai Guo, Shengnan Zhu, Feihu Zhang, Zilong Huang, Jiashi Feng, and Bingyi Kang. Video depth anything: Consistent depth estimation for super-long videos. InCVPR, pages 22831–22840, June 2025. 2, 3
2025
-
[16]
Depthcrafter: Generating consistent long depth sequences for open-world videos
Wenbo Hu, Xiangjun Gao, Xiaoyu Li, Sijie Zhao, Xiaodong Cun, Yong Zhang, Long Quan, and Ying Shan. Depthcrafter: Generating consistent long depth sequences for open-world videos. InCVPR, pages 2005–2015, June 2025
2005
-
[17]
Geometrycrafter: Consistent geometry estimation for open-world videos with diffusion priors
Tian-Xing Xu, Xiangjun Gao, Wenbo Hu, Xiaoyu Li, Song- Hai Zhang, and Ying Shan. Geometrycrafter: Consistent geometry estimation for open-world videos with diffusion priors. InICCV, pages 6632–6644, October 2025. 2, 3
2025
-
[18]
invs : Repurposing diffusion inpainters for novel view synthesis
Yash Kant, Aliaksandr Siarohin, Michael Vasilkovsky, Riza Alp Guler, Jian Ren, Sergey Tulyakov, and Igor Gilitschenski. invs : Repurposing diffusion inpainters for novel view synthesis. InSIGGRAPH Asia, 2023. 2
2023
-
[19]
Multidiff: Consistent novel view synthesis from a single image
Norman M ¨uller, Katja Schwarz, Barbara R ¨ossle, Lorenzo Porzi, Samuel Rota Bul `o, Matthias Nießner, and Peter 9 Kontschieder. Multidiff: Consistent novel view synthesis from a single image. InCVPR, pages 10258–10268, June
-
[20]
Trajectory attention for fine-grained video motion control
Zeqi Xiao, Wenqi Ouyang, Yifan Zhou, Shuai Yang, Lei Yang, Jianlou Si, and Xingang Pan. Trajectory attention for fine-grained video motion control. InICLR, 2025. 2
2025
-
[21]
Generative camera dolly: Extreme monocular dynamic novel view synthesis.ECCV, 2024
Basile Van Hoorick, Rundi Wu, Ege Ozguroglu, Kyle Sar- gent, Ruoshi Liu, Pavel Tokmakov, Achal Dave, Changxi Zheng, and Carl V ondrick. Generative camera dolly: Extreme monocular dynamic novel view synthesis.ECCV, 2024. 3
2024
-
[22]
CamCloneMaster: Enabling reference-based camera control for video generation
Yawen Luo, Jianhong Bai, Xiaoyu Shi, Menghan Xia, Xintao Wang, Pengfei Wan, Di Zhang, Kun Gai, and Tianfan Xue. CamCloneMaster: Enabling reference-based camera control for video generation. InSIGGRAPH Asia, 2025. 3, 4, 5, 6, 13, 14, 15
2025
-
[23]
Jensen (Jinghao) Zhou, Hang Gao, Vikram V oleti, Aaryaman Vasishta, Chun-Han Yao, Mark Boss, Philip Torr, Christian Rupprecht, and Varun Jampani. Stable virtual camera: Gen- erative view synthesis with diffusion models.arXiv preprint arXiv:2503.14489, 2025. 3
-
[24]
Spad: Spatially aware multi-view diffusers
Yash Kant, Aliaksandr Siarohin, Ziyi Wu, Michael Vasilkovsky, Guocheng Qian, Jian Ren, Riza Alp Guler, Bernard Ghanem, Sergey Tulyakov, and Igor Gilitschenski. Spad: Spatially aware multi-view diffusers. InCVPR, 2024
2024
-
[25]
Chen Liu and et al. Zero-1-to-3: Zero-shot novel view syn- thesis from a single image.arXiv:2303.11328, 2023
-
[26]
MVDream: Multi-view diffusion for 3D generation
Yichun Shi, Peng Wang, Jianglong Ye, Long Mai, Kejie Li, and Xiao Yang. MVDream: Multi-view diffusion for 3D generation. InProc. ICLR, 2024
2024
-
[27]
Vikram V oleti, Chun-Han Yao, Mark Boss, Adam Letts, David Pankratz, Dmitry Tochilkin, Christian Laforte, Robin Rombach, and Varun Jampani. SV3D: Novel multi-view syn- thesis and 3D generation from a single image using latent video diffusion.arXiv preprint arXiv:2403.12008, 2024. 3
-
[28]
Cameractrl ii: Dynamic scene exploration via camera-controlled video diffusion models, 2025
Hao He, Ceyuan Yang, Shanchuan Lin, Yinghao Xu, Meng Wei, Liangke Gui, Qi Zhao, Gordon Wetzstein, Lu Jiang, and Hongsheng Li. Cameractrl ii: Dynamic scene exploration via camera-controlled video diffusion models, 2025. 3
2025
-
[29]
Vd3d: Taming large video diffusion transformers for 3d camera control.Proc
Sherwin Bahmani, Ivan Skorokhodov, Aliaksandr Siarohin, Willi Menapace, Guocheng Qian, Michael Vasilkovsky, Hsin- Ying Lee, Chaoyang Wang, Jiaxu Zou, Andrea Tagliasacchi, et al. Vd3d: Taming large video diffusion transformers for 3d camera control.Proc. ICLR, 2025
2025
-
[30]
Yiming Xie, Chun-Han Yao, Vikram V oleti, Huaizu Jiang, and Varun Jampani. Sv4d: Dynamic 3d content generation with multi-frame and multi-view consistency.arXiv preprint arXiv:2407.17470, 2024. 3
-
[31]
Structure-from-motion revisited
Johannes Lutz Sch ¨onberger and Jan-Michael Frahm. Structure-from-motion revisited. InCVPR, 2016. 3
2016
-
[32]
Vggsfm: Visual geometry grounded deep structure from motion
Jianyuan Wang, Nikita Karaev, Christian Rupprecht, and David Novotny. Vggsfm: Visual geometry grounded deep structure from motion. InCVPR, pages 21686–21697, 2024
2024
-
[33]
Global Structure-from-Motion Revisited
Linfei Pan, Daniel Barath, Marc Pollefeys, and Johannes Lutz Sch¨onberger. Global Structure-from-Motion Revisited. In European Conference on Computer Vision (ECCV), 2024. 3, 21
2024
-
[34]
Gene Chou, Wenqi Xian, Guandao Yang, Mohamed Abdelfat- tah, Bharath Hariharan, Noah Snavely, Ning Yu, and Paul Debevec. Flashdepth: Real-time streaming video depth es- timation at 2k resolution.arXiv preprint arXiv:2504.07093,
-
[35]
MoGe-2: Accurate Monocular Geometry with Metric Scale and Sharp Details
Ruicheng Wang, Sicheng Xu, Yue Dong, Yu Deng, Jianfeng Xiang, Zelong Lv, Guangzhong Sun, Xin Tong, and Jiaolong Yang. Moge-2: Accurate monocular geometry with metric scale and sharp details.arXiv preprint arXiv:2507.02546, 2025
work page internal anchor Pith review arXiv 2025
-
[36]
Unidepthv2: Universal monocular metric depth estimation made simpler
Luigi Piccinelli, Christos Sakaridis, Yung-Hsu Yang, Mat- tia Segu, Siyuan Li, Wim Abbeloos, and Luc Van Gool. Unidepthv2: Universal monocular metric depth estimation made simpler.arXiv preprint arXiv:2502.20110, 2025. 3
-
[37]
Megasam: Accurate, fast and robust structure and motion from casual dynamic videos
Zhengqi Li, Richard Tucker, Forrester Cole, Qianqian Wang, Linyi Jin, Vickie Ye, Angjoo Kanazawa, Aleksander Holynski, and Noah Snavely. Megasam: Accurate, fast and robust structure and motion from casual dynamic videos. InCVPR, pages 10486–10496, June 2025. 3
2025
-
[38]
Zhai, and Shenlong Wang
David Yifan Yao, Albert J. Zhai, and Shenlong Wang. Uni4d: Unifying visual foundation models for 4d modeling from a single video. InCVPR, pages 1116–1126, June 2025. 5, 15
2025
-
[39]
Vipe: Video pose engine for 3d geometric perception, 2025
Jiahui Huang, Qunjie Zhou, Hesam Rabeti, Aleksandr Ko- rovko, Huan Ling, Xuanchi Ren, Tianchang Shen, Jun Gao, Dmitry Slepichev, Chen-Hsuan Lin, Jiawei Ren, Kevin Xie, Joydeep Biswas, Laura Leal-Taixe, and Sanja Fidler. Vipe: Video pose engine for 3d geometric perception, 2025. 3, 21
2025
-
[40]
Droid-slam: Deep visual slam for monocular, stereo, and rgb-d cameras.Advances in neural information processing systems, 34:16558–16569, 2021
Zachary Teed and Jia Deng. Droid-slam: Deep visual slam for monocular, stereo, and rgb-d cameras.Advances in neural information processing systems, 34:16558–16569, 2021. 3
2021
-
[41]
Dust3r: Geometric 3d vision made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. Dust3r: Geometric 3d vision made easy. InCVPR, 2024. 3
2024
-
[42]
VGGT: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. VGGT: Visual geometry grounded transformer. InCVPR, 2025
2025
-
[43]
MapAnything: Universal Feed-Forward Metric 3D Reconstruction
Nikhil Keetha, Norman M ¨uller, Johannes Sch ¨onberger, Lorenzo Porzi, Yuchen Zhang, Tobias Fischer, Arno Knapitsch, Duncan Zauss, Ethan Weber, Nelson Antunes, et al. Mapanything: Universal feed-forward metric 3d recon- struction.arXiv preprint arXiv:2509.13414, 2025. 3
work page internal anchor Pith review arXiv 2025
-
[44]
π3: Scalable permutation-equivariant visual geometry learning, 2025
Yifan Wang, Jianjun Zhou, Haoyi Zhu, Wenzheng Chang, Yang Zhou, Zizun Li, Junyi Chen, Jiangmiao Pang, Chunhua Shen, and Tong He. π3: Scalable permutation-equivariant visual geometry learning, 2025. 3, 5, 13, 17, 21
2025
-
[45]
Q. Sun et al. Monst3r: A simple approach for estimating geometry in dynamic scenes.arXiv:2410.03825, 2024
-
[46]
D. Zhuo et al. Streaming 4d visual geometry transformer. arXiv:2507.11539, 2025
-
[47]
arXiv preprint arXiv:2504.07961 , year =
Zeren Jiang, Chuanxia Zheng, Iro Laina, Diane Larlus, and Andrea Vedaldi. Geo4d: Leveraging video genera- tors for geometric 4d scene reconstruction.arXiv preprint arXiv:2504.07961, 2025. 3
-
[48]
Harley, Leonidas Guibas, and Kostas Daniilidis
Jiahui Lei, Yijia Weng, Adam W. Harley, Leonidas Guibas, and Kostas Daniilidis. MoSca: Dynamic gaussian fusion from casual videos via 4d motion scaffolds. InCVPR, pages 6165–6177, June 2025. 3 10
2025
-
[49]
Shape of motion: 4d reconstruction from a single video
Qianqian Wang, Vickie Ye, Hang Gao, Weijia Zeng, Jake Austin, Zhengqi Li, and Angjoo Kanazawa. Shape of motion: 4d reconstruction from a single video. InICCV, pages 9660– 9672, October 2025. 22
2025
-
[50]
Gflow: Recovering 4d world from monoc- ular video
Shizun Wang, Xingyi Yang, Qiuhong Shen, Zhenxiang Jiang, and Xinchao Wang. Gflow: Recovering 4d world from monoc- ular video. InAAAI. AAAI Press, 2025. ISBN 978-1-57735- 897-8. 3
2025
-
[51]
SAM 2: Segment anything in images and videos, 2024
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Doll´ar, and Christoph Feichtenhofer. SAM 2: Segment anything in images and videos, 2024. 3, 5, 15, 17
2024
-
[52]
Grounding DINO 1.5: Advance the “edge” of open-set object detection, 2024
Tianhe Ren, Qing Jiang, Shilong Liu, Zhaoyang Zeng, Wen- long Liu, Han Gao, Hongjie Huang, Zhengyu Ma, Xiaoke Jiang, Yihao Chen, Yuda Xiong, Hao Zhang, Feng Li, Pei- jun Tang, Kent Yu, and Lei Zhang. Grounding DINO 1.5: Advance the “edge” of open-set object detection, 2024
2024
-
[53]
Grounded SAM: Assembling open-world models for diverse visual tasks, 2024
Tianhe Ren, Shilong Liu, Ailing Zeng, Jing Lin, Kunchang Li, He Cao, Jiayu Chen, Xinyu Huang, Yukang Chen, Feng Yan, Zhaoyang Zeng, Hao Zhang, Feng Li, Jie Yang, Hongyang Li, Qing Jiang, and Lei Zhang. Grounded SAM: Assembling open-world models for diverse visual tasks, 2024. 3, 5, 15, 17
2024
-
[54]
Col- laborative video diffusion: Consistent multi-video generation with camera control
Zhengfei Kuang, Shengqu Cai, Hao He, Yinghao Xu, Hong- sheng Li, Leonidas J Guibas, and Gordon Wetzstein. Col- laborative video diffusion: Consistent multi-video generation with camera control. In A. Globerson, L. Mackey, D. Bel- grave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors, Adv. Neural Inform. Process. Syst., volume 37, pages 16240– 16271....
2024
-
[55]
Cameractrl: Enabling camera control for video diffusion models
Hao He, Yinghao Xu, Yuwei Guo, Gordon Wetzstein, Bo Dai, Hongsheng Li, and Ceyuan Yang. Cameractrl: Enabling camera control for video diffusion models. InICLR, 2025
2025
-
[56]
Virtually being : Customizing camera-controllable video diffusion models with multi-view performance captures
Yuancheng Xu, Wenqi Xian, Li Ma, Julien Philip, Ahmet Lev- ent Tas ¸el, Yiwei Zhao, Ryan Burgert, Mingming He, Oliver Hermann, Oliver Pilarski, Rahul Garg, Paul Debevec, and Ning Yu. Virtually being : Customizing camera-controllable video diffusion models with multi-view performance captures. InSIGGRAPH Asia, 2025. 4, 5, 13
2025
-
[57]
Superglue: Learning feature match- ing with graph neural networks
Paul-Edouard Sarlin, Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. Superglue: Learning feature match- ing with graph neural networks. InCVPR, June 2020. 4, 5
2020
-
[58]
Superpoint: Self-supervised interest point detection and description
Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabi- novich. Superpoint: Self-supervised interest point detection and description. InCVPR Workshops, June 2018. 5, 22
2018
-
[59]
Pippo: High-resolution multi- view humans from a single image
Yash Kant, Ethan Weber, Jin Kyu Kim, Rawal Khirodkar, Su Zhaoen, Julieta Martinez, Igor Gilitschenski, Shunsuke Saito, and Timur Bagautdinov. Pippo: High-resolution multi- view humans from a single image. InCVPR, 2025. 4, 5, 22
2025
-
[60]
Monocular dynamic view synthesis: A reality check
Hang Gao, Ruilong Li, Shubham Tulsiani, Bryan Russell, and Angjoo Kanazawa. Monocular dynamic view synthesis: A reality check. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors,Adv. Neural In- form. Process. Syst., volume 35, pages 33768–33780. Curran Associates, Inc., 2022. 4, 6, 7, 22
2022
-
[61]
Vbench: Com- prehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, Yaohui Wang, Xinyuan Chen, Limin Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. Vbench: Com- prehensive benchmark suite for video generative models. In CVPR, pages 21807–21818, June 2024. 5, 6, 22
2024
-
[62]
Vbench-2.0: Advancing video generation benchmark suite for intrinsic faithfulness,
Dian Zheng, Ziqi Huang, Hongbo Liu, Kai Zou, Yinan He, Fan Zhang, Lulu Gu, Yuanhan Zhang, Jingwen He, Wei-Shi Zheng, Yu Qiao, and Ziwei Liu. Vbench-2.0: Advancing video generation benchmark suite for intrinsic faithfulness,
-
[63]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximil- ian Nickel, and Matthew Le. Flow matching for generative modeling. InICLR, 2023. 5
2023
-
[64]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InICCV, pages 4195–4205, October 2023. 5
2023
-
[65]
OpenVid-1M: A large-scale high-quality dataset for text-to- video generation
Kepan Nan, Rui Xie, Penghao Zhou, Tiehan Fan, Zhen- heng Yang, Zhijie Chen, Xiang Li, Jian Yang, and Ying Tai. OpenVid-1M: A large-scale high-quality dataset for text-to- video generation. InThe Thirteenth International Conference on Learning Representations, 2025. 5, 13
2025
-
[66]
Recognize anything: A strong image tagging model
Youcai Zhang, Xinyu Huang, Jinyu Ma, Zhaoyang Li, Zhaochuan Luo, Yanchun Xie, Yuzhuo Qin, Tong Luo, Yaqian Li, Shilong Liu, et al. Recognize Anything: A strong image tagging model.arXiv preprint arXiv:2306.03514, 2023. 5, 15
-
[67]
The Llama 3 herd of models, 2024
Llama Team. The Llama 3 herd of models, 2024. 5, 15
2024
-
[68]
A benchmark dataset and evaluation methodology for video object segmentation
Federico Perazzi, Jordi Pont-Tuset, Brian McWilliams, Luc Van Gool, Markus Gross, and Alexander Sorkine-Hornung. A benchmark dataset and evaluation methodology for video object segmentation. InCVPR, June 2016. 5, 17
2016
-
[69]
Pexels: Free stock photos & videos, 2025
Pexels. Pexels: Free stock photos & videos, 2025. 5, 17
2025
-
[70]
Go-with-the-flow: Motion-controllable video diffusion models using real-time warped noise
Ryan Burgert, Yuancheng Xu, Wenqi Xian, Oliver Pilarski, Pascal Clausen, Mingming He, Li Ma, Yitong Deng, Lingxiao Li, Mohsen Mousavi, Michael Ryoo, Paul Debevec, and Ning Yu. Go-with-the-flow: Motion-controllable video diffusion models using real-time warped noise. InCVPR, pages 13–23, June 2025. 6
2025
-
[71]
Gans trained by a two time-scale update rule converge to a local nash equilibrium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bern- hard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. In I. Guyon, U. V on Luxburg, S. Bengio, H. Wallach, R. Fer- gus, S. Vishwanathan, and R. Garnett, editors,Advances in Neural Information Processing Systems, volume 30. Curran Assoc...
2017
-
[72]
To- wards accurate generative models of video: A new metric & challenges, 2019
Thomas Unterthiner, Sjoerd van Steenkiste, Karol Kurach, Raphael Marinier, Marcin Michalski, and Sylvain Gelly. To- wards accurate generative models of video: A new metric & challenges, 2019. 6, 22
2019
-
[73]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. In Marina Meila and Tong Zhang, editors,Int. Conf. Machine Learn., volume 11 139 ofProceedings of Ma...
2021
-
[74]
Continuous 3d perception model with persistent state
Qianqian Wang, Yifei Zhang, Aleksander Holynski, Alexei A Efros, and Angjoo Kanazawa. Continuous 3d perception model with persistent state. InCVPR, 2025. 13
2025
-
[75]
Least-squares estimation of transformation parameters between two point patterns.IEEE Transactions on pattern analysis and machine intelligence, 13(4):376–380,
Shinji Umeyama. Least-squares estimation of transformation parameters between two point patterns.IEEE Transactions on pattern analysis and machine intelligence, 13(4):376–380,
-
[76]
CogVLM2: Visual language models for image and video understanding, 2024
Wenyi Hong, Weihan Wang, Ming Ding, Wenmeng Yu, Qing- song Lv, Yan Wang, Yean Cheng, Shiyu Huang, Junhui Ji, Zhao Xue, Lei Zhao, Zhuoyi Yang, Xiaotao Gu, Xiaohan Zhang, Guanyu Feng, Da Yin, Zihan Wang, Ji Qi, Xixuan Song, Peng Zhang, Debing Liu, Bin Xu, Juanzi Li, Yuxiao Dong, and Jie Tang. CogVLM2: Visual language models for image and video understanding...
2024
-
[77]
CogVideoX: Text-to-video diffusion models with an expert transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, Da Yin, Yuxuan.Zhang, Weihan Wang, Yean Cheng, Bin Xu, Xiaotao Gu, Yuxiao Dong, and Jie Tang. CogVideoX: Text-to-video diffusion models with an expert transformer. InThe Thirteenth International Conference on Learning Represen...
2025
-
[78]
PySceneDetect, 2025
Brandon Castellano. PySceneDetect, 2025. 15
2025
-
[79]
Gemini 2.5: Pushing the frontier with ad- vanced reasoning, multimodality, long context, and next gen- eration agentic capabilities, 2025
Gemini Team. Gemini 2.5: Pushing the frontier with ad- vanced reasoning, multimodality, long context, and next gen- eration agentic capabilities, 2025. 17
2025
-
[80]
Viser: Im- perative, web-based 3d visualization in python, 2025
Brent Yi, Chung Min Kim, Justin Kerr, Gina Wu, Rebecca Feng, Anthony Zhang, Jonas Kulhanek, Hongsuk Choi, Yi Ma, Matthew Tancik, and Angjoo Kanazawa. Viser: Im- perative, web-based 3d visualization in python, 2025. 18, 20
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.