Recognition: unknown
Long-Horizon Manipulation via Trace-Conditioned VLA Planning
Pith reviewed 2026-05-09 21:06 UTC · model grok-4.3
The pith
Predicting the remaining plan at each step creates an implicit closed loop that lets vision-language-action policies complete long-horizon manipulation tasks by automatically replanning after errors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
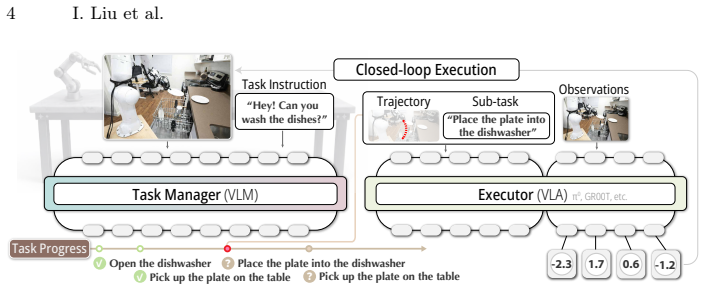
LoHo-Manip decouples a dedicated task-management vision-language model from the executor vision-language-action policy. The manager runs in receding-horizon fashion: given the latest observation it predicts a progress-aware subtask sequence with an explicit done-plus-remaining split together with a visual trace consisting of a compact 2D keypoint trajectory. The executor is adapted to follow the rendered trace, turning long-horizon decisions into repeated short-horizon control. Because the manager re-predicts the entire remaining plan at every step, failed actions stay in the output and the trace updates, producing an implicit closed loop for continuation and replanning without hand-crafted
What carries the argument
The receding-horizon task-management VLM that repeatedly generates a progress-aware subtask sequence and a 2D keypoint visual trace to condition the executor VLA policy.
If this is right
- Failed execution steps remain visible in subsequent manager outputs and are automatically addressed without separate recovery code.
- Long-horizon manipulation becomes repeated local control conditioned on fresh traces rather than monolithic planning.
- The framework applies to embodied planning, long-horizon reasoning, trajectory prediction, and real-robot manipulation without brittle visual-history buffers.
- Out-of-distribution generalization improves because the manager continuously re-interprets the current observation.
Where Pith is reading between the lines
- The separation between manager and executor may allow independent scaling or replacement of either component for different robot hardware.
- Visual traces defined as 2D keypoints could serve as a lightweight interface for combining the system with other motion planners.
- Testing the same manager on tasks with larger environmental changes would reveal how far the implicit replanning extends before prediction errors accumulate.
Load-bearing premise
The task-management vision-language model must reliably output accurate remaining subtasks and useful visual traces from current observations across different environments and task distributions.
What would settle it
Run the manager model on a set of held-out long-horizon tasks and check whether its predicted subtask sequences and traces produce lower end-to-end success rates than a plain short-horizon VLA baseline on the same tasks.
Figures









read the original abstract
Long-horizon manipulation remains challenging for vision-language-action (VLA) policies: real tasks are multi-step, progress-dependent, and brittle to compounding execution errors. We present LoHo-Manip, a modular framework that scales short-horizon VLA execution to long-horizon instruction following via a dedicated task-management VLM. The manager is decoupled from the executor and is invoked in a receding-horizon manner: given the current observation, it predicts a progress-aware remaining plan that combines (i) a subtask sequence with an explicit done + remaining split as lightweight language memory, and (ii) a visual trace -- a compact 2D keypoint trajectory prompt specifying where to go and what to approach next. The executor VLA is adapted to condition on the rendered trace, thereby turning long-horizon decision-making into repeated local control by following the trace. Crucially, predicting the remaining plan at each step yields an implicit closed loop: failed steps persist in subsequent outputs, and traces update accordingly, enabling automatic continuation and replanning without hand-crafted recovery logic or brittle visual-history buffers. Extensive experiments spanning embodied planning, long-horizon reasoning, trajectory prediction, and end-to-end manipulation in simulation and on a real Franka robot demonstrate strong gains in long-horizon success, robustness, and out-of-distribution generalization. Project page: https://www.liuisabella.com/LoHoManip
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LoHo-Manip, a modular framework for long-horizon robotic manipulation. It decouples a task-management VLM from a short-horizon VLA executor: the VLM is invoked receding-horizon style on the current observation to output a progress-aware remaining plan consisting of (i) a subtask sequence with explicit done/remaining language split and (ii) a visual trace (compact 2D keypoint trajectory). The executor VLA is conditioned on the rendered trace to reduce long-horizon control to repeated local following. The central claim is that repeated prediction of the remaining plan creates an implicit closed loop that automatically continues or replans on failures without hand-crafted recovery logic or visual-history buffers. Experiments across embodied planning, trajectory prediction, and real Franka manipulation report strong gains in success, robustness, and OOD generalization.
Significance. If the central mechanism holds, the work offers a practical route to scale existing short-horizon VLAs to long-horizon tasks by adding a lightweight modular manager and visual-trace conditioning. This could reduce reliance on brittle recovery heuristics and improve generalization, which are persistent bottlenecks in real-world manipulation. The approach is modular and re-uses off-the-shelf VLAs, which is a positive engineering contribution.
major comments (3)
- [Abstract / method overview] Abstract and method description: the implicit closed-loop claim rests on the task-management VLM reliably outputting an accurate done/remaining split and corrective traces from the current observation alone. No quantitative analysis of progress-prediction error rates, failure modes under partial observability, or visual aliasing is provided; if the VLM drops failed subtasks, the loop collapses and the claimed robustness advantage disappears. This is load-bearing for the central contribution.
- [Experiments] Experiments (assumed §4–5): while 'strong gains' are stated, the manuscript must report per-task success rates, number of trials, exact baselines (e.g., VLA with history buffers, other receding-horizon planners), and error bars. Without these, it is impossible to assess whether the reported improvements are statistically meaningful or driven by the trace-conditioning mechanism versus other factors.
- [Method] Method section on visual trace: the 2D keypoint trajectory is introduced as a compact prompt, but the rendering process, how keypoints are chosen or updated, and the precise conditioning mechanism into the VLA (e.g., tokenization, training adaptations) are not specified in sufficient detail to reproduce or analyze the executor adaptation.
minor comments (2)
- [Abstract] The abstract mentions 'extensive experiments spanning embodied planning, long-horizon reasoning, trajectory prediction, and end-to-end manipulation'; a clearer mapping from these categories to the reported tables/figures would improve readability.
- [Method] Notation for the done/remaining split and trace rendering should be formalized (e.g., as equations or pseudocode) rather than left in prose.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential of our modular framework. We address each major comment below, indicating the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / method overview] Abstract and method description: the implicit closed-loop claim rests on the task-management VLM reliably outputting an accurate done/remaining split and corrective traces from the current observation alone. No quantitative analysis of progress-prediction error rates, failure modes under partial observability, or visual aliasing is provided; if the VLM drops failed subtasks, the loop collapses and the claimed robustness advantage disappears. This is load-bearing for the central contribution.
Authors: We agree that the reliability of the VLM's progress prediction is central to the implicit closed-loop mechanism. While our end-to-end results demonstrate overall robustness, we did not include isolated quantitative metrics on progress-prediction accuracy. In the revision, we will add a new analysis subsection reporting error rates for done/remaining splits, performance under partial observability, and failure modes including visual aliasing, with metrics on how often the VLM correctly identifies completed subtasks and generates corrective traces. revision: yes
-
Referee: [Experiments] Experiments (assumed §4–5): while 'strong gains' are stated, the manuscript must report per-task success rates, number of trials, exact baselines (e.g., VLA with history buffers, other receding-horizon planners), and error bars. Without these, it is impossible to assess whether the reported improvements are statistically meaningful or driven by the trace-conditioning mechanism versus other factors.
Authors: We agree that more granular reporting is required. The current manuscript includes per-task success rates and baseline comparisons, but we will revise the experiments section to explicitly report the number of trials per task, include error bars (standard deviation), and detail exact baseline implementations such as VLA with history buffers and other receding-horizon planners. This will enable assessment of statistical significance and the specific contribution of trace conditioning. revision: yes
-
Referee: [Method] Method section on visual trace: the 2D keypoint trajectory is introduced as a compact prompt, but the rendering process, how keypoints are chosen or updated, and the precise conditioning mechanism into the VLA (e.g., tokenization, training adaptations) are not specified in sufficient detail to reproduce or analyze the executor adaptation.
Authors: We agree that the visual trace details require expansion for reproducibility. We will update the method section to specify the rendering process for the 2D keypoint trajectories, the criteria for selecting and updating keypoints based on subtask goals and observations, and the precise conditioning into the VLA including tokenization and any training adaptations to the executor. We will add pseudocode and figures to illustrate these steps. revision: yes
Circularity Check
No circularity: modular framework with independent components and external validation
full rationale
The paper introduces LoHo-Manip as a decoupled modular system: a task-management VLM predicts progress-aware subtask sequences plus visual traces in receding horizon, and an executor VLA conditions on rendered traces. The implicit closed-loop property follows directly from the design choice of re-predicting the remaining plan at each step with explicit done/remaining split; it is not obtained by redefining any quantity in terms of itself or by fitting a parameter to a subset and relabeling the output as a prediction. No equations, ansatzes, or uniqueness theorems are invoked that reduce the central claims to prior self-citations or inputs by construction. Experiments across simulation, real-robot, and out-of-distribution settings supply independent empirical support, rendering the derivation self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The vision-language model can generate accurate and useful subtask sequences and visual traces from single observations
invented entities (1)
-
Visual trace as 2D keypoint trajectory
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
In: CoRL (2022)
Ahn, M., Brohan, A., Brown, N., Chebotar, Y., Cortes, O., David, B., Finn, C., Fu, C., Gopalakrishnan, K., Hausman, K., et al.: Do as i can, not as i say: Grounding language in robotic affordances. In: CoRL (2022)
2022
-
[3]
In: NeurIPS (2025)
Ahn, S., Choi, W., Lee, J., Park, J., Woo, H.: Towards reliable code- as-policies: A neuro-symbolic framework for embodied task planning. In: NeurIPS (2025)
2025
-
[4]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., Lin, J.: Qwen2.5-vl technical report. arXiv preprint arXiv:2502.13923 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Barreiros, J., Beaulieu, A., Bhat, A., Cory, R., Cousineau, E., Dai, H., Fang, C.H., Hashimoto, K., Irshad, M.Z., Itkina, M., et al.: A careful examination of large behavior models for multitask dexterous manipulation. arXiv preprint arXiv:2507.05331 (2025)
-
[7]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Bjorck, J., Castañeda, F., Cherniadev, N., Da, X., Ding, R., Fan, L., Fang, Y., Fox, D., Hu, F., Huang, S., et al.: Gr00t n1: An open foundation model for generalist humanoid robots. arXiv preprint arXiv:2503.14734 (2025)
work page internal anchor Pith review arXiv 2025
-
[8]
In: RSS (2025)
Black, K., Brown, N., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., Groom, L., Hausman, K., Ichter, B., et al.:π0: A vision- language-action flow model for general robot control. In: RSS (2025)
2025
-
[9]
In: RSS (2023)
Brohan, A., Brown, N., Carbajal, J., Chebotar, Y., Dabis, J., Finn, C., Gopalakrishnan, K., Hausman, K., Herzog, A., Hsu, J., et al.: Rt-1: Robotics transformer for real-world control at scale. In: RSS (2023)
2023
-
[10]
arXiv preprint arXiv: (2025)
Cen, J., Yu, C., Yuan, H., Jiang, Y., Huang, S., Guo, J., Li, X., Song, Y., Luo, H., Wang, F., Zhao, D., Chen, H.: Worldvla: Towards autoregressive action world model. arXiv preprint arXiv: (2025)
2025
-
[11]
Chen, Z., Wang, W., Cao, Y., Liu, Y., Gao, Z., Cui, E., Zhu, J., Ye, S., Tian, H., Liu, Z., et al.: Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling. arXiv preprint arXiv:2412.05271 (2024)
work page internal anchor Pith review arXiv 2024
-
[12]
In: RSS (2025)
Cheng, A.C., Ji, Y., Yang, Z., Gongye, Z., Zou, X., Kautz, J., Bıyık, E., Yin, H., Liu, S., Wang, X.: Navila: Legged robot vision-language- action model for navigation. In: RSS (2025)
2025
-
[13]
In: RSS (2023)
Chi, C., Xu, Z., Feng, S., Cousineau, E., Du, Y., Burchfiel, B., Tedrake, R., Song, S.: Diffusion policy: Visuomotor policy learning via action diffusion. In: RSS (2023)
2023
-
[14]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al.: 22 I. Liu et al. Gemini 2.5: Pushing the frontier with advanced reasoning, mul- timodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
StarVLA: A Lego-like Codebase for Vision-Language-Action Model Developing
Community, S.: Starvla: A lego-like codebase for vision-language- action model developing. arXiv preprint arXiv:2604.05014 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
RynnBrain: Open Embodied Foundation Models.arXiv preprint arXiv:2602.14979, 2026
Dang, R., Guo, J., Hou, B., Leng, S., Li, K., Li, X., Liu, J., Mao, Y., Wang, Z., Yuan, Y., et al.: Rynnbrain: Open embodied foundation models. arXiv preprint arXiv:2602.14979 (2026)
-
[17]
In: ICRA (2025)
Dasari, S., Mees, O., Zhao, S., Srirama, M.K., Levine, S.: The ingre- dients for robotic diffusion transformers. In: ICRA (2025)
2025
-
[18]
In: ICRA (2017)
Devin, C., Gupta, A., Darrell, T., Abbeel, P., Levine, S.: Learn- ing modular neural network policies for multi-task and multi-robot transfer. In: ICRA (2017)
2017
-
[19]
In: ICML (2023)
Driess, D., Xia, F., Sajjadi, M.S., Lynch, C., Chowdhery, A., Ichter, B., Wahid, A., Tompson, J., Vuong, Q., Yu, T., et al.: Palm-e: An embodied multimodal language model. In: ICML (2023)
2023
-
[20]
In: CoRL (2025)
Fan, Y., Ding, P., Bai, S., Tong, X., Zhu, Y., Lu, H., Dai, F., Zhao, W., Liu, Y., Huang, S., et al.: Long-vla: Unleashing long-horizon capability of vision language action model for robot manipulation. In: CoRL (2025)
2025
-
[21]
Robix: A unified model for robot interaction, reasoning and planning
Fang, H., Zhang, M., Dong, H., Li, W., Wang, Z., Zhang, Q., Tian, X., Hu, Y., Li, H.: Robix: A unified model for robot interaction, reasoning and planning. arXiv preprint arXiv:2509.01106 (2025)
-
[22]
In: CoRL (2021)
Florence, P., Lynch, C., Zeng, A., Ramirez, O.A., Wahid, A., Downs, L., Wong, A., Lee, J., Mordatch, I., Tompson, J.: Implicit behavioral cloning. In: CoRL (2021)
2021
-
[23]
Garrett, C.R., Chitnis, R., Holladay, R., Kim, B., Silver, T., Kael- bling, L.P., Lozano-Pérez, T.: Integrated task and motion plan- ning.AnnualReviewofControl,Robotics,andAutonomousSystems (2021)
2021
-
[24]
Google DeepMind: Gemini 3 Flash: frontier intelligence built for speed.https://deepmind.google/models/gemini/flash(2025)
2025
-
[25]
Hu, Y., Zhang, J., Luo, Y., Guo, Y., Chen, X., Sun, X., Feng, K., Lu, Q., Chen, S., Zhang, Y., Li, W., Chen, J.: Bagelvla: Enhanc- ing long-horizon manipulation via interleaved vision-language-action generation. arXiv preprint arXiv:2602.09849 (2026)
-
[26]
In: CVPR (2026)
Huang, C.P., Man, Y., Yu, Z., Chen, M.H., Kautz, J., Wang, Y.C.F., Yang, F.E.: Fast-thinkact: Efficient vision-language-action reasoning via verbalizable latent planning. In: CVPR (2026)
2026
-
[27]
In: NeurIPS (2025)
Huang, C.P., Wu, Y.H., Chen, M.H., Wang, Y.C.F., Yang, F.E.: Thinkact: Vision-language-action reasoning via reinforced visual la- tent planning. In: NeurIPS (2025)
2025
-
[28]
In: CoRL (2023)
Huang, W., Wang, C., Zhang, R., Li, Y., Wu, J., Fei-Fei, L.: Vox- poser: Composable 3d value maps for robotic manipulation with lan- guage models. In: CoRL (2023)
2023
-
[29]
Inner Monologue: Embodied Reasoning through Planning with Language Models
Huang, W., Xia, F., Xiao, T., Chan, H., Liang, J., Florence, P., Zeng, A., Tompson, J., Mordatch, I., Chebotar, Y., et al.: Inner monologue: Embodied reasoning through planning with language models. arXiv preprint arXiv:2207.05608 (2022) Lo-Ho Manip 23
work page internal anchor Pith review arXiv 2022
-
[30]
Nora: A small open-sourced generalist vision language action model for embodied tasks, 2025
Hung, C.Y., Sun, Q., Hong, P., Zadeh, A., Li, C., Tan, U., Ma- jumder, N., Poria, S., et al.: Nora: A small open-sourced general- ist vision language action model for embodied tasks. arXiv preprint arXiv:2504.19854 (2025)
-
[31]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Intelligence, P., Black, K., Brown, N., Darpinian, J., Dhabalia, K., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., et al.:π0.5: A vision-language-action model with open-world generalization. arXiv preprint arXiv:2504.16054 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
In: ICML (2022)
Janner, M., Du, Y., Tenenbaum, J.B., Levine, S.: Planning with diffusion for flexible behavior synthesis. In: ICML (2022)
2022
-
[33]
In: CVPR (2025)
Ji, Y., Tan, H., Shi, J., Hao, X., Zhang, Y., Zhang, H., Wang, P., Zhao, M., Mu, Y., An, P., et al.: Robobrain: A unified brain model for robotic manipulation from abstract to concrete. In: CVPR (2025)
2025
-
[34]
In: ICML (2023)
Jiang, Y., Gupta, A., Zhang, Z., Wang, G., Dou, Y., Chen, Y., Fei- Fei, L., Anandkumar, A., Zhu, Y., Fan, L.: Vima: Robot manipula- tion with multimodal prompts. In: ICML (2023)
2023
-
[35]
Kaelbling, L.P., Lozano-Pérez, T.: Hierarchical task and motion planning in the now. Tech. rep. (2010),https://dspace.mit.edu/ handle/1721.1/54780
2010
-
[36]
In: CoRL (2024)
Kim, M.J., Pertsch, K., Karamcheti, S., Xiao, T., Balakrishna, A., Nair, S., Rafailov, R., Foster, E., Lam, G., Sanketi, P., et al.: Open- vla: An open-source vision-language-action model. In: CoRL (2024)
2024
-
[37]
In: RSS (2021)
Kumar, A., Fu, Z., Pathak, D., Malik, J.: Rma: Rapid motor adap- tation for legged robots. In: RSS (2021)
2021
-
[38]
In: ICRA (2026)
Lee, J., Duan, J., Fang, H., Deng, Y., Liu, S., Li, B., Fang, B., Zhang, J., Wang, Y.R., Lee, S., et al.: Molmoact: Action reasoning models that can reason in space. In: ICRA (2026)
2026
-
[39]
In: ICCV (2025)
Li, D., Zhang, Y., Cao, M., Liu, D., Xie, W., Hui, T., Lin, L., Xie, Z., Li, Y.: Towards long-horizon vision-language-action system: Rea- soning, acting and memory. In: ICCV (2025)
2025
-
[40]
In: ICLR (2025)
Li, Y., Deng, Y., Zhang, J., Jang, J., Memmel, M., Yu, R., Garrett, C.R., Ramos, F., Fox, D., Li, A., et al.: Hamster: Hierarchical action models for open-world robot manipulation. In: ICLR (2025)
2025
-
[41]
In: ICRA (2023)
Liang, J., Huang, W., Xia, F., Xu, P., Hausman, K., Ichter, B., Flo- rence, P., Zeng, A.: Code as policies: Language model programs for embodied control. In: ICRA (2023)
2023
-
[42]
In: NeurIPS (2023)
Liu, B., Zhu, Y., Gao, C., Feng, Y., Liu, Q., Zhu, Y., Stone, P.: Libero: Benchmarking knowledge transfer for lifelong robot learning. In: NeurIPS (2023)
2023
-
[43]
In: ICLR (2025)
Liu, Y., Hamid, J.I., Xie, A., Lee, Y., Du, M., Finn, C.: Bidirectional decoding: Improving action chunking via guided test-time sampling. In: ICLR (2025)
2025
-
[44]
In: CVPR (2025)
Liu, Z., Zhu, L., Shi, B., Zhang, Z., Lou, Y., Yang, S., Xi, H., Cao, S., Gu, Y., Li, D., et al.: Nvila: Efficient frontier visual language models. In: CVPR (2025)
2025
-
[45]
In: The Inter- national FLAIRS Conference Proceedings (2022)
McArthur, M., Moshfeghi, Y., Cashmore, M.: Egoplan: A framework for multi-agent planning using single agent planners. In: The Inter- national FLAIRS Conference Proceedings (2022)
2022
-
[46]
Liu et al
Meta AI: Llama 3.2: Revolutionizing edge ai and vision with open, customizable models.https://ai.meta.com/blog/llama- 3- 2- connect-2024-vision-edge-mobile-devices(2024) 24 I. Liu et al
2024
-
[47]
nvidia.com/labs/gear/gr00t-n1_5(2025)
NVIDIA Research: GR00T N1.5: An Improved Open Founda- tion Model for Generalist Humanoid Robots.https://research. nvidia.com/labs/gear/gr00t-n1_5(2025)
2025
-
[48]
In: RSS (2024)
Octo Model Team, Ghosh, D., Walke, H., Pertsch, K., Black, K., Mees, O., Dasari, S., Hejna, J., Xu, C., Luo, J., Kreiman, T., Tan, Y., Sanketi, P., Vuong, Q., Xiao, T., Sadigh, D., Finn, C., Levine, S.: Octo: An open-source generalist robot policy. In: RSS (2024)
2024
-
[49]
https : / / openai
OpenAI: GPT-4o Mini: Advancing Cost-Efficient Intelligence. https : / / openai . com / index / gpt - 4o - mini - advancing - cost - efficient-intelligence(2024)
2024
-
[50]
In: ICRA (2024)
O’Neill, A., Rehman, A., Maddukuri, A., Gupta, A., Padalkar, A., Lee, A., Pooley, A., Gupta, A., Mandlekar, A., Jain, A., et al.: Open x-embodiment: Robotic learning datasets and rt-x models: Open x- embodiment collaboration 0. In: ICRA (2024)
2024
-
[51]
In: RSS (2025)
Pertsch, K., Stachowicz, K., Ichter, B., Driess, D., Nair, S., Vuong, Q., Mees, O., Finn, C., Levine, S.: Fast: Efficient action tokenization for vision-language-action models. In: RSS (2025)
2025
-
[52]
arXiv preprint arXiv:2412.04447 (2024)
Qiu, L., Chen, Y., Ge, Y., Ge, Y., Shan, Y., Liu, X.: Egoplan-bench2: A benchmark for multimodal large language model planning in real- world scenarios. arXiv preprint arXiv:2412.04447 (2024)
-
[53]
In: RSS (2025)
Qu, D., Song, H., Chen, Q., Yao, Y., Ye, X., Ding, Y., Wang, Z., Gu, J., Zhao, B., Wang, D., et al.: Spatialvla: Exploring spatial rep- resentations for visual-language-action model. In: RSS (2025)
2025
-
[54]
Sayplan: Grounding large language models using 3d scene graphs for scalable task planning,
Rana, K., Haviland, J., Garg, S., Abou-Chakra, J., Reid, I., Suen- derhauf, N.: Sayplan: Grounding large language models using 3d scene graphs for scalable robot task planning. arXiv preprint arXiv:2307.06135 (2023)
-
[55]
In: Proceed- ings of the fourteenth international conference on artificial intelli- gence and statistics
Ross, S., Gordon, G., Bagnell, D.: A reduction of imitation learning and structured prediction to no-regret online learning. In: Proceed- ings of the fourteenth international conference on artificial intelli- gence and statistics. pp. 627–635. JMLR Workshop and Conference Proceedings (2011)
2011
-
[56]
In: ICRA (2024)
Sermanet, P., Ding, T., Zhao, J., Xia, F., Dwibedi, D., Gopalakr- ishnan, K., Chan, C., Dulac-Arnold, G., Maddineni, S., Joshi, N.J., et al.: Robovqa: Multimodal long-horizon reasoning for robotics. In: ICRA (2024)
2024
-
[57]
In: ICRA (2023)
Singh, I., Blukis, V., Mousavian, A., Goyal, A., Xu, D., Tremblay, J., Fox, D., Thomason, J., Garg, A.: Progprompt: Generating situated robot task plans using large language models. In: ICRA (2023)
2023
-
[58]
arXiv preprint arXiv:2601.14352 , year=
Tan, H., Zhou, E., Li, Z., Xu, Y., Ji, Y., Chen, X., Chi, C., Wang, P., Jia, H., Ao, Y., et al.: Robobrain 2.5: Depth in sight, time in mind. arXiv preprint arXiv:2601.14352 (2026)
-
[59]
arXiv preprint arXiv:2507.02029 , year=
Team, B.R.: Robobrain 2.0 technical report. arXiv preprint arXiv:2507.02029 (2025)
-
[60]
Torne, M., Pertsch, K., Walke, H., Vedder, K., Nair, S., Ichter, B., Ren, A.Z., Wang, H., Tang, J., Stachowicz, K., et al.: Mem: Multi- scale embodied memory for vision language action models.https: //www.pi.website/download/Mem.pdf(2026)
2026
-
[61]
A pragmatic vla foundation model.arXiv preprint arXiv:2601.18692, 2026
Wu, W., Lu, F., Wang, Y., Yang, S., Liu, S., Wang, F., Zhu, Q., Sun, H., Wang, Y., Ma, S., Ren, Y., Zhang, K., Yu, H., Zhao, J., Zhou, S., Lo-Ho Manip 25 Qiu, Z., Xiong, H., Wang, Z., Wang, Z., Cheng, R., Li, Y., Huang, Y., Zhu, X., Shen, Y., Zheng, K.: A pragmatic vla foundation model. arXiv preprint arXiv:2601.18692 (2026)
-
[62]
arXiv preprint arXiv:2511.20887 (2025)
Yan, R., Fu, J., Yang, S., Paulsen, L., Cheng, X., Wang, X.: Ace-f: A cross embodiment foldable system with force feedback for dexterous teleoperation. arXiv preprint arXiv:2511.20887 (2025)
-
[63]
In: CVPR (2025)
Yang, J., Tan, R., Wu, Q., Zheng, R., Peng, B., Liang, Y., Gu, Y., Cai, M., Ye, S., Jang, J., et al.: Magma: A foundation model for multimodal ai agents. In: CVPR (2025)
2025
-
[64]
In: ICML (2025)
Yang, R., Chen, H., Zhang, J., Zhao, M., Qian, C., Wang, K., Wang, Q., Koripella, T.V., Movahedi, M., Li, M., et al.: Embodiedbench: Comprehensive benchmarking multi-modal large language models for vision-driven embodied agents. In: ICML (2025)
2025
-
[65]
In: ICLR (2026)
Yuan, Y., Cui, H., Chen, Y., Dong, Z., Ni, F., Kou, L., Liu, J., Li, P., Zheng, Y., Hao, J.: From seeing to doing: Bridging reasoning and decision for robotic manipulation. In: ICLR (2026)
2026
-
[66]
In: ICLR (2026)
Yuan, Y., Cui, H., Huang, Y., Chen, Y., Ni, F., Dong, Z., Li, P., Zheng, Y., Hao, J.: Embodied-r1: Reinforced embodied reasoning for general robotic manipulation. In: ICLR (2026)
2026
-
[67]
In: ICCV (2025)
Zhang, S., Xu, Z., Liu, P., Yu, X., Li, Y., Gao, Q., Fei, Z., Yin, Z., Wu, Z., Jiang, Y.G., et al.: Vlabench: A large-scale benchmark for language-conditioned robotics manipulation with long-horizon rea- soning tasks. In: ICCV (2025)
2025
-
[68]
In: CVPR (2025)
Zhao,Q.,Lu,Y.,Kim,M.J.,Fu,Z.,Zhang,Z.,Wu,Y.,Li,Z.,Ma,Q., Han, S., Finn, C., et al.: Cot-vla: Visual chain-of-thought reasoning for vision-language-action models. In: CVPR (2025)
2025
-
[69]
In: ICLR (2025)
Zheng, R., Liang, Y., Huang, S., Gao, J., III, H.D., Kolobov, A., Huang, F., Yang, J.: TraceVLA: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies. In: ICLR (2025)
2025
-
[70]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Zhu, J., Wang, W., Chen, Z., Liu, Z., Ye, S., Gu, L., Tian, H., Duan, Y., Su, W., Shao, J., et al.: Internvl3: Exploring advanced train- ing and test-time recipes for open-source multimodal models. arXiv preprint arXiv:2504.10479 (2025)
work page internal anchor Pith review arXiv 2025
-
[71]
In: CoRL (2023)
Zitkovich, B., Yu, T., Xu, S., Xu, P., Xiao, T., Xia, F., Wu, J., Wohlhart, P., Welker, S., Wahid, A., et al.: Rt-2: Vision-language- action models transfer web knowledge to robotic control. In: CoRL (2023)
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.