Recognition: unknown
Mochi: Aligning Pre-training and Inference for Efficient Graph Foundation Models via Meta-Learning
Pith reviewed 2026-05-09 22:30 UTC · model grok-4.3
The pith
Mochi aligns pre-training with inference in graph foundation models by training on few-shot episodes that match downstream tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
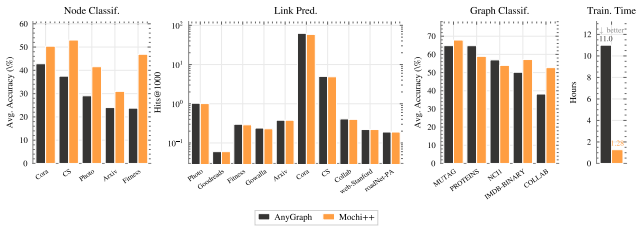
Mochi pre-trains on few-shot episodes that mirror the downstream evaluation protocol, aligning the training objective with inference rather than relying on a post-hoc unification step. We show that Mochi, along with its more powerful variant Mochi++, achieves competitive or superior performance compared to existing Graph Foundation Models across 25 real-world graph datasets spanning node classification, link prediction, and graph classification, while requiring 8~27 times less training time than the strongest baseline.
What carries the argument
A meta-learning training framework that constructs few-shot episodes to exactly replicate the downstream task protocol, replacing reconstruction-based pre-training plus separate unification.
If this is right
- Representations learned by Mochi transfer directly to node classification, link prediction, and graph classification without extra unification steps.
- Training time drops by a factor of 8 to 27 relative to the strongest prior graph foundation model baseline.
- The same meta-learning episode design supports both the base Mochi model and the stronger Mochi++ variant.
- Performance remains competitive or better across 25 diverse real-world graph datasets.
Where Pith is reading between the lines
- The episode-matching idea could be tested on other structured data domains where reconstruction pre-training is currently standard.
- If episode design proves robust, it may reduce the need for task-specific fine-tuning heads in graph models.
- Efficiency gains open the possibility of pre-training on larger and more heterogeneous graph collections within the same compute budget.
Load-bearing premise
Reconstruction-based pre-training plus post-hoc unification has inherent limitations that hurt downstream performance, and few-shot meta-learning episodes can mirror evaluation protocols without creating new mismatches or biases.
What would settle it
If Mochi shows lower accuracy than the strongest baseline on a majority of the 25 datasets or requires comparable training time when both are run under identical conditions, the central claim of improved alignment and efficiency would be refuted.
Figures




read the original abstract
We propose Mochi, a Graph Foundation Model that addresses task unification and training efficiency by adopting a meta-learning based training framework. Prior models pre-train with reconstruction-based objectives such as link prediction, and assume that the resulting representations can be aligned with downstream tasks through a separate unification step such as class prototypes. We demonstrate through synthetic and real-world experiments that this procedure, while simple and intuitive, has limitations that directly affect downstream task performance. To address these limitations, Mochi pre-trains on few-shot episodes that mirror the downstream evaluation protocol, aligning the training objective with inference rather than relying on a post-hoc unification step. We show that Mochi, along with its more powerful variant Mochi++, achieves competitive or superior performance compared to existing Graph Foundation Models across 25 real-world graph datasets spanning node classification, link prediction, and graph classification, while requiring 8$\sim$27 times less training time than the strongest baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Mochi, a graph foundation model trained via meta-learning on few-shot episodes that are constructed to mirror downstream evaluation protocols. This replaces the standard pipeline of reconstruction-based pre-training (e.g., link prediction) followed by a separate unification step such as class prototypes. The authors argue that the latter approach has limitations that degrade downstream performance, and they support this with synthetic and real-world experiments. They report that Mochi and its variant Mochi++ achieve competitive or superior results on 25 real-world graph datasets spanning node classification, link prediction, and graph classification while requiring 8–27× less training time than the strongest baseline.
Significance. If the empirical claims hold under detailed scrutiny, the work provides a concrete advance in efficient graph foundation model training by directly aligning the pre-training objective with inference via meta-learning rather than post-hoc unification. The reported efficiency gains and evaluation breadth across three task types and 25 datasets are notable strengths. The approach also supplies a falsifiable test of whether reconstruction-plus-unification pipelines are fundamentally limited, which could influence future GFM design.
major comments (2)
- The central motivation—that reconstruction-based pre-training plus post-hoc unification directly harms downstream performance—is load-bearing for the contribution. The abstract states that synthetic and real-world experiments demonstrate this, yet the manuscript must provide quantitative isolation of the unification step’s effect (e.g., an ablation that keeps the encoder fixed and varies only the unification method) to rule out confounding factors such as representation quality or optimization differences.
- The claim that few-shot meta-learning episodes “mirror the downstream evaluation protocol” without introducing new mismatches is central to the alignment argument. The paper should include an explicit protocol comparison (e.g., a table listing episode construction rules versus test-time evaluation rules) and report any residual distribution shift metrics between training episodes and downstream tasks.
minor comments (3)
- Clarify the precise definition of “few-shot episodes” (support size, query size, sampling strategy) in the methods section so that the mirroring claim can be reproduced.
- The efficiency comparison (8–27× less training time) should specify whether wall-clock time, FLOPs, or GPU-hours are reported and whether the baseline implementations were re-run under identical hardware and hyper-parameter budgets.
- Add a limitations paragraph discussing potential biases introduced by the meta-learning episode construction, especially for graph classification tasks where episode sampling may differ from standard inductive settings.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The two major comments highlight important aspects of our claims that we can clarify and strengthen with additional material. We address each point below and will incorporate the requested elements in the revised manuscript.
read point-by-point responses
-
Referee: The central motivation—that reconstruction-based pre-training plus post-hoc unification directly harms downstream performance—is load-bearing for the contribution. The abstract states that synthetic and real-world experiments demonstrate this, yet the manuscript must provide quantitative isolation of the unification step’s effect (e.g., an ablation that keeps the encoder fixed and varies only the unification method) to rule out confounding factors such as representation quality or optimization differences.
Authors: We agree that a direct isolation of the unification step strengthens the central claim. Our synthetic experiments were designed to hold the encoder fixed (using the same reconstruction-pretrained weights) while varying only the unification procedure, showing clear performance gaps attributable to post-hoc unification. To make this isolation fully explicit and rule out any remaining confounds, we will add a dedicated ablation subsection (new Table/Figure in Section 4) that fixes the encoder from a reconstruction baseline and systematically compares unification methods (class prototypes, linear probes, and direct meta-inference) on identical representations across multiple datasets. This will be included in the revision. revision: yes
-
Referee: The claim that few-shot meta-learning episodes “mirror the downstream evaluation protocol” without introducing new mismatches is central to the alignment argument. The paper should include an explicit protocol comparison (e.g., a table listing episode construction rules versus test-time evaluation rules) and report any residual distribution shift metrics between training episodes and downstream tasks.
Authors: We agree that an explicit side-by-side protocol comparison and quantitative shift metrics will make the alignment argument more transparent. In the revised manuscript we will insert a new table (e.g., Table 2) that lists, for each task type, the exact episode-construction rules used during meta-training versus the corresponding test-time evaluation rules. We will also report residual distribution-shift metrics (e.g., Wasserstein distance on node/graph feature distributions and label-balance divergence) between the meta-training episodes and the downstream test sets, computed on the 25 real-world datasets. These additions will appear in Section 3.2 and the experimental analysis. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper frames Mochi as a meta-learning framework that pre-trains on few-shot episodes mirroring downstream protocols, directly contrasting it with reconstruction-based pre-training plus post-hoc unification. This is supported by synthetic and real-world experiments on 25 datasets showing performance and efficiency gains (8-27x less training time). No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations are present in the provided text. The central claim reduces to empirical comparison rather than any input-by-construction equivalence, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Few-shot episodes can be constructed to mirror downstream evaluation protocols without introducing distribution shift
Reference graph
Works this paper leans on
-
[2]
Uni- versal prompt tuning for graph neural networks
Taoran Fang, Yunchao Zhang, Yang Yang, Chunping Wang, and Lei Chen. Uni- versal prompt tuning for graph neural networks. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors,Advances in Neural Information Processing Systems 36: Annual Conference on Neural Informa- tion Processing Systems 2023, NeurIPS 2023, N...
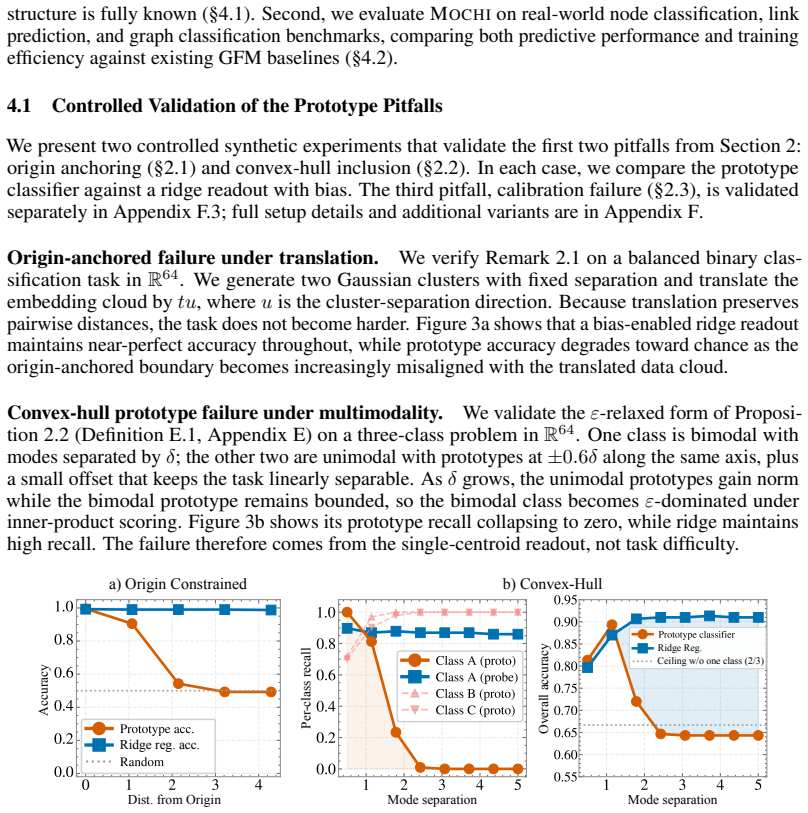
2023
-
[3]
Chawla, Chuxu Zhang, and Yanfang Ye
Zehong Wang, Zheyuan Zhang, Nitesh V . Chawla, Chuxu Zhang, and Yanfang Ye. GFT: graph foundation model with transferable tree vocabulary. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub M. Tomczak, and Cheng Zhang, edi- tors,Advances in Neural Information Processing Systems 38: Annual Conference on Neural Informatio...
2024
-
[4]
Zemin Liu, Xingtong Yu, Yuan Fang, and Xinming Zhang. Graphprompt: Unifying pre-training and downstream tasks for graph neural networks. In Ying Ding, Jie Tang, Juan F. Sequeda, Lora Aroyo, Carlos Castillo, and Geert-Jan Houben, editors,Proceedings of the ACM Web Conference 2023, WWW 2023, Austin, TX, USA, 30 April 2023 - 4 May 2023, pages 417–428. ACM, 2...
-
[5]
One for all: Towards training one graph model for all classification tasks
Hao Liu, Jiarui Feng, Lecheng Kong, Ningyue Liang, Dacheng Tao, Yixin Chen, and Muhan Zhang. One for all: Towards training one graph model for all classification tasks. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11,
2024
-
[6]
URLhttps://openreview.net/forum?id=4IT2pgc9v6
OpenReview.net, 2024. URLhttps://openreview.net/forum?id=4IT2pgc9v6
2024
-
[7]
Unigraph: Learning a unified cross-domain foundation model for text-attributed graphs
Yufei He, Yuan Sui, Xiaoxin He, and Bryan Hooi. Unigraph: Learning a unified cross-domain foundation model for text-attributed graphs. In Yizhou Sun, Flavio Chierichetti, Hady W. Lauw, Claudia Perlich, Wee Hyong Tok, and Andrew Tomkins, editors,Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining, V .1, KDD 2025, Toronto, O...
-
[8]
Jake Snell, Kevin Swersky, and Richard S. Zemel. Prototypical networks for few-shot learning. In Isabelle Guyon, Ulrike von Luxburg, Samy Bengio, Hanna M. Wallach, Rob Fergus, S. V . N. Vishwanathan, and Roman Garnett, editors,Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-...
2017
-
[9]
A closer look at prototype classifier for few-shot image classification
Mingcheng Hou and Issei Sato. A closer look at prototype classifier for few-shot image classification. In Sanmi Koyejo, S. Mohamed, A. Agarwal, Danielle Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 ...
2022
-
[10]
Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining , pages =
Jiezhong Qiu, Yuxiao Dong, Hao Ma, Jian Li, Kuansan Wang, and Jie Tang. Network embedding as matrix factorization: Unifying deepwalk, line, pte, and node2vec. In Yi Chang, Chengxiang Zhai, Yan Liu, and Yoelle Maarek, editors,Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, WSDM 2018, Marina Del Rey, CA, USA, February...
-
[12]
Zehong Wang, Chuxu Zhang, Jundong Li, Nitesh V . Chawla, and Yanfang Ye. Graph foundation models: Challenges, methods, and open questions. In Luiza Antonie, Jian Pei, Xiaohui Yu, Flavio Chierichetti, Hady W. Lauw, Yizhou Sun, and Srinivasan Parthasarathy, editors, Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining, V .2, ...
-
[13]
arXiv preprint arXiv:1911.04623 , year=
Yan Wang, Wei-Lun Chao, Kilian Q. Weinberger, and Laurens van der Maaten. Simpleshot: Revisiting nearest-neighbor classification for few-shot learning.CoRR, abs/1911.04623, 2019. URLhttp://arxiv.org/abs/1911.04623
-
[14]
Zexi Huang, Arlei Silva, and Ambuj K. Singh. A broader picture of random-walk based graph embedding. In Feida Zhu, Beng Chin Ooi, and Chunyan Miao, editors,KDD ’21: The 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Virtual Event, Singapore, August 14-18, 2021, pages 685–695. ACM, 2021. doi: 10.1145/3447548.3467300. URL https://doi.org...
-
[15]
Weinberger
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q. Weinberger. On calibration of modern neural networks. In Doina Precup and Yee Whye Teh, editors,Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6-11 August 2017, Proceedings of Machine Learning Research, pages 1321–1330. PMLR, 2017. URL http: //proceedi...
2017
-
[16]
Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods.Advances in large margin classifiers, 10(3):61–74, 1999
John Platt et al. Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods.Advances in large margin classifiers, 10(3):61–74, 1999
1999
-
[17]
Model-agnostic meta-learning for fast adapta- tion of deep networks
Chelsea Finn, Pieter Abbeel, and Sergey Levine. Model-agnostic meta-learning for fast adapta- tion of deep networks. In Doina Precup and Yee Whye Teh, editors,Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6-11 August 2017, Proceedings of Machine Learning Research, pages 1126–1135. PMLR, 2017. URLh...
2017
-
[18]
Hoffman, David Pfau, Tom Schaul, and Nando de Freitas
Marcin Andrychowicz, Misha Denil, Sergio Gomez Colmenarejo, Matthew W. Hoffman, David Pfau, Tom Schaul, and Nando de Freitas. Learning to learn by gradient descent by gradient descent. In Daniel D. Lee, Masashi Sugiyama, Ulrike von Luxburg, Isabelle Guyon, and Roman Garnett, editors,Advances in Neural Information Processing Systems 29: Annual Conference o...
2016
-
[19]
Empowering graph representation learning with test-time graph transformation
Wei Jin, Tong Zhao, Jiayuan Ding, Yozen Liu, Jiliang Tang, and Neil Shah. Empowering graph representation learning with test-time graph transformation. InThe Eleventh Interna- tional Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023. URLhttps://openreview.net/forum?id=Lnxl5pr018
2023
-
[20]
Meta-learning with differentiable convex optimization
Kwonjoon Lee, Subhransu Maji, Avinash Ravichandran, and Stefano Soatto. Meta-learning with differentiable convex optimization. InIEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019, pages 10657–10665. Computer Vision Foundation / IEEE, 2019. doi: 10.1109/CVPR.2019.01091. URL http://openaccess.thecvf...
-
[21]
Position-aware graph neural networks
Jiaxuan You, Rex Ying, and Jure Leskovec. Position-aware graph neural networks. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors,Proceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, USA, Proceedings of Machine Learning Research, pages 7134–7143. PMLR, 2019. URL http://proceedings. ...
2019
-
[22]
On the equivalence between positional node embeddings and structural graph representations
Balasubramaniam Srinivasan and Bruno Ribeiro. On the equivalence between positional node embeddings and structural graph representations. In8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net, 2020. URLhttps://openreview.net/forum?id=SJxzFySKwH
2020
-
[23]
Henriques, Philip H
Luca Bertinetto, João F. Henriques, Philip H. S. Torr, and Andrea Vedaldi. Meta-learning with differentiable closed-form solvers. In7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net, 2019. URL https: //openreview.net/forum?id=HyxnZh0ct7
2019
-
[24]
Meta- gnn: On few-shot node classification in graph meta-learning
Fan Zhou, Chengtai Cao, Kunpeng Zhang, Goce Trajcevski, Ting Zhong, and Ji Geng. Meta- gnn: On few-shot node classification in graph meta-learning. In Wenwu Zhu, Dacheng Tao, Xueqi Cheng, Peng Cui, Elke A. Rundensteiner, David Carmel, Qi He, and Jeffrey Xu Yu, editors,Proceedings of the 28th ACM International Conference on Information and Knowledge Manage...
-
[25]
Graph meta learning via local subgraphs
Kexin Huang and Marinka Zitnik. Graph meta learning via local subgraphs. In Hugo Larochelle, Marc’Aurelio Ranzato, Raia Hadsell, Maria-Florina Balcan, and Hsuan-Tien Lin, editors,Advances in Neural Information Processing Systems 33: Annual Con- ference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6- 12, 2020, virtual, 2020. URL ht...
2020
-
[26]
All in One: Multi-Task Prompting for Graph Neural Networks
Xiangguo Sun, Hong Cheng, Jia Li, Bo Liu, and Jihong Guan. All in One: Multi-Task Prompting for Graph Neural Networks. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD ’23, pages 2120–2131, New York, NY , USA, August 2023. Association for Computing Machinery. ISBN 979-8-4007-0103-0. doi: 10.1145/3580305.3599256. ...
-
[27]
Proceedings of the ACM on Web Conference 2025 , pages =
Xingtong Yu, Zechuan Gong, Chang Zhou, Yuan Fang, and Hui Zhang. SAMGPT: text-free graph foundation model for multi-domain pre-training and cross-domain adaptation. In Guodong Long, Michale Blumestein, Yi Chang, Liane Lewin-Eytan, Zi Helen Huang, and Elad Yom-Tov, editors,Proceedings of the ACM on Web Conference 2025, WWW 2025, Sydney, NSW, Australia, 28 ...
-
[28]
Graph attention multi-layer perceptron
Wentao Zhang, Ziqi Yin, Zeang Sheng, Yang Li, Wen Ouyang, Xiaosen Li, Yangyu Tao, Zhi Yang, and Bin Cui. Graph attention multi-layer perceptron. In Aidong Zhang and Huzefa Rangwala, editors,KDD ’22: The 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, August 14 - 18, 2022, pages 4560–4570. ACM, 2022. doi: 10.1145/353...
-
[29]
Hansi Yang and James T. Kwok. Efficient variance reduction for meta-learning. In Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvári, Gang Niu, and Sivan Sabato, editors, International Conference on Machine Learning, ICML 2022, 17-23 July 2022, Baltimore, Maryland, USA, Proceedings of Machine Learning Research, pages 25070–25095. PMLR, 2022. U...
2022
-
[30]
PRODIGY: enabling in-context learning over graphs
Qian Huang, Hongyu Ren, Peng Chen, Gregor Krzmanc, Daniel Zeng, Percy Liang, and Jure Leskovec. PRODIGY: enabling in-context learning over graphs. In Alice Oh, Tris- tan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors, Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Sy...
2023
-
[31]
Graph contrastive learning with augmentations
Yuning You, Tianlong Chen, Yongduo Sui, Ting Chen, Zhangyang Wang, and Yang Shen. Graph contrastive learning with augmentations. In Hugo Larochelle, Marc’Aurelio Ranzato, Raia Hadsell, Maria-Florina Balcan, and Hsuan-Tien Lin, editors,Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, Neu...
2020
-
[32]
Position: Graph foundation models are already here
Haitao Mao, Zhikai Chen, Wenzhuo Tang, Jianan Zhao, Yao Ma, Tong Zhao, Neil Shah, Mikhail Galkin, and Jiliang Tang. Position: Graph foundation models are already here. In Ruslan Salakhutdinov, Zico Kolter, Katherine A. Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors,Forty-first International Conference on Machine Lear...
2024
-
[33]
GPPT: Graph Pre-training and Prompt Tuning to Generalize Graph Neural Networks
Mingchen Sun, Kaixiong Zhou, Xin He, Ying Wang, and Xin Wang. GPPT: Graph Pre-training and Prompt Tuning to Generalize Graph Neural Networks. InProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 1717–1727, Washington DC USA, August 2022. ACM. ISBN 978-1-4503-9385-0. doi: 10.1145/3534678.3539249. URLhttps://dl.acm.o...
-
[34]
Opengraph: Towards open graph foundation models
Lianghao Xia, Ben Kao, and Chao Huang. Opengraph: Towards open graph foundation models. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Findings of the Association for Computational Linguistics: EMNLP 2024, Miami, Florida, USA, November 12-16, 2024, Findings of ACL, pages 2365–2379. Association for Computational Linguistics, 2024. doi: 10.18...
-
[35]
Alex O. Davies, Riku W. Green, Nirav S. Ajmeri, and Telmo M. Silva Filho. Topology Only Pre-Training: Towards Generalised Multi-Domain Graph Models, December 2024. URL http://arxiv.org/abs/2311.03976. arXiv:2311.03976 [cs]
-
[36]
Wenzhuo Tang, Haitao Mao, Danial Dervovic, Ivan Brugere, Saumitra Mishra, Yuying Xie, and Jiliang Tang. Cross-domain graph data scaling: A showcase with diffusion models.CoRR, abs/2406.01899, 2024. doi: 10.48550/ARXIV .2406.01899. URL https://doi.org/10. 48550/arXiv.2406.01899
work page internal anchor Pith review doi:10.48550/arxiv 2024
-
[37]
Chawla, Chuxu Zhang, and Yanfang Ye
Zehong Wang, Zheyuan Zhang, Tianyi Ma, Nitesh V . Chawla, Chuxu Zhang, and Yanfang Ye. Towards graph foundation models: Learning generalities across graphs via task-trees. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu, editors,Forty-second International Conference on Machine L...
2025
-
[38]
Zerog: Investigating cross- dataset zero-shot transferability in graphs
Yuhan Li, Peisong Wang, Zhixun Li, Jeffrey Xu Yu, and Jia Li. Zerog: Investigating cross- dataset zero-shot transferability in graphs. In Ricardo Baeza-Yates and Francesco Bonchi, editors,Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD 2024, Barcelona, Spain, August 25-29, 2024, pages 1725–1735. ACM, 2024. doi: 10...
-
[39]
Llaga: Large language and graph assistant
Runjin Chen, Tong Zhao, Ajay Kumar Jaiswal, Neil Shah, and Zhangyang Wang. Llaga: Large language and graph assistant. In Ruslan Salakhutdinov, Zico Kolter, Katherine A. Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors,Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024...
2024
-
[40]
Holographic node representations: Pre-training task-agnostic node embeddings
Beatrice Bevilacqua, Joshua Robinson, Jure Leskovec, and Bruno Ribeiro. Holographic node representations: Pre-training task-agnostic node embeddings. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenRe- view.net, 2025. URLhttps://openreview.net/forum?id=tGYFikNONB
2025
-
[41]
Bronstein, and Jian Tang
Jianan Zhao, Zhaocheng Zhu, Mikhail Galkin, Hesham Mostafa, Michael M. Bronstein, and Jian Tang. Fully-inductive node classification on arbitrary graphs. InThe Thirteenth Inter- national Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025. URLhttps://openreview.net/forum?id=1Qpt43cqhg. 13
2025
-
[42]
Kaiwen Dong, Haitao Mao, Zhichun Guo, and Nitesh V . Chawla. Universal link predictor by in-context learning on graphs.Trans. Mach. Learn. Res., 2025, 2025. URL https:// openreview.net/forum?id=EYpqmoejB8
2025
-
[43]
A perspective view and survey of meta-learning.Artif
Ricardo Vilalta and Youssef Drissi. A perspective view and survey of meta-learning.Artif. Intell. Rev., 18(2):77–95, 2002. doi: 10.1023/A:1019956318069. URL https://doi.org/10. 1023/A:1019956318069
-
[44]
Match- ing networks for one shot learning
Oriol Vinyals, Charles Blundell, Tim Lillicrap, Koray Kavukcuoglu, and Daan Wierstra. Match- ing networks for one shot learning. In Daniel D. Lee, Masashi Sugiyama, Ulrike von Luxburg, Isabelle Guyon, and Roman Garnett, editors,Advances in Neural Information Processing Sys- tems 29: Annual Conference on Neural Information Processing Systems 2016, December...
2016
-
[45]
Task-adaptive few-shot node classification
Song Wang, Kaize Ding, Chuxu Zhang, Chen Chen, and Jundong Li. Task-adaptive few-shot node classification. In Aidong Zhang and Huzefa Rangwala, editors,KDD ’22: The 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, August 14 - 18, 2022, pages 1910–1919. ACM, 2022. doi: 10.1145/3534678.3539265. URL https://doi.org/10.1...
-
[46]
Meta-gps++: Enhancing graph meta-learning with contrastive learning and self-training.ACM Trans
Yonghao Liu, Mengyu Li, Ximing Li, Lan Huang, Fausto Giunchiglia, Yanchun Liang, Xiaoyue Feng, and Renchu Guan. Meta-gps++: Enhancing graph meta-learning with contrastive learning and self-training.ACM Trans. Knowl. Discov. Data, 18(9):212:1–212:30, 2024. doi: 10.1145/ 3679018. URLhttps://doi.org/10.1145/3679018
-
[47]
Graph prototypical networks for few-shot learning on attributed networks
Kaize Ding, Jianling Wang, Jundong Li, Kai Shu, Chenghao Liu, and Huan Liu. Graph prototypical networks for few-shot learning on attributed networks. In Mathieu d’Aquin, Stefan Dietze, Claudia Hauff, Edward Curry, and Philippe Cudré-Mauroux, editors,CIKM ’20: The 29th ACM International Conference on Information and Knowledge Management, Virtual Event, Ire...
-
[48]
How powerful are graph neural networks? In7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019
Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. How powerful are graph neural networks? In7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net, 2019. URL https://openreview.net/ forum?id=ryGs6iA5Km
2019
-
[49]
Fast Graph Representation Learning with PyTorch Geometric
Matthias Fey and Jan Eric Lenssen. Fast graph representation learning with pytorch geometric. CoRR, abs/1903.02428, 2019. URLhttp://arxiv.org/abs/1903.02428
work page internal anchor Pith review arXiv 1903
- [51]
-
[52]
An empirical study of graph contrastive learning
Yanqiao Zhu, Yichen Xu, Qiang Liu, and Shu Wu. An empirical study of graph contrastive learning. In Joaquin Vanschoren and Sai-Kit Yeung, editors,Proceed- ings of the Neural Information Processing Systems Track on Datasets and Bench- marks 1, NeurIPS Datasets and Benchmarks 2021, December 2021, virtual, 2021. URL https://datasets-benchmarks-proceedings.ne...
2021
-
[53]
The matrix cookbook.Technical University of Denmark, 7(15):510, 2008
Kaare Brandt Petersen, Michael Syskind Pedersen, et al. The matrix cookbook.Technical University of Denmark, 7(15):510, 2008. 14 A Why Link-Prediction Embeddings Trigger Prototype Failure The origin-anchored failure identified in Section 2.1 is not merely a theoretical possibility; the geometry of link-prediction embeddings makes it the expected outcome. ...
2008
-
[54]
This arises because higher-degree nodes must produce larger inner products with more neighbors
Norms encode degree.For matrix-factorization-based models, ∥zv∥ ≈ √dv, where dv is the degree of node v. This arises because higher-degree nodes must produce larger inner products with more neighbors
-
[55]
Neighbors align directionally.Connected nodes have similar angular positions in embedding space, sincez ⊤ u zv =∥z u∥ ∥zv∥cosθ uv must be large for edges(u, v)∈E
-
[56]
The embeddings rarely cross the origin
Embeddings cluster in a cone.For assortative graphs (where connected nodes share properties), properties (i) and (ii) together concentrate embeddings in a low-dimensional cone within a half- space. The embeddings rarely cross the origin. Property (iii) means that embeddings typically lie in a half-space, so the origin-constrained prototype boundary is mis...
-
[57]
the distance fromp A toconv(p B, pC), corresponding to theεin Definition E.1
-
[58]
per-class recall of the prototype classifier
-
[59]
per-class recall of a ridge readout with bias; and
-
[60]
We use a 50/50 support/query split and average all results over 20 random seeds
overall accuracy of both methods. We use a 50/50 support/query split and average all results over 20 random seeds. Results.As δ increases, A’s per-mode samples develop dominant inner products withpB (mode 1) andp C (mode 2), while⟨z, p A⟩stays bounded by they-projection. Figure 3b shows that prototype recall for class A then drops sharply, reaching exactl...
-
[61]
Expected Calibration Error (ECE) of prototype softmax probabilities
-
[62]
ECE after temperature scaling, with the temperature fitted on the support set; and
-
[63]
Reliability diagrams are computed using 15 equally spaced confidence bins, and all results are averaged over 20 random seeds
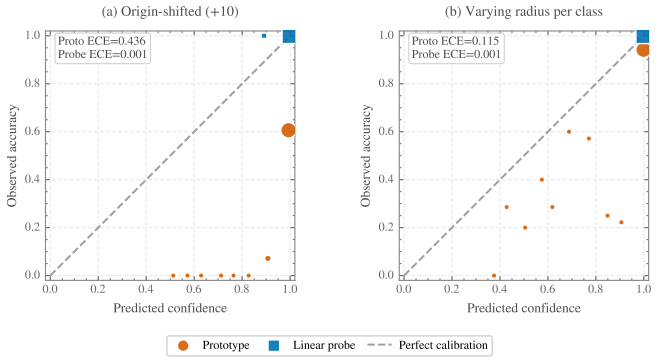
ECE of ridge logistic regression probabilities. Reliability diagrams are computed using 15 equally spaced confidence bins, and all results are averaged over 20 random seeds. Results.Under origin-shifted embeddings, prototype softmax is severely miscalibrated (ECE = 0.44 ): the per-class additive bias ⟨t, pc⟩ shifts logits across classes inconsistently, pr...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.