Recognition: unknown
Source-Modality Monitoring in Vision-Language Models
Pith reviewed 2026-05-09 21:07 UTC · model grok-4.3
The pith
Vision-language models rely more on semantic signals than syntactic ones to track whether information originates from images or text when the two modalities differ sharply in distribution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
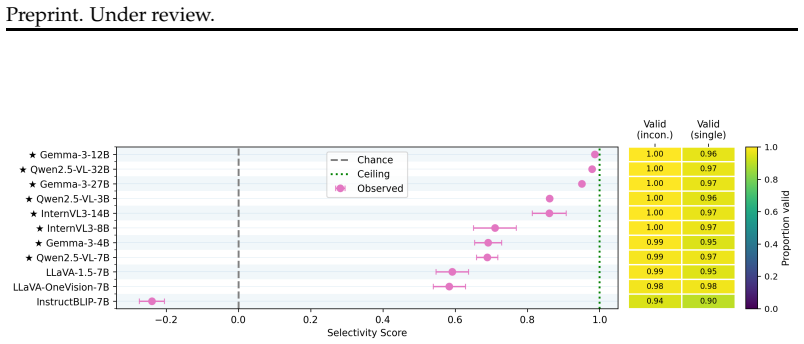
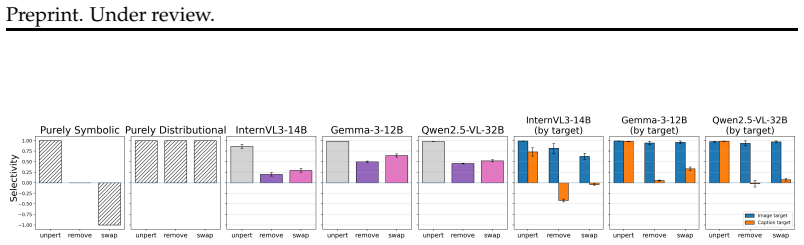
We define source-modality monitoring as the ability of multimodal models to track and communicate the input source from which pieces of information originate. Treating it as an instance of the binding problem, we evaluate how models exploit syntactic versus semantic signals to associate words such as image in a user prompt with the correct component of their multimodal input and context. Across experiments with eleven vision-language models performing target-modality information retrieval tasks, both classes of signal prove important, but semantic signals outweigh syntactic ones when the modalities are highly distinct distributionally. We discuss the implications of these findings for model
What carries the argument
Source-modality monitoring, the mechanism by which models bind prompt references to specific input components using a combination of syntactic and semantic signals.
Load-bearing premise
The selected information retrieval tasks and the eleven tested vision-language models are representative of how source-modality monitoring works in broader multimodal and agentic settings.
What would settle it
An experiment in which syntactic signals alone produce higher source-attribution accuracy than semantic signals even when image and text distributions are highly distinct would falsify the reported pattern.
Figures













read the original abstract
We define and investigate source-modality monitoring -- the ability of multimodal models to track and communicate the input source from which pieces of information originate. We consider source-modality monitoring as an instance of the more general binding problem, and evaluate the extent to which models exploit syntactic vs. semantic signals in order to bind words like image in a user-provided prompt to specific components of their input and context (i.e., actual images). Across experiments spanning 11 vision-language models (VLMs) performing target-modality information retrieval tasks, we find that both syntactic and semantic signals play an important role, but that the latter tend to outweigh the former in cases when modalities are highly distinct distributionally. We discuss the implications of these findings for model robustness, and in the context of increasingly multimodal agentic systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper defines source-modality monitoring as the capacity of vision-language models to track and report the input source of information fragments, framing this as an instance of the binding problem. It reports experiments across 11 VLMs on target-modality information retrieval tasks that vary prompts to isolate syntactic versus semantic cues for associating terms such as 'image' with actual visual inputs. The central empirical finding is that both cue types contribute, yet semantic signals predominate when the modalities are highly distinct in their distributional properties; implications for robustness and agentic multimodal systems are noted.
Significance. If the reported pattern holds under fuller methodological scrutiny, the work supplies concrete evidence on how VLMs perform cross-modal binding, a capability directly relevant to reliability in agentic and multi-turn settings. The multi-model scope (11 VLMs) and explicit syntactic/semantic contrast are strengths that could inform targeted training interventions or evaluation benchmarks. The binding-problem framing usefully connects the empirical results to a broader computational literature, though the absence of parameter-free derivations or machine-checked claims limits the result to an observational contribution.
major comments (3)
- [Abstract] Abstract: The abstract states findings from experiments on 11 models but supplies no details on task construction, controls, statistical tests, or potential confounds, so the support for the central claim cannot be verified from available information.
- [Experiments] The claim that semantic signals outweigh syntactic ones 'when modalities are highly distinct distributionally' is load-bearing for the comparative result, yet the manuscript provides no explicit operationalization or metric for distributional distinctness (e.g., no distance measure between image and text feature distributions or ablation on the degree of distinctness).
- [Discussion] The weakest assumption—that the chosen target-modality retrieval tasks and 11 VLMs capture source-modality monitoring in general multimodal and agentic settings—is not tested via any out-of-distribution or agentic-use-case ablation, leaving the scope of the finding unclear.
minor comments (2)
- [Introduction] The introduction of the novel term 'source-modality monitoring' would benefit from a short comparison table or paragraph situating it against related notions such as modality attribution or cross-modal grounding already studied in the VLM literature.
- [Results] Figure or table captions should explicitly state the number of trials per condition and any error bars or significance thresholds used to support the 'outweigh' conclusion.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work defining source-modality monitoring in vision-language models. We address each major comment below, indicating planned revisions where appropriate to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] The abstract states findings from experiments on 11 models but supplies no details on task construction, controls, statistical tests, or potential confounds, so the support for the central claim cannot be verified from available information.
Authors: We agree that the abstract is concise and omits key methodological details. In the revised version, we will expand the abstract to include a brief description of the target-modality retrieval tasks, the syntactic versus semantic prompt variations, the 11 VLMs evaluated, and a note on robustness across models with statistical controls. Full details on task construction, confounds, and tests will remain in the methods and appendix due to length limits. revision: yes
-
Referee: [Experiments] The claim that semantic signals outweigh syntactic ones 'when modalities are highly distinct distributionally' is load-bearing for the comparative result, yet the manuscript provides no explicit operationalization or metric for distributional distinctness (e.g., no distance measure between image and text feature distributions or ablation on the degree of distinctness).
Authors: This observation is correct and highlights a gap in the current presentation. The manuscript relies on a qualitative contrast between modalities without a formal metric. We will add an explicit operationalization in the experiments section, defining distributional distinctness via a quantitative measure such as average feature-space distance (e.g., cosine or Euclidean) between modality-specific embeddings, and include an ablation varying this degree where feasible across model pairs. revision: yes
-
Referee: [Discussion] The weakest assumption—that the chosen target-modality retrieval tasks and 11 VLMs capture source-modality monitoring in general multimodal and agentic settings—is not tested via any out-of-distribution or agentic-use-case ablation, leaving the scope of the finding unclear.
Authors: We acknowledge this as a genuine scope limitation of the present study, which focuses on controlled retrieval tasks rather than full agentic or OOD scenarios. In the revised discussion, we will explicitly state this assumption, clarify the intended applicability to binding in standard VLM settings, and add a dedicated paragraph outlining extensions to agentic use cases as future work. No new experiments will be added at this stage. revision: partial
Circularity Check
No significant circularity
full rationale
The paper is entirely empirical and contains no derivations, equations, or first-principles claims that could reduce to their own inputs. It defines source-modality monitoring as an instance of the binding problem and reports results from controlled experiments across 11 VLMs using target-modality retrieval tasks with prompt variations to separate syntactic and semantic signals. These measurements are independent of any fitted parameters, self-citations, or ansatzes; the comparative finding that semantic signals outweigh syntactic ones under distributional mismatch is a direct outcome of the experimental design rather than a tautology. No load-bearing self-citation chains or uniqueness theorems are invoked.
Axiom & Free-Parameter Ledger
invented entities (1)
-
source-modality monitoring
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report.ar...
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Ailin Deng, Tri Cao, Zhirui Chen, and Bryan Hooi
URL https://arxiv.org/abs/ 2207.07051. Ailin Deng, Tri Cao, Zhirui Chen, and Bryan Hooi. Words or vision: Do vision-language models have blind faith in text? In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 3867–3876,
-
[3]
Syntab-llava: Enhancing multimodal table understanding with decou- pled synthesis
doi: 10.1109/CVPR52734.2025.00366. Jiahai Feng and Jacob Steinhardt. How do language models bind entities in context? InThe Twelfth International Conference on Learning Representations,
-
[4]
Embodied ai agents: Modeling the world,
URLhttps://openreview. net/forum?id=zb3b6oKO77. Pascale Fung, Yoram Bachrach, Asli Celikyilmaz, Kamalika Chaudhuri, Delong Chen, Willy Chung, Emmanuel Dupoux, Hongyu Gong, Herv´e J´egou, Alessandro Lazaric, et al. Embodied ai agents: Modeling the world.arXiv preprint arXiv:2506.22355,
-
[5]
doi: 10.1037/0278-7393.26.2.321. John Hewitt and Percy Liang. Designing and interpreting probes with control tasks. In Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan (eds.),Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), ...
-
[6]
LongEval: Guidelines for human evaluation of faithfulness in long-form summariza- tion
Association for Computational Linguistics. doi: 10.18653/v1/ D19-1275. URLhttps://aclanthology.org/D19-1275/. Tianze Hua, Tian Yun, and Ellie Pavlick. How do vision-language models process conflicting information across modalities?arXiv preprint arXiv:2507.01790,
-
[7]
Microsoft COCO: Common Objects in Context
URLhttps://arxiv.org/abs/1405.0312. Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. In NeurIPS,
work page internal anchor Pith review arXiv
-
[8]
Mixed signals: Decod- ing VLMs’ reasoning and underlying bias in vision-language conflict
Pouya Pezeshkpour, Moin Aminnaseri, and Estevam Hruschka. Mixed signals: Decod- ing VLMs’ reasoning and underlying bias in vision-language conflict. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng (eds.),Findings of the Association for Computational Linguistics: EMNLP 2025, pp. 24833–24848, Suzhou, China, November
2025
-
[9]
URL https://aclanthology.org/2025
doi: 10.18653/v1/2025.findings-emnlp.1351. URL https://aclanthology.org/2025. findings-emnlp.1351/. Erfan Shayegani, GM Shahariar, Sara Abdali, Lei Yu, Nael Abu-Ghazaleh, and Yue Dong. Misaligned roles, misplaced images: Structural input perturbations expose multimodal alignment blind spots.arXiv preprint arXiv:2504.03735,
-
[10]
ISSN 0004-3702. doi: https://doi.org/10.1016/0004-3702(90)90007-M. URL https://www. sciencedirect.com/science/article/pii/000437029090007M. Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, and Tie-Yan Liu. Mpnet: masked and permuted pre-training for language understanding. InProceedings of the 34th International Conference on Neural Information Processing Syste...
-
[11]
Curran Associates Inc. ISBN 9781713829546. Gemini Robotics Team, Abbas Abdolmaleki, Saminda Abeyruwan, Joshua Ainslie, Jean- Baptiste Alayrac, Montserrat Gonzalez Arenas, Ashwin Balakrishna, Nathan Batche- lor, Alex Bewley, Jeff Bingham, Michael Bloesch, Konstantinos Bousmalis, Philemon Brakel, Anthony Brohan, Thomas Buschmann, Arunkumar Byravan, Serkan C...
-
[12]
URLhttps://arxiv.org/abs/2511.02243. Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479,
-
[13]
Caption:
13 Preprint. Under review. A Dataset Details We use two image–captioning datasets: MSCOCO 2017 captions and Flickr30k. Flickr30k.For Flickr30k, we use the test split from the lmms-lab/flickr30k release on HuggingFace. We then randomly permute the examples using a fixed seed and subsample 4,000 examples for train, 2,000 for validation, and 2,000 for test. ...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.