Recognition: 1 theorem link
· Lean TheoremLayerBoost: Layer-Aware Attention Reduction for Efficient LLMs
Pith reviewed 2026-05-15 06:57 UTC · model grok-4.3
The pith
LayerBoost cuts LLM inference latency up to 68% by replacing or dropping attention only in low-sensitivity layers after targeted analysis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
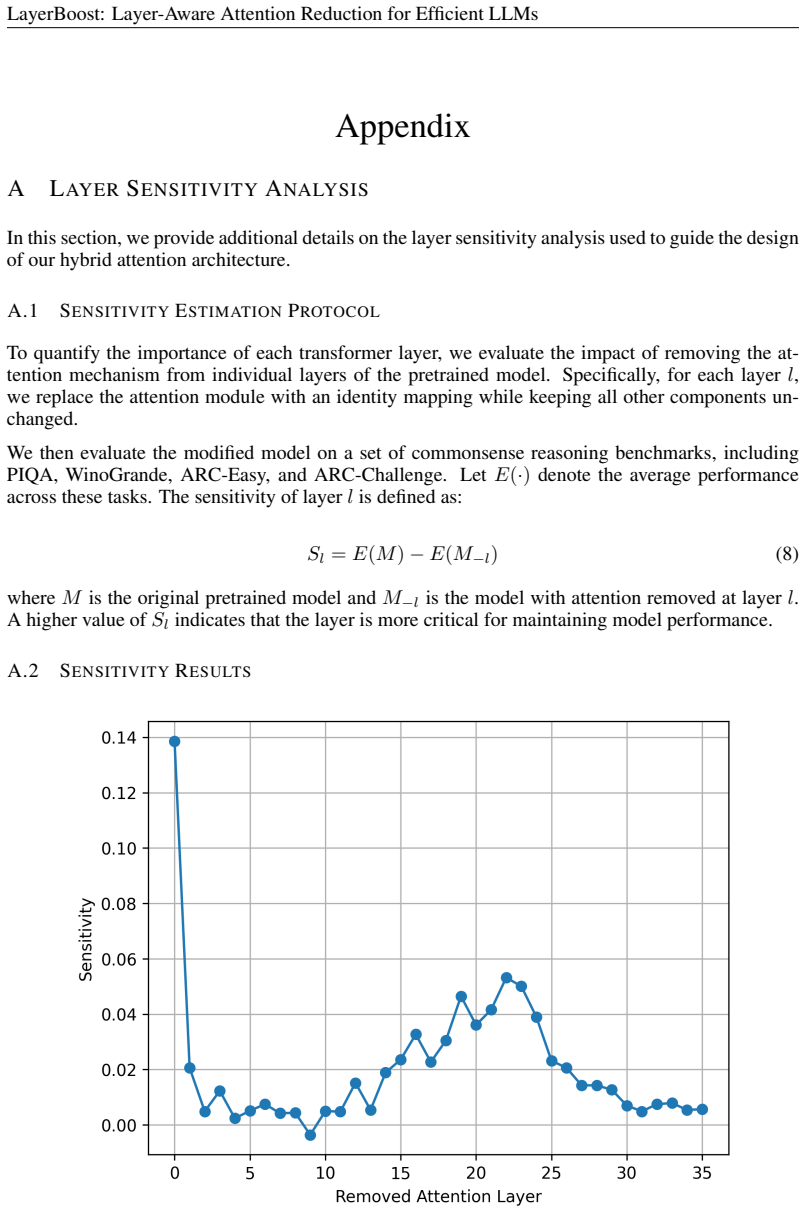
By classifying layers according to sensitivity and applying one of three attention strategies per layer—retaining softmax, switching to linear sliding window, or removing attention—followed by lightweight 10M-token distillation, LayerBoost achieves up to 68% lower inference latency at high concurrency while matching base-model performance on several benchmarks and showing only minor degradation on others.
What carries the argument
Layer-aware attention reduction that uses sensitivity analysis to assign each layer one of three strategies—full softmax, linear sliding window, or no attention—then heals the change with 10M-token distillation.
If this is right
- Matches base model performance on several standard benchmarks
- Shows only minor degradations on the remaining benchmarks
- Significantly outperforms prior uniform attention linearization methods
- Delivers up to 68% latency reduction and corresponding throughput gains at high concurrency
- Particularly suited to high-concurrency serving and hardware-constrained deployments
Where Pith is reading between the lines
- The same sensitivity-driven approach could be tested on other sequence models that contain attention-like modules to see if similar layer specialization emerges.
- If sensitivity patterns prove stable across model sizes, the analysis step could be performed once on a smaller proxy model and reused.
- Removing attention from low-sensitivity layers may also reduce peak memory usage, enabling longer contexts on the same hardware.
- The short distillation phase might be further shortened by using synthetic data that targets only the affected layers.
Load-bearing premise
The sensitivity analysis performed once on the pretrained model correctly identifies which layers can tolerate attention reduction or removal and still recover full quality after distillation.
What would settle it
Evaluate the healed model on a fresh downstream task never seen during the 10M-token distillation phase and check whether accuracy falls more than a few percent below the unmodified base model.
Figures



read the original abstract
Transformers are mostly relying on softmax attention, which introduces quadratic complexity with respect to sequence length and remains a major bottleneck for efficient inference. Prior work on linear or hybrid attention typically replaces softmax attention uniformly across all layers, often leading to significant performance degradation or requiring extensive retraining to recover model quality. This work proposes LayerBoost, a layer-aware attention reduction method that selectively modifies the attention mechanism based on the sensitivity of individual transformer layers. It first performs a systematic sensitivity analysis on a pretrained model to identify layers that are critical for maintaining performance. Guided by this analysis, three distinct strategies can be applied: retaining standard softmax attention in highly sensitive layers, replacing it with linear sliding window attention in moderately sensitive layers, and removing attention entirely in layers that exhibit low sensitivity. To recover performance after these architectural modifications, we introduce a lightweight distillation-based healing phase requiring only 10M additional training tokens. LayerBoost reduces inference latency and improves throughput by up to 68% at high concurrency, while maintaining competitive model quality. It matches base model performance on several benchmarks, exhibits only minor degradations on others, and significantly outperforms state-of-the-art attention linearization methods. These efficiency gains make our method particularly well-suited for high-concurrency serving and hardware-constrained deployment scenarios, where inference cost and memory footprint are critical bottlenecks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LayerBoost, a layer-aware method for reducing attention computation in transformer-based LLMs. It conducts sensitivity analysis on a pretrained model to classify layers and applies one of three strategies: retain softmax attention for sensitive layers, use linear sliding-window attention for moderately sensitive layers, or remove attention for low-sensitivity layers. A subsequent 10M-token distillation phase is used to heal performance. The authors report up to 68% reduction in inference latency and improved throughput at high concurrency, with competitive benchmark performance compared to the base model and superior results to prior attention linearization methods.
Significance. Should the empirical claims be substantiated with detailed ablations and comparisons, the work could provide a valuable practical contribution to efficient LLM inference by enabling selective attention reduction without uniform replacement across all layers. The lightweight healing phase is a positive aspect for minimizing retraining costs.
major comments (2)
- [§3.1] §3.1: The sensitivity analysis performed on the unmodified pretrained model may not accurately predict layer tolerances after per-layer attention changes are applied; the manuscript does not provide evidence or analysis showing that initial sensitivities hold post-modification, which is critical for the central claim.
- [§4] §4: The abstract and method description lack quantitative tables, error bars, ablation studies on the sensitivity metric, and details on how the three strategies are chosen per layer, making it impossible to verify the reported latency gains, throughput improvements, and benchmark parity.
minor comments (1)
- [Abstract] Abstract: The phrase 'significantly outperforms state-of-the-art attention linearization methods' should be supported by specific citations and quantitative comparisons in the main text.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback on our manuscript. The comments highlight important aspects of our sensitivity analysis and the need for greater quantitative rigor in reporting. We address each major comment below and commit to a major revision that incorporates additional experiments, tables, and clarifications to strengthen the paper.
read point-by-point responses
-
Referee: [§3.1] §3.1: The sensitivity analysis performed on the unmodified pretrained model may not accurately predict layer tolerances after per-layer attention changes are applied; the manuscript does not provide evidence or analysis showing that initial sensitivities hold post-modification, which is critical for the central claim.
Authors: We agree that demonstrating the stability of the initial sensitivity classifications after applying the per-layer modifications is essential to support the core claim. In the revised manuscript we will add a new subsection with an ablation that recomputes layer sensitivities on the modified model (prior to the distillation phase) and directly compares them to the original sensitivities. We will report any observed shifts, discuss their implications for the method, and, if needed, refine the classification thresholds based on this analysis. revision: yes
-
Referee: [§4] §4: The abstract and method description lack quantitative tables, error bars, ablation studies on the sensitivity metric, and details on how the three strategies are chosen per layer, making it impossible to verify the reported latency gains, throughput improvements, and benchmark parity.
Authors: We acknowledge that the current version does not provide sufficient quantitative detail for independent verification. In the revision we will: (i) expand §3 with a table listing per-layer sensitivity scores, the exact thresholds used to assign high/moderate/low sensitivity, and the resulting strategy assignment; (ii) add ablation studies that vary the sensitivity metric and thresholds while reporting downstream benchmark and latency impact; (iii) include error bars on all latency, throughput, and accuracy figures derived from multiple independent runs; and (iv) add a consolidated results table that explicitly shows the 68% latency reduction, throughput gains at different concurrency levels, and benchmark comparisons against the base model and prior linearization methods. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents an empirical method consisting of a sensitivity analysis performed on the unmodified pretrained model, followed by selective attention modifications (softmax retention, linear sliding-window replacement, or removal) and a short 10M-token distillation recovery phase. All reported outcomes (latency reductions up to 68%, benchmark scores) are measured against external held-out benchmarks rather than being algebraically forced by any internal equation or self-referential definition. No fitted parameters are renamed as predictions, no uniqueness theorems are invoked via self-citation, and no ansatz is smuggled in; the central claims rest on observable post-modification measurements.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
LayerBoost... performs a systematic sensitivity analysis... three distinct strategies: retaining standard softmax... sliding window... removing attention entirely... lightweight distillation-based healing phase requiring only 10M additional training tokens.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[3]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[4]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.