Recognition: unknown
Where Should LoRA Go? Component-Type Placement in Hybrid Language Models
Pith reviewed 2026-05-08 12:13 UTC · model grok-4.3
The pith
Adapting only the attention components with LoRA outperforms full-model adaptation in hybrid LLMs, with recurrent adaptation harming sequential hybrids but helping parallel ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
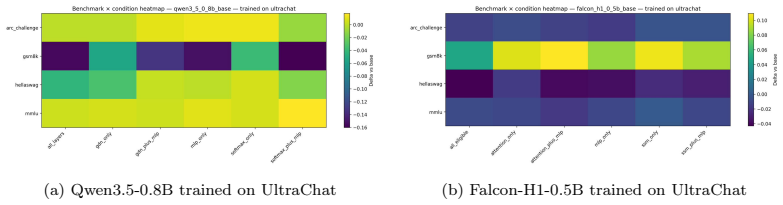
We find that the attention pathway -- despite being the minority component -- consistently outperforms full-model adaptation with 5-10x fewer trainable parameters. Crucially, adapting the recurrent backbone is destructive in sequential hybrids (-14.8 pp on GSM8K) but constructive in parallel ones (+8.6 pp).
Load-bearing premise
That the performance differences arise primarily from hybrid topology (sequential versus parallel) rather than from model-specific details such as exact recurrent implementation, training data, or hyperparameter choices.
Figures




read the original abstract
Hybrid language models that interleave attention with recurrent components are increasingly competitive with pure Transformers, yet standard LoRA practice applies adapters uniformly without considering the distinct functional roles of each component type. We systematically study component-type LoRA placement across two hybrid architectures -- Qwen3.5-0.8B (sequential, GatedDeltaNet + softmax attention) and Falcon-H1-0.5B (parallel, Mamba-2 SSM + attention) -- fine-tuned on three domains and evaluated on five benchmarks. We find that the attention pathway -- despite being the minority component -- consistently outperforms full-model adaptation with 5-10x fewer trainable parameters. Crucially, adapting the recurrent backbone is destructive in sequential hybrids (-14.8 pp on GSM8K) but constructive in parallel ones (+8.6 pp). We further document a transfer asymmetry: parallel hybrids exhibit positive cross-task transfer while sequential hybrids suffer catastrophic forgetting. These results establish that hybrid topology fundamentally determines adaptation response, and that component-aware LoRA placement is a necessary design dimension for hybrid architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an empirical study on LoRA adapter placement in hybrid language models that combine attention and recurrent components. Using two specific hybrids—one sequential (Qwen3.5-0.8B with GatedDeltaNet) and one parallel (Falcon-H1-0.5B with Mamba-2)—fine-tuned on three domains and tested on five benchmarks, the authors claim that attention-only adaptation is superior to full-model adaptation, that recurrent adaptation harms performance in sequential hybrids but helps in parallel ones, and that parallel hybrids show better cross-task transfer while sequential ones suffer forgetting. They conclude that component-type placement is a key design choice determined by hybrid topology.
Significance. Should the findings prove robust after addressing confounds, this would contribute to the field by demonstrating that standard uniform LoRA is not optimal for hybrids and that topology influences adaptation dynamics. It provides practical insights for parameter-efficient fine-tuning of competitive hybrid models, potentially leading to more efficient training practices. The use of multiple domains and benchmarks is a strength, though the small number of models limits broader applicability.
major comments (3)
- [Abstract] The assertion that the results 'establish that hybrid topology fundamentally determines adaptation response' overstates the evidence. The study compares only two models that differ in multiple respects beyond topology: recurrent component type (GatedDeltaNet vs Mamba-2 SSM), model size (0.8B vs 0.5B), and pretraining details. Without additional experiments using the same recurrent module in both sequential and parallel configurations or matched scales, the causal role of topology cannot be isolated from these confounds.
- [Results] The reported performance changes, such as -14.8 percentage points on GSM8K for recurrent adaptation in the sequential hybrid and +8.6 pp in the parallel hybrid, are presented without visible error bars, statistical tests, or full tables showing all benchmarks and conditions. This undermines confidence in the 'destructive' versus 'constructive' characterization.
- [Experiments] The experimental setup does not appear to include controls for hyperparameter differences or training data variations between the two models, which could explain the observed differences in adaptation behavior rather than the sequential vs. parallel topology.
minor comments (2)
- [Abstract] Specify the three domains and five benchmarks explicitly in the abstract for better reader orientation.
- Ensure that all figures and tables include clear legends and that any abbreviations like LoRA are defined on first use in the main text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address each of the major comments in detail below, indicating where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Abstract] The assertion that the results 'establish that hybrid topology fundamentally determines adaptation response' overstates the evidence. The study compares only two models that differ in multiple respects beyond topology: recurrent component type (GatedDeltaNet vs Mamba-2 SSM), model size (0.8B vs 0.5B), and pretraining details. Without additional experiments using the same recurrent module in both sequential and parallel configurations or matched scales, the causal role of topology cannot be isolated from these confounds.
Authors: We agree that our claim in the abstract overstates the causal isolation of topology given the differences in recurrent modules, model sizes, and pretraining between the two hybrids. While the observed patterns align with topology (sequential vs. parallel), we cannot rule out contributions from other factors. In the revised version, we will moderate the language in the abstract to 'indicate that hybrid topology influences adaptation dynamics' and expand the discussion section to explicitly acknowledge these confounds and call for future work with controlled experiments. This constitutes a partial revision as we are unable to conduct additional large-scale experiments at this time. revision: partial
-
Referee: [Results] The reported performance changes, such as -14.8 percentage points on GSM8K for recurrent adaptation in the sequential hybrid and +8.6 pp in the parallel hybrid, are presented without visible error bars, statistical tests, or full tables showing all benchmarks and conditions. This undermines confidence in the 'destructive' versus 'constructive' characterization.
Authors: The referee is correct that the main results lack error bars, statistical tests, and comprehensive tables. We will revise the results section to include error bars from multiple random seeds, perform and report paired statistical tests (e.g., t-tests) for the key performance differences, and move full benchmark tables to the appendix. These additions will provide stronger support for the destructive and constructive characterizations of recurrent adaptation. revision: yes
-
Referee: [Experiments] The experimental setup does not appear to include controls for hyperparameter differences or training data variations between the two models, which could explain the observed differences in adaptation behavior rather than the sequential vs. parallel topology.
Authors: We used the default or recommended hyperparameters for each base model and applied the same fine-tuning data domains and schedules where possible. However, we did not explicitly match all hyperparameters or isolate data variations as controls. We will add a dedicated subsection in the experimental setup detailing all hyperparameter choices and data preprocessing steps for transparency. Additionally, we will include a limitations paragraph noting that while patterns hold across domains, unaccounted variations may contribute. We maintain that the topology difference is the primary variable of interest, but acknowledge the need for this clarification. revision: partial
Circularity Check
No circularity: purely empirical observations from fine-tuning experiments
full rationale
The paper reports direct experimental results from applying LoRA to specific components in two fixed hybrid models (Qwen3.5-0.8B and Falcon-H1-0.5B) across domains and benchmarks. Claims such as attention outperforming full adaptation or recurrent adaptation being destructive/constructive are stated as measured performance deltas (e.g., -14.8 pp, +8.6 pp) rather than any derivation, prediction, or first-principles result. No equations, ansatzes, uniqueness theorems, or self-citations appear as load-bearing steps in the provided text; the central findings rest on observable outcomes from the fine-tuning runs themselves and do not reduce to their inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
E.J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, W. Chen, LoRA: Low-Rank Adaptation of Large Language Models, in: ICLR, 2022. arXiv:2106.09685
work page internal anchor Pith review arXiv 2022
-
[2]
K. Galim, W. Kang, Y. Zeng, H.I. Koo, K. Lee, Parameter-Efficient Fine-Tuning of State Space Models, in: ICML, 2025. arXiv:2410.09016
-
[3]
S0 Tuning: Zero-Overhead Adaptation of Hybrid Recurrent-Attention Models
J. Young,S 0 Tuning: Zero-Overhead Adaptation of Hybrid Recurrent- Attention Models, arXiv preprint arXiv:2604.01168, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
H. Borobia, E. Seguí-Mas, G. Tormo-Carbó, Functional Component Ab- lation Reveals Specialization Patterns in Hybrid Language Model Archi- tectures, arXiv preprint arXiv:2603.22473, 2026
-
[5]
Zuo, et al., Falcon-H1: A Family of Hybrid-Head Language Models, Technical Report, Technology Innovation Institute, 2025
J. Zuo, et al., Falcon-H1: A Family of Hybrid-Head Language Models, Technical Report, Technology Innovation Institute, 2025
2025
-
[6]
Qwen Team, Qwen3 Technical Report, arXiv preprint, 2025
2025
-
[7]
S. Yang, B. Wang, Y. Shen, R. Panda, Y. Kim, Gated Linear Attention Transformers with Hardware-Efficient Training, in: ICML, 2024
2024
-
[8]
T. Dao, A. Gu, Transformers are SSMs: Generalized Models and Ef- ficient Algorithms through Structured State Space Duality, in: ICML, 2024
2024
-
[9]
S.Wang, etal., ASystematicAnalysisofHybridLinearAttention, arXiv preprint, 2025. 19
2025
-
[10]
A. Gu, T. Dao, Mamba: Linear-Time Sequence Modeling with Selective State Spaces, arXiv preprint arXiv:2312.00752, 2023
work page internal anchor Pith review arXiv 2023
-
[11]
Lieber, et al., Jamba: A Hybrid Transformer-Mamba Language Model, arXiv preprint, 2024
O. Lieber, et al., Jamba: A Hybrid Transformer-Mamba Language Model, arXiv preprint, 2024
2024
-
[12]
Glorioso, et al., Zamba: A Compact 7B SSM Hybrid Model, arXiv preprint, 2024
P. Glorioso, et al., Zamba: A Compact 7B SSM Hybrid Model, arXiv preprint, 2024
2024
-
[13]
Zhang, M
Q. Zhang, M. Chen, A. Bukharin, P. He, Y. Cheng, W. Chen, T. Zhao, AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine- Tuning, in: ICLR, 2023
2023
-
[14]
Liu, C.-Y
S.-Y. Liu, C.-Y. Wang, H. Yin, P. Molchanov, Y.-C.F. Wang, K.-T. Cheng, M.-H. Chen, DoRA: Weight-Decomposed Low-Rank Adapta- tion, in: ICML, 2024
2024
-
[15]
MambaPEFT: Exploring parameter-efficient fine-tuning for mamba.arXiv preprint arXiv:2411.03855,
M. Yoshimura, T. Hayashi, Y. Maeda, MambaPEFT: Explor- ing Parameter-Efficient Fine-Tuning for Mamba, in: ICLR, 2025. arXiv:2411.03855
-
[16]
Training Verifiers to Solve Math Word Problems
K. Cobbe, V. Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, C. Hesse, J. Schul- man, Training Verifiers to Solve Math Word Problems, arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review arXiv 2021
-
[17]
Chaudhary, Code Alpaca: An Instruction-Following LLaMA Model for Code Generation, GitHub repository, 2023
S. Chaudhary, Code Alpaca: An Instruction-Following LLaMA Model for Code Generation, GitHub repository, 2023
2023
-
[18]
N. Ding, Y. Chen, B. Xu, Y. Qin, Z. Zheng, S. Hu, Z. Liu, M. Sun, B. Zhou, Enhancing Chat Language Models by Scaling High-quality Instructional Conversations, in: EMNLP, 2023
2023
-
[19]
Hendrycks, C
D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, J. Steinhardt, Measuring Massive Multitask Language Understanding, in: ICLR, 2021
2021
-
[20]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
P. Clark, I. Cowhey, O. Etzioni, T. Khot, A. Sabharwal, C. Schoenick, O. Tafjord, Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge, arXiv preprint arXiv:1803.05457, 2018. 20
work page internal anchor Pith review arXiv 2018
-
[21]
Zellers, A
R. Zellers, A. Holtzman, Y. Bisk, A. Farhadi, Y. Choi, HellaSwag: Can a Machine Really Finish Your Sentence?, in: ACL, 2019
2019
-
[22]
M. Chen, J. Tworek, H. Jun, Q. Yuan, H.P. de Oliveira Pinto, J. Ka- plan, et al., Evaluating Large Language Models Trained on Code, arXiv preprint arXiv:2107.03374, 2021. 21
work page internal anchor Pith review arXiv 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.