Recognition: unknown
Reliable Self-Harm Risk Screening via Adaptive Multi-Agent LLM Systems
Pith reviewed 2026-05-08 12:37 UTC · model grok-4.3
The pith
A statistical framework for adaptive multi-agent LLM pipelines reduces false positives in self-harm risk screening by 40 percent while maintaining recall.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We present a statistical framework for multi-agent pipelines structured as directed acyclic graphs (DAGs) that provides an alternative to heuristic voting with principled, adaptive decision-making. We model each agent as a stochastic categorical decision and introduce tighter agent-level performance confidence bounds, a bandit-based adaptive sampling strategy based on input difficulty, and regret guarantees over the multi-agent system that shows logarithmic error growth when deployed. Empirically, the adaptive sampling achieves the lowest false positive rate of 0.095 on AEGIS 2.0 compared to 0.159 for single-agent models, reducing incorrect flagging of safe content by 40% with similar false
What carries the argument
The bandit-based adaptive sampling strategy that estimates input difficulty to decide how many agents to consult in the DAG pipeline, providing both empirical precision gains and theoretical regret guarantees.
Load-bearing premise
That each LLM agent can be accurately modeled as a stochastic categorical decision whose difficulty can be estimated well enough for bandit adaptive sampling to apply without violating the regret analysis assumptions.
What would settle it
A new evaluation on an independent labeled dataset for self-harm risk where the adaptive strategy fails to show a statistically significant reduction in false positive rate compared to single-agent baselines, or where observed error rates exceed the predicted logarithmic bound.
Figures

read the original abstract
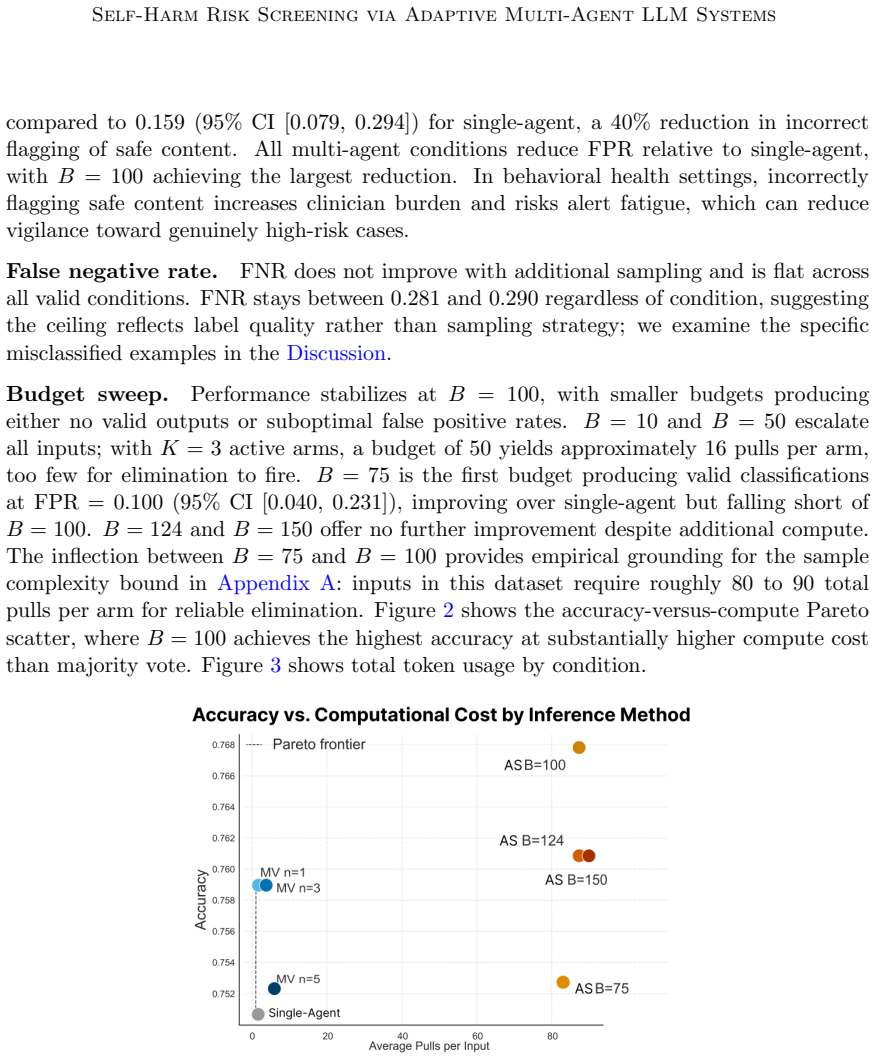
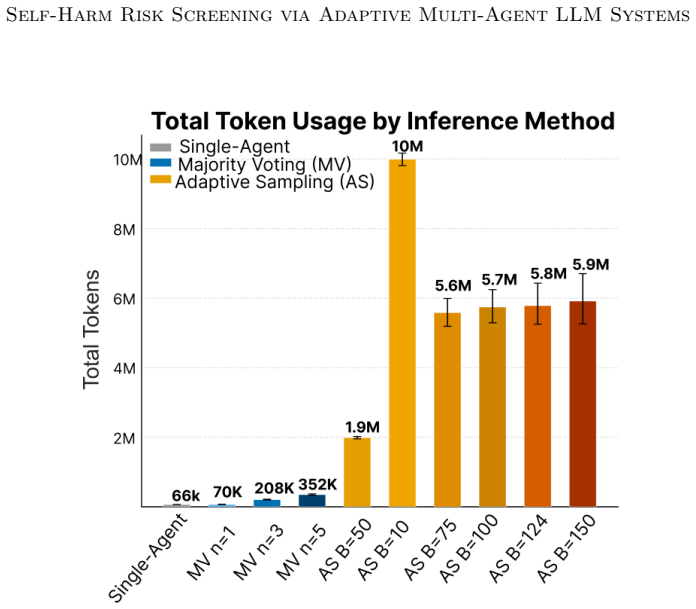
Emerging AI systems in behavioral health and psychiatry use multi-step or multi-agent LLM pipelines for tasks like assessing self-harm risk and screening for depression. However, common evaluation approaches, like LLM-as-a-judge, do not indicate when a decision is reliable or how errors may accumulate across multiple LLM judgements, limiting their suitability for safety-critical settings. We present a statistical framework for multi-agent pipelines structured as directed acyclic graphs (DAGs) that provides an alternative to heuristic voting with principled, adaptive decision-making. We model each agent as a stochastic categorical decision and introduce (1) tighter agent-level performance confidence bounds, (2) a bandit-based adaptive sampling strategy based on input difficulty, and (3) regret guarantees over the multi-agent system that shows logarithmic error growth when deployed. We evaluate our system on two labeled datasets in behavioral health : the AEGIS 2.0 behavioral health subset (N=161) and a stratified sample of SWMH Reddit posts (N=250). Empirically, our adaptive sampling strategy achieves the lowest false positive rate of any condition across both datasets, 0.095 on AEGIS 2.0 compared to 0.159 for single-agent models, reducing incorrect flagging of safe content by 40\% and still having similar false negative rates across all conditions. These results suggest that principled adaptive sampling offers a meaningful improvement in precision without reducing recall in this setting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a statistical framework for multi-agent LLM pipelines structured as directed acyclic graphs (DAGs) for self-harm risk screening. It models each agent as a stochastic categorical decision, introduces tighter agent-level performance confidence bounds, a bandit-based adaptive sampling strategy driven by estimated input difficulty, and regret guarantees claiming logarithmic error growth for the overall system. Empirical evaluation on the AEGIS 2.0 behavioral health subset (N=161) and a stratified SWMH Reddit sample (N=250) reports that the adaptive strategy achieves the lowest false positive rate (0.095 on AEGIS 2.0 versus 0.159 for single-agent baselines), corresponding to a 40% reduction in incorrect flagging of safe content while maintaining comparable false negative rates.
Significance. If the regret analysis and modeling assumptions can be rigorously validated, the framework would offer a principled, theoretically grounded alternative to heuristic voting or LLM-as-a-judge methods for reliability in safety-critical multi-agent LLM deployments. The reported empirical gains in precision without recall degradation are promising for behavioral health applications. The attempt to derive regret bounds for adaptive DAG-structured pipelines is a positive step toward falsifiable guarantees, though the small dataset sizes and unaddressed stochasticity validation limit broader impact.
major comments (3)
- [Abstract and §4 (Regret Analysis)] The regret guarantees (described in the abstract as showing 'logarithmic error growth when deployed') rest on the bandit adaptive sampler receiving accurate per-input difficulty estimates that satisfy the concentration inequalities of the underlying multi-armed bandit analysis. The manuscript provides no derivation or validation showing how difficulty is estimated from proxy signals (e.g., response variance or prior agent outputs) without ground-truth labels at inference time; any mismatch directly risks converting the claimed logarithmic bound into linear error accumulation across the DAG.
- [§5 (Empirical Evaluation)] Table or results section reporting the FPR values (0.095 vs. 0.159) and 40% reduction claim: no error bars, confidence intervals, or statistical significance tests (e.g., paired tests accounting for LLM stochasticity) are provided despite the modest sample sizes (N=161 and N=250). This omission makes it impossible to determine whether the observed improvement is robust or attributable to sampling variability or uncontrolled prompt stochasticity.
- [§3 (Agent Modeling)] §3 (Agent Modeling): The central modeling assumption that each LLM agent behaves as an independent stochastic categorical random variable whose difficulty can be estimated sufficiently well to preserve the bandit regret analysis is load-bearing but unsupported by any empirical check on the self-harm screening task, where output variance may be driven by prompt sensitivity rather than stable per-input difficulty.
minor comments (2)
- [Abstract] The abstract references 'tighter agent-level performance confidence bounds' without citing the specific section, equation, or theorem where the improvement over standard Hoeffding or Bernstein bounds is derived.
- [§2-3] Notation for the DAG structure and how bandit decisions propagate through multiple agents is introduced without a clear diagram or pseudocode, making it difficult to verify that the overall regret bound accounts for all paths.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive feedback. The comments identify key areas where additional rigor is needed in the theoretical analysis and empirical reporting. We respond to each major comment below and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract and §4 (Regret Analysis)] The regret guarantees (described in the abstract as showing 'logarithmic error growth when deployed') rest on the bandit adaptive sampler receiving accurate per-input difficulty estimates that satisfy the concentration inequalities of the underlying multi-armed bandit analysis. The manuscript provides no derivation or validation showing how difficulty is estimated from proxy signals (e.g., response variance or prior agent outputs) without ground-truth labels at inference time; any mismatch directly risks converting the claimed logarithmic bound into linear error accumulation across the DAG.
Authors: We agree that the logarithmic regret claim is conditional on the difficulty estimates satisfying the required concentration properties. The manuscript describes the use of proxy signals such as response variance and prior agent outputs for adaptive sampling but does not include an explicit derivation linking these proxies to the bandit analysis without ground-truth labels. We will revise §4 to add a formal statement of the assumptions, a derivation sketch showing how the proxies are intended to approximate difficulty, and a discussion of the risks if the estimates are inaccurate. We will also qualify the abstract claim to specify that the bound holds under accurate estimation. revision: yes
-
Referee: [§5 (Empirical Evaluation)] Table or results section reporting the FPR values (0.095 vs. 0.159) and 40% reduction claim: no error bars, confidence intervals, or statistical significance tests (e.g., paired tests accounting for LLM stochasticity) are provided despite the modest sample sizes (N=161 and N=250). This omission makes it impossible to determine whether the observed improvement is robust or attributable to sampling variability or uncontrolled prompt stochasticity.
Authors: This observation is correct. The reported metrics are point estimates, and the modest sample sizes combined with LLM stochasticity require uncertainty quantification. We will update §5 to include bootstrap confidence intervals for the FPR, FNR, and reduction claims, as well as paired statistical tests (e.g., McNemar’s test) that account for the stochasticity across conditions. We will also expand the limitations discussion to address the implications of sample size. revision: yes
-
Referee: [§3 (Agent Modeling)] §3 (Agent Modeling): The central modeling assumption that each LLM agent behaves as an independent stochastic categorical random variable whose difficulty can be estimated sufficiently well to preserve the bandit regret analysis is load-bearing but unsupported by any empirical check on the self-harm screening task, where output variance may be driven by prompt sensitivity rather than stable per-input difficulty.
Authors: The modeling in §3 is presented as a theoretical framework under the stated assumptions of stochastic categorical decisions and estimable difficulty. We did not provide a dedicated empirical validation of these assumptions on the self-harm task. We will add supporting analysis, such as repeated-query consistency measurements across agents on the same inputs, to the revised §5 or an appendix. If the results indicate that variance is largely prompt-driven, we will explicitly note this as a limitation of the current modeling. revision: yes
Circularity Check
No circularity: standard bandit analysis applied to modeled agents
full rationale
The paper models each LLM agent as a stochastic categorical decision and applies a bandit-based adaptive sampling strategy with regret guarantees derived from standard multi-armed bandit theory. These guarantees and the associated logarithmic error growth follow directly from the external theoretical framework once the per-agent model is stated; they do not reduce by construction to quantities fitted from the AEGIS or SWMH evaluation data, nor do they rest on self-citations, uniqueness theorems, or ansatzes imported from prior author work. The reported false-positive improvements are presented as empirical outcomes of the deployed system rather than as inputs that define the theoretical claims. No self-definitional loops or fitted-input-called-prediction patterns appear in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Each agent produces stochastic categorical decisions
- domain assumption Input difficulty can be estimated to drive bandit sampling without violating regret assumptions
Reference graph
Works this paper leans on
-
[1]
AEGIS2.0: A diverse ai safety dataset and risks taxonomy for alignment of llm guardrails
Shaona Ghosh, Prasoon Varshney, Thomas Westfechtel, Ryota Uehara, and Romain Paulus. AEGIS2.0: A diverse ai safety dataset and risks taxonomy for alignment of llm guardrails. arXiv preprint arXiv:2501.09004,
-
[2]
Xiaolei Huang, Lei Zhang, Tianli Liu, David Chiu, Tingshao Zhu, and Xin Li
doi: 10.1177/10783903221077292. Xiaolei Huang, Lei Zhang, Tianli Liu, David Chiu, Tingshao Zhu, and Xin Li. Detect- ing suicidal ideation in Chinese microblogs with psychological lexicons.arXiv preprint arXiv:1411.0778,
-
[3]
Mentalbert: Publicly available pretrained language models for mental healthcare,
Shaoxiong Ji, Tianlin Zhang, Luna Ansari, Jie Fu, Prayag Tiwari, and Erik Cambria. MentalBERT: Publicly available pretrained language models for mental healthcare.arXiv preprint arXiv:2110.15621,
-
[4]
arXiv:2310.17389 (2023), https://arxiv.org/abs/2310.17389
doi: 10.1038/ s41746-025-01940-4. Zi Lin, Zihan Wang, Yongqi Tian, Yuxin Zheng, Zhiyong Xi, and Pengfei Liu. ToxicChat: Unveiling hidden challenges of toxicity detection in real-world user-ai conversation.arXiv preprint arXiv:2310.17389,
-
[5]
ScAN: Suicide attempt and ideation events dataset
Bhanu Pratap Singh Rawat, Samuel Kovaly, Hong Yu, and Wilfred Pigeon. ScAN: Suicide attempt and ideation events dataset. In Marine Carpuat, Marie-Catherine de Marneffe, and Ivan Vladimir Meza Ruiz, editors,Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 1...
2022
-
[6]
doi: 10.18653/v1/2022.naacl-main.75
Association for Com- putational Linguistics. doi: 10.18653/v1/2022.naacl-main.75. Jie Sun, Tangsheng Lu, Xuexiao Shao, Ying Han, Yu Xia, Yongbo Zheng, Yongxiang Wang, Xinmin Li, Arun Ravindran, Lizhou Fan, et al. Practical ai application in psychiatry: historical review and future directions.Molecular Psychiatry, 30(9):4399–4408,
-
[7]
Ethical and social risks of harm from Language Models
Laura Weidinger, John Mellor, Maribeth Rauh, Conor Griffin, Jonathan Uesato, Po-Sen Huang, Myra Cheng, Mia Glaese, Borja Balle, Atoosa Kasirzadeh, et al. Ethical and social risks of harm from language models.arXiv preprint arXiv:2112.04359,
work page internal anchor Pith review arXiv
-
[8]
AgentNet : Decentralized Evolutionary Coordination for LLM -based Multi - Agent Systems , April 2025
15 Self-Harm Risk Screening via Adaptive Multi-Agent LLM Systems Yingxuan Yang et al. AgentNet: Decentralized evolutionary coordination for LLM-based multi-agent systems.arXiv preprint arXiv:2504.00587,
-
[9]
Depression and self-harm risk assess- ment in online forums
Andrew Yates, Arman Cohan, and Nazli Goharian. Depression and self-harm risk assess- ment in online forums. InProceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 2968–2978,
2017
-
[10]
CLPsych 2019 shared task: Predicting the degree of suicide risk in Reddit posts
Ayah Zirikly, Philip Resnik, Ozlem Uzuner, and Kristy Hollingshead. CLPsych 2019 shared task: Predicting the degree of suicide risk in Reddit posts. InProceedings of the Sixth Workshop on Computational Linguistics and Clinical Psychology, pages 24–33,
2019
-
[11]
Theorem (Node-Level Categorical Bound).Under i.i.d
16 Self-Harm Risk Screening via Adaptive Multi-Agent LLM Systems Appendix A: DKW Inequality and Node-Level Bound The Dvoretzky-Kiefer-Wolfowitz (DKW) inequality provides simultaneous error bounds across all categories of a categorical distribution without the lnKpenalty that arises from applying Hoeffding’s inequality to each category separately and takin...
1956
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.