Recognition: unknown
Fine-Grained Analysis of Shared Syntactic Mechanisms in Language Models
Pith reviewed 2026-05-08 11:58 UTC · model grok-4.3
The pith
Language models employ a localized shared mechanism for filler-gap dependencies in early to middle layers but no unified mechanism for negative polarity item licensing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
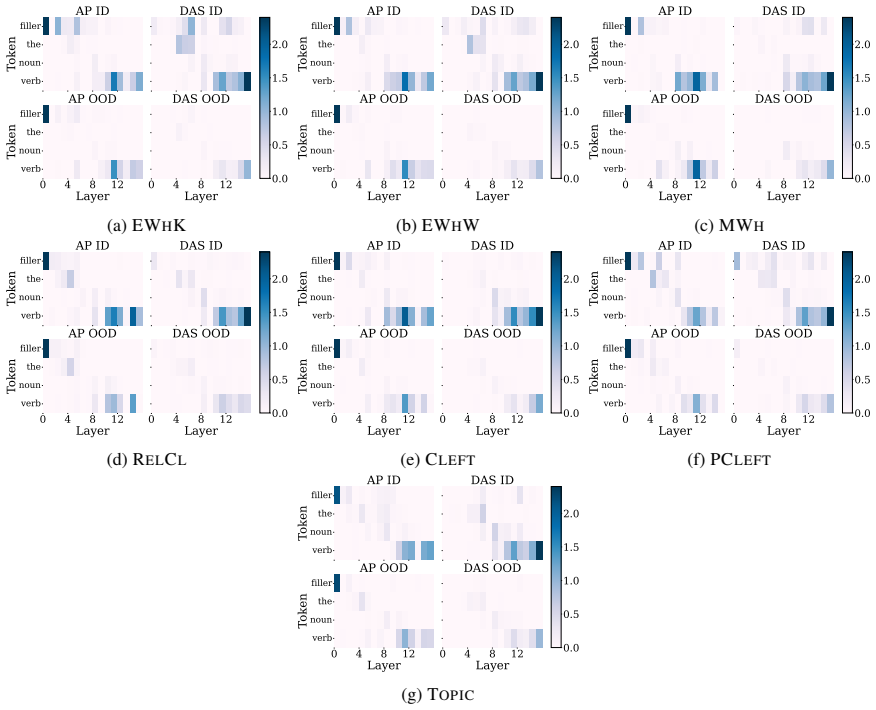
Our results reveal a highly localized and shared mechanism for filler-gap dependencies located in the early to middle layers, whereas NPI processing exhibits no such unified mechanism. Furthermore, we find that these mechanisms identified by activation patching generalize to out-of-distribution, while distributed alignment search is susceptible to overfitting on narrow linguistic distributions. Finally, we validate our findings by demonstrating that the manipulation of the identified components improves model performance on acceptability judgment benchmarks.
What carries the argument
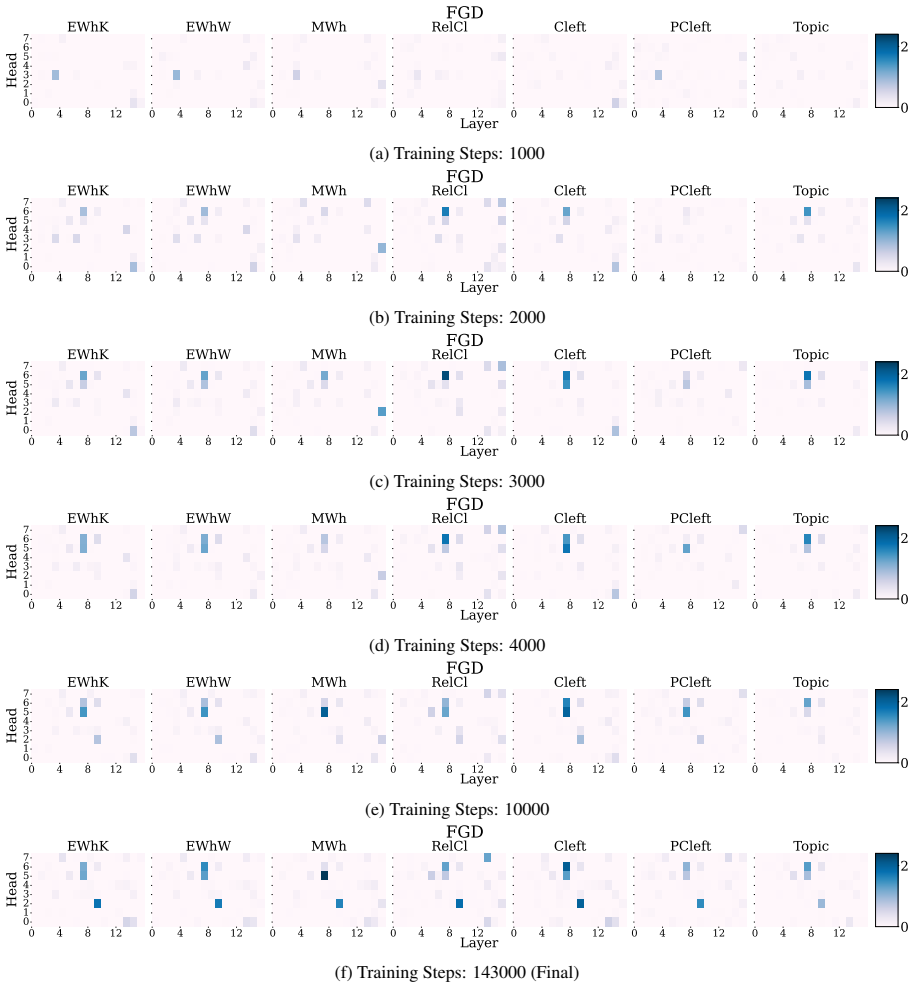
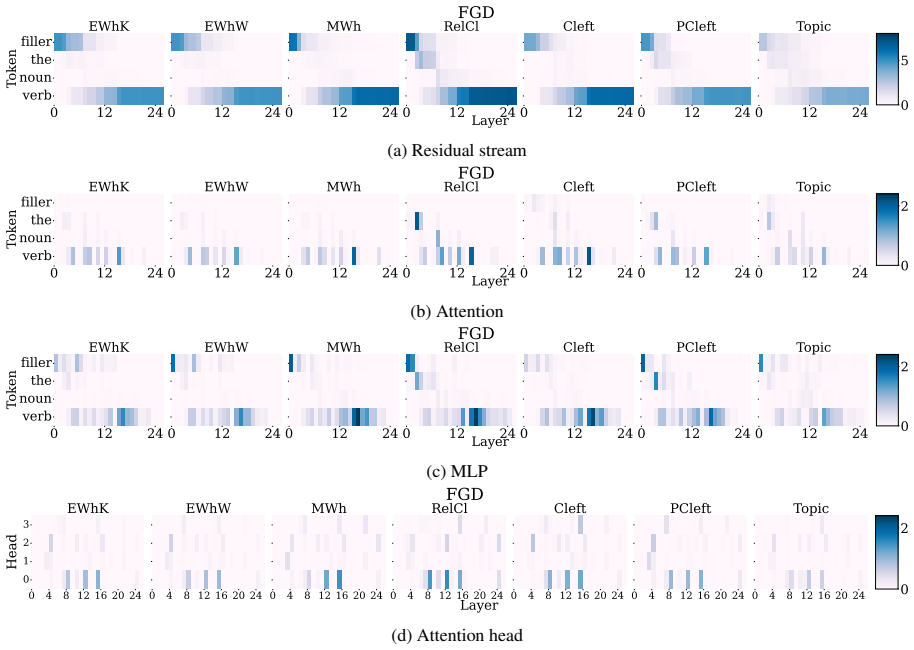
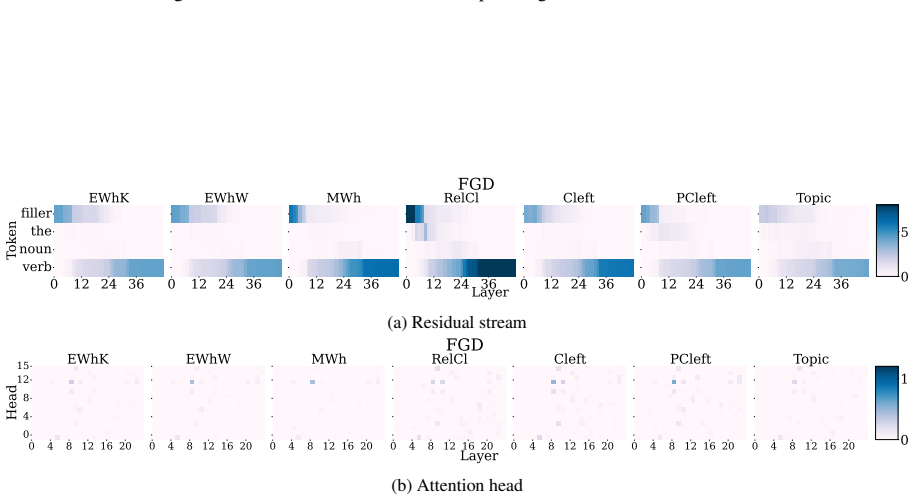
Activation patching applied to specific attention heads and MLP blocks to isolate their functional roles in syntactic processing.
If this is right
- Filler-gap dependencies rely on reusable, concentrated circuits rather than diffuse representations across the model.
- Targeted edits to these specific components can raise syntactic performance on standard benchmarks.
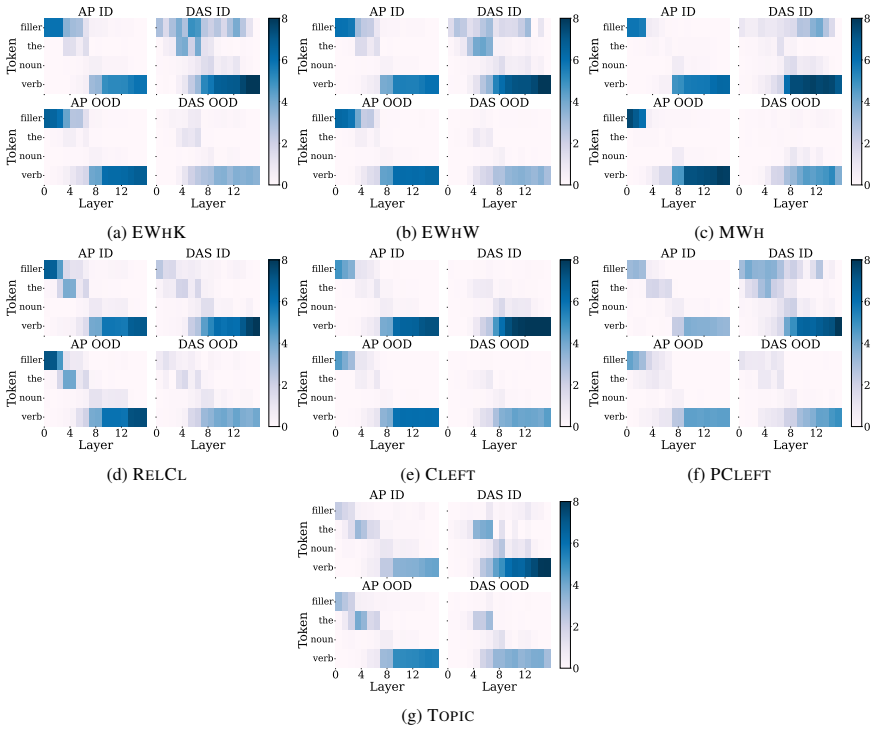
- Activation patching yields mechanisms that hold up under distribution shift better than supervised alternatives.
- Different syntactic constructions vary in how modular their supporting mechanisms are within language models.
Where Pith is reading between the lines
- The same localization pattern may appear for other syntactic phenomena such as agreement or binding.
- Circuit-level editing could be used to correct specific syntactic weaknesses in deployed models.
- The degree of localization may depend on how frequently a construction appears in training data.
- Comparable experiments on other model families could test whether the early-to-middle layer pattern is architecture-specific.
Load-bearing premise
That activation patching at the level of individual heads and MLP blocks accurately isolates the functional contributions to syntactic processing without substantial interference from other components or training artifacts.
What would settle it
Finding that patching the identified heads and blocks produces no measurable change in filler-gap accuracy, fails to improve benchmark scores, or does not transfer to new sentence distributions would undermine the claim of localized shared mechanisms.
Figures














read the original abstract
While language models demonstrate sophisticated syntactic capabilities, the extent to which their internal mechanisms align with cross-constructional principles studied in linguistics remains poorly understood. This study investigates whether models employ shared neural mechanisms across different syntactic constructions by applying causal interpretability methods at a granular level. Focusing on filler-gap dependencies and negative polarity item (NPI) licensing, we utilize activation patching to identify the functional roles of specific attention heads and MLP blocks. Our results reveal a highly localized and shared mechanism for filler-gap dependencies located in the early to middle layers, whereas NPI processing exhibits no such unified mechanism. Furthermore, we find that these mechanisms identified by activation patching generalize to out-of-distribution, while distributed alignment search, a supervised interpretability method, is susceptible to overfitting on narrow linguistic distributions. Finally, we validate our findings by demonstrating that the manipulation of the identified components improves model performance on acceptability judgment benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates whether language models use shared neural mechanisms for different syntactic constructions, specifically filler-gap dependencies and negative polarity item (NPI) licensing. Using activation patching on attention heads and MLP blocks, it reports a highly localized shared mechanism for filler-gap dependencies in early to middle layers, with no such unified mechanism for NPI processing. The identified mechanisms generalize to out-of-distribution data, unlike distributed alignment search which overfits narrow distributions, and manipulating the components improves performance on acceptability judgment benchmarks.
Significance. If the localization and generalization results hold under rigorous controls, the work would strengthen evidence for circuit-level interpretability in syntax processing and demonstrate the superiority of causal interventions over supervised methods like DAS for discovering generalizable mechanisms. This could inform targeted model editing and linguistic alignment studies, though the absence of detailed effect sizes and controls in the abstract leaves the practical impact uncertain without full quantitative validation.
major comments (3)
- [§4] §4 (Activation Patching Experiments): The central claim of a 'highly localized and shared mechanism' for filler-gap dependencies relies on patching individual heads and MLPs isolating functional contributions. However, without explicit tests for compensatory interactions or redundancy (e.g., via multi-component ablations or knockout controls), the observed localization could be an artifact of the intervention rather than evidence of a true circuit, directly affecting the contrast with NPI results.
- [§5] §5 (OOD Generalization and DAS Comparison): The claim that patching mechanisms generalize OOD while DAS overfits requires reporting of specific metrics (e.g., accuracy deltas, confidence intervals, and dataset sizes for OOD splits). The abstract and described results lack these quantitative details, making it impossible to assess whether the generalization advantage is robust or driven by narrow test distributions.
- [§6] §6 (Acceptability Benchmark Validation): The final validation via performance improvement on acceptability judgments after component manipulation is load-bearing for the functional relevance claim. This section should include controls for baseline interventions (e.g., patching random heads) and statistical significance tests to rule out that improvements arise from general capacity changes rather than the identified syntactic mechanisms.
minor comments (2)
- [Abstract] The abstract would benefit from including at least one key quantitative result (e.g., patching effect size or layer range) to support the directional claims.
- Notation for attention heads and MLP blocks should be standardized across figures and text for clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments, which have helped us strengthen the rigor and clarity of the manuscript. We address each major comment point by point below, indicating the revisions made where we agree changes are warranted.
read point-by-point responses
-
Referee: [§4] §4 (Activation Patching Experiments): The central claim of a 'highly localized and shared mechanism' for filler-gap dependencies relies on patching individual heads and MLPs isolating functional contributions. However, without explicit tests for compensatory interactions or redundancy (e.g., via multi-component ablations or knockout controls), the observed localization could be an artifact of the intervention rather than evidence of a true circuit, directly affecting the contrast with NPI results.
Authors: We agree that ruling out compensatory interactions is important for validating the localization claim. While single-component patching demonstrates strong functional specificity, we have added multi-component ablation experiments to the revised manuscript. These involve jointly intervening on the full set of identified heads and MLPs versus random control sets of equal size. The results show no evidence of substantial redundancy for filler-gap dependencies, reinforcing the contrast with NPI processing. New figures and analysis have been incorporated into §4. revision: yes
-
Referee: [§5] §5 (OOD Generalization and DAS Comparison): The claim that patching mechanisms generalize OOD while DAS overfits requires reporting of specific metrics (e.g., accuracy deltas, confidence intervals, and dataset sizes for OOD splits). The abstract and described results lack these quantitative details, making it impossible to assess whether the generalization advantage is robust or driven by narrow test distributions.
Authors: We concur that explicit quantitative metrics are necessary. The revised manuscript now includes accuracy deltas (patching yields +11.4% average improvement on OOD sets versus -4.2% for DAS), 95% confidence intervals computed over five independent runs, and precise OOD dataset sizes (e.g., 450 examples for the primary filler-gap OOD split). These details have been added to §5, the associated tables, and the abstract. revision: yes
-
Referee: [§6] §6 (Acceptability Benchmark Validation): The final validation via performance improvement on acceptability judgments after component manipulation is load-bearing for the functional relevance claim. This section should include controls for baseline interventions (e.g., patching random heads) and statistical significance tests to rule out that improvements arise from general capacity changes rather than the identified syntactic mechanisms.
Authors: This is a valid concern for establishing causal relevance. In the revised §6, we have added baseline controls that patch an equal number of randomly selected heads and MLPs, which produce no statistically significant gains on the acceptability benchmarks. We also report paired t-test results (p < 0.01 for the identified components versus random interventions) to confirm that improvements are attributable to the specific mechanisms rather than nonspecific capacity effects. revision: yes
Circularity Check
No significant circularity; claims rest on empirical interventions
full rationale
The paper's central results derive from applying activation patching to isolate contributions of specific heads and MLP blocks to filler-gap and NPI processing, followed by OOD generalization tests and benchmark validation. These are experimental measurements and interventions, not quantities defined in terms of the patching outcomes themselves. No self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations that reduce the localization or generalization claims to the method's own definitions. The derivation chain remains self-contained against external benchmarks and does not invoke uniqueness theorems or ansatzes from prior self-work that would force the reported mechanisms.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Activation patching can causally isolate the contribution of specific attention heads and MLP blocks to syntactic phenomena
Reference graph
Works this paper leans on
-
[1]
Aryaman Arora, Dan Jurafsky, and Christopher Potts. 2024. https://doi.org/10.18653/v1/2024.acl-long.785 C ausal G ym: Benchmarking causal interpretability methods on linguistic tasks . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 14638--14663, Bangkok, Thailand. Association for C...
-
[2]
Stella Biderman, Hailey Schoelkopf, Quentin Gregory Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, and 1 others. 2023. Pythia: A suite for analyzing large language models across training and scaling. In International Conference on Machine Learning, pages 2397--2430. PMLR
2023
-
[3]
Sasha Boguraev, Christopher Potts, and Kyle Mahowald. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.1271 Causal interventions reveal shared structure across E nglish filler -- gap constructions . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 25032--25053, Suzhou, China. Association for Computational L...
-
[4]
Chi-Yun Chang, Xueyang Huang, Humaira Nasir, Shane Storks, Olawale Akingbade, and Huteng Dai. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.761 Mind the gap: How B aby LM s learn filler-gap dependencies . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 15060--15076, Suzhou, China. Association for Comput...
-
[5]
Kevin Clark, Urvashi Khandelwal, Omer Levy, and Christopher D. Manning. 2019. https://doi.org/10.18653/v1/W19-4828 What does BERT look at? an analysis of BERT ' s attention . In Proceedings of the 2019 ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, pages 276--286, Florence, Italy. Association for Computational Linguistics
-
[6]
Manning, Joakim Nivre, and Daniel Zeman
Marie-Catherine de Marneffe, Christopher D. Manning, Joakim Nivre, and Daniel Zeman. 2021. https://doi.org/10.1162/coli_a_00402 U niversal D ependencies . Computational Linguistics, 47(2):255--308
-
[7]
Deanna DeCarlo, William Palmer, Michael Wilson, and Bob Frank. 2023. https://doi.org/10.18653/v1/2023.blackboxnlp-1.25 NPI s aren ' t exactly easy: Variation in licensing across large language models . In Proceedings of the 6th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP, pages 332--341, Singapore. Association for Computationa...
-
[8]
Yanai Elazar, Shauli Ravfogel, Alon Jacovi, and Yoav Goldberg. 2021. https://doi.org/10.1162/tacl_a_00359 Amnesic probing: Behavioral explanation with amnesic counterfactuals . Transactions of the Association for Computational Linguistics, 9:160--175
-
[9]
Matthew Finlayson, Aaron Mueller, Sebastian Gehrmann, Stuart Shieber, Tal Linzen, and Yonatan Belinkov. 2021. https://doi.org/10.18653/v1/2021.acl-long.144 Causal analysis of syntactic agreement mechanisms in neural language models . In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint...
-
[10]
Jaden Fiotto-Kaufman, Alexander R Loftus, Eric Todd, Jannik Brinkmann, Caden Juang, Koyena Pal, Can Rager, Aaron Mueller, Samuel Marks, Arnab Sen Sharma, Francesca Lucchetti, Michael Ripa, Adam Belfki, Nikhil Prakash, Sumeet Multani, Carla Brodley, Arjun Guha, Jonathan Bell, Byron Wallace, and David Bau. 2024. https://arxiv.org/abs/2407.14561 Nnsight and ...
-
[11]
Richard Futrell and Kyle Mahowald. 2025. https://doi.org/10.1017/S0140525X2510112X How linguistics learned to stop worrying and love the language models . Behavioral and Brain Sciences, page 1–98
-
[12]
Atticus Geiger, Hanson Lu, Thomas F Icard, and Christopher Potts. 2021. https://openreview.net/forum?id=RmuXDtjDhG Causal abstractions of neural networks . In Advances in Neural Information Processing Systems
2021
-
[13]
Atticus Geiger, Zhengxuan Wu, Christopher Potts, Thomas Icard, and Noah Goodman. 2024. https://proceedings.mlr.press/v236/geiger24a.html Finding alignments between interpretable causal variables and distributed neural representations . In Proceedings of the Third Conference on Causal Learning and Reasoning, volume 236 of Proceedings of Machine Learning Re...
2024
-
[14]
Gemma Team . 2025. https://goo.gle/Gemma3Report Gemma 3
2025
-
[15]
Anastasia Giannakidou. 1998. Polarity sensitivity as (non) veridical dependency
1998
-
[16]
John Hewitt and Christopher D. Manning. 2019. https://doi.org/10.18653/v1/N19-1419 A structural probe for finding syntax in word representations . In Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) , pages 4129--4138, Minneapol...
-
[17]
Katherine Howitt, Sathvik Nair, Allison Dods, and Robert Melvin Hopkins. 2024. https://doi.org/10.18653/v1/2024.conll-1.21 Generalizations across filler-gap dependencies in neural language models . In Proceedings of the 28th Conference on Computational Natural Language Learning, pages 269--279, Miami, FL, USA. Association for Computational Linguistics
-
[18]
Jennifer Hu, Jon Gauthier, Peng Qian, Ethan Wilcox, and Roger Levy. 2020. https://doi.org/10.18653/v1/2020.acl-main.158 A systematic assessment of syntactic generalization in neural language models . In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 1725--1744, Online. Association for Computational Linguistics
-
[19]
Jaap Jumelet, Milica Denic, Jakub Szymanik, Dieuwke Hupkes, and Shane Steinert-Threlkeld. 2021. https://doi.org/10.18653/v1/2021.findings-acl.439 Language models use monotonicity to assess NPI licensing . In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 4958--4969, Online. Association for Computational Linguistics
-
[20]
Daria Kryvosheieva, Andrea de Varda, Evelina Fedorenko, and Greta Tuckute. 2025. https://arxiv.org/abs/2512.03676 Different types of syntactic agreement recruit the same units within large language models . Preprint, arXiv:2512.03676
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
William Allen Ladusaw. 1979. Polarity sensitivity as inherent scope relations. The University of Texas at Austin
1979
-
[22]
Nur Lan, Emmanuel Chemla, and Roni Katzir. 2024. https://doi.org/10.1162/ling_a_00533 Large language models and the argument from the poverty of the stimulus . Linguistic Inquiry, pages 1--28
-
[23]
Karim Lasri, Tiago Pimentel, Alessandro Lenci, Thierry Poibeau, and Ryan Cotterell. 2022. https://doi.org/10.18653/v1/2022.acl-long.603 Probing for the usage of grammatical number . In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8818--8831, Dublin, Ireland. Association for Computat...
-
[24]
Lovish Madaan, David Esiobu, Pontus Stenetorp, Barbara Plank, and Dieuwke Hupkes. 2025. https://doi.org/10.18653/v1/2025.naacl-long.466 Lost in inference: Rediscovering the role of natural language inference for large language models . In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguis...
-
[25]
Thomas and Pavlick, Ellie and Linzen, Tal
R. Thomas McCoy, Ellie Pavlick, and Tal Linzen. 2019. https://doi.org/10.18653/v1/P19-1334 Right for the wrong reasons: Diagnosing syntactic heuristics in natural language inference . In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 3428--3448, Florence, Italy. Association for Computational Linguistics
-
[26]
Manning, Sampo Pyysalo, Sebastian Schuster, Francis Tyers, and Daniel Zeman
Joakim Nivre, Marie-Catherine de Marneffe, Filip Ginter, Jan Haji c , Christopher D. Manning, Sampo Pyysalo, Sebastian Schuster, Francis Tyers, and Daniel Zeman. 2020. https://aclanthology.org/2020.lrec-1.497/ U niversal D ependencies v2: An evergrowing multilingual treebank collection . In Proceedings of the Twelfth Language Resources and Evaluation Conf...
2020
-
[27]
Satoru Ozaki, Dan Yurovsky, and Lori Levin. 2022. https://aclanthology.org/2022.scil-1.6/ How well do LSTM language models learn filler-gap dependencies? In Proceedings of the Society for Computation in Linguistics 2022, pages 76--88, online. Association for Computational Linguistics
2022
-
[28]
Natalia Silveira, Timothy Dozat, Marie-Catherine de Marneffe, Samuel Bowman, Miriam Connor, John Bauer, and Chris Manning. 2014. https://aclanthology.org/L14-1067/ A gold standard dependency corpus for E nglish . In Proceedings of the Ninth International Conference on Language Resources and Evaluation ( LREC '14) , pages 2897--2904, Reykjavik, Iceland. Eu...
2014
-
[29]
Naoya Ueda, Masato Mita, Teruaki Oka, and Mamoru Komachi. 2024. https://aclanthology.org/2024.lrec-main.1410/ Token-length bias in minimal-pair paradigm datasets . In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 16224--16236, Torino, Italia. ELRA and ICCL
2024
-
[30]
Jesse Vig, Sebastian Gehrmann, Yonatan Belinkov, Sharon Qian, Daniel Nevo, Yaron Singer, and Stuart Shieber. 2020. https://proceedings.neurips.cc/paper_files/paper/2020/file/92650b2e92217715fe312e6fa7b90d82-Paper.pdf Investigating gender bias in language models using causal mediation analysis . In Advances in Neural Information Processing Systems, volume ...
2020
-
[31]
Alex Warstadt, Yu Cao, Ioana Grosu, Wei Peng, Hagen Blix, Yining Nie, Anna Alsop, Shikha Bordia, Haokun Liu, Alicia Parrish, Sheng-Fu Wang, Jason Phang, Anhad Mohananey, Phu Mon Htut, Paloma Jeretic, and Samuel R. Bowman. 2019. https://doi.org/10.18653/v1/D19-1286 Investigating BERT ' s knowledge of language: Five analysis methods with NPI s . In Proceedi...
-
[32]
Alex Warstadt, Alicia Parrish, Haokun Liu, Anhad Mohananey, Wei Peng, Sheng-Fu Wang, and Samuel R. Bowman. 2020. https://doi.org/10.1162/tacl_a_00321 BL i MP : The benchmark of linguistic minimal pairs for E nglish . Transactions of the Association for Computational Linguistics, 8:377--392
-
[33]
Ethan Wilcox, Roger Levy, Takashi Morita, and Richard Futrell. 2018. https://doi.org/10.18653/v1/W18-5423 What do RNN language models learn about filler -- gap dependencies? In Proceedings of the 2018 EMNLP Workshop B lackbox NLP : Analyzing and Interpreting Neural Networks for NLP , pages 211--221, Brussels, Belgium. Association for Computational Linguistics
-
[34]
Ethan Gotlieb Wilcox, Richard Futrell, and Roger Levy. 2024. https://doi.org/10.1162/ling_a_00491 Using computational models to test syntactic learnability . Linguistic Inquiry, 55(4):805--848
-
[35]
Zhengxuan Wu, Atticus Geiger, Aryaman Arora, Jing Huang, Zheng Wang, Noah Goodman, Christopher Manning, and Christopher Potts. 2024 a . https://doi.org/10.18653/v1/2024.naacl-demo.16 pyvene: A library for understanding and improving P y T orch models via interventions . In Proceedings of the 2024 Conference of the North American Chapter of the Association...
-
[36]
Zhengxuan Wu, Atticus Geiger, Jing Huang, Aryaman Arora, Thomas Icard, Christopher Potts, and Noah D. Goodman. 2024 b . https://arxiv.org/abs/2401.12631 A reply to makelov et al. (2023)'s "interpretability illusion" arguments . Preprint, arXiv:2401.12631
-
[37]
Frans Zwarts. 1998. Three types of polarity. In Plurality and quantification, pages 177--238. Springer
1998
-
[38]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[39]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.