Recognition: unknown
Estimating Tail Risks in Language Model Output Distributions
Pith reviewed 2026-05-08 12:23 UTC · model grok-4.3
The pith
Creating unsafe versions of language models allows accurate estimation of rare harmful outputs with 10-20 times fewer samples than brute force.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
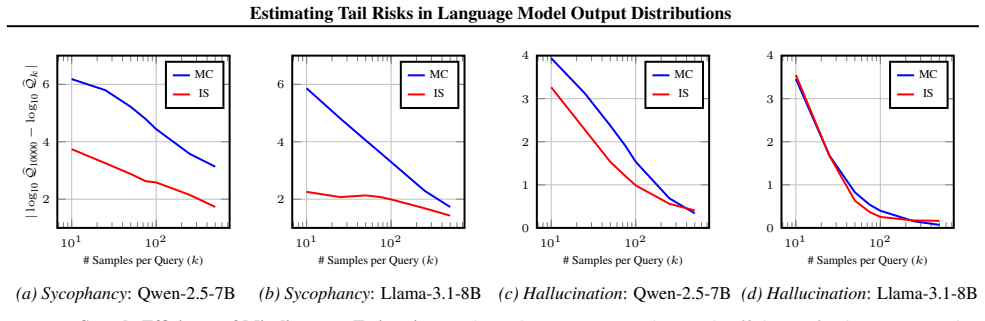
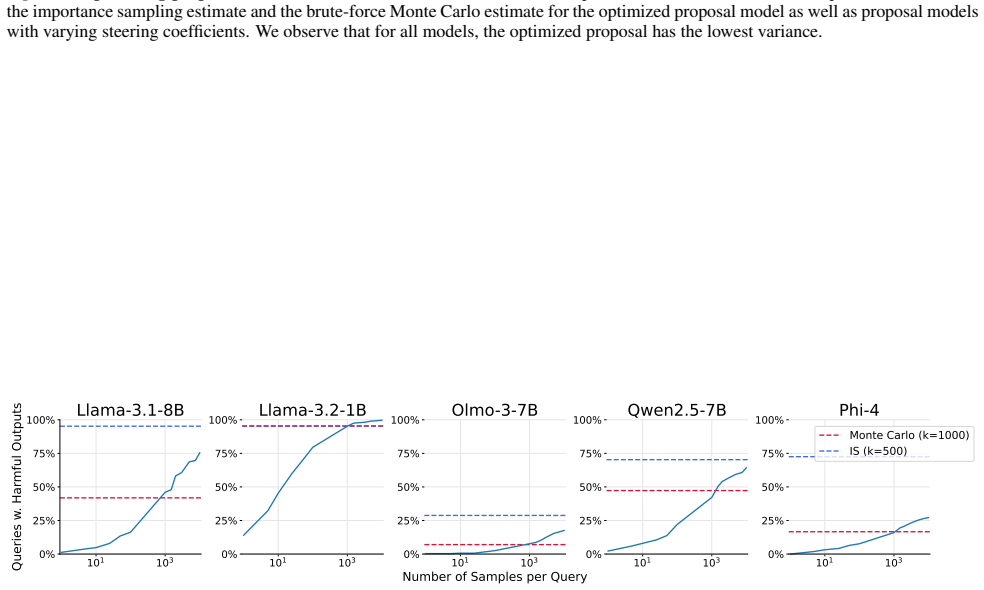
The paper establishes that operationalizing importance sampling through the creation of unsafe variants of the target language model enables sample-efficient estimation of the probability of harmful outputs, achieving accuracy comparable to brute-force Monte Carlo sampling while using 10-20 times fewer samples, such as estimating probabilities around 10 to the power of -4 with only 500 samples.
What carries the argument
Importance sampling performed by constructing unsafe versions of the language model that increase the likelihood of harmful outputs, allowing reweighting to recover the original probabilities.
Load-bearing premise
Unsafe versions of the target model can be constructed so that importance sampling produces unbiased estimates of the original model's probabilities for harmful outputs.
What would settle it
A direct comparison on the same set of inputs where the importance sampling estimates are computed with 500 samples and brute-force Monte Carlo is run with 10,000 or more samples; if the two do not agree within expected statistical variation, the method's accuracy is not supported.
Figures







read the original abstract
Language models are increasingly capable and are being rapidly deployed on a population-level scale. As a result, the safety of these models is increasingly high-stakes. Fortunately, advances in alignment have significantly reduced the likelihood of harmful model outputs. However, when models are queried billions of times in a day, even rare worst-case behaviors will occur. Current safety evaluations focus on capturing the distribution of inputs that yield harmful outputs. These evaluations disregard the probabilistic nature of models and their tail output behavior. To measure this tail risk, we propose a method to efficiently estimate the probability of harmful outputs for any input query. Instead of naive brute-force sampling from the target model, where harmful outputs could be rare, we operationalize importance sampling by creating unsafe versions of the target model. These unsafe versions enable sample-efficient estimation by making harmful outputs more probable. On benchmarks measuring misuse and misalignment, these estimates match brute-force Monte Carlo estimates using 10-20x fewer samples. For example, we can estimate probability of harmful outputs on the order of 10^-4 with just 500 samples. Additionally, we find that these harmfulness estimates can reveal the sensitivity of models to perturbations in model input and predict deployment risks. Our work demonstrates that accurate rare-event estimation is both critical and feasible for safety evaluations. Code is available at https://github.com/rangell/LMTailRisk
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an importance sampling method to estimate tail probabilities of harmful outputs in language models by constructing 'unsafe' versions of the target model as proposal distributions. It claims these estimates match brute-force Monte Carlo on misuse and misalignment benchmarks while using 10-20x fewer samples, e.g., recovering probabilities of order 10^{-4} from 500 proposal samples, and that the estimates can reveal input sensitivity and predict deployment risks.
Significance. If the unbiasedness of the importance sampling procedure holds, the work could meaningfully advance safety evaluations by enabling efficient quantification of rare harmful events at deployment scale. The claimed empirical agreement with Monte Carlo and public code release are positive for reproducibility, but the central claim depends on validation details that are not yet fully substantiated.
major comments (3)
- [Abstract] Abstract: the reported match between IS estimates and brute-force MC lacks specification of the exact MC sample size N, confidence intervals on the MC estimator, or convergence checks across independent runs. For target probabilities p≈10^{-4}, even N=10,000 yields an expected event count of 1 and relative standard error near 100%; without these diagnostics, agreement between two noisy estimators does not confirm that the IS procedure recovers the true tail probability.
- [Methods] Methods (importance sampling construction): the claim that unsafe model variants yield unbiased estimates of the original model's harmful output probabilities requires an explicit derivation showing that the importance weights fully correct for any distributional shift introduced by the modification process. The weakest assumption—that such modifications introduce no systematic bias—must be validated, e.g., via a controlled experiment on a known distribution or a proof that the proposal remains a valid importance sampler.
- [Experiments] Experiments: the manuscript must report data exclusion rules, exact benchmark query sets, and any filtering applied before sampling, because these choices directly affect whether the reported agreement with MC supports the central claim of accurate rare-event estimation across the full output distribution.
minor comments (2)
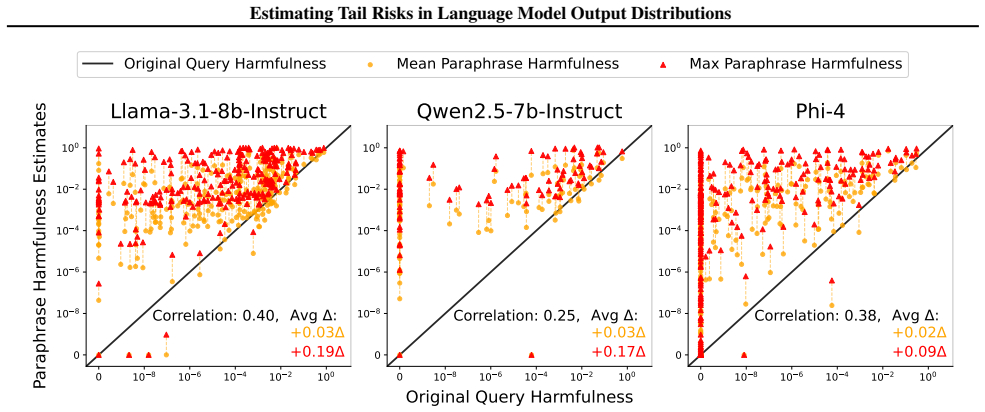
- [Abstract] Abstract: the statement that harmfulness estimates 'can reveal the sensitivity of models to perturbations in model input' would benefit from a concrete example or figure reference in the main text to clarify the operationalization.
- [Appendix] The code repository link is a strength for reproducibility; the manuscript should include a brief methods appendix summarizing the unsafe-model construction hyperparameters so readers can replicate without inspecting the repository.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments, which identify key areas for improving the statistical rigor, theoretical grounding, and transparency of our work. We have revised the manuscript accordingly and address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported match between IS estimates and brute-force MC lacks specification of the exact MC sample size N, confidence intervals on the MC estimator, or convergence checks across independent runs. For target probabilities p≈10^{-4}, even N=10,000 yields an expected event count of 1 and relative standard error near 100%; without these diagnostics, agreement between two noisy estimators does not confirm that the IS procedure recovers the true tail probability.
Authors: We agree that these details are necessary to substantiate the comparison. In the revised manuscript we have added the exact MC sample sizes used (sufficient to observe multiple events for the reported probabilities), bootstrap-derived 95% confidence intervals on the MC estimates, and results from multiple independent runs demonstrating convergence of both estimators. These additions show that the IS estimates lie within the MC confidence intervals. revision: yes
-
Referee: [Methods] Methods (importance sampling construction): the claim that unsafe model variants yield unbiased estimates of the original model's harmful output probabilities requires an explicit derivation showing that the importance weights fully correct for any distributional shift introduced by the modification process. The weakest assumption—that such modifications introduce no systematic bias—must be validated, e.g., via a controlled experiment on a known distribution or a proof that the proposal remains a valid importance sampler.
Authors: We appreciate this request for formal justification. The revised Methods section now contains an explicit derivation establishing that the importance weights w(y) = p_target(y | x) / p_unsafe(y | x) recover the target expectation without bias, provided the unsafe variant preserves support over the target distribution (which holds under our logit-modification and fine-tuning procedures). We have also added a controlled validation on a synthetic autoregressive model with known closed-form tail probabilities, confirming that the estimator is unbiased. revision: yes
-
Referee: [Experiments] Experiments: the manuscript must report data exclusion rules, exact benchmark query sets, and any filtering applied before sampling, because these choices directly affect whether the reported agreement with MC supports the central claim of accurate rare-event estimation across the full output distribution.
Authors: We agree that full experimental transparency is required. The revised Experiments section now specifies the complete benchmark query sets (with sizes and public references), states that no queries were excluded beyond standard length-based truncation, and confirms that no post-sampling filtering on harmfulness or other criteria was applied. All generated outputs were retained for the probability estimates. revision: yes
Circularity Check
No significant circularity; estimator validated externally against Monte Carlo baselines
full rationale
The paper's core contribution is an importance-sampling procedure that constructs unsafe proposal models to estimate rare harmful-output probabilities under the original target model. This follows the standard unbiased IS identity p(harm) = E_proposal[ indicator(harm) * (target_prob / proposal_prob) ], with the proposal obtained by an explicit (non-self-referential) modification step whose bias properties are asserted as an assumption rather than derived from the target quantity. The reported results consist of direct numerical comparisons to independent brute-force Monte Carlo runs on the same benchmarks; no fitted parameter is relabeled as a prediction, no uniqueness theorem is imported from prior self-work, and no ansatz is smuggled via citation. The derivation chain therefore remains self-contained and does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
Abdin, M. et al. Phi-4 technical report. arXiv preprint arXiv:2412.08905, 2024
work page internal anchor Pith review arXiv 2024
-
[3]
Jailbreaking leading safety-aligned LLM s with simple adaptive attacks
Andriushchenko, M., Croce, F., and Flammarion, N. Jailbreaking leading safety-aligned LLM s with simple adaptive attacks. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=hXA8wqRdyV
2025
-
[4]
Claude sonnet 4.5 system card
Anthropic. Claude sonnet 4.5 system card. Technical report, September 2025. URL https://www.anthropic.com/claude-sonnet-4-5-system-card
2025
-
[5]
B., Syed, A., Paleka, D., Rimsky, N., Gurnee, W., and Nanda, N
Arditi, A., Obeso, O. B., Syed, A., Paleka, D., Rimsky, N., Gurnee, W., and Nanda, N. Refusal in language models is mediated by a single direction. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://openreview.net/forum?id=pH3XAQME6c
2024
-
[6]
Emergent misalignment: Narrow finetuning can produce broadly misaligned LLMs, 2025
Betley, J., Tan, D., Warncke, N., Sztyber-Betley, A., Bao, X., Soto, M., Labenz, N., and Evans, O. Emergent misalignment: Narrow finetuning can produce broadly misaligned llms, 2025. URL https://arxiv.org/abs/2502.17424
-
[7]
Jailbreaking Black Box Large Language Models in Twenty Queries
Chao, P., Robey, A., Dobriban, E., Hassani, H., Pappas, G. J., and Wong, E. Jailbreaking black box large language models in twenty queries, 2024. URL https://arxiv.org/abs/2310.08419
work page internal anchor Pith review arXiv 2024
-
[8]
and Diaconis, P
Chatterjee, S. and Diaconis, P. The sample size required in importance sampling. The Annals of Applied Probability, 28 0 (2): 0 1099--1135, 2018
2018
-
[9]
Persona Vectors: Monitoring and Controlling Character Traits in Language Models
Chen, R., Arditi, A., Sleight, H., Evans, O., and Lindsey, J. Persona vectors: Monitoring and controlling character traits in language models, 2025. URL https://arxiv.org/abs/2507.21509
work page internal anchor Pith review arXiv 2025
-
[10]
An introduction to sequential Monte Carlo, volume 4
Chopin, N., Papaspiliopoulos, O., et al. An introduction to sequential Monte Carlo, volume 4. Springer, 2020
2020
-
[11]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Cunningham, H., Ewart, A., Riggs, L., Huben, R., and Sharkey, L. Sparse autoencoders find highly interpretable features in language models, 2023. URL https://arxiv.org/abs/2309.08600
work page internal anchor Pith review arXiv 2023
-
[12]
P., Mannor, S., and Rubinstein, R
De Boer, P.-T., Kroese, D. P., Mannor, S., and Rubinstein, R. Y. A tutorial on the cross-entropy method. Annals of operations research, 134 0 (1): 0 19--67, 2005
2005
-
[13]
and Ferreira, A
De Haan, L. and Ferreira, A. Extreme value theory: an introduction. Springer, 2006
2006
-
[14]
Dubey, A., Grattafiori, A., Jauhri, A., et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review arXiv 2024
-
[15]
Ettinger, A. et al. Olmo 3. arXiv preprint arXiv:2512.13961, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Alignment faking in large language models
Greenblatt, R., Denison, C., Wright, B., Roger, F., MacDiarmid, M., Marks, S., Treutlein, J., Belonax, T., Chen, J., Duvenaud, D., Khan, A., Michael, J., Mindermann, S., Perez, E., Petrini, L., Uesato, J., Kaplan, J., Shlegeris, B., Bowman, S. R., and Hubinger, E. Alignment faking in large language models, 2024 a . URL https://arxiv.org/abs/2412.14093
work page internal anchor Pith review arXiv 2024
-
[17]
AI control: Improving safety despite intentional subversion,
Greenblatt, R., Shlegeris, B., Sachan, K., and Roger, F. Ai control: Improving safety despite intentional subversion, 2024 b . URL https://arxiv.org/abs/2312.06942
-
[18]
Hesterberg, T. C. Advances in importance sampling. Stanford University, 1988
1988
-
[19]
Catastrophic jailbreak of open-source llms via exploiting generation
Huang, Y., Gupta, S., Xia, M., Li, K., and Chen, D. Catastrophic jailbreak of open-source llms via exploiting generation, 2023. URL https://arxiv.org/abs/2310.06987
-
[20]
Catastrophic jailbreak of open-source LLM s via exploiting generation
Huang, Y., Gupta, S., Xia, M., Li, K., and Chen, D. Catastrophic jailbreak of open-source LLM s via exploiting generation. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=r42tSSCHPh
2024
-
[21]
Hughes, J., Price, S., Lynch, A., Schaeffer, R., Barez, F., Koyejo, S., Sleight, H., Jones, E., Perez, E., and Sharma, M. Best-of-n jailbreaking, 2024. URL https://arxiv.org/abs/2412.03556
-
[22]
Forecasting rare language model behaviors
Jones, E., Tong, M., Mu, J., Mahfoud, M., Leike, J., Grosse, R., Kaplan, J., Fithian, W., Perez, E., and Sharma, M. Forecasting rare language model behaviors. arXiv preprint arXiv:2502.16797, 2025
-
[23]
L., Chowdhury, N., Johnson, D
Li, X. L., Chowdhury, N., Johnson, D. D., Hashimoto, T., Liang, P., Schwettmann, S., and Steinhardt, J. Eliciting language model behaviors with investigator agents. In Forty-second International Conference on Machine Learning, 2025. URL https://openreview.net/forum?id=AulTigiaMv
2025
-
[24]
E., Vorobeychik, Y., Mao, Z., Jha, S., McDaniel, P., Sun, H., Li, B., and Xiao, C
Liu, X., Li, P., Suh, G. E., Vorobeychik, Y., Mao, Z., Jha, S., McDaniel, P., Sun, H., Li, B., and Xiao, C. Auto DAN -turbo: A lifelong agent for strategy self-exploration to jailbreak LLM s. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=bhK7U37VW8
2025
-
[25]
Natural emergent misalignment from reward hacking in production rl, 2025
MacDiarmid, M., Wright, B., Uesato, J., Benton, J., Kutasov, J., Price, S., Bouscal, N., Bowman, S., Bricken, T., Cloud, A., Denison, C., Gasteiger, J., Greenblatt, R., Leike, J., Lindsey, J., Mikulik, V., Perez, E., Rodrigues, A., Thomas, D., Webson, A., Ziegler, D., and Hubinger, E. Natural emergent misalignment from reward hacking in production rl, 202...
-
[26]
and Tegmark, M
Marks, S. and Tegmark, M. The geometry of truth: Emergent linear structure in large language model representations of true/false datasets. In First Conference on Language Modeling, 2024. URL https://openreview.net/forum?id=aajyHYjjsk
2024
-
[27]
Tdc 2023 (llm edition): The trojan detection challenge
Mazeika, M., Zou, A., Mu, N., Phan, L., Wang, Z., Yu, C., Khoja, A., Jiang, F., O'Gara, A., Sakhaee, E., Xiang, Z., Rajabi, A., Hendrycks, D., Poovendran, R., Li, B., and Forsyth, D. Tdc 2023 (llm edition): The trojan detection challenge. In NeurIPS Competition Track, 2023
2023
-
[28]
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
Mazeika, M., Phan, L., Yin, X., Zou, A., Wang, Z., Mu, N., Sakhaee, E., Li, N., Basart, S., Li, B., Forsyth, D., and Hendrycks, D. Harmbench: A standardized evaluation framework for automated red teaming and robust refusal, 2024. URL https://arxiv.org/abs/2402.04249
work page internal anchor Pith review arXiv 2024
-
[29]
Neumann, A., Kirsten, E., Zafar, M. B., and Singh, J. Position is power: System prompts as a mechanism of bias in large language models (llms). In Proceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency, FAccT ’25, pp.\ 573–598. ACM, June 2025. doi:10.1145/3715275.3732038. URL http://dx.doi.org/10.1145/3715275.3732038
-
[30]
Steering language model refusal with sparse autoencoders.arXiv preprint arXiv:2411.11296, 2024
O'Brien, K., Majercak, D., Fernandes, X., Edgar, R., Bullwinkel, B., Chen, J., Nori, H., Carignan, D., Horvitz, E., and Poursabzi-Sangdeh, F. Steering language model refusal with sparse autoencoders, 2025. URL https://arxiv.org/abs/2411.11296
-
[31]
Update to gpt-5 system card: Gpt-5.2
OpenAI. Update to gpt-5 system card: Gpt-5.2. Technical report, December 2025 a . URL https://openai.com/index/gpt-5-system-card-update-gpt-5-2/
2025
-
[32]
gpt-oss-120b & gpt-oss-20b Model Card
OpenAI. gpt-oss-120b and gpt-oss-20b model card, 2025 b . URL https://arxiv.org/abs/2508.10925
work page internal anchor Pith review arXiv 2025
-
[33]
and Zhou, Y
Owen, A. and Zhou, Y. Safe and effective importance sampling. Journal of the American Statistical Association, 95 0 (449): 0 135--143, 2000
2000
-
[34]
Panickssery, N., Gabrieli, N., Schulz, J., Tong, M., Hubinger, E., and Turner, A. M. Steering llama 2 via contrastive activation addition, 2024. URL https://arxiv.org/abs/2312.06681
work page internal anchor Pith review arXiv 2024
-
[35]
P., Casella, G., and Casella, G
Robert, C. P., Casella, G., and Casella, G. Monte Carlo statistical methods, volume 2. Springer, 1999
1999
- [36]
-
[37]
A strong REJECT for empty jailbreaks
Souly, A., Lu, Q., Bowen, D., Trinh, T., Hsieh, E., Pandey, S., Abbeel, P., Svegliato, J., Emmons, S., Watkins, O., and Toyer, S. A strong REJECT for empty jailbreaks. In The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2024. URL https://openreview.net/forum?id=KZLE5BaaOH
2024
-
[38]
Taori, R., Gulrajani, I., Zhang, T., Dubois, Y., Li, X., Guestrin, C., Liang, P., and Hashimoto, T. B. Stanford alpaca: An instruction-following llama model. https://github.com/tatsu-lab/stanford_alpaca, 2023
2023
-
[39]
Team, G. et al. Gemma: Open models based on gemini research and technology, 2024. URL https://arxiv.org/abs/2403.08295
work page internal anchor Pith review arXiv 2024
-
[40]
Qwen2.5: A party of foundation models, September 2024
Team, Q. Qwen2.5: A party of foundation models, September 2024. URL https://qwenlm.github.io/blog/qwen2.5/
2024
-
[41]
Estimating worst-case frontier risks of open-weight llms, 2025
Wallace, E., Watkins, O., Wang, M., Chen, K., and Koch, C. Estimating worst-case frontier risks of open-weight llms, 2025. URL https://arxiv.org/abs/2508.03153
-
[42]
Wu, G. and Hilton, J. Estimating the probabilities of rare outputs in language models. arXiv preprint arXiv:2410.13211, 2024
-
[43]
Grok 3 beta — the age of reasoning agents, February 2025
xAI. Grok 3 beta — the age of reasoning agents, February 2025. URL https://x.ai/news/grok-3. Accessed: 2026-01-27
2025
-
[44]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Zou, A., Wang, Z., Carlini, N., Nasr, M., Kolter, J. Z., and Fredrikson, M. Universal and transferable adversarial attacks on aligned language models, 2023. URL https://arxiv.org/abs/2307.15043
work page internal anchor Pith review arXiv 2023
-
[45]
@esa (Ref
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[46]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[47]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.