Recognition: unknown
MCI: A Maximal Clique Index for Efficient Arbitrary-Filtered Approximate Nearest Neighbor Search
Pith reviewed 2026-05-08 09:20 UTC · model grok-4.3
The pith
The Maximal Clique Index uses clique covers to compress neighbor graphs for efficient arbitrary-filtered approximate nearest neighbor search.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that approximating a dense Nearest Neighbor Graph with a compact representation based on maximal cliques allows for robust and efficient AFANNS. The Maximal Clique Cover exploits geometric transitivity to encode dense neighborhoods, while Local Neighborhood Graph Geometric Densification builds the structure from a sparse starting point by increasing distance thresholds locally. The index is constructed in parallel and queried with a multi-seed strategy to manage fragmented subgraphs from predicates, resulting in superior query performance and reduced space.
What carries the argument
Maximal Clique Cover, which groups dense neighborhoods into maximal cliques to achieve high compression and connectivity in the index for filtered searches.
If this is right
- The index supports arbitrary filtering predicates in a general way without needing separate indexes for different filter types.
- Query throughput increases by up to an order of magnitude at high recall levels while memory footprint decreases.
- The construction scales well due to its lock-free parallel design.
- The multi-seed query strategy effectively deals with predicate-induced fragmentation of the graph.
Where Pith is reading between the lines
- This clique-based compression could be tested on other high-dimensional similarity search tasks beyond nearest neighbors.
- Adapting the densification technique might help in scenarios with evolving data where graphs need periodic rebuilding.
- The assumption of geometric transitivity suggests potential use in domains like image retrieval where point distributions follow similar patterns.
Load-bearing premise
The geometric transitivity property of high-dimensional spaces allows dense neighborhoods to be encoded as maximal cliques without major loss in approximation quality for filtered searches.
What would settle it
Compare the recall achieved by the MCI index versus a standard nearest neighbor graph index on a dataset of randomly generated high-dimensional vectors that lack clustered structure, to see if the clique method still maintains its advantages.
Figures


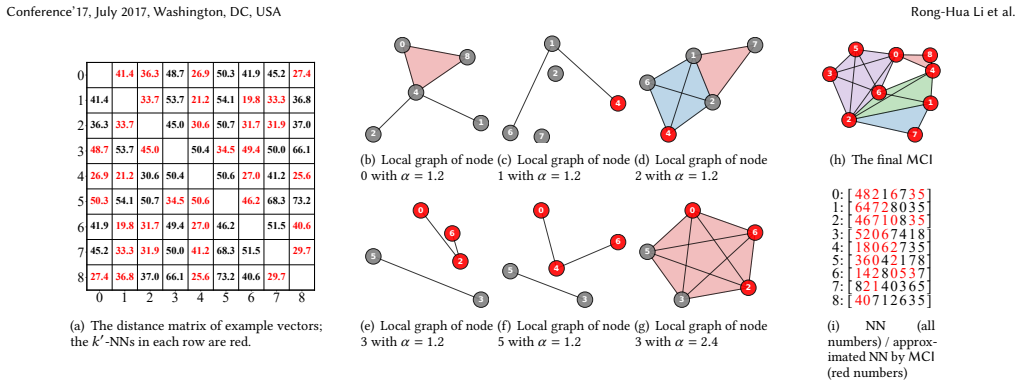
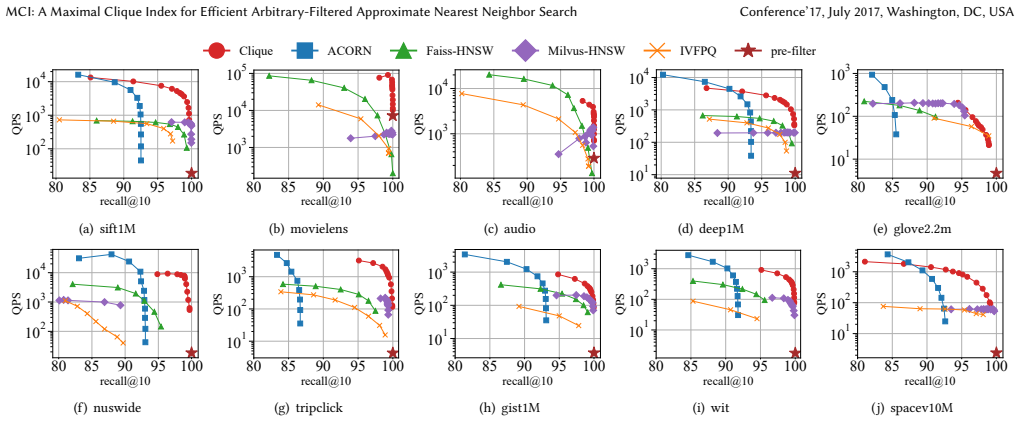
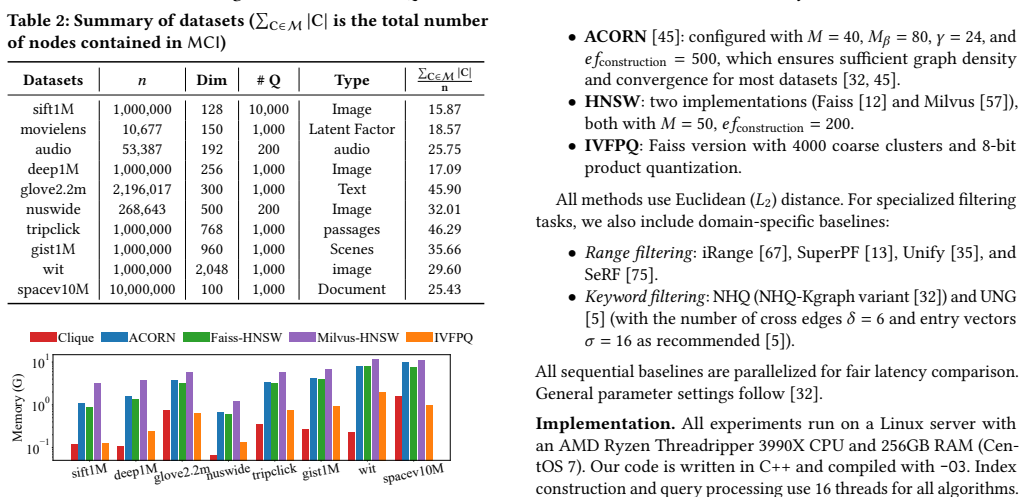

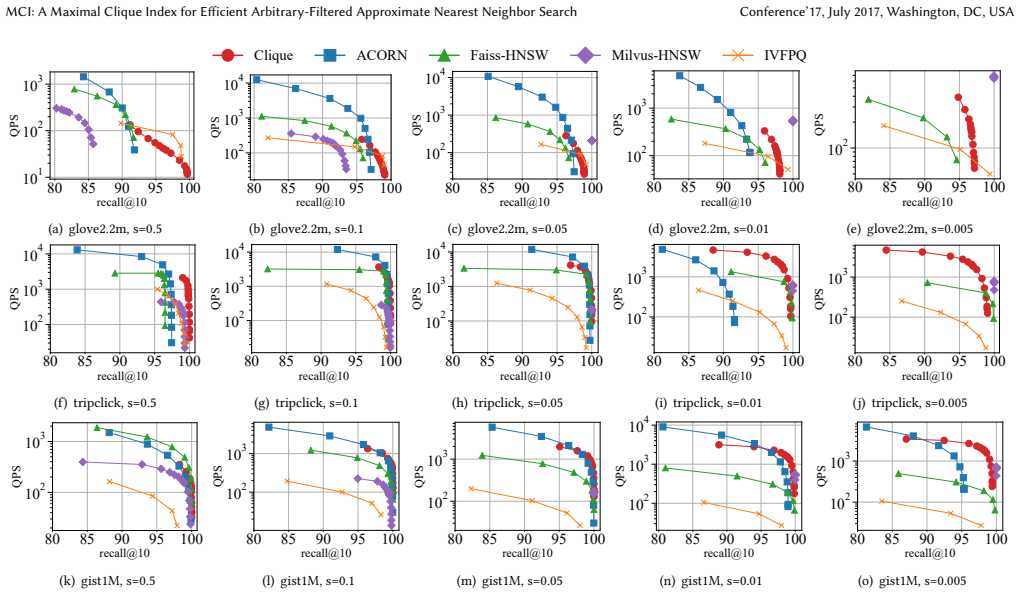







read the original abstract
Approximate Nearest Neighbor Search with arbitrary filtering predicates (AFANNS) is essential for modern data applications, yet existing methods often incur substantial storage and computational costs. In this work, we introduce the Maximal Clique Index (\mci), a novel graph-based index designed for robust and efficient AFANNS. The core idea of \mci is to approximate a dense Nearest Neighbor Graph (NNG) through a compact, clique-based representation. We propose two key techniques: (1) Maximal Clique Cover (\mcc), which exploits the geometric transitivity of high-dimensional spaces to encode dense neighborhoods as maximal cliques, achieving an index with high compression and connectivity; and (2) Local Neighborhood Graph Geometric Densification, a strategy that constructs an index approximating a large NNG from a sparse initial NNG, recovers global connectivity by progressively increasing distance thresholds to locally densify the structure. The index is built in a lock-free parallel manner for scalability and queried via a carefully-designed multi-seed strategy to handle fragmented predicate-induced subgraphs. Extensive experiments on 10 datasets show that \mci significantly outperforms state-of-the-art methods by up to one order of magnitude in QPS at high recall while using substantially smaller space, and remains competitive even on range/keyword filtering tasks, demonstrating robust general-purpose performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Maximal Clique Index (MCI) for approximate nearest neighbor search under arbitrary filtering predicates (AFANNS). It approximates a dense nearest-neighbor graph via Maximal Clique Cover (MCC), which encodes neighborhoods as maximal cliques by exploiting geometric transitivity, combined with Local Neighborhood Graph Geometric Densification to recover connectivity from a sparse initial graph. The index supports lock-free parallel construction and a multi-seed query strategy for handling predicate-induced fragmentation. Experiments on 10 datasets report up to 10x higher QPS at high recall versus state-of-the-art methods, with substantially smaller space and competitive results on range/keyword filtering.
Significance. If the performance claims and underlying connectivity assumptions hold under verification, MCI would constitute a meaningful advance for filtered high-dimensional search by delivering a compact index with strong query throughput. The lock-free parallel build and multi-seed strategy for fragmented subgraphs address practical scalability needs. Credit is due for the scale of the evaluation (10 datasets) and the attempt to handle arbitrary predicates rather than narrow filter types.
major comments (2)
- [Abstract] Abstract: the central claim that MCC 'exploits the geometric transitivity of high-dimensional spaces to encode dense neighborhoods as maximal cliques, achieving an index with high compression and connectivity' is load-bearing for the reported QPS gains and space savings, yet no formal bound, approximation-error analysis, or quantification of omitted edges is supplied. High-dimensional distance concentration can weaken transitivity, risking loss of cross-neighborhood edges that become critical once predicates fragment the graph.
- [Abstract / §3] Abstract / §3 (MCC and densification): the manuscript invokes 'progressively increasing distance thresholds' for densification but provides neither the exact schedule nor a parameter count for these thresholds, nor any empirical sensitivity analysis. This directly affects reproducibility of the 'substantially smaller space' and 'high recall' results under filtering.
minor comments (1)
- [Abstract] Abstract: the phrase 'arbitrary-filtered' is used without a concise definition or taxonomy of supported predicate classes beyond the range/keyword examples mentioned later.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. We appreciate the recognition of the work's significance, the lock-free construction, multi-seed query strategy, and the scale of the 10-dataset evaluation. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that MCC 'exploits the geometric transitivity of high-dimensional spaces to encode dense neighborhoods as maximal cliques, achieving an index with high compression and connectivity' is load-bearing for the reported QPS gains and space savings, yet no formal bound, approximation-error analysis, or quantification of omitted edges is supplied. High-dimensional distance concentration can weaken transitivity, risking loss of cross-neighborhood edges that become critical once predicates fragment the graph.
Authors: We agree that the claim is central and that the absence of a formal bound or approximation-error analysis is a limitation. Deriving a tight theoretical bound on omitted edges under high-dimensional distance concentration is challenging and would require substantial additional theoretical development beyond the scope of this systems-oriented paper. The manuscript instead supports the claim through empirical results across 10 datasets, including connectivity preservation under filtering. We will revise the abstract to qualify the claim as empirically supported and add a new paragraph in Section 3 quantifying the fraction of edges retained by the maximal clique cover relative to a dense NNG, along with a short discussion of distance concentration and how densification addresses fragmentation. revision: partial
-
Referee: [Abstract / §3] Abstract / §3 (MCC and densification): the manuscript invokes 'progressively increasing distance thresholds' for densification but provides neither the exact schedule nor a parameter count for these thresholds, nor any empirical sensitivity analysis. This directly affects reproducibility of the 'substantially smaller space' and 'high recall' results under filtering.
Authors: This observation is correct; the current manuscript describes the progressive densification at a conceptual level without specifying the exact threshold schedule, the number of parameters, or sensitivity results. We will revise Section 3 to document the precise schedule and parameter count used in the experiments, and we will add an empirical sensitivity analysis (in the main text or appendix) showing the impact on space and recall. These additions will directly improve reproducibility. revision: yes
- A formal bound or approximation-error analysis for the geometric transitivity assumption in MCC under high-dimensional distance concentration, as this lies outside the current scope of the applied paper.
Circularity Check
No significant circularity; algorithmic construction is self-contained
full rationale
The paper presents MCI as an algorithmic index built via Maximal Clique Cover (exploiting geometric transitivity) and Local Neighborhood Graph Geometric Densification to approximate a dense NNG from a sparse one, followed by multi-seed querying. These steps are constructive procedures grounded in graph properties and stated assumptions about high-dimensional spaces, with performance claims backed by experiments across 10 datasets. No equations, fitted parameters, or derivations reduce by construction to their own inputs. No self-citation chains or ansatz smuggling are load-bearing in the provided description. The derivation chain does not collapse into tautology or statistical forcing.
Axiom & Free-Parameter Ledger
free parameters (1)
- distance thresholds
axioms (1)
- domain assumption High-dimensional spaces exhibit geometric transitivity that permits dense neighborhoods to be represented as maximal cliques
invented entities (1)
-
Maximal Clique Index (MCI)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Razenshteyn, and Ludwig Schmidt
Alexandr Andoni, Piotr Indyk, Thijs Laarhoven, Ilya P. Razenshteyn, and Ludwig Schmidt. 2015. Practical and Optimal LSH for Angular Distance. InNIPS. 1225– 1233
2015
-
[2]
Fabien André, Anne-Marie Kermarrec, and Nicolas Le Scouarnec. 2017. Acceler- ated Nearest Neighbor Search with Quick ADC. InICMR. ACM, 159–166
2017
-
[3]
Akhil Arora, Sakshi Sinha, Piyush Kumar, and Arnab Bhattacharya. 2018. HD- Index: Pushing the Scalability-Accuracy Boundary for Approximate kNN Search in High-Dimensional Spaces.Proc. VLDB Endow.11, 8 (2018), 906–919
2018
-
[4]
Fedor Borisyuk, Siddarth Malreddy, Jun Mei, Yiqun Liu, Xiaoyi Liu, Piyush Ma- heshwari, Anthony Bell, and Kaushik Rangadurai. 2021. VisRel: Media Search at Scale. InSIGKDD. ACM, 2584–2592
2021
-
[5]
Yuzheng Cai, Jiayang Shi, Yizhuo Chen, and Weiguo Zheng. 2024. Navigating La- bels and Vectors: A Unified Approach to Filtered Approximate Nearest Neighbor Search.Proc. ACM Manag. Data2, 6 (2024), 246:1–246:27
2024
-
[6]
Manos Chatzakis, Panagiota Fatourou, Eleftherios Kosmas, Themis Palpanas, and Botao Peng. 2023. Odyssey: A Journey in the Land of Distributed Data Series Similarity Search.Proc. VLDB Endow.16, 5 (2023), 1140–1153
2023
-
[7]
Sean Wang
Meng Chen, Kai Zhang, Zhenying He, Yinan Jing, and X. Sean Wang. 2024. RoarGraph: A Projected Bipartite Graph for Efficient Cross-Modal Approximate Nearest Neighbor Search.Proc. VLDB Endow.17, 11 (2024), 2735–2749
2024
-
[8]
Chen, Wei-Cheng Chang, Jyun-Yu Jiang, Hsiang-Fu Yu, Inderjit S
Patrick H. Chen, Wei-Cheng Chang, Jyun-Yu Jiang, Hsiang-Fu Yu, Inderjit S. Dhillon, and Cho-Jui Hsieh. 2023. FINGER: Fast Inference for Graph-based Approximate Nearest Neighbor Search. InWWW. ACM, 3225–3235
2023
-
[9]
Abhinandan Das, Mayur Datar, Ashutosh Garg, and Shyamsundar Rajaram. 2007. Google news personalization: scalable online collaborative filtering. InWWW. ACM, 271–280
2007
-
[10]
Liwei Deng, Penghao Chen, Ximu Zeng, Tianfu Wang, Yan Zhao, and Kai Zheng. 2024. Efficient Data-aware Distance Comparison Operations for High- Dimensional Approximate Nearest Neighbor Search.Proc. VLDB Endow.18, 3 (2024), 812–821
2024
-
[11]
Wei Dong, Moses Charikar, and Kai Li. 2011. Efficient k-nearest neighbor graph construction for generic similarity measures. InWWW 2011. ACM, 577–586
2011
-
[12]
Matthijs Douze, Alexandr Guzhva, Chengqi Deng, Jeff Johnson, Gergely Szilvasy, Pierre-Emmanuel Mazaré, Maria Lomeli, Lucas Hosseini, and Hervé Jégou. 2024. The Faiss library. (2024). arXiv:2401.08281 [cs.LG]
work page internal anchor Pith review arXiv 2024
-
[13]
Joshua Engels, Benjamin Landrum, Shangdi Yu, Laxman Dhulipala, and Julian Shun. 2024. Approximate Nearest Neighbor Search with Window Filters. InForty- first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net
2024
-
[14]
Wenqi Fan, Yujuan Ding, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, and Qing Li. 2024. A Survey on RAG Meeting LLMs: Towards Retrieval-Augmented Large Language Models. InSIGKDD. ACM, 6491–6501
2024
- [15]
-
[16]
Cong Fu, Changxu Wang, and Deng Cai. 2022. High Dimensional Similarity Search With Satellite System Graph: Efficiency, Scalability, and Unindexed Query Compatibility.IEEE Trans. Pattern Anal. Mach. Intell.44, 8 (2022), 4139–4150
2022
-
[17]
Cong Fu, Chao Xiang, Changxu Wang, and Deng Cai. 2019. Fast Approximate Nearest Neighbor Search With The Navigating Spreading-out Graph.Proc. VLDB Endow.12, 5 (2019), 461–474
2019
-
[18]
Yujian Fu, Cheng Chen, Yao Chen, Weng-Fai Wong, and Bingsheng He. 2025. Vista: Vector Indexing and Search for Large-Scale Imbalanced Datasets. InICDE. IEEE, 543–556
2025
-
[19]
Jianyang Gao, Yutong Gou, Yuexuan Xu, Yongyi Yang, Cheng Long, and Ray- mond Chi-Wing Wong. 2025. Practical and Asymptotically Optimal Quantization of High-Dimensional Vectors in Euclidean Space for Approximate Nearest Neigh- bor Search.Proc. ACM Manag. Data3, 3 (2025), 202:1–202:26
2025
-
[20]
Jianyang Gao and Cheng Long. 2023. High-Dimensional Approximate Nearest Neighbor Search: with Reliable and Efficient Distance Comparison Operations. Proc. ACM Manag. Data1, 2 (2023), 137:1–137:27
2023
-
[21]
Jianyang Gao and Cheng Long. 2024. RaBitQ: Quantizing High-Dimensional Vectors with a Theoretical Error Bound for Approximate Nearest Neighbor Search. Proc. ACM Manag. Data2, 3 (2024), 167
2024
-
[22]
Siddharth Gollapudi, Neel Karia, Varun Sivashankar, Ravishankar Krishnaswamy, Nikit Begwani, Swapnil Raz, Yiyong Lin, Yin Zhang, Neelam Mahapatro, Premku- mar Srinivasan, Amit Singh, and Harsha Vardhan Simhadri. 2023. Filtered- DiskANN: Graph Algorithms for Approximate Nearest Neighbor Search with Filters. InWWW. ACM, 3406–3416
2023
-
[23]
Yutong Gou, Jianyang Gao, Yuexuan Xu, and Cheng Long. 2025. SymphonyQG: Towards Symphonious Integration of Quantization and Graph for Approximate Nearest Neighbor Search.Proc. ACM Manag. Data3, 1 (2025), 80:1–80:26
2025
-
[24]
Ben Harwood and Tom Drummond. 2016. FANNG: Fast Approximate Nearest Neighbour Graphs. InCVPR. 5713–5722
2016
-
[25]
Ville Hyvönen, Elias Jääsaari, and Teemu Roos. 2024. A Multilabel Classification Framework for Approximate Nearest Neighbor Search.J. Mach. Learn. Res.25 (2024), 46:1–46:51
2024
-
[26]
Elias Jääsaari, Ville Hyvönen, and Teemu Roos. 2024. LoRANN: Low-Rank Matrix Factorization for Approximate Nearest Neighbor Search. InNIPS
2024
-
[27]
Suhas Jayaram Subramanya, Fnu Devvrit, Harsha Vardhan Simhadri, Ravishankar Krishnawamy, and Rohan Kadekodi. 2019. DiskANN: Fast Accurate Billion-point Nearest Neighbor Search on a Single Node. InAdvances in Neural Information Processing Systems, Vol. 32. Curran Associates, Inc
2019
-
[28]
Hervé Jégou, Matthijs Douze, and Cordelia Schmid. 2011. Product Quantization for Nearest Neighbor Search.IEEE Trans. Pattern Anal. Mach. Intell.33, 1 (2011), 117–128
2011
-
[29]
Mengxu Jiang, Zhi Yang, Fangyuan Zhang, Guanhao Hou, Jieming Shi, Wenchao Zhou, Feifei Li, and Sibo Wang. 2025. DIGRA: A Dynamic Graph Indexing for Approximate Nearest Neighbor Search with Range Filter.Proc. ACM Manag. Data 3, 3 (2025), 148:1–148:26. doi:10.1145/3725399
-
[30]
Zhongming Jin, Debing Zhang, Yao Hu, Shiding Lin, Deng Cai, and Xiaofei He
-
[31]
IEEE Trans
Fast and Accurate Hashing Via Iterative Nearest Neighbors Expansion. IEEE Trans. Cybern.44, 11 (2014), 2167–2177
2014
-
[32]
Oh, and Jae W
Sungjun Jung, Yongsang Park, Haeun Lee, Young H. Oh, and Jae W. Lee. 2025. Angular Distance-Guided Neighbor Selection for Graph-Based Approximate Nearest Neighbor Search. InWWW. ACM, 4014–4023
2025
-
[33]
Mocheng Li, Xiao Yan, Baotong Lu, Yue Zhang, James Cheng, and Chenhao Ma
-
[34]
ACM Manag
Attribute Filtering in Approximate Nearest Neighbor Search: An In-depth Experimental Study.Proc. ACM Manag. Data3, 6 (2025), 1–26
2025
-
[35]
Wen Li, Ying Zhang, Yifang Sun, Wei Wang, Mingjie Li, Wenjie Zhang, and Xuemin Lin. 2020. Approximate Nearest Neighbor Search on High Dimensional Data - Experiments, Analyses, and Improvement.TKDE32, 8 (2020), 1475–1488
2020
-
[36]
Zhaoheng Li, Silu Huang, Wei Ding, Yongjoo Park, and Jianjun Chen. 2025. SIEVE: Effective Filtered Vector Search with Collection of Indexes.Proc. VLDB Endow. 18, 11 (2025), 4723–4736
2025
-
[37]
Anqi Liang, Pengcheng Zhang, Bin Yao, Zhongpu Chen, Yitong Song, and Guangxu Cheng. 2024. UNIFY: Unified Index for Range Filtered Approximate Nearest Neighbors Search.Proc. VLDB Endow.18, 4 (2024), 1118–1130
2024
-
[38]
Zihan Liu, Wentao Ni, Jingwen Leng, Yu Feng, Cong Guo, Quan Chen, Chao Li, Minyi Guo, and Yuhao Zhu. 2024. JUNO: Optimizing High-Dimensional Approximate Nearest Neighbour Search with Sparsity-Aware Algorithm and Ray-Tracing Core Mapping. InASPLOS. ACM, 549–565
2024
-
[39]
Kejing Lu, Chuan Xiao, and Yoshiharu Ishikawa. 2024. Probabilistic Routing for Graph-Based Approximate Nearest Neighbor Search. InICML. OpenReview.net
2024
-
[40]
Jiarui Luo, Miao Qiao, Chaoji Zuo, and Dong Deng. 2025. Tag-Filtered Approx- imate Nearest Neighbor Search. In41st IEEE International Conference on Data Engineering, ICDE. MCI: A Maximal Clique Index for Efficient Arbitrary-Filtered Approximate Nearest Neighbor Search Conference’17, July 2017, Washington, DC, USA
2025
-
[41]
Yury Malkov, Alexander Ponomarenko, Andrey Logvinov, and Vladimir Krylov
-
[42]
Syst.45 (2014), 61–68
Approximate nearest neighbor algorithm based on navigable small world graphs.Inf. Syst.45 (2014), 61–68
2014
-
[43]
Malkov and Dmitry A
Yury A. Malkov and Dmitry A. Yashunin. 2020. Efficient and Robust Approximate Nearest Neighbor Search Using Hierarchical Navigable Small World Graphs.IEEE Trans. Pattern Anal. Mach. Intell.42, 4 (2020), 824–836
2020
-
[44]
Blelloch, Laxman Dhulipala, Yan Gu, Harsha Vardhan Simhadri, and Yihan Sun
Magdalen Dobson Manohar, Zheqi Shen, Guy E. Blelloch, Laxman Dhulipala, Yan Gu, Harsha Vardhan Simhadri, and Yihan Sun. 2024. ParlayANN: Scalable and Deterministic Parallel Graph-Based Approximate Nearest Neighbor Search Algorithms. InPPoPP. ACM, 270–285
2024
-
[45]
Ilyas, Umar Farooq Minhas, Jeffrey Pound, and Theodoros Rekatsinas
Jason Mohoney, Anil Pacaci, Shihabur Rahman Chowdhury, Ali Mousavi, Ihab F. Ilyas, Umar Farooq Minhas, Jeffrey Pound, and Theodoros Rekatsinas. 2023. High- Throughput Vector Similarity Search in Knowledge Graphs.Proc. ACM Manag. Data1, 2 (2023), 197:1–197:25
2023
-
[46]
Javier Alvaro Vargas Muñoz, Marcos André Gonçalves, Zanoni Dias, and Ricardo da Silva Torres. 2019. Hierarchical Clustering-Based Graphs for Large Scale Approximate Nearest Neighbor Search.Pattern Recognit.96 (2019)
2019
-
[47]
Hiroyuki Ootomo, Akira Naruse, Corey Nolet, Ray Wang, Tamas Feher, and Yong Wang. 2024. CAGRA: Highly Parallel Graph Construction and Approximate Nearest Neighbor Search for GPUs. InICDE. IEEE, 4236–4247
2024
-
[48]
Liana Patel, Peter Kraft, Carlos Guestrin, and Matei Zaharia. 2024. ACORN: Per- formant and Predicate-Agnostic Search Over Vector Embeddings and Structured Data.Proc. ACM Manag. Data2, 3 (2024), 120
2024
-
[49]
Yun Peng, Byron Choi, Tsz Nam Chan, Jianye Yang, and Jianliang Xu. 2023. Efficient Approximate Nearest Neighbor Search in Multi-dimensional Databases. Proc. ACM Manag. Data1, 1 (2023), 54:1–54:27
2023
-
[50]
Zhencan Peng, Miao Qiao, Wenchao Zhou, Feifei Li, and Dong Deng. 2025. Dy- namic Range-Filtering Approximate Nearest Neighbor Search.Proc. VLDB Endow. 18, 10 (2025), 3256–3268
2025
-
[51]
Chanop Silpa-Anan and Richard I. Hartley. 2008. Optimised KD-trees for fast image descriptor matching. InCVPR. IEEE Computer Society
2008
-
[52]
Bing Tian, Haikun Liu, Zhuohui Duan, Xiaofei Liao, Hai Jin, and Yu Zhang. 2024. Scalable Billion-point Approximate Nearest Neighbor Search Using SmartSSDs. InUSENIX ATC. USENIX Association, 1135–1150
2024
-
[53]
Yao Tian, Xi Zhao, and Xiaofang Zhou. 2024. DB-LSH 2.0: Locality-Sensitive Hashing With Query-Based Dynamic Bucketing.IEEE Trans. Knowl. Data Eng. 36, 3 (2024), 1000–1015
2024
-
[54]
Etsuji Tomita, Akira Tanaka, and Haruhisa Takahashi. 2006. The worst-case time complexity for generating all maximal cliques and computational experiments. Theor. Comput. Sci.363, 1 (2006), 28–42
2006
-
[56]
Toussaint
Godfried T. Toussaint. 1980. The relative neighbourhood graph of a finite planar set.Pattern Recognit.12, 4 (1980), 261–268
1980
-
[57]
R. v. Mises. 1942. On the Correct Use of Bayes’ Formula.The Annals of Mathe- matical Statistics13, 2 (1942), 156 – 165
1942
-
[58]
Thomas Vecchiato, Claudio Lucchese, Franco Maria Nardini, and Sebastian Bruch
-
[59]
A Learning-to-Rank Formulation of Clustering-Based Approximate Nearest Neighbor Search. InSIGIR. ACM, 2261–2265
-
[60]
2018.High-Dimensional Probability: An Introduction with Applications in Data Science
Roman Vershynin. 2018.High-Dimensional Probability: An Introduction with Applications in Data Science. Cambridge University Press
2018
-
[61]
Jianguo Wang, Xiaomeng Yi, Rentong Guo, Hai Jin, Peng Xu, Shengjun Li, Xi- angyu Wang, Xiangzhou Guo, Chengming Li, Xiaohai Xu, et al. 2021. Milvus: A Purpose-Built Vector Data Management System. InProceedings of the 2021 International Conference on Management of Data. 2614–2627
2021
-
[62]
Mengzhao Wang, Lingwei Lv, Xiaoliang Xu, Yuxiang Wang, Qiang Yue, and Jiongkang Ni. 2023. An Efficient and Robust Framework for Approximate Nearest Neighbor Search with Attribute Constraint. InNIPS
2023
-
[63]
Mengzhao Wang, Xiaoliang Xu, Qiang Yue, and Yuxiang Wang. 2021. A Com- prehensive Survey and Experimental Comparison of Graph-Based Approximate Nearest Neighbor Search.Proc. VLDB Endow.14, 11 (2021), 1964–1978
2021
-
[64]
Yitu Wang, Shiyu Li, Qilin Zheng, Linghao Song, Zongwang Li, Andrew Chang, Hai Li, and Yiran Chen. 2024. NDSEARCH: Accelerating Graph-Traversal-Based Approximate Nearest Neighbor Search through Near Data Processing. InISCA. IEEE, 368–381
2024
-
[65]
Yi Wang, Huan Liu, Jianan Yuan, Jiaxian Chen, Tianyu Wang, Chenlin Ma, and Rui Mao. 2024. Leanor: A Learning-Based Accelerator for Efficient Approximate Nearest Neighbor Search via Reduced Memory Access. InDAC. ACM, 61:1–61:6
2024
-
[66]
Zeyu Wang, Qitong Wang, Xiaoxing Cheng, Peng Wang, Themis Palpanas, and Wei Wang. 2024. Steiner-Hardness: A Query Hardness Measure for Graph-Based ANN Indexes.Proc. VLDB Endow.17, 13 (2024), 4668–4682
2024
-
[67]
Zeyu Wang, Haoran Xiong, Qitong Wang, Zhenying He, Peng Wang, Themis Palpanas, and Wei Wang. 2024. Dimensionality-Reduction Techniques for Ap- proximate Nearest Neighbor Search: A Survey and Evaluation.IEEE Data Eng. Bull.48, 3 (2024), 63–80
2024
-
[68]
Jiuqi Wei, Xiaodong Lee, Zhenyu Liao, Themis Palpanas, and Botao Peng. 2025. Subspace Collision: An Efficient and Accurate Framework for High-dimensional Approximate Nearest Neighbor Search.Proc. ACM Manag. Data3, 1 (2025), 79:1–79:29
2025
-
[69]
Jiuqi Wei, Botao Peng, Xiaodong Lee, and Themis Palpanas. 2024. DET-LSH: A Locality-Sensitive Hashing Scheme with Dynamic Encoding Tree for Approxi- mate Nearest Neighbor Search.Proc. VLDB Endow.17, 9 (2024), 2241–2254
2024
-
[70]
Jiadong Xie, Jeffrey Xu Yu, Siyi Teng, and Yingfan Liu. 2025. Beyond Vector Search: Querying With and Without Predicates.Proc. ACM Manag. Data3, 6 (2025), 1–26. doi:10.1145/3769765
-
[71]
Yuexuan Xu, Jianyang Gao, Yutong Gou, Cheng Long, and Christian S. Jensen
-
[72]
ACM Manag
iRangeGraph: Improvising Range-dedicated Graphs for Range-filtering Nearest Neighbor Search.Proc. ACM Manag. Data2, 6 (2024), 239:1–239:26
2024
-
[73]
Ming Yang, Yuzheng Cai, and Weiguo Zheng. 2024. CSPG: Crossing Sparse Proximity Graphs for Approximate Nearest Neighbor Search. InNIPS
2024
-
[74]
Xiaowei Ye, Rong-Hua Li, and Guoren Wang. 2025. The Power of Core Clique Removal for Exact Clique Enumeration.Proc. ACM Manag. Data3, 4 (2025), 269:1–269:27
2025
-
[75]
Ziqi Yin, Jianyang Gao, Pasquale Balsebre, Gao Cong, and Cheng Long. 2025. DEG: Efficient Hybrid Vector Search Using the Dynamic Edge Navigation Graph. Proc. ACM Manag. Data3, 1 (2025), 29:1–29:28
2025
-
[76]
Qiang Yue, Xiaoliang Xu, Yuxiang Wang, Yikun Tao, and Xuliyuan Luo. 2024. Routing-Guided Learned Product Quantization for Graph-Based Approximate Nearest Neighbor Search. InICDE. IEEE, 4870–4883
2024
-
[77]
Fangyuan Zhang, Mengxu Jiang, Guanhao Hou, Jieming Shi, Hua Fan, Wenchao Zhou, Feifei Li, and Sibo Wang. 2025. Efficient Dynamic Indexing for Range Filtered Approximate Nearest Neighbor Search.Proc. ACM Manag. Data3, 3 (2025), 152:1–152:26. doi:10.1145/3725401
-
[78]
Xi Zhao, Yao Tian, Kai Huang, Bolong Zheng, and Xiaofang Zhou. 2023. Towards Efficient Index Construction and Approximate Nearest Neighbor Search in High- Dimensional Spaces.Proc. VLDB Endow.16, 8 (2023), 1979–1991
2023
-
[79]
Bolong Zheng, Xi Zhao, Lianggui Weng, Quoc Viet Hung Nguyen, Hang Liu, and Christian S. Jensen. 2022. PM-LSH: a fast and accurate in-memory framework for high-dimensional approximate NN and closest pair search.VLDB J.31, 6 (2022), 1339–1363
2022
-
[80]
Chaoji Zuo, Miao Qiao, Wenchao Zhou, Feifei Li, and Dong Deng. 2024. SeRF: Segment Graph for Range-Filtering Approximate Nearest Neighbor Search.Proc. ACM Manag. Data2, 1 (2024), 69:1–69:26. Conference’17, July 2017, Washington, DC, USA Rong-Hua Li et al. 80 85 90 95 100 recall@10 103 QPS 6 8 10 12 (a) Various quality of𝑘 ′-NNG 80 85 90 95 100 recall@10 1...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.