Recognition: unknown
Optimal Investment and Entropy-Regularized Learning Under Stochastic Volatility Models with Portfolio Constraints
Pith reviewed 2026-05-08 08:53 UTC · model grok-4.3
The pith
Optimal exploratory investment policies under stochastic volatility and constraints are truncated Gaussian distributions derived from a nonlinear PDE solution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The optimal exploratory policy takes the form of a truncated Gaussian distribution characterized by spatial derivatives of the solution of the resulting nonlinear quasilinear parabolic partial differential equation. Under suitable structural conditions on the model coefficients, classical solutions to this nonlinear HJB equation exist for the value function, a verification theorem holds, and the policy-improvement structure induced by the entropy-regularized Hamiltonian supplies a continuous-time interpretation of actor-critic learning dynamics that enables an implementable algorithm via martingale methods.
What carries the argument
The entropy-regularized Hamilton-Jacobi-Bellman equation obtained by optimizing over probability measures on the compact set of admissible allocations, whose solution yields the truncated Gaussian policy through its spatial derivatives.
If this is right
- The value function and optimal policy are obtained by solving the nonlinear quasilinear parabolic PDE.
- Iterating the policy-improvement structure produces a sequence of improving policies that mirrors actor-critic updates.
- Recasting the problem in a martingale framework converts the PDE solution into a practical reinforcement learning algorithm.
- The same derivation applies to any continuous-time investment problem whose control set is compact and whose running reward includes an entropy term.
Where Pith is reading between the lines
- The explicit Gaussian form may allow closed-form updates in low-dimensional cases, reducing the need for function approximation in the critic.
- The martingale reformulation could be combined with existing numerical PDE solvers to create hybrid model-based RL methods for finance.
- Similar entropy-regularized HJB equations might arise in other constrained stochastic control problems outside portfolio selection.
Load-bearing premise
The drift, volatility, and correlation functions satisfy structural conditions that guarantee existence of classical solutions to the nonlinear quasilinear parabolic PDE.
What would settle it
A stochastic volatility model obeying the stated structural conditions on coefficients for which the entropy-regularized HJB equation nevertheless admits no classical solution, or a numerical test in which the derived truncated Gaussian policy fails to maximize the entropy-regularized objective on simulated paths.
Figures
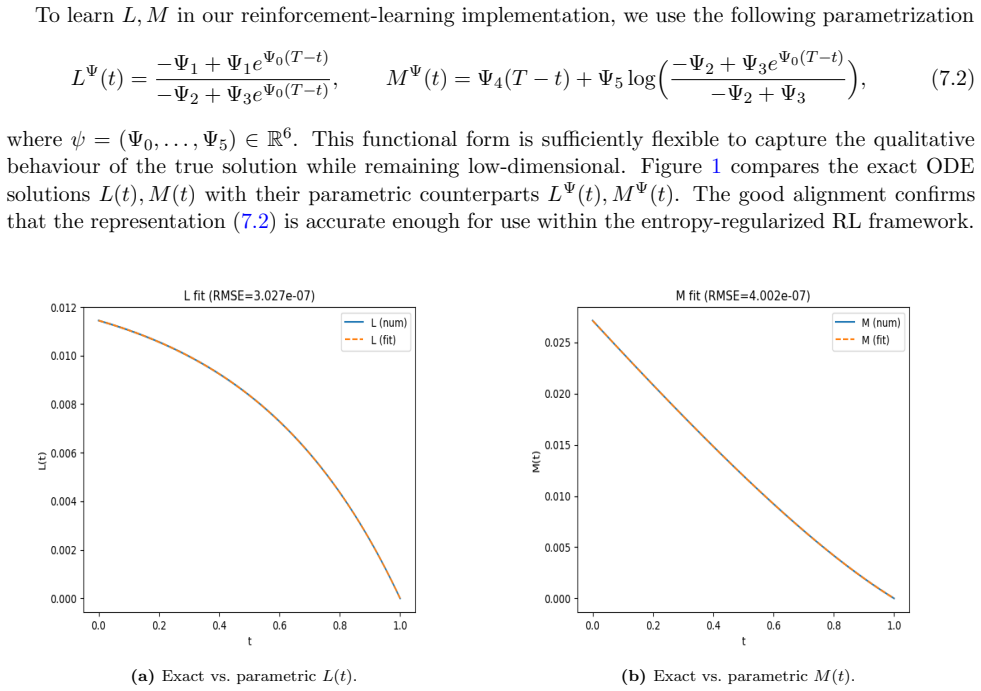

read the original abstract
We study the problem of optimal portfolio selection under stochastic volatility within a continuous time reinforcement learning framework with portfolio constraints. Exploration is modeled through entropy-regularized relaxed controls, where the investor selects probability distributions over admissible portfolio allocations rather than deterministic strategies. Using dynamic programming arguments, we derive the associated entropy-regularized Hamilton-Jacobi-Bellman equation, whose Hamiltonian involves optimization over probability measures supported on a compact control set. We show that the optimal exploratory policy takes the form of a truncated Gaussian distribution characterized by spatial derivatives of the solution of the resulting nonlinear quasilinear parabolic partial differential equation. Under suitable structural conditions on the model coefficients, we prove the existence of classical solutions to this nonlinear HJB equation for the value function. We then establish a verification theorem and analyze the policy-improvement structure induced by the entropy-regularized Hamiltonian, showing how the resulting sequence of PDEs provides a continuous-time interpretation of actor-critic learning dynamics. Finally, our PDE analysis with a semi-closed form of optimal value and optimal policy enables the design of an implementable reinforcement learning algorithm by recasting the optimal problem in a martingale framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops a continuous-time reinforcement learning approach to optimal portfolio selection under stochastic volatility models with constraints. Exploration is incorporated via entropy-regularized relaxed controls over admissible allocations. Dynamic programming yields an entropy-regularized HJB equation whose Hamiltonian is optimized over probability measures; the resulting optimal exploratory policy is shown to be a truncated Gaussian whose parameters depend on spatial derivatives of the value function. Under suitable structural conditions on the coefficients, classical solutions to the resulting nonlinear quasilinear parabolic PDE are proved to exist. A verification theorem is established, the policy-improvement structure is analyzed as a continuous-time actor-critic dynamics, and the problem is recast in a martingale framework to yield an implementable RL algorithm.
Significance. If the central results hold, the work supplies a rigorous dynamic-programming and verification foundation for entropy-regularized RL in constrained stochastic-volatility portfolio problems, together with an explicit policy characterization and a martingale reformulation that directly supports algorithm design. The continuous-time actor-critic interpretation and the semi-closed-form elements are genuine strengths that could facilitate both theoretical extensions and practical implementations.
major comments (1)
- [Abstract] Abstract: the existence of classical solutions to the nonlinear quasilinear parabolic HJB PDE is asserted only under unspecified “suitable structural conditions on the model coefficients.” No explicit hypotheses (uniform ellipticity, growth bounds, monotonicity, or Lipschitz requirements) are stated, nor are they verified for standard stochastic-volatility specifications such as Heston or SABR. Because the verification theorem, the truncated-Gaussian policy characterization, and the subsequent policy-improvement analysis all presuppose these classical solutions, the gap is load-bearing for the central claims.
minor comments (1)
- [Abstract] The abstract refers to a “semi-closed form of optimal value and optimal policy,” yet the precise split between closed-form expressions and quantities that must be obtained numerically is not clarified in the provided summary.
Simulated Author's Rebuttal
We thank the referee for the constructive comment and positive overall assessment of the manuscript. We address the concern regarding the abstract below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the existence of classical solutions to the nonlinear quasilinear parabolic HJB PDE is asserted only under unspecified “suitable structural conditions on the model coefficients.” No explicit hypotheses (uniform ellipticity, growth bounds, monotonicity, or Lipschitz requirements) are stated, nor are they verified for standard stochastic-volatility specifications such as Heston or SABR. Because the verification theorem, the truncated-Gaussian policy characterization, and the subsequent policy-improvement analysis all presuppose these classical solutions, the gap is load-bearing for the central claims.
Authors: We agree that the abstract would benefit from greater precision on this point. The structural conditions (uniform ellipticity of the generator, boundedness and Lipschitz continuity of the coefficients in the state variables, and suitable growth restrictions) are stated explicitly in Assumption 3.1 and used in Theorem 4.1 to invoke standard existence theory for quasilinear parabolic equations. In the revised manuscript we will update the abstract to name these hypotheses and to note that they are satisfied by the Heston model under the usual parameter restrictions that guarantee positivity and mean reversion. For the SABR model the degeneracy at zero volatility lies outside the current framework; we will add a brief remark acknowledging this limitation and indicating that a separate analysis would be required. These clarifications will be confined to the abstract and the statement of Assumption 3.1, leaving the verification theorem and policy characterization unchanged. revision: yes
Circularity Check
No circularity: derivation chain from dynamic programming to HJB, verification, and policy analysis is self-contained.
full rationale
The paper proceeds from dynamic programming to derive the entropy-regularized HJB PDE, characterizes the optimal exploratory policy explicitly as a truncated Gaussian in terms of the value function's spatial derivatives, invokes standard structural conditions on coefficients to obtain classical solutions, and proves a verification theorem plus policy-improvement structure. None of these steps reduce the claimed results to fitted parameters, self-defined quantities, or load-bearing self-citations; the martingale reformulation for the RL algorithm follows directly from the PDE analysis without circular renaming or imported uniqueness theorems. The derivation is therefore independent of the authors' prior work and does not exhibit any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The underlying stochastic volatility model admits well-defined solutions under the given portfolio constraints and entropy regularization.
- ad hoc to paper Suitable structural conditions on the model coefficients guarantee classical solvability of the nonlinear quasilinear parabolic PDE.
Reference graph
Works this paper leans on
-
[1]
Simulation of square-root processes made simple: applications to the Heston model
Abi Jaber, E., 2024. Simulation of square-root processes made simple: applications to the Heston model. ArXiv preprint arXiv:2412.11264
-
[2]
Machine learning and speed in high frequency trading
Arifovic, J., He, X.Z., Wei, L., 2022. Machine learning and speed in high frequency trading. Journal of Economic Dynamics and Control 139, 104438
2022
-
[3]
Reinforcement learning for household finance: Designing policy via responsiveness
Bandyopadhyay, A.P., Maliar, L., 2026. Reinforcement learning for household finance: Designing policy via responsiveness. Journal of Economic Dynamics and Control 182, 105229
2026
-
[4]
Heterogeneous trading strategies with adaptive fuzzy actor–critic reinforce- ment learning: A behavioral approach
Bekiros, S.D., 2010. Heterogeneous trading strategies with adaptive fuzzy actor–critic reinforce- ment learning: A behavioral approach. Journal of Economic Dynamics and Control 34, 1153–1170
2010
-
[5]
Continuous time reinforcement learning: A random measure approach
Bender, C., Nguyen, T., 2026. Continuous time reinforcement learning: A random measure approach. Stochastic Processes and their Applications 194, 104848
2026
-
[6]
Applications of variational inequalities in stochastic control
Bensoussan, A., Lions, J.L., 2011. Applications of variational inequalities in stochastic control. volume 12. Elsevier
2011
-
[7]
Risk-sensitive dynamic asset management
Bielecki, T.R., Pliska, S.R., 1999. Risk-sensitive dynamic asset management. Applied Mathematics and Optimization 39, 337–360
1999
-
[8]
Consumption and portfolio decisions when expected returns are time varying
Campbell, J.Y., Viceira, L.M., 1999. Consumption and portfolio decisions when expected returns are time varying. Quarterly Journal of Economics 114, 433–495
1999
-
[9]
Dynamic consumption and portfolio choice with stochastic volatility in incomplete markets
Chacko, G., Viceira, L.M., 2005. Dynamic consumption and portfolio choice with stochastic volatility in incomplete markets. Review of Financial Studies 18, 1369–1402
2005
-
[10]
Continuous-time optimal investment with portfolio constraints: A reinforcement learning approach
Chau, H., Nguyen, D., Nguyen, T., 2026. Continuous-time optimal investment with portfolio constraints: A reinforcement learning approach. European Journal of Operational Research 328, 1068–1092
2026
-
[11]
Learning, information processing and order submission in limit order markets
Chiarella, C., He, X.Z., Wei, L., 2015. Learning, information processing and order submission in limit order markets. Journal of Economic Dynamics and Control 61, 245–268
2015
-
[12]
User’s guide to viscosity solutions of second order partial differential equations
Crandall, M.G., Ishii, H., Lions, P.L., 1992. User’s guide to viscosity solutions of second order partial differential equations. Bulletin of the American Mathematical Society 27, 1–67
1992
-
[13]
Viscosity solutions of Hamilton–Jacobi equations
Crandall, M.G., Lions, P.L., 1983. Viscosity solutions of Hamilton–Jacobi equations. Transactions of the American Mathematical Society 277, 1–42
1983
-
[14]
Optimal consumption and equilibrium prices with portfolio constraints and stochastic income
Cuoco, D., 1997. Optimal consumption and equilibrium prices with portfolio constraints and stochastic income. Journal of Economic Theory 72, 33–73
1997
-
[15]
Convex duality in constrained portfolio optimization
Cvitani´ c, J., Karatzas, I., 1992. Convex duality in constrained portfolio optimization. Annals of Applied Probability 2, 767–818
1992
-
[16]
Hedging contingent claims with constrained portfolios
Cvitani´ c, J., Karatzas, I., 1993. Hedging contingent claims with constrained portfolios. Annals of Applied Probability 3, 652–681. 36
1993
-
[17]
Dai, M., Dong, Y., Jia, Y., Zhou, X.Y., 2023. Learning Merton’s strategies in an incom- plete market: recursive entropy regularization and biased Gaussian exploration. arXiv preprint arXiv:2303.14931
-
[18]
Large deviations for Markov processes and the asymptotic evaluation of certain Markov process expectations for large times, in: Probabilistic Methods in Differential Equations
Donsker, M.D., Varadhan, S.R.S., 2006. Large deviations for Markov processes and the asymptotic evaluation of certain Markov process expectations for large times, in: Probabilistic Methods in Differential Equations. Springer, pp. 82–88
2006
-
[19]
Reinforcement learning in continuous time and space
Doya, K., 2000. Reinforcement learning in continuous time and space. Neural Computation 12, 219–245
2000
-
[20]
Stochastic differential utility
Duffie, D., Epstein, L.G., 1992. Stochastic differential utility. Econometrica 60, 353–394
1992
-
[21]
Backward stochastic differential equations in finance
El Karoui, N., Peng, S., Quenez, M.C., 1997. Backward stochastic differential equations in finance. Mathematical Finance 7, 1–71
1997
-
[22]
Controlled Markov processes and viscosity solutions
Fleming, W.H., Soner, H.M., 2006. Controlled Markov processes and viscosity solutions. vol- ume 25. 2nd ed., Springer
2006
-
[23]
Reinforcement learning for jump-diffusions, with financial applications
Gao, X., Li, L., Zhou, X.Y., 2024. Reinforcement learning for jump-diffusions, with financial applications. Mathematical Finance Forthcoming
2024
-
[24]
Robust control and model uncertainty
Hansen, L.P., Sargent, T.J., 2001. Robust control and model uncertainty. American Economic Review 91, 60–66
2001
-
[25]
A closed-form solution for options with stochastic volatility with applications to bond and currency options
Heston, S.L., 1993. A closed-form solution for options with stochastic volatility with applications to bond and currency options. Review of Financial Studies 6, 327–343
1993
-
[26]
Policy evaluation and temporal-difference learning in continuous time and space: A martingale approach
Jia, Y., Zhou, X.Y., 2022. Policy evaluation and temporal-difference learning in continuous time and space: A martingale approach. Journal of Machine Learning Research 23, 1–55
2022
-
[27]
Policy gradient and actor-critic learning in continuous time and space: Theory and algorithms
Jia, Y., Zhou, X.Y., 2022. Policy gradient and actor-critic learning in continuous time and space: Theory and algorithms. Journal of Machine Learning Research 23, 1–50
2022
-
[28]
Continuous multivariate distributions
Johnson, N.L., Kotz, S., Balakrishnan, N., 2002. Continuous multivariate distributions. volume 1. Wiley
2002
-
[29]
small investor
Karatzas, I., Lehoczky, J.P., Shreve, S.E., 1987. Optimal portfolio and consumption decisions for a “small investor” on a finite horizon. SIAM Journal on Control and Optimization 25, 1557–1586
1987
-
[30]
Methods of mathematical finance
Karatzas, I., Shreve, S.E., 1998. Methods of mathematical finance. volume 39. Springer
1998
-
[31]
Optimal consumption from investment and random endowment in incomplete semimartingale markets
Karatzas, I., ˇZitkovi´ c, G., 2003. Optimal consumption from investment and random endowment in incomplete semimartingale markets. Annals of Probability 31, 1821–1858
2003
-
[32]
Dynamic nonmyopic portfolio behavior
Kim, T.S., Omberg, E., 1996. Dynamic nonmyopic portfolio behavior. Review of Financial Studies 9, 141–161
1996
-
[33]
Optimal portfolios and Heston’s stochastic volatility model: an explicit solution for power utility
Kraft, H., 2005. Optimal portfolios and Heston’s stochastic volatility model: an explicit solution for power utility. Quantitative Finance 5, 303–313
2005
-
[34]
Nonlinear elliptic and parabolic equations of the second order
Krylov, N.V., 1987. Nonlinear elliptic and parabolic equations of the second order. Springer
1987
-
[35]
Numerical methods for stochastic control problems in continuous time
Kushner, H.J., 1990. Numerical methods for stochastic control problems in continuous time. SIAM Journal on Control and Optimization 28, 999–1048. 37
1990
-
[36]
Linear and quasi-linear equations of parabolic type
Ladyzhenskaya, O.A., Solonnikov, V.A., Ural’tseva, N.N., 1968. Linear and quasi-linear equations of parabolic type. volume 23. American Mathematical Society
1968
-
[37]
Introduction au calcul stochastique appliqu´ e ` a la finance
Lamberton, D., Lapeyre, B., 1997. Introduction au calcul stochastique appliqu´ e ` a la finance. Ellipses
1997
-
[38]
Second order parabolic differential equations
Lieberman, G.M., 1996. Second order parabolic differential equations. World Scientific
1996
-
[39]
Portfolio selection in stochastic environments
Liu, J., 2007. Portfolio selection in stochastic environments. Review of Financial Studies 20, 1–39
2007
-
[40]
Robust portfolio rules and asset pricing
Maenhout, P.J., 2004. Robust portfolio rules and asset pricing. Review of Financial Studies 17, 951–983
2004
-
[41]
Robust portfolio rules and detection-error probabilities for a mean-reverting risk premium
Maenhout, P.J., 2006. Robust portfolio rules and detection-error probabilities for a mean-reverting risk premium. Journal of Economic Theory 128, 136–163
2006
-
[42]
Lifetime portfolio selection under uncertainty: The continuous-time case
Merton, R.C., 1969. Lifetime portfolio selection under uncertainty: The continuous-time case. Review of Economics and Statistics 51, 247–257
1969
-
[43]
Optimum consumption and portfolio rules in a continuous-time model, in: Ziemba, W.T., Vickson, R.G
Merton, R.C., 1975. Optimum consumption and portfolio rules in a continuous-time model, in: Ziemba, W.T., Vickson, R.G. (Eds.), Stochastic Optimization Models in Finance. Academic Press, pp. 621–661
1975
-
[44]
On estimating the expected return on the market: An exploratory investiga- tion
Merton, R.C., 1980. On estimating the expected return on the market: An exploratory investiga- tion. Journal of Financial Economics 8, 323–361
1980
-
[45]
Backward stochastic differential equations and quasilinear parabolic partial differential equations, in: Stochastic Partial Differential Equations and Their Applications
Pardoux, ´E., Peng, S., 2005. Backward stochastic differential equations and quasilinear parabolic partial differential equations, in: Stochastic Partial Differential Equations and Their Applications. Springer, pp. 200–217
2005
-
[46]
Portfolio selection and asset pricing models
P´ astor,ˇL., 2000. Portfolio selection and asset pricing models. Journal of Finance 55, 179–223
2000
-
[47]
Applications to partial differential equations—nonlinear equations, in: Semigroups of Linear Operators and Applications to Partial Differential Equations
Pazy, A., 1983. Applications to partial differential equations—nonlinear equations, in: Semigroups of Linear Operators and Applications to Partial Differential Equations. Springer, pp. 230–251
1983
-
[48]
Probabilistic interpretation for systems of quasilinear parabolic partial differential equations
Peng, S., 1991. Probabilistic interpretation for systems of quasilinear parabolic partial differential equations. Stochastics and Stochastics Reports 37, 61–74
1991
-
[49]
A generalized dynamic programming principle and Hamilton–Jacobi–Bellman equation
Peng, S., 1992. A generalized dynamic programming principle and Hamilton–Jacobi–Bellman equation. Stochastics and Stochastic Reports 38, 119–134
1992
-
[50]
Continuous-time stochastic control and optimization with financial applications
Pham, H., 2009. Continuous-time stochastic control and optimization with financial applications. volume 61 ofStochastic Modelling and Applied Probability. Springer
2009
-
[51]
Stochastic optimal control as approximate in- ference: A new perspective, in: Proceedings of the International Conference on Machine Learning (ICML)
Rawlik, K., Toussaint, M., Vijayakumar, S., 2013. Stochastic optimal control as approximate in- ference: A new perspective, in: Proceedings of the International Conference on Machine Learning (ICML)
2013
-
[52]
Estimation of parameters of doubly truncated normal distri- bution from first four sample moments
Shah, S.M., Jaiswal, M.C., 1966. Estimation of parameters of doubly truncated normal distri- bution from first four sample moments. Annals of the Institute of Statistical Mathematics 18, 107–111
1966
-
[53]
Optimal investment and consumption with transaction costs
Shreve, S.E., Soner, H.M., 1994. Optimal investment and consumption with transaction costs. Annals of Applied Probability 4, 609–692
1994
-
[54]
Reinforcement learning: An introduction
Sutton, R.S., Barto, A.G., 1998. Reinforcement learning: An introduction. MIT Press. 38
1998
-
[55]
Efficient computation of optimal actions
Todorov, E., 2009. Efficient computation of optimal actions. Proceedings of the National Academy of Sciences 106, 11478–11483
2009
-
[56]
Reinforcement learning in continuous time and space: A stochastic control approach
Wang, H., Zariphopoulou, T., Zhou, X.Y., 2020. Reinforcement learning in continuous time and space: A stochastic control approach. Journal of Machine Learning Research 21, 1–34
2020
-
[57]
Continuous-time mean–variance portfolio selection: A reinforcement learning framework
Wang, H., Zhou, X.Y., 2020. Continuous-time mean–variance portfolio selection: A reinforcement learning framework. Mathematical Finance 30, 1273–1308
2020
-
[58]
Reinforcement learning for continuous-time mean-variance portfolio selection in a regime-switching market
Wu, B., Li, L., 2024. Reinforcement learning for continuous-time mean-variance portfolio selection in a regime-switching market. Journal of Economic Dynamics and Control 158, 104787
2024
-
[59]
Stochastic controls: Hamiltonian systems and HJB equations
Yong, J., Zhou, X.Y., 1999. Stochastic controls: Hamiltonian systems and HJB equations. vol- ume 43. Springer Science & Business Media. Appendix A. Auxiliary lemmas Lemma 4(Donsker–Varadhan variational formula [18]).Let(Θ,F, P)be a probability space, and let h: Θ→Rbe a measurable function such thate h ∈L 1(P). Then lnE P h eh i = sup Q≪P {EQ[h]−KL(Q∥P)},(...
1999
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.