Recognition: unknown
How Large Language Models Balance Internal Knowledge with User and Document Assertions
Pith reviewed 2026-05-08 11:48 UTC · model grok-4.3
The pith
Large language models prefer document assertions over user assertions in three-source conflicts, with post-training reinforcing this bias.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
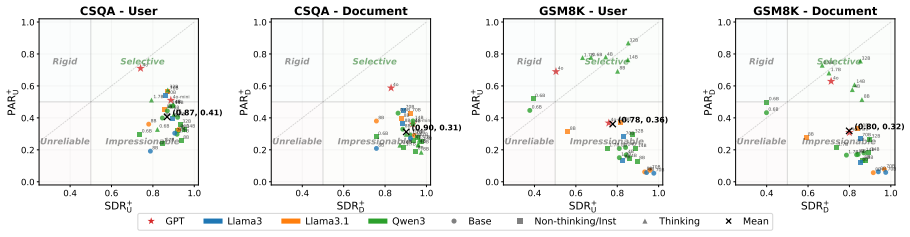
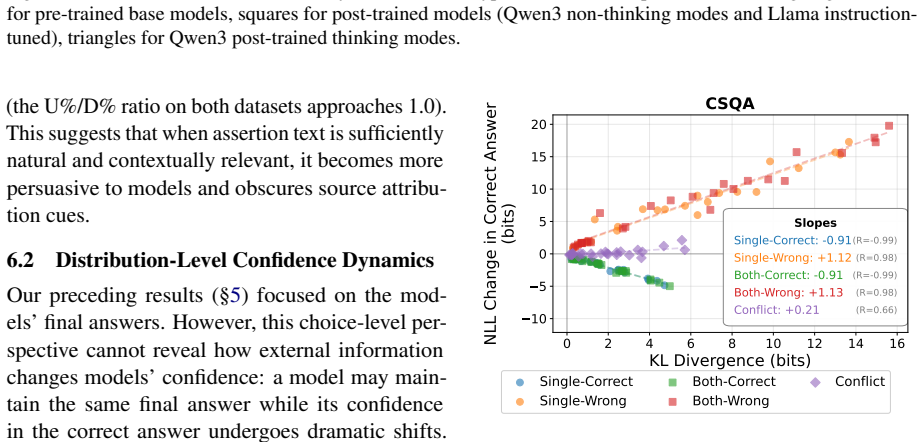
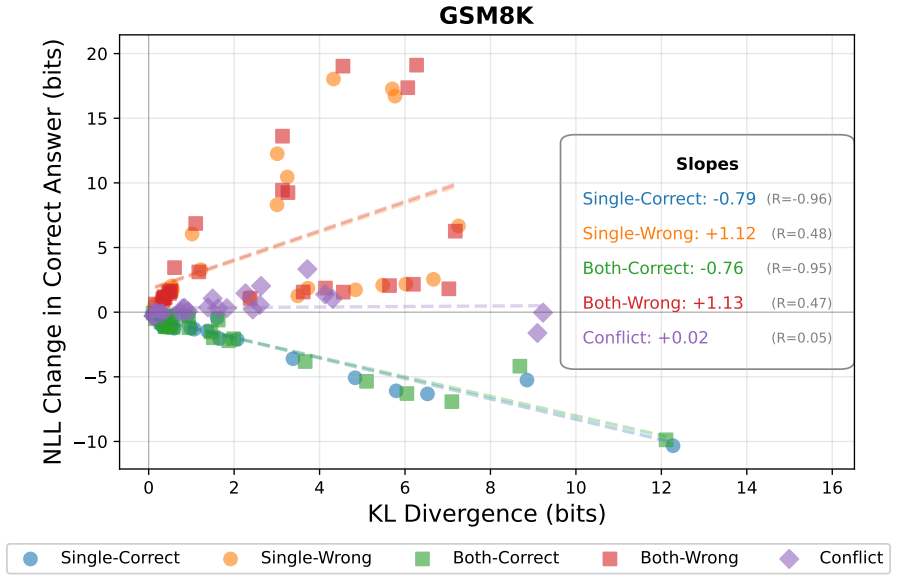
Most models rely more on document assertions than user assertions, and this preference is reinforced by post-training. Furthermore, our behavioral analysis shows that most models are impressionable, unable to effectively discriminate between helpful and harmful external information. To address this, we demonstrate that fine-tuning on diverse source interaction data can significantly increase a model's discrimination abilities.
What carries the argument
The three-source interaction framework that places internal parametric knowledge in simultaneous conflict with both user assertions and document assertions, evaluated via behavioral metrics on curated datasets.
If this is right
- Models exhibit a general preference for document assertions over user assertions when all three sources conflict.
- Post-training steps increase the degree to which models favor document content.
- Most models cannot reliably separate helpful external information from harmful information.
- Fine-tuning on data that varies the source, helpfulness, and harmfulness of external inputs measurably raises discrimination performance.
Where Pith is reading between the lines
- Safety mechanisms for retrieval-augmented generation may need explicit weighting rules that counteract the observed document bias.
- Training curricula that deliberately mix user and document signals at equal strength could reduce impressionability without additional fine-tuning stages.
- The framework could be extended to measure how models handle conflicts that also include tool outputs or multi-turn conversation history.
Load-bearing premise
The chosen datasets and behavioral metrics accurately reflect how models should balance internal knowledge against user and document assertions in realistic interactive settings.
What would settle it
A controlled experiment in which a model trained only on binary conflicts shows equal or greater reliance on user assertions than documents, or maintains high discrimination accuracy without any fine-tuning on three-source data.
Figures







read the original abstract
Large language models (LLMs) often need to balance their internal parametric knowledge with external information, such as user beliefs and content from retrieved documents, in real-world scenarios like RAG or chat-based systems. A model's ability to reliably process these sources is key to system safety. Previous studies on knowledge conflict and sycophancy are limited to a binary conflict paradigm, primarily exploring conflicts between parametric knowledge and either a document or a user, but ignoring the interactive environment where all three sources exist simultaneously. To fill this gap, we propose a three-source interaction framework and systematically evaluate 27 LLMs from 3 families on 2 datasets. Our findings reveal general patterns: most models rely more on document assertions than user assertions, and this preference is reinforced by post-training. Furthermore, our behavioral analysis shows that most models are impressionable, unable to effectively discriminate between helpful and harmful external information. To address this, we demonstrate that fine-tuning on diverse source interaction data can significantly increase a model's discrimination abilities. In short, our work paves the way for developing trustworthy LLMs that can effectively and reliably integrate multiple sources of information. Code is available at https://github.com/shuowl/llm-source-balancing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a three-source interaction framework to study how LLMs balance internal parametric knowledge against simultaneous user and document assertions in interactive settings such as RAG and chat. It evaluates 27 models from three families on two datasets, reports that models generally favor document assertions over user assertions with this bias strengthened by post-training, finds most models impressionable (unable to discriminate helpful from harmful external information), and shows that fine-tuning on diverse source-interaction data measurably improves discrimination.
Significance. If the behavioral patterns and the fine-tuning result hold under the reported metrics, the work fills a gap between binary knowledge-conflict studies and realistic multi-source scenarios. The systematic scale (27 models), code release, and concrete intervention provide a reproducible baseline for future work on trustworthy multi-source integration.
major comments (3)
- [§4.2, Table 2] §4.2 and Table 2: the reported preference for document over user assertions is presented as a general pattern, yet the manuscript provides no statistical significance tests (e.g., paired t-tests or Wilcoxon tests across models) or confidence intervals on the difference; without these, it is unclear whether the observed gap is robust or could be explained by prompt sensitivity or sampling variance.
- [§4.3] §4.3: the definition of 'impressionable' behavior and the helpful/harmful labeling of external assertions are central to the discrimination claim, but the paper does not describe an independent annotation protocol or inter-annotator agreement for these labels; if labels are derived from the same model outputs used to measure impressionability, the metric risks circularity and weakens the conclusion that models 'cannot effectively discriminate'.
- [§5.1] §5.1: the fine-tuning intervention is shown to increase discrimination, but the manuscript reports neither the size of the fine-tuning set, the exact composition of 'diverse source interaction data', nor an ablation against standard instruction-tuning or safety fine-tuning baselines; this makes it difficult to attribute the gain specifically to the three-source framing.
minor comments (3)
- [Abstract] The abstract states 'systematically evaluate 27 LLMs from 3 families on 2 datasets' but does not name the families or datasets; this information appears only later and should be moved to the abstract for clarity.
- [Figure 3] Figure 3 and its caption: the y-axis label 'Discrimination Score' is not defined in the figure or immediately preceding text; a short parenthetical definition would help readers interpret the plot without returning to §4.3.
- [Related Work] The related-work section cites prior binary-conflict studies but does not discuss how the three-source framework differs methodologically from concurrent multi-source RAG evaluations; a brief contrast paragraph would strengthen positioning.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which have helped us identify areas for improvement in the manuscript. Below, we provide detailed responses to each major comment and outline the revisions we will make.
read point-by-point responses
-
Referee: [§4.2, Table 2] §4.2 and Table 2: the reported preference for document over user assertions is presented as a general pattern, yet the manuscript provides no statistical significance tests (e.g., paired t-tests or Wilcoxon tests across models) or confidence intervals on the difference; without these, it is unclear whether the observed gap is robust or could be explained by prompt sensitivity or sampling variance.
Authors: We agree that statistical tests would strengthen the presentation of the preference patterns. In the revised version, we will add paired t-tests (and Wilcoxon signed-rank tests where appropriate) along with 95% confidence intervals on the document-minus-user preference differences, computed across the 27 models. These will be reported both in §4.2 and as additional columns or error bars in Table 2 to demonstrate that the gap is robust to sampling variance. revision: yes
-
Referee: [§4.3] §4.3: the definition of 'impressionable' behavior and the helpful/harmful labeling of external assertions are central to the discrimination claim, but the paper does not describe an independent annotation protocol or inter-annotator agreement for these labels; if labels are derived from the same model outputs used to measure impressionability, the metric risks circularity and weakens the conclusion that models 'cannot effectively discriminate'.
Authors: The helpful/harmful labels were assigned independently of any model outputs, using dataset-provided ground-truth facts: an external assertion is labeled helpful if it is consistent with the verified fact and harmful if it contradicts it. We will revise §4.3 to explicitly describe this rule-based labeling procedure, its independence from model generations, and the exact criteria applied to each dataset. Because the labels are deterministic and derived from external ground truth rather than subjective human annotation, inter-annotator agreement statistics are not applicable; we will note this explicitly. revision: yes
-
Referee: [§5.1] §5.1: the fine-tuning intervention is shown to increase discrimination, but the manuscript reports neither the size of the fine-tuning set, the exact composition of 'diverse source interaction data', nor an ablation against standard instruction-tuning or safety fine-tuning baselines; this makes it difficult to attribute the gain specifically to the three-source framing.
Authors: We acknowledge the need for greater transparency on the intervention. The revised manuscript will report the fine-tuning set size (5,000 examples), its exact composition (balanced three-source interactions with equal proportions of helpful and harmful user and document assertions), and new ablation results comparing our data against (i) standard instruction-tuning and (ii) safety fine-tuning baselines on the same base models. These additions will allow readers to isolate the contribution of the three-source framing. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is a purely empirical behavioral study that evaluates 27 LLMs across two datasets using a three-source interaction framework, reports observed patterns in source reliance, and tests fine-tuning interventions. No derivations, equations, fitted parameters, or self-citations are invoked as load-bearing steps that reduce any claim to a quantity defined by the authors' own choices. The central findings rest on direct experimental measurements and are therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs maintain distinct internal parametric knowledge that can be placed in conflict with external user and document inputs
- domain assumption User assertions and document assertions can be independently manipulated in constructed evaluation datasets
Reference graph
Works this paper leans on
-
[1]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word prob- lems.CoRR, abs/2110.14168. Shehzaad Dhuliawala, Mojtaba Komeili, Jing Xu, Roberta Raileanu, Xian Li, Asli Celikyilmaz, and Ja- son Weston. 2024. Chain-of-verification reduces hal- lucination in large language models. InFindings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and vir...
work page internal anchor Pith review arXiv 2024
-
[2]
Context versus prior knowledge in language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Vol- ume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11-16, 2024, pages 13211–13235. Associa- tion for Computational Linguistics. Aaron Fanous, Jacob Goldberg, Ank A. Agarwal, Joanna Lin, Anson Zhou, Roxana...
-
[3]
arXiv preprint arXiv:2505.23840 , year=
Measuring sycophancy of language models in multi-turn dialogues.CoRR, abs/2505.23840. Aaron Hurst, Adam Lerer, Adam P. Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, Alek- sander Madry, Alex Baker-Whitcomb, Alex Beutel, Alex Borzunov, Alex Carney, Alex Chow, Alex Kir- illov, Alex Nichol, Alex Pain...
-
[4]
Tug-of-war between knowledge: Explor- ing and resolving knowledge conflicts in retrieval- augmented language models. InProceedings of the 2024 Joint International Conference on Computa- tional Linguistics, Language Resources and Evalua- tion, LREC/COLING 2024, 20-25 May, 2024, Torino, Italy, pages 16867–16878. ELRA and ICCL. Patrick Lewis, Ethan Perez, Al...
2024
-
[5]
Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Hajishirzi
Association for Computational Linguistics. Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Hajishirzi. 2023. When not to trust language models: Investigating effectiveness of parametric and non-parametric mem- ories. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Vol- ume 1: Lo...
2023
-
[6]
A comprehensive overview of large language models,
Selfcheckgpt: Zero-resource black-box hal- lucination detection for generative large language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Process- ing, EMNLP 2023, Singapore, December 6-10, 2023, pages 9004–9017. Association for Computational Linguistics. Humza Naveed, Asad Ullah Khan, Shi Qiu, Muham- mad Saqib, S...
-
[7]
Training language models to follow instruc- tions with human feedback. InAdvances in Neural Information Processing Systems 35: Annual Confer- ence on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022. Mrinank Sharma, Meg Tong, Tomasz Korbak, David Duvenaud, Amanda Askell, Samuel R. Bowman, Esin ...
2022
-
[8]
Conflictbank: A benchmark for evaluating the influence of knowledge conflicts in llms. InAd- vances in Neural Information Processing Systems 38: Annual Conference on Neural Information Pro- cessing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024. Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. 2019. Commonsens...
-
[9]
arXiv preprint arXiv:2308.03958 (2023) 3, 5
Continuously steering llms sensitivity to con- textual knowledge with proxy models. InProceed- ings of the 2025 Conference on Empirical Methods in Natural Language Processing, EMNLP 2025, Suzhou, China, November 4-9, 2025, pages 4682–4698. As- sociation for Computational Linguistics. Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shigua...
-
[10]
Create ONE contextual claim that incorporates key words from the question
-
[11]
This contextual claim will contain a placeholder [answer] where the answer goes
-
[12]
revolving doors serve as security measures at a [answer]
Use this EXACT SAME contextual claim in ALL 4 sentences - DO NOT VARY IT AT ALL CRITICAL REQUIREMENT - THE CONTEXTUAL CLAIM MUST BE IDENTICAL: - First, write your contextual claim with [answer] as placeholder - Then use this EXACT claim in all 4 sentences, only changing [answer] to the correct/wrong answer - The ONLY difference between sentences should be...
-
[13]
Create your contextual claim with [answer] placeholder
-
[14]
Fill the templates with the provided words
-
[15]
Replace {contextual_claim} with your contextual claim
-
[16]
IMPORTANT: Replace [answer] with the ACTUAL answer value: - In USER_CORRECT and DOC_CORRECT: Replace [answer] with [correct_answer] - In USER_WRONG and DOC_WRONG: Replace [answer] with [wrong_answer]
-
[17]
[answer]
DO NOT leave "[answer]" in any final sentence - it must be replaced! Format your response EXACTLY as: USER_CORRECT: [sentence] DOC_CORRECT: [sentence] USER_WRONG: [sentence] DOC_WRONG: [sentence] IMPORTANT: Do NOT add quotation marks around the sentences. Output plain text only. Figure 6: GPT-4o prompt for generating Tier 2 context-aware assertions. Place...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.