Recognition: unknown
Qubit-Scalable CVRP via Lagrangian Knapsack Decomposition and Noise-Aware Quantum Execution
Pith reviewed 2026-05-08 11:56 UTC · model grok-4.3
The pith
Lagrangian decomposition turns CVRP into bounded knapsack subproblems whose dual variables are updated by a learned controller and whose quantum executions are chosen by a noise-aware bandit.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By dualizing the assignment constraints of the Fisher-Jaikumar linearization, the full CVRP separates into per-vehicle knapsack problems that admit direct QUBO encoding; a multiplier-update policy pretrained on expert trajectories and refined by reinforcement learning on execution feedback, together with a constrained contextual bandit that picks noisy backends and configurations, produces higher-quality reconstructed routes than subgradient control or static quantum execution under matched computational limits.
What carries the argument
Lagrangian relaxation of customer-assignment couplers that yields independent per-vehicle knapsack subproblems, controlled by a reinforcement-learning multiplier policy and a feasibility-screened contextual bandit for hardware selection.
If this is right
- Subproblem widths remain bounded as the number of customers and vehicles increases across standard benchmark families.
- Learned multiplier updates produce better final routing costs than classical subgradient methods when both are given the same number of quantum evaluations.
- Hardware-aware selection via the bandit lowers median optimality gaps compared with any single fixed backend and circuit choice.
- The same decomposition and control loop supports parallel scheduling across multiple QPUs while preserving feasibility.
Where Pith is reading between the lines
- The same Lagrangian separation could be applied to other assignment-heavy routing or scheduling problems whose direct QUBO encodings exceed current qubit limits.
- If the reward signal and screening rules prove robust, the RL dual controller might transfer to Lagrangian relaxations in other hybrid quantum optimization domains.
- Wider adoption of contextual bandit hardware selection would reduce the engineering overhead of running hybrid algorithms on heterogeneous and evolving quantum devices.
- Explicit measurement of how quickly the learned policy degrades on instance distributions far from the training set would quantify the practical scope of the generalization claim.
Load-bearing premise
The reinforcement-learning multiplier controller and contextual bandit generalize across CVRP instances and heterogeneous noisy quantum hardware without instance-specific retraining or bias from reward design and feasibility rules.
What would settle it
Evaluating the trained controller and bandit on a held-out CVRPLIB family or a different quantum backend and checking whether subproblem widths remain bounded and end-to-end route quality still exceeds classical subgradient and static baselines.
Figures
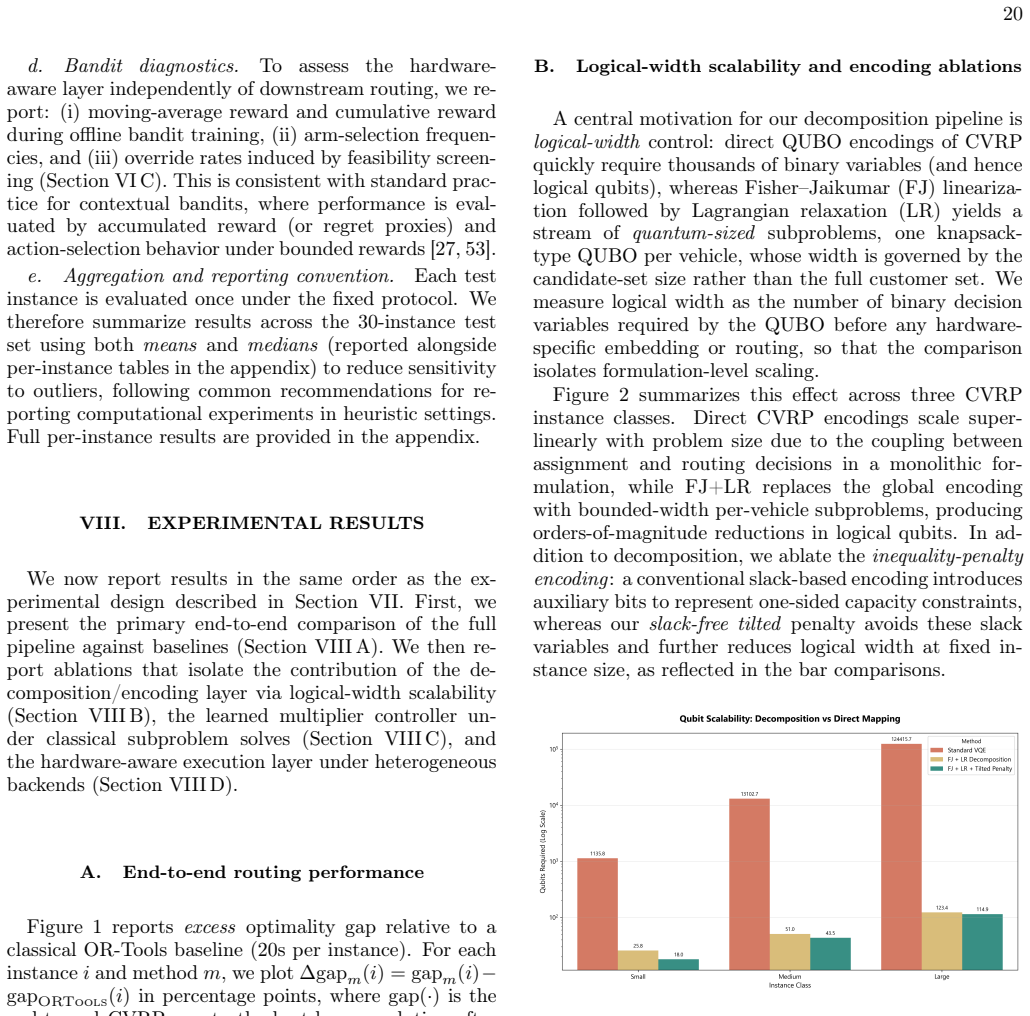








read the original abstract
Hybrid quantum optimization for vehicle routing faces a practical bottleneck: direct QUBO encodings of CVRP quickly exceed near-term qubit and gate budgets, while quantum evaluations are expensive, noise-limited, and sensitive to backend and circuit configuration. We address this gap with an end-to-end decomposition pipeline that converts CVRP into bounded-width quantum subproblems and treats quantum execution as a decision problem within the optimization loop. Starting from a Fisher--Jaikumar assignment linearization, we apply Lagrangian relaxation to dualize customer-assignment couplers, yielding independent per-vehicle knapsack subproblems that admit QUBO/Ising evaluation. To replace brittle subgradient tuning, we learn a multiplier-update controller using expert-guided pretraining followed by reinforcement-learning fine-tuning, with rewards based on execution-realized progress and route reconstruction. We also introduce a constrained contextual bandit as a hardware-aware execution layer that selects backend and circuit configuration with feasibility screening, enabling adaptation across heterogeneous noisy resources and parallel multi-QPU scheduling. Computational results on multiple CVRPLIB families show that the decomposition yields stable bounded-width subproblems across instance sizes, learned multiplier updates improve end-to-end routing quality relative to classical subgradient control under matched budgets, and hardware-mode configuration reduces median optimality gaps relative to static execution choices in our test set. We do not claim quantum advantage. Instead, the contribution is a practical end-to-end framework for scaling hybrid quantum CVRP optimization through OR decomposition, learning-augmented dual control, and adaptive hardware-aware execution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a hybrid quantum-classical framework for the Capacitated Vehicle Routing Problem (CVRP) that decomposes the problem via Lagrangian relaxation applied to a Fisher-Jaikumar assignment linearization, producing independent bounded-width knapsack subproblems amenable to QUBO/Ising formulation. It replaces classical subgradient tuning with a learned multiplier-update controller trained via expert pretraining followed by reinforcement learning fine-tuning (using execution-realized progress and route reconstruction rewards), and adds a constrained contextual bandit layer for noise-aware selection of quantum backends, circuit configurations, and parallel multi-QPU scheduling with feasibility screening. Computational results on multiple CVRPLIB families are presented to show stable subproblem widths across instance sizes, improved end-to-end routing quality from the learned controller versus subgradient baselines under matched budgets, and reduced median optimality gaps from adaptive hardware execution. The work explicitly disclaims any claim of quantum advantage and frames its contribution as a practical end-to-end pipeline combining OR decomposition, learning-augmented dual control, and adaptive quantum execution.
Significance. If the reported improvements hold under proper generalization testing, the work could offer a pragmatic route to scaling hybrid quantum optimization for routing problems by mitigating qubit and noise constraints through decomposition and adaptive control. Credit is due for the explicit integration of standard Lagrangian techniques with RL and bandit methods, the focus on real-hardware considerations, and the absence of overstated quantum-advantage claims. The approach builds on established OR and RL tools rather than introducing fundamentally new axioms, so its value lies in the end-to-end engineering and empirical demonstration on standard benchmarks.
major comments (2)
- [Abstract] Abstract and computational results: the headline claims that learned multiplier updates outperform subgradient control and that the hardware bandit reduces gaps rest on the RL controller and contextual bandit generalizing across CVRP instances and noisy backends without per-instance retraining. No evidence is supplied that training and test CVRPLIB families were disjoint, that reward design (progress + feasibility screening) does not favor particular route structures, or that the policy transfers to unseen customer distributions or new hardware; this directly undermines the robustness of the reported improvements.
- [Hardware-aware execution layer] The description of the constrained contextual bandit execution layer states that it enables adaptation across heterogeneous resources, yet the manuscript provides no ablation or transfer experiments showing performance when the bandit is applied to previously unseen QPUs or instance sizes; without such tests the claim that hardware-mode configuration reduces median gaps relative to static choices cannot be evaluated as load-bearing.
minor comments (2)
- [Abstract] The abstract would benefit from inclusion of concrete instance sizes, median gap values, and number of CVRPLIB families tested to allow immediate assessment of scale and effect size.
- [Methods] Notation for the Lagrangian multipliers and the RL state representation should be introduced with explicit equations early in the methods section for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the practical engineering focus of the work. We address each major comment below with clarifications and indicate the revisions planned for the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and computational results: the headline claims that learned multiplier updates outperform subgradient control and that the hardware bandit reduces gaps rest on the RL controller and contextual bandit generalizing across CVRP instances and noisy backends without per-instance retraining. No evidence is supplied that training and test CVRPLIB families were disjoint, that reward design (progress + feasibility screening) does not favor particular route structures, or that the policy transfers to unseen customer distributions or new hardware; this directly undermines the robustness of the reported improvements.
Authors: We acknowledge that the manuscript does not explicitly document a disjoint train/test split across CVRPLIB families or provide dedicated analysis of reward bias and cross-distribution/hardware transfer. The reported results use multiple standard CVRPLIB families with the learned controller and bandit evaluated on the test instances shown. In revision we will (i) qualify the abstract claims to reflect the evaluated test set, (ii) add a subsection detailing the exact instance partitioning used (different families for training versus testing where applicable), and (iii) include a short analysis of the reward formulation showing that progress and feasibility terms are defined on aggregate metrics independent of specific route topologies. We will also add a limitations paragraph noting the absence of explicit transfer experiments to entirely new customer distributions or hardware platforms and will temper language accordingly rather than overstate generalization. revision: partial
-
Referee: [Hardware-aware execution layer] The description of the constrained contextual bandit execution layer states that it enables adaptation across heterogeneous resources, yet the manuscript provides no ablation or transfer experiments showing performance when the bandit is applied to previously unseen QPUs or instance sizes; without such tests the claim that hardware-mode configuration reduces median gaps relative to static choices cannot be evaluated as load-bearing.
Authors: We agree that the absence of explicit ablation or transfer experiments on unseen QPUs limits the strength of the adaptation claim. The current results demonstrate gap reduction relative to static execution choices on the hardware configurations tested in the study. In the revision we will expand the hardware-layer description with any available sensitivity data, add a dedicated paragraph clarifying the scope of the experiments (i.e., adaptation within the set of available backends and instance sizes), and revise the abstract and conclusions to avoid implying untested transfer. If additional compute resources permit, we will include a limited ablation; otherwise the language will be adjusted to match the evidence presented. revision: partial
Circularity Check
No circularity: standard decomposition and empirical RL results are independent of inputs
full rationale
The derivation begins with the Fisher-Jaikumar linearization, applies Lagrangian relaxation to produce independent knapsack subproblems, and then uses RL pretraining plus fine-tuning for multiplier updates and a contextual bandit for hardware selection. These are standard OR and RL techniques whose outputs (bounded-width subproblems, improved routing quality, reduced gaps) are demonstrated via computational experiments on CVRPLIB families against explicit baselines (subgradient control, static execution). No equation reduces to a fitted parameter by construction, no self-citation is load-bearing for the central claims, and the reported improvements are falsifiable empirical comparisons rather than definitional. The paper explicitly disclaims quantum advantage and frames its contribution as an engineering pipeline.
Axiom & Free-Parameter Ledger
free parameters (1)
- RL reward function weights
axioms (1)
- domain assumption Fisher-Jaikumar assignment linearization plus Lagrangian relaxation decomposes CVRP into independent per-vehicle knapsack subproblems
invented entities (2)
-
Learned multiplier-update controller
no independent evidence
-
Constrained contextual bandit execution layer
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Offline bandit behavior Figure 4 summarizes the trace-driven offline training (Section VID). The bounded execution-proxy reward rises rapidly from a cold start and then plateaus, indi- cating that LinUCB identifies a stable set of high-utility configurationarmsfromthejointhardware/problemcon- text (Section VIA) rather than continuing to explore broadly. F...
-
[2]
Constraint pressure: gate-budget risk versus logical width Figure 6 reports the empiricalgate-budget hit rateas a function of logical width, defined as the fraction of con- sult calls in which the bandit’s top-ranked arm is rejected by feasibility screening (becausebG > G max) and the se- lector falls back to the best-ranked feasible alternative. The hit ...
-
[3]
Total time
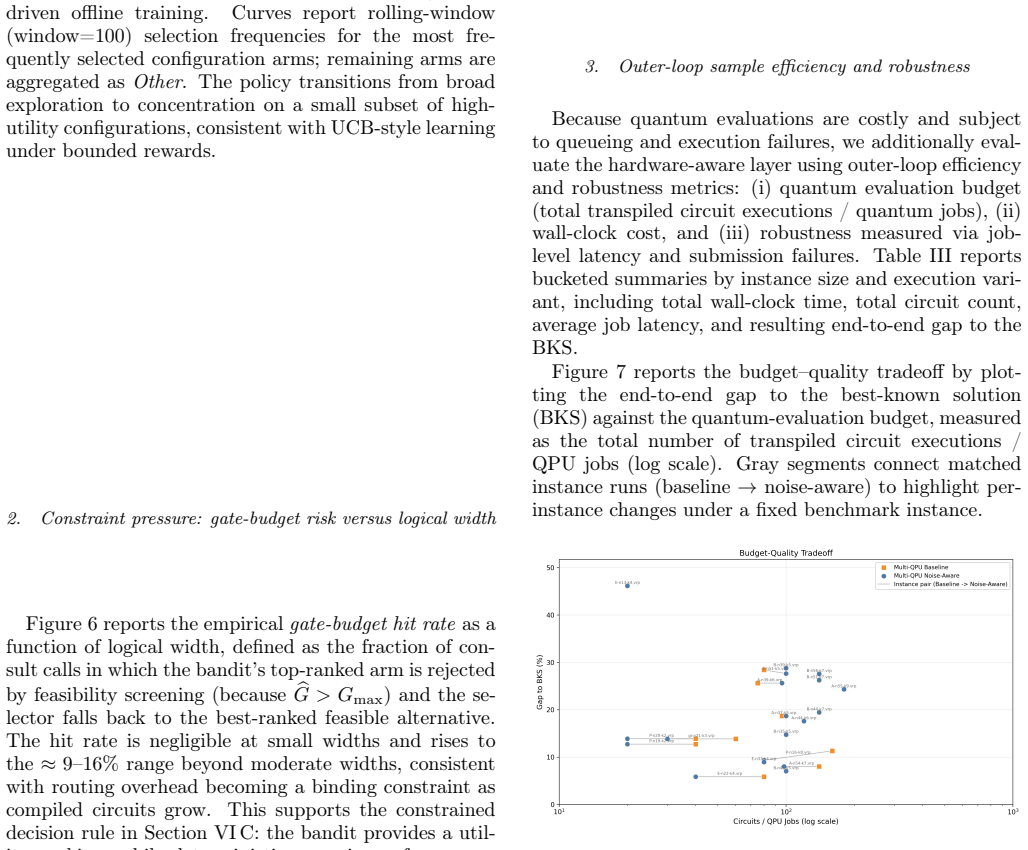
Outer-loop sample efficiency and robustness Because quantum evaluations are costly and subject to queueing and execution failures, we additionally eval- uate the hardware-aware layer using outer-loop efficiency and robustness metrics: (i) quantum evaluation budget (total transpiled circuit executions / quantum jobs), (ii) wall-clock cost, and (iii) robust...
2080
-
[4]
End-to-end impact under noisy simulation and hardware Finally, we evaluate the end-to-end routing impact of hardware-aware configuration. Figure 8 compares CVRP optimality gaps (to BKS) under three execution set- tings for the same learned multiplier controller: (i) noisy simulation without bandit-based configuration, (ii) real- hardware execution without...
-
[5]
Preskill, Quantum2, 79 (2018)
J. Preskill, Quantum2, 79 (2018)
2018
- [6]
- [7]
-
[8]
Toth and D
P. Toth and D. Vigo,The vehicle routing problem(SIAM, 2002)
2002
-
[9]
G. B. Dantzig and J. H. Ramser, Management Science6, 80 (1959)
1959
-
[10]
Clarke and J
G. Clarke and J. Wright, Operations Research12, 568 (1964)
1964
-
[11]
M. L. Fisher and R. Jaikumar, Networks11, 109 (1981)
1981
-
[12]
Bollapragada, C
R. Bollapragada, C. Karamanli, B. Keith, B. Lazarov, S. Petrides, and J. Wang, Computers & Mathematics with Applications149, 239 (2023)
2023
-
[13]
N. Xiao, X. Liu, and Y.-x. Yuan, Optimization Methods and Software37, 1205 (2022)
2022
-
[14]
Bharti, A
K. Bharti, A. Cervera-Lierta, T. H. Kyaw, T. Haug, S. Alperin-Lea, A. Anand, M. Degroote, H. Heimonen, J. S. Kottmann, T. Menke, W.-K. Mok, S. Sim, L.- C. Kwek, and A. Aspuru-Guzik, Rev. Mod. Phys.94, 015004 (2022)
2022
-
[15]
X. Fang, K. Yin, Y. Zhu, J. Ruan, D. Tullsen, Z. Liang, A. Sornborger, A. Li, T. Humble, Y. Ding, and Y. Shi, inProceedings of the 52nd Annual International Sympo- sium on Computer Architecture, ISCA ’25 (Association for Computing Machinery, New York, NY, USA, 2025) p. 1402–1416
2025
-
[16]
M. A. Gaye, D. Albrecht, S. Young, T. Albash, and N. T. Jacobson, Phys. Rev. B111, 115303 (2025)
2025
-
[17]
Proctor, M
T. Proctor, M. Revelle, E. Nielsen, K. Rudinger, D. Lob- ser, P. Maunz, and K. Young, Nature Communications 11, 5396 (2020)
2020
-
[18]
B. E. Gillett and L. R. Miller, Operations Research22, 340 (1974)
1974
-
[19]
B. M. Baker and J. Sheasby, European Journal of Oper- ational Research119, 147 (1999)
1999
-
[20]
A. M. Geoffrion, inApproaches to integer programming (Springer, 2009) pp. 82–114
2009
-
[21]
M. L. Fisher, Management science27, 1 (1981)
1981
-
[22]
B. T. Polyak, Nonsmooth optimization , 5 (1977)
1977
-
[23]
Ising formulations of many NP problems
A. Lucas, Frontiers in Physics2, 10.3389/fphy.2014.00005 (2014)
-
[24]
Kochenberger, J.-K
G. Kochenberger, J.-K. Hao, F. Glover, M. Lewis, Z. Lü, H. Wang, and Y. Wang, Journal of combinatorial opti- mization28, 58 (2014)
2014
-
[25]
Peruzzo, J
A. Peruzzo, J. McClean, P. Shadbolt, M.-H. Yung, X.-Q. Zhou, P. J. Love, A. Aspuru-Guzik, and J. L. O’brien, Nature communications5, 4213 (2014)
2014
-
[26]
A Quantum Approximate Optimization Algorithm
E. Farhi, J. Goldstone, and S. Gutmann, arXiv preprint arXiv:1411.4028 (2014)
work page internal anchor Pith review arXiv 2014
-
[27]
G. Li, Y. Ding, and Y. Xie, inProceedings of the twenty- fourth international conference on architectural support for programming languages and operating systems(2019) pp. 1001–1014
2019
-
[28]
Sivarajah, S
S. Sivarajah, S. Dilkes, A. Cowtan, W. Simmons, A. Edg- ington, and R. Duncan, Quantum Science & Technology 6, 014003 (2021)
2021
-
[29]
P. D. Nation and M. Treinish, PRX Quantum4, 010327 (2023)
2023
-
[30]
H. Kurniawan, L. Rodríguez-Soriano, D. Cuomo, C. G. Almudever, and F. G. Herrero, arXiv preprint arXiv:2407.21462 (2024)
-
[31]
L. Li, W. Chu, J. Langford, and R. E. Schapire, inPro- ceedings of the 19th international conference on World wide web(2010) pp. 661–670
2010
-
[32]
W. Chu, L. Li, L. Reyzin, and R. E. Schapire, inPro- ceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Proceedings of Ma- chine Learning Research (2011)
2011
-
[33]
S. Feld, C. Roch, T. Gabor, C. Seidel, F. Neukart, I. Gal- ter, W. Mauerer, and C. Linnhoff-Popien, Frontiers in ICTVolume 6 - 2019, 10.3389/fict.2019.00013 (2019)
- [34]
-
[35]
L. Palackal, B. Poggel, M. Wulff, H. Ehm, J. M. Lorenz, and C. B. Mendl, in2023 IEEE International Conference on Quantum Computing and Engineering (QCE)(Belle- vue, WA, USA, 2023) pp. 648–658, arXiv:2304.09629 [quant-ph]
-
[36]
N. Xie, X. Lee, D. Cai, Y. Saito, N. Asai, and H. C. Lau, Quantum Information Processing23, 291 (2024)
2024
-
[37]
J. Holliday, B. Morgan, H. Churchill, and K. Luu, Hy- brid quantum tabu search for solving the vehicle routing problem (2024), arXiv:2404.13203 [cs.ET]
- [38]
-
[39]
W. hao Huang, H. Matsuyama, and Y. Yamashiro, Solv- ingcapacitatedvehicleroutingproblemwithquantumal- ternating operator ansatz and column generation (2025), arXiv:2503.17051 [quant-ph]
-
[40]
arXiv preprint arXiv:2509.11469
C. Onah and K. Michielsen, Requirements for early quan- tum advantage and quantum utility in the capacitated vehicle routing problem (2025), arXiv:2509.11469 [quant- ph]
-
[41]
Baldacci, N
R. Baldacci, N. Christofides, and A. Mingozzi, Mathe- matical Programming115, 351 (2008)
2008
-
[42]
M. Held, P. Wolfe, and H. P. Crowder, Mathematical programming6, 62 (1974)
1974
-
[43]
arXiv preprint arXiv:1811.11538
F. Glover, G. Kochenberger, and Y. Du, A tuto- rial on formulating and using qubo models (2019), arXiv:1811.11538 [cs.DS]
-
[44]
J. A. Montañez-Barrera, D. Willsch, A. Maldonado- Romo, and K. Michielsen, Quantum Science and Tech- nology9, 025022 (2024)
2024
-
[45]
D. G. Cattrysse and L. N. Van Wassenhove, European journal of operational research60, 260 (1992)
1992
-
[46]
I. H. Osman, Operations-Research-Spektrum17, 211 (1995)
1995
-
[47]
Nedić and D
A. Nedić and D. P. Bertsekas, Mathematical program- ming125, 75 (2010)
2010
-
[48]
K. C. Kiwiel, SIAM Journal on Optimization14, 807 (2004)
2004
-
[49]
R. S. Sutton, A. G. Barto,et al.,Reinforcement learning: An introduction(MIT press Cambridge, 1998)
1998
-
[50]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, arXiv preprint arXiv:1707.06347 (2017). 27
work page internal anchor Pith review arXiv 2017
-
[51]
Stooke, J
A. Stooke, J. Achiam, and P. Abbeel, inInternational Conference on Machine Learning(PMLR, 2020) pp. 9133–9143
2020
-
[52]
S. Ross, G. Gordon, and D. Bagnell, inProceedings of the fourteenth international conference on artificial intel- ligence and statistics(JMLR Workshop and Conference Proceedings, 2011) pp. 627–635
2011
-
[53]
Bengio, J
Y. Bengio, J. Louradour, R. Collobert, and J. Weston, in Proceedings of the 26th annual international conference on machine learning(2009) pp. 41–48
2009
-
[54]
P. Veličković, G. Cucurull, A. Casanova, A. Romero, P. Lio, and Y. Bengio, arXiv preprint arXiv:1710.10903 (2017)
work page internal anchor Pith review arXiv 2017
-
[55]
How attentive are graph attention networks?arXiv preprint arXiv:2105.14491,
S. Brody, U. Alon, and E. Yahav, arXiv preprint arXiv:2105.14491 (2021)
-
[56]
A. Y. Ng, D. Harada, and S. Russell, inIcml, Vol. 99 (Citeseer, 1999) pp. 278–287
1999
-
[57]
P. Auer, N. Cesa-Bianchi, and P. Fischer, Machine learn- ing47, 235 (2002)
2002
-
[58]
Uchoa, D
E. Uchoa, D. Pecin, A. Pessoa, M. Poggi, T. Vidal, and A. Subramanian, European Journal of Operational Re- search257, 845 (2017)
2017
-
[59]
In the multi-QPU evaluator,solve_timeis measured around the full evaluation loop, andvqe_timeaccumu- lates time spent inside quantum subproblem calls
-
[60]
P. K. Barkoutsos, G. Nannicini, A. Robert, I. Tavernelli, and S. Woerner, Quantum4, 256 (2020). Appendix A: Penalty encodings for knapsack capacity constraints
2020
-
[61]
unbalanced penalization
Quantum knapsack encoding in LR-decomposed CVRP: Taylor vs. Tilted penalties a. Context (LR-decomposed per-vehicle knapsack).Under the Lagrangian relaxation of the Fisher–Jaikumar as- signment surrogate, the relaxed problem decomposes into one subproblem per vehiclek(Section IIIC). Each vehicle solves a 0–1 knapsack-structured selection problem of the for...
-
[62]
Lagrangian heuristic
Micro-benchmark under noisy simulation: feasibility and optimality yield To motivate the choice of tilted penalization in the LR–CVRP pipeline, we perform a controlled micro-benchmark on CVRP instances. We generated random CVRP instances, and used our framework of decomposition and LR to extract the corresponding knapsack subproblems. We then compile and ...
-
[63]
Cluster-level route construction For each vehiclek:
-
[64]
Construct an initial tour on{0}∪Vk using a fast heuristic (e.g., nearest-neighbor or savings-based initialization)
-
[65]
Apply a fixed budget of local improvements (e.g., 2-opt and node relabeling moves) to reduce travel cost
-
[66]
Output the improved tour as the route for vehiclek. Because capacity feasibility is enforced at the assignment level, each cluster route is capacity-feasible by construction; reconstruction failures are therefore rare and typically arise only from degenerate edge cases (e.g., empty cluster handling or numerical issues), which are handled deterministically...
-
[67]
•Route-feasible: a valid depot-starting tour exists for each nonempty cluster
Cost evaluation and feasibility flags The reconstruction module returns: (i) the set of routesR={R k}K k=1, (ii) the total routing costCost(R) =P k P (i,j)∈Rk cij, and (iii) feasibility flags: •Assignment-feasible: all customers assigned exactly once and all vehicle loads≤Q. •Route-feasible: a valid depot-starting tour exists for each nonempty cluster. In...
-
[68]
Any heuristic that uses random choices (e.g., randomized nearest-neighbor) is run with fixed seeds
Determinism and reproducibility To ensure that differences in end-to-end performance are attributable to subproblem generation and quantum sampling (rather than reconstruction randomness), reconstruction is implemented deterministically givenˆyand the distance matrix. Any heuristic that uses random choices (e.g., randomized nearest-neighbor) is run with f...
-
[69]
TABLE IV: Default policy hyperparameters (DiagonalPrecondPolicy)
Policy architecture (DiagonalPrecondPolicy) Table IV summarizes the default graph-policy architecture used in our two-phase training pipeline. TABLE IV: Default policy hyperparameters (DiagonalPrecondPolicy). Parameter Value Node feature dimension (input_dim) 14 GNN hidden dimension (hidden_dim) 256 Number of GATv2 layers (num_layers) 4 Attention heads pe...
-
[70]
The default bounds and horizon used by the curriculum environment are: •Maximum outer-loop steps per episode:200
Environment and multiplier bounds We clamp multipliers to a bounded interval for numerical stability and to prevent extreme dual oscillations. The default bounds and horizon used by the curriculum environment are: •Maximum outer-loop steps per episode:200. •Multiplier bounds:λ min =−400,λ max = 800. •Frequency of primal evaluation: every2iterations. •Freq...
-
[71]
BC” denotes the expert-guided pretraining phase; “BC+RL
Two-stage training schedule Table V summarizes the training schedule and optimizer settings. “BC” denotes the expert-guided pretraining phase; “BC+RL” denotes the PPO fine-tuning phase with an annealed imitation weight. 33 TABLE V: Training hyperparameters (default configuration). Parameter Value Discount factorγ0.99 GAE parameterλ0.95 BC epochs 120 DAgge...
2048
-
[72]
•Phase 2→3 transition when gap falls below 0.20
Curriculum parameters The curriculum transitions and phase-specific weights are fixed as follows: •Phase 1→2 transition when assignment ratio exceeds 0.65. •Phase 2→3 transition when gap falls below 0.20. •Transition smoothing window: 30 iterations. •Phase weights: feasibility (phase 1) = 3.0, gap (phase 2) = 3.0. •Phase 3 weights: cost = 0.10, gap = 0.01...
-
[73]
Estimator pass rate
Circuit-level overhead under selected configurations To connect configuration choices to compilation overhead, we summarize transpiled circuit statistics recorded under the configurations selected by the consult routine. Table VII reports mean transpiled depth and mean total gate count as proxies for compiled circuit size, aggregated by backend, along wit...
-
[74]
35 TABLE VIII: Per-instance quantum decomposition results across CVRP benchmarks
Full per-instance cost and quality results Table VIII reports per-instance outer-loop sample-efficiency metrics, including quantum-evaluation budget, wall- clock time, and latency statistics, together with the resulting end-to-end gap after decoding/repair and route recon- struction. 35 TABLE VIII: Per-instance quantum decomposition results across CVRP be...
-
[75]
Simulator
Backend usage and orchestration behavior For multi-QPU runs, we record which backend executes each submitted quantum job and summarize the resulting allocation across device families. Figure 12 reports the aggregatedevice mixfor the multi-QPU noise-aware setting, 36 TABLE IX: Per-instance end-to-end optimality gaps (%) to the best-known solution (BKS) acr...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.