Recognition: unknown
Rethinking Semantic Collaborative Integration: Why Alignment Is Not Enough
Pith reviewed 2026-05-08 10:20 UTC · model grok-4.3
The pith
Enforcing global geometric alignment between semantic and collaborative representations can distort local structures and suppress view-specific signals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
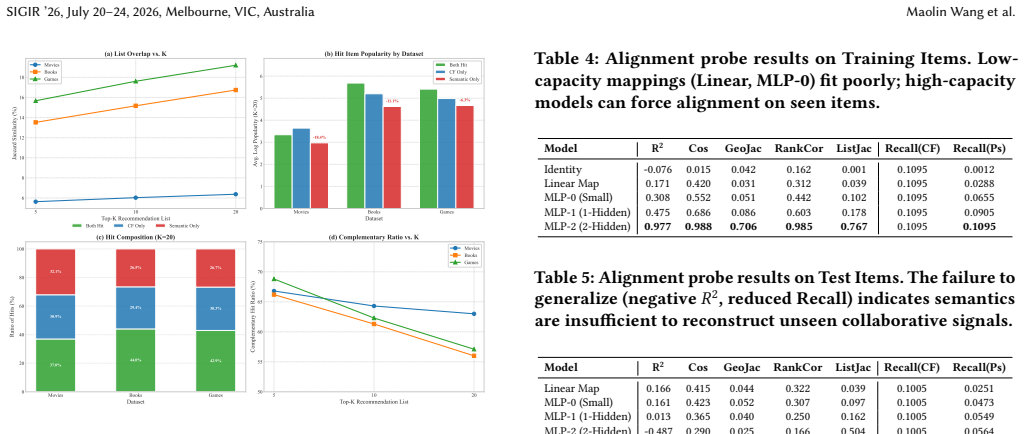
The paper establishes that semantic and collaborative representations follow a shared-plus-private latent structure in which each view encodes both common and view-specific factors. Under this structure, the prevailing global low-complexity alignment hypothesis leads to distortion of local structure and suppression of informational diversity. Empirical diagnostics on sparse recommendation benchmarks demonstrate low item-level agreement between views and substantial gains from oracle fusion, while controlled probes show low-capacity alignment mappings capture only shared components and fail to recover full collaborative geometry under distribution shift.
What carries the argument
The shared-plus-private latent structure, under which semantic and collaborative representations each contain both shared and view-specific factors, supported by complementarity-aware diagnostics that quantify overlap, unique-hit contribution, and theoretical fusion upper bounds.
If this is right
- Low item-level agreement between semantic and collaborative views indicates strong complementarity beyond what alignment can capture.
- Substantial oracle fusion gains on sparse benchmarks show that selective integration can outperform global alignment.
- Low-capacity alignment mappings capture only shared components and fail to recover full collaborative geometry under distribution shift.
- Alignment should not be treated as the default integration principle; designs must selectively integrate shared factors while preserving private signals.
Where Pith is reading between the lines
- Models could incorporate separate private encoders for each view before selective merging to explicitly retain view-specific information.
- The same shared-plus-private framing may apply to other multimodal settings where forced alignment risks losing modality-unique signals.
- Experiments on denser datasets could test whether the observed distortion from alignment varies systematically with data sparsity.
Load-bearing premise
Semantic and collaborative representations are partially shared yet fundamentally heterogeneous views each containing both shared and view-specific factors.
What would settle it
Demonstrating high item-level agreement between semantic and collaborative representations together with no additional performance gains from oracle fusion on multiple sparse benchmarks would falsify the core complementarity argument.
Figures





read the original abstract
Large language models (LLMs) have become an important semantic infrastructure for modern recommender systems. A prevailing paradigm integrates LLM-derived semantic embeddings with collaborative representations via representation alignment, implicitly assuming that the two views encode a shared latent entity and that stronger alignment yields better results. We formalize this assumption as the global low-complexity alignment hypothesis and argue that it is stronger than necessary and often structurally mismatched with real-world recommendation settings. We propose a complementary perspective in which semantic and collaborative representations are treated as partially shared yet fundamentally heterogeneous views, each containing both shared and view-specific factors. Under this shared-plus-private latent structure, enforcing global geometric alignment may distort local structure, suppress view-specific signals, and reduce informational diversity. To support this perspective, we develop complementarity-aware diagnostics that quantify overlap, unique-hit contribution, and theoretical fusion upper bounds. Empirical analyses on sparse recommendation benchmarks reveal low item-level agreement between semantic and collaborative views and substantial oracle fusion gains, indicating strong complementarity. Furthermore, controlled alignment probes show that low-capacity mappings capture only shared components and fail to recover full collaborative geometry, especially under distribution shift. These findings suggest that alignment should not be treated as the default integration principle. We advocate a shift from alignment-centric modeling to complementarity fusion-centric, complementarity-aware design, where shared factors are selectively integrated while private signals are preserved. This reframing provides a principled foundation for the next generation of LLM-enhanced recommender systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes the prevailing 'global low-complexity alignment hypothesis' for integrating LLM-derived semantic embeddings with collaborative representations in recommender systems, argues that this assumption is structurally mismatched with real data, and advances a shared-plus-private latent structure in which the two views contain both overlapping and view-specific factors. It introduces complementarity-aware diagnostics (item-level agreement, unique-hit contribution, oracle fusion upper bounds) and reports empirical results on sparse benchmarks showing low agreement, substantial oracle gains, and that low-capacity alignment mappings recover only shared components while failing to preserve full collaborative geometry under shift. The conclusion advocates moving from alignment-centric to complementarity fusion-centric design.
Significance. If the shared-plus-private characterization is accurate and the diagnostics generalize, the work provides a principled reframing that could redirect research on LLM-enhanced recommenders away from default alignment toward methods that selectively integrate shared factors while preserving private signals, with potential gains in diversity and robustness. The diagnostic framework itself is a concrete contribution that future papers can adopt or extend.
major comments (2)
- [Empirical Analyses] The empirical section reports low item-level agreement and oracle fusion gains but does not present a direct comparison of any alignment-based integration method against a non-alignment (complementarity-preserving) fusion baseline on standard recommendation metrics such as Recall@K or NDCG@K. Without this, the claim that enforcing global alignment distorts local structure and harms downstream performance remains interpretive rather than empirically demonstrated.
- [Controlled Alignment Probes] The controlled alignment probes are restricted to low-capacity mappings; the manuscript does not test whether higher-capacity, selective, or geometry-preserving alignment procedures could recover additional collaborative structure, leaving open the possibility that the reported failures are capacity-dependent rather than inherent to alignment.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from an explicit statement of the exact datasets, sparsity levels, and evaluation protocols used for the reported diagnostics.
- Notation for 'unique-hit contribution' and 'theoretical fusion upper bounds' should be defined formally at first use to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments identify valuable opportunities to strengthen the empirical grounding of our claims regarding the limitations of alignment-based integration. We address each major comment below and describe the revisions we will make.
read point-by-point responses
-
Referee: [Empirical Analyses] The empirical section reports low item-level agreement and oracle fusion gains but does not present a direct comparison of any alignment-based integration method against a non-alignment (complementarity-preserving) fusion baseline on standard recommendation metrics such as Recall@K or NDCG@K. Without this, the claim that enforcing global alignment distorts local structure and harms downstream performance remains interpretive rather than empirically demonstrated.
Authors: We agree that including direct comparisons on downstream metrics would make the performance implications more concrete rather than interpretive. The manuscript's focus is on complementarity-aware diagnostics and oracle bounds to characterize the structural mismatch, but we did not evaluate end-to-end recommendation performance. In the revised version we will add experiments that compare standard alignment methods (linear projection and contrastive alignment) against a shared-plus-private fusion baseline on Recall@K and NDCG@K using the same sparse benchmarks, thereby providing explicit evidence of any performance differences. revision: yes
-
Referee: [Controlled Alignment Probes] The controlled alignment probes are restricted to low-capacity mappings; the manuscript does not test whether higher-capacity, selective, or geometry-preserving alignment procedures could recover additional collaborative structure, leaving open the possibility that the reported failures are capacity-dependent rather than inherent to alignment.
Authors: We acknowledge that restricting the probes to low-capacity mappings leaves open whether higher-capacity or geometry-preserving alignments could recover more structure. Our design choice was to isolate the effect under the global low-complexity alignment hypothesis without confounding factors from model capacity. To address this, the revision will extend the controlled probes to include higher-capacity mappings (deeper MLPs) and geometry-preserving techniques (e.g., optimal transport or Gromov-Wasserstein alignment), reporting the extent to which additional collaborative geometry is recovered or whether view-specific signals remain suppressed. revision: yes
Circularity Check
No significant circularity; new diagnostics and empirical measurements provide independent support
full rationale
The paper formalizes the prevailing alignment hypothesis as the 'global low-complexity alignment hypothesis,' proposes the shared-plus-private latent structure as an alternative perspective, and supports the latter through newly developed complementarity-aware diagnostics (overlap, unique-hit contribution, theoretical fusion upper bounds) plus controlled alignment probes and benchmark observations (low item-level agreement, oracle fusion gains). No equations reduce any claimed result to a fitted parameter or self-referential definition, and no load-bearing step relies on self-citation chains or imported uniqueness theorems. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Semantic and collaborative representations are partially shared yet fundamentally heterogeneous views each containing both shared and view-specific factors
Reference graph
Works this paper leans on
-
[1]
Oren Barkan, Noam Koenigstein, Eylon Yogev, and Ori Katz. 2019. CB2CF: a neural multiview content-to-collaborative filtering model for completely cold item recommendations. InProceedings of the 13th ACM Conference on Recom- mender Systems(Copenhagen, Denmark)(RecSys ’19). Association for Computing Machinery, New York, NY, USA, 228–236. doi:10.1145/3298689.3347038
-
[2]
Avrim Blum and Tom M. Mitchell. 1998. Combining Labeled and Unlabeled Data with Co-Training. InProceedings of the Eleventh Annual Conference on Computational Learning Theory, COLT 1998, Madison, Wisconsin, USA, July 24-26, 1998, Peter L. Bartlett and Yishay Mansour (Eds.). ACM, 92–100. doi:10.1145/ 279943.279962
-
[3]
Konstantinos Bousmalis, George Trigeorgis, Nathan Silberman, Dilip Krishnan, and Dumitru Erhan. 2016. Domain separation networks. InProceedings of the 30th International Conference on Neural Information Processing Systems(Barcelona, Spain)(NIPS’16). Curran Associates Inc., Red Hook, NY, USA, 343–351
2016
-
[4]
Robin Burke. 2002. Hybrid recommender systems: Survey and experiments.User modeling and user-adapted interaction12, 4 (2002), 331–370
2002
-
[5]
Jianlyu Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu
-
[6]
M3-Embedding: Multi-Linguality, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation. InFindings of the As- sociation for Computational Linguistics: ACL 2024, Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds.). Association for Computational Linguistics, Bangkok, Thailand, 2318–2335. doi:10.18653/v1/2024.findings-acl.137
-
[7]
Sunhao Dai, Chen Xu, Shicheng Xu, Liang Pang, Zhenhua Dong, and Jun Xu
-
[8]
InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining
Bias and unfairness in information retrieval systems: New challenges in the llm era. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 6437–6447
-
[9]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers). 4171–4186
2019
- [10]
-
[11]
Xiangnan He, Kuan Deng, Xiang Wang, Yan Li, YongDong Zhang, and Meng Wang. 2020. LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation. InProceedings of the 43rd International ACM SIGIR Confer- ence on Research and Development in Information Retrieval(Virtual Event, China) (SIGIR ’20). Association for Computing Machinery, New Yor...
-
[12]
Harold Hotelling. 1992. Relations between two sets of variates. InBreakthroughs in statistics: methodology and distribution. Springer, 162–190
1992
-
[13]
Yupeng Hou, Jiacheng Li, Zhankui He, An Yan, Xiusi Chen, and Julian McAuley
-
[14]
Bridging Language and Items for Retrieval and Recommendation.arXiv preprint arXiv:2403.03952(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Yupeng Hou, Shanlei Mu, Wayne Xin Zhao, Yaliang Li, Bolin Ding, and Ji-Rong Wen. 2022. Towards universal sequence representation learning for recommender systems. InProceedings of the 28th ACM SIGKDD conference on knowledge discovery and data mining. 585–593
2022
-
[16]
Mihee Lee and Vladimir Pavlovic. 2021. Private-shared disentangled multimodal vae for learning of latent representations. InProceedings of the ieee/cvf conference on computer vision and pattern recognition. 1692–1700
2021
-
[17]
Baolin Li, Yankai Jiang, Vijay Gadepally, and Devesh Tiwari. 2024. Llm infer- ence serving: Survey of recent advances and opportunities. In2024 IEEE High Performance Extreme Computing Conference (HPEC). IEEE, 1–8
2024
-
[18]
Jianghao Lin, Xinyi Dai, Yunjia Xi, Weiwen Liu, Bo Chen, Hao Zhang, Yong Liu, Chuhan Wu, Xiangyang Li, Chenxu Zhu, et al . 2025. How can recommender systems benefit from large language models: A survey.ACM Transactions on Information Systems43, 2 (2025), 1–47
2025
-
[19]
Zihan Lin, Changxin Tian, Yupeng Hou, and Wayne Xin Zhao. 2022. Improving graph collaborative filtering with neighborhood-enriched contrastive learning. InProceedings of the ACM web conference 2022. 2320–2329
2022
-
[20]
Cheng Liu, Chenhuan Yu, Ning Gui, Zhiwu Yu, and Songgaojun Deng. 2023. SimGCL: graph contrastive learning by finding homophily in heterophily.Knowl. Inf. Syst.66, 3 (Nov. 2023), 2089–2114. doi:10.1007/s10115-023-02022-1
- [21]
-
[22]
Yibin Liu, Jianyu Zhang, and Shijian Li. 2025. Enhancing Recommendation with Reliable Multi-profile Alignment and Collaborative-aware Contrastive Learning. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. 1936–1946
2025
-
[23]
Suphakit Niwattanakul, Jatsada Singthongchai, Ekkachai Naenudorn, and Su- pachanun Wanapu. 2013. Using of Jaccard coefficient for keywords similarity. InProceedings of the international multiconference of engineers and computer scientists, Vol. 1. 380–384
2013
-
[24]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. InInternational conference on machine learning. PmLR, 8748–8763
2021
-
[25]
Xubin Ren, Wei Wei, Lianghao Xia, Lixin Su, Suqi Cheng, Junfeng Wang, Dawei Yin, and Chao Huang. 2024. Representation learning with large language models for recommendation. InProceedings of the ACM web conference 2024. 3464–3475
2024
-
[26]
Steffen Rendle, Christoph Freudenthaler, Zeno Gantner, and Lars Schmidt-Thieme
-
[27]
InProceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence(Montreal, Quebec, Canada)(UAI ’09)
BPR: Bayesian personalized ranking from implicit feedback. InProceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence(Montreal, Quebec, Canada)(UAI ’09). AUAI Press, Arlington, Virginia, USA, 452–461
-
[28]
Leheng Sheng, An Zhang, Yi Zhang, Yuxin Chen, Xiang Wang, and Tat-Seng Chua
-
[29]
Language Representations Can be What Recommenders Need: Findings and Potentials. InICLR
-
[30]
Ajit Paul Singh and Geoffrey J. Gordon. 2008. Relational learning via collec- tive matrix factorization. InProceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, Nevada, USA, August 24-27, 2008, Ying Li, Bing Liu, and Sunita Sarawagi (Eds.). ACM, 650–658. doi:10.1145/1401890.1401969
-
[31]
Dong, Yuan Fang, and Hady W Lauw
Hoang V. Dong, Yuan Fang, and Hady W Lauw. 2025. A contrastive framework with user, item and review alignment for recommendation. InProceedings of the Eighteenth ACM International Conference on Web Search and Data Mining. 117–126
2025
-
[32]
MS Varun, Bhaskarjyoti Das, et al. 2024. Multimodal Recommendation Systems in the LLM Era: A Survey of Feature Representation and Fusion Methods. In2024 4th International Conference on Advanced Enterprise Information System (AEIS). IEEE, 89–95
2024
-
[33]
Chong Wang and David M Blei. 2011. Collaborative topic modeling for recom- mending scientific articles. InProceedings of the 17th ACM SIGKDD international conference on Knowledge discovery and data mining. 448–456
2011
- [34]
-
[35]
Chen Wang, Liangwei Yang, Zhiwei Liu, Xiaolong Liu, Mingdai Yang, Yueqing Liang, and Philip S Yu. 2024. Collaborative alignment for recommendation. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management. 2315–2325
2024
-
[36]
Hao Wang, Naiyan Wang, and Dit-Yan Yeung. 2015. Collaborative deep learning for recommender systems. InProceedings of the 21th ACM SIGKDD international conference on knowledge discovery and data mining. 1235–1244
2015
- [37]
-
[38]
Yuhao Wang, Junwei Pan, Pengyue Jia, Wanyu Wang, Maolin Wang, Zhixiang Feng, Xiaotian Li, Jie Jiang, and Xiangyu Zhao. 2025. Pre-train, align, and dis- entangle: Empowering sequential recommendation with large language models. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1455–1465
2025
-
[39]
Likang Wu, Zhi Zheng, Zhaopeng Qiu, Hao Wang, Hongchao Gu, Tingjia Shen, Chuan Qin, Chen Zhu, Hengshu Zhu, Qi Liu, et al . 2024. A survey on large language models for recommendation.World Wide Web27, 5 (2024), 60
2024
-
[40]
Eva Zangerle and Christine Bauer. 2022. Evaluating recommender systems: survey and framework.ACM computing surveys55, 8 (2022), 1–38
2022
-
[41]
Yang Zhang, Fuli Feng, Jizhi Zhang, Keqin Bao, Qifan Wang, and Xiangnan He
-
[42]
Collm: Integrating collaborative embeddings into large language models for recommendation.IEEE Transactions on Knowledge and Data Engineering(2025)
2025
-
[43]
Zihuai Zhao, Wenqi Fan, Jiatong Li, Yunqing Liu, Xiaowei Mei, Yiqi Wang, Zhen Wen, Fei Wang, Xiangyu Zhao, Jiliang Tang, et al. 2024. Recommender systems in the era of large language models (llms).IEEE Transactions on Knowledge and Data Engineering36, 11 (2024), 6889–6907. 11
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.