Recognition: unknown
Accelerating Intra-Node GPU-to-GPU Communication Through Multi-Path Transfers with CUDA Graphs
Pith reviewed 2026-05-08 09:57 UTC · model grok-4.3
The pith
Integrating CUDA Graphs into UCX enables up to 2.95x faster multi-path GPU-to-GPU communication.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
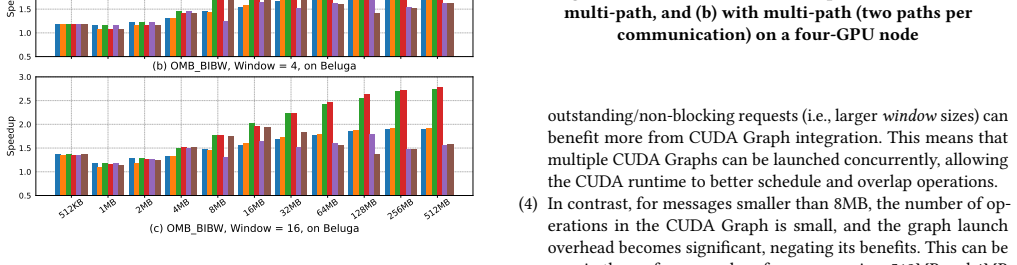
By integrating CUDA Graphs into UCX, the approach captures and replays optimized multi-path communication patterns, allowing concurrent use of the host path and two GPU paths to achieve up to 2.95 times the bandwidth of single-path UCX CUDA-IPC transfers for messages up to 512 MB in OMB tests.
What carries the argument
The CUDA Graph integration in UCX for concurrent multi-path transfers, which optimizes workflows by leveraging NVLink and PCIe paths simultaneously.
If this is right
- Bandwidth in GPU-to-GPU transfers improves significantly when multiple paths are used together under CUDA Graph control.
- Communication overhead decreases in MPI applications running on multi-GPU nodes.
- The first seamless integration of CUDA Graphs into UCX opens the door for similar optimizations in other frameworks.
- Performance holds for message sizes up to 512MB on tested hardware.
Where Pith is reading between the lines
- This method could be extended to larger GPU clusters if path diversity is available across nodes.
- Application developers might see benefits in non-OMB workloads like deep learning training data exchanges.
- Testing on different GPU generations would confirm if the gains generalize beyond the four-GPU node used here.
Load-bearing premise
That the overhead from CUDA Graph integration remains negligible and the multi-path configuration stays beneficial and stable on varied GPU hardware and system setups.
What would settle it
Running the OMB bandwidth test on the same four-GPU node and observing bandwidth no higher than the single-path baseline when activating the multi-path CUDA Graph feature would disprove the performance improvement.
Figures












read the original abstract
Effective intra-node GPU communication is essential for optimizing performance in MPI-based HPC applications, especially when leveraging multiple communication paths. In this study, we propose a novel approach that integrates CUDA Graphs into the UCX framework to enhance intra-node multi-path point-to-point GPU communication. By concurrently leveraging multiple paths, including NVLink and PCIe through the host, and optimizing communication workflows using CUDA Graph, we achieve significant reductions in communication overhead and improve execution efficiency. To the best of our knowledge, our proposed approach is the first to seamlessly integrate CUDA Graphs into UCX. Through extensive experiments on a four-GPU node, our proposed CUDA Graph-based multi-path communication approach achieves up to a 2.95x bandwidth improvement, compared to the single-path UCX (UCT::CUDA-IPC), in GPU-to-GPU OMB bandwidth test when utilizing the host path and two other GPU paths, at message sizes up to 512MB.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes integrating CUDA Graphs into the UCX framework to support concurrent multi-path intra-node GPU-to-GPU point-to-point communication (including NVLink and host PCIe paths). It claims this is the first such seamless integration and reports up to 2.95x bandwidth improvement over single-path UCX (UCT::CUDA-IPC) in OMB GPU-to-GPU bandwidth tests on a four-GPU node for message sizes up to 512 MB.
Significance. If the experimental results hold under scrutiny, the work could meaningfully improve communication efficiency in MPI-based HPC applications on multi-GPU nodes by reducing launch overhead via CUDA Graphs while exploiting multiple hardware paths. The engineering novelty of embedding CUDA Graphs within UCX is a clear strength.
major comments (1)
- [Experimental results / OMB bandwidth tests] The central performance claim (2.95x bandwidth improvement) is presented without details on the number of runs, error bars, exact path configurations (which two GPU paths plus host), driver versions, or controls for cache effects. This information is load-bearing for assessing whether the observed gain is robust or reproducible.
minor comments (1)
- [Abstract] The abstract states the approach 'optimizes communication workflows using CUDA Graph' but does not clarify how graph capture is performed around UCX calls or whether any modifications to UCX internals were required.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address the major comment below and will revise the manuscript to improve experimental reproducibility.
read point-by-point responses
-
Referee: [Experimental results / OMB bandwidth tests] The central performance claim (2.95x bandwidth improvement) is presented without details on the number of runs, error bars, exact path configurations (which two GPU paths plus host), driver versions, or controls for cache effects. This information is load-bearing for assessing whether the observed gain is robust or reproducible.
Authors: We agree that the manuscript omits these details, which are necessary for full reproducibility and scrutiny of the results. In the revised version we will expand the experimental setup section to specify the number of runs performed for each measurement, include error bars on all reported bandwidth values, provide precise descriptions of the communication paths (including which GPU pairs use NVLink versus the host PCIe path), state the CUDA driver and software versions used, and describe the controls applied to mitigate cache effects. These additions will be placed in Section 4 and will allow readers to better evaluate the robustness of the reported 2.95x improvement. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's central contribution is an engineering implementation that integrates CUDA Graphs into the UCX framework for multi-path intra-node GPU communication, with performance evaluated through direct benchmarking against an external baseline (single-path UCT::CUDA-IPC). No mathematical derivation, parameter fitting presented as prediction, or self-referential equations appear in the abstract or described claims. The reported 2.95x bandwidth improvement is an observed experimental outcome on a four-GPU node rather than a result forced by definition or prior self-citation, rendering the chain self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2025. CUDA. https://docs.nvidia.com/cuda/index.html [Accessed: 2025-04-01]
2025
-
[2]
CUDA Graphs
2025. CUDA Graphs. https://developer.nvidia.com/blog/cuda-graphs/ https: //developer.nvidia.com/blog/cuda-graphs/ [Accessed: 2025-04-01]
2025
-
[3]
CUDA Graphs in Dynamic Environments
2025. CUDA Graphs in Dynamic Environments. https://developer. nvidia.com/blog/employing-cuda-graphs-in-a-dynamic-environment/ https://developer.nvidia.com/blog/employing-cuda-graphs-in-a-dynamic- environment/ [Accessed: 2025-04-01]
2025
-
[4]
InfiniBand Trade Association
2025. InfiniBand Trade Association. https://www.infinibandta.org/ https: //www.infinibandta.org/ [Accessed: 2025-04-01]
2025
-
[5]
Multi-GPU Jacobi Solver
2025. Multi-GPU Jacobi Solver. https://github.com/NVIDIA/multi-gpu- programming-models https://github.com/NVIDIA/multi-gpu-programming- models [Accessed: 2025-04-01]
2025
-
[6]
Bernholdt, Swen Boehm, George Bosilca, Manjunath Gorentla Venkata, Ryan E
David E. Bernholdt, Swen Boehm, George Bosilca, Manjunath Gorentla Venkata, Ryan E. Grant, Thomas Naughton, Howard P. Pritchard, Martin Schulz, and Geoffroy R. Vallee. 2020. A survey of MPI usage in the US exascale computing project.Concurrency and Computation: Practice and Experience (CCPE)3 (2020), 1–16. doi:10.1002/cpe.4851
-
[7]
Devendar Bureddy, H. Wang, A. Venkatesh, S. Potluri, and D. K. Panda. 2012. OMB-GPU: A micro-benchmark suite for evaluating MPI libraries on GPU clus- ters. InProceedings of the European MPI Users’ Group Meeting (EuroMPI). 110–120. doi:10.1007/978-3-642-33518-1_16
-
[8]
Chen Chun Chen, Kawthar Shafie Khorassani, Pouya Kousha, Qinghua Zhou, Jinghan Yao, Hari Subramoni, and Dhabaleswar K. Panda. 2023. MPI-xCCL: A Portable MPI Library over Collective Communication Libraries for Various Accelerators. InProceedings of the SC Workshops of The International Conference on High Performance Computing, Network, Storage, and Analysi...
-
[9]
Yuxin Chen, Benjamin Brock, Katherine Yelick, and John D Owens. 2022. Scalable Irregular Parallelism with GPUs : Getting CPUs Out of the Way. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC). 1–16. doi:10.1109/SC41404.2022.00055
-
[10]
Jaemin Choi, David F. Richards, and Laxmikant V. Kale. 2022. Improving Scalabil- ity with GPU-Aware Asynchronous Tasks. InProceedings of the IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW). IEEE, 1–10. arXiv:2202.11819 doi:10.1109/IPDPSW55747.2022.00097
- [11]
- [12]
-
[13]
Dian Lun Lin and Tsung Wei Huang. 2021. Efficient GPU Computation Using Task Graph Parallelism. InProceedings of the European Conference on Parallel Processing (Euro-Par). Springer International Publishing, 435–450. doi:10.1007/978-3-030- 85665-6_27
-
[14]
MPI Forum. 2025. https://www.mpi-forum.org/ [Accessed: 2025-04-01]
2025
-
[15]
MPICH. 2025. https://www.mpich.org/ [Accessed: 2025-04-01]
2025
-
[16]
Akira Nukada. 2022. Performance Optimization of Allreduce Operation for Multi-GPU Systems. InProceedings of the International Conference on Big Data (Big Data). IEEE, 1–6. doi:10.1109/bigdata52589.2021.9672073
-
[17]
NVIDIA. 2025. https://www.nvidia.com/ [Accessed: 2025-04-01]
2025
-
[18]
NVIDIA. 2025. NVIDIA Collective Communications Library. https://github. com/NVIDIA/nccl [Accessed: 2025-04-01]
2025
-
[19]
Open MPI. 2025. https://www.open-mpi.org/ [Accessed: 2025-04-01]
2025
-
[20]
Akif Ozkan, Jurgen Teich, and Frank Hannig
Bo Qiao, M. Akif Ozkan, Jurgen Teich, and Frank Hannig. 2020. The best of both worlds: Combining CUDA graph with an image processing DSL. InProceedings of the ACM/IEEE Design Automation Conference (DAC). 1–6. doi:10.1109/DAC18072. 2020.9218531
-
[21]
Pavel Shamis, Manjunath Gorentla Venkata, M Graham Lopez, Matthew B Baker, Oscar Hernandez, Yossi Itigin, Mike Dubman, Gilad Shainer, Richard L Graham, Liran Liss, and Yiftah Shahar. 2015. UCX : An Open Source Framework for HPC Network APIs and Beyond. InProceedings of the IEEE Symposium on High- Performance Interconnects (HOTI). IEEE, 40–43. doi:10.1109/...
-
[22]
Amirhossein Sojoodi, Mohammad Akbari, Hamed Sharifian, Ali Farazdaghi, Ryan E. Grant, and Ahmad Afsahi. 2025. Accelerating Intra-Node GPU Com- munication: A Performance Model for Multi-Path Transfers. InProceedings of the Workshops of the International Conference on High Performance Computing, Network, Storage, and Analysis (SC-W). Association for Computi...
-
[23]
Amirhossein Sojoodi, Ali Farazdaghi, Hamed Sharifian, Ryan E Grant, and Ah- mad Afsahi. 2025. Collaborative Bandwidth-Efficient Intra-Node Allreduce. In Proceedings of the International Workshop on Accelerators and Hybrid Emerging Systems (AsHES). 1–5. doi:10.1109/IPDPSW66978.2025.00016
-
[24]
Amirhossein Sojoodi, Majid Salimi Beni, and Farshad Khunjush. 2020. Ignite- GPU: a GPU-enabled in-memory computing architecture on clusters.Journal of Supercomputing(2020), 1–28. doi:10.1007/s11227-020-03390-z
-
[25]
Amirhossein Sojoodi, Yıltan Hassan Temucin, and Ahmad Afsahi. 2024. Enhanc- ing Intra-Node GPU-to-GPU Performance in MPI + UCX through Multi-Path Communication. InProceedings of the International Workshop on Extreme Hetero- geneity Solutions (ExHET). 1–6. doi:10.1145/3642961.3643800
-
[26]
Yuya Tatsugi and Akira Nukada. 2022. Accelerating data transfer between host and device using idle GPU. InProceedings of the Workshop on General Purpose Processing using GPUs (GPGPU). 1–6. doi:10.1145/3530390.3532732
-
[27]
Yıltan Hassan Temucin, Amirhossein Sojoodi, Pedram Alizadeh, and Ahmad Afsahi. 2021. Efficient Multi-Path NVLink / PCIe-Aware UCX based Collective Communication for Deep Learning. InProceedings of the IEEE Symposium on High-Performance Interconnects (HOTI). 1–10. doi:10.1109/HOTI52880.2021.00018
- [28]
-
[29]
Top500. 2025. https://top500.org/ [Accessed: 2025-04-01]
2025
-
[30]
Unified Communication Framework Consortium. 2025. Unified Collective Com- munication (UCC). https://github.com/openucx/ucc [Accessed: 2025-04-01]
2025
-
[31]
Unified Communication Framework Consortium. 2025. Unified Communication X (UCX). https://openucx.org/ [Accessed: 2025-04-01]
2025
-
[32]
Manjunath Gorentla Venkata, Valentine Petrov, Sergey Lebedev, Devendar Bu- reddy, Ferrol Aderholdt, Joshua Ladd, Gil Bloch, Mike Dubman, and Gilad Shainer
-
[33]
In2024 IEEE Symposium on High-Performance Interconnects (HOTI)
Unified Collective Communication ( UCC ): An Unified Library for CPU , GPU , and DPU Collectives. InProceedings of the IEEE Symposium on High- Performance Interconnects (HOTI). IEEE, 37–46. doi:10.1109/HOTI63208.2024. 00018
-
[34]
Yuxuan Zhao, Qi Sun, Zhuolun He, Yang Bai, and Bei Yu. 2023. AutoGraph: Optimizing DNN Computation Graph for Parallel GPU Kernel Execution. Proceedings of the AAAI Conference on Artificial Intelligence37 (2023), 1–9. doi:10.1609/aaai.v37i9.26343
-
[35]
Bojian Zheng, Cody Hao Yu, Jie Wang, Yaoyao Ding, Yizhi Liu, Yida Wang, and Gennady Pekhimenko. 2023. Grape: Practical and Efficient Graphed Execution for Dynamic Deep Neural Networks on GPUs. InProceedings of the International Sym- posium on Microarchitecture (MICRO). 1364–1380. doi:10.1145/3613424.3614248
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.