Recognition: unknown
Learning Control Policies to Provably Satisfy Hard Affine Constraints for Black-Box Hybrid Dynamical Systems
Pith reviewed 2026-05-08 11:33 UTC · model grok-4.3
The pith
RL policies made affine and repulsive near boundaries can provably keep black-box hybrid systems inside affine constraints without knowing their dynamics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By restricting the learned policy to be affine and repulsive near the constraint boundaries for the unknown nonlinear dynamics and introducing a second repulsive affine region before each affine reset, the closed-loop trajectories of black-box hybrid systems provably satisfy the hard affine state constraints.
What carries the argument
An affine repulsive policy structure that outputs controls directing the state away from the unsafe set near each constraint boundary, plus a pre-reset repulsive zone that prevents post-jump violations.
Load-bearing premise
That an affine repulsive policy structure, without any knowledge of the unknown nonlinear dynamics, is sufficient to prevent constraint violations both during continuous flow and immediately after affine resets.
What would settle it
A concrete hybrid system, affine constraint, and learned policy satisfying the sufficient conditions for which a closed-loop trajectory starting from a safe initial state reaches the unsafe region either in flow or after a reset.
Figures






read the original abstract
Ensuring safety for black-box hybrid dynamical systems presents significant challenges due to their instantaneous state jumps and unknown explicit nonlinear dynamics. Existing solutions for strict safety constraint satisfaction, like control barrier functions (CBFs) and reachability analysis, rely on direct knowledge of the dynamics. Similarly, safe reinforcement learning (RL) approaches often rely on known system dynamics or merely discourage safety violations through reward shaping. In this work, we want to learn RL policies which provably satisfy affine state constraints in closed loop for black-box hybrid dynamical systems with affine reset maps. Our key insight is forcing the RL policy to be affine and repulsive near the constraint boundaries for the unknown nonlinear dynamics of the system, providing guarantees that the trajectories will not violate the constraint. We further account for constraint violation due to instantaneous state jumps that occur due to impacts or reset maps in the hybrid system by introducing a second repulsive affine region before the reset that prevents post-reset states from violating the constraint. We derive sufficient conditions under which these policies satisfy safety constraints in closed loop. We also compare our approach with state-of-the-art reward shaping and learned-CBF methods on hybrid dynamical systems like the constrained pendulum and paddle juggler environments. In both scenarios, we show that our methodology learns higher quality policies while always satisfying the safety constraints.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes learning RL policies for black-box hybrid dynamical systems (unknown nonlinear continuous dynamics, known affine resets) that provably satisfy hard affine state constraints. The key idea is to restrict policies to an affine repulsive structure near constraint boundaries (to repel trajectories from violation during flow) plus a second pre-reset repulsive affine region (to ensure post-jump states remain safe). Sufficient conditions are derived under which these structured policies guarantee closed-loop safety; experiments on constrained pendulum and paddle-juggler hybrids show the method learns higher-quality policies than reward-shaping or learned-CBF baselines while never violating constraints.
Significance. If the derived sufficient conditions truly guarantee safety for arbitrary unknown nonlinear f without hidden bounds or data-dependent certification of gains, the result would be significant: it supplies hard, model-free safety for hybrid systems via policy structure rather than CBFs or reachability that require known dynamics. The handling of affine resets via pre-reset repulsion is a concrete technical contribution, and the empirical outperformance on two hybrid benchmarks supports practicality. The approach could influence safe RL for impact-rich robotics if the guarantees hold.
major comments (2)
- [derivation of sufficient conditions] The derivation of sufficient conditions (abstract and § on policy structure) for the affine repulsive policy to prevent constraint violations under completely unknown nonlinear f(x, π(x)) must be examined for implicit dependence on bounds on ||f|| or its Lipschitz constant. For arbitrary black-box f, any finite repulsive gain can be overpowered near the boundary, so the conditions are load-bearing for the 'provably' claim; if they require a priori bounds or data-driven gain selection not stated in the abstract, the guarantee does not hold for general black-box hybrids.
- [hybrid reset handling] The pre-reset repulsive region is introduced to handle affine resets, but the interaction between the continuous repulsive policy, the reset map, and the unknown flow immediately before reset needs explicit verification that post-reset states remain inside the constraint for all possible pre-reset trajectories consistent with the unknown dynamics.
minor comments (2)
- [policy parameterization] Clarify the precise form of the affine repulsive policy (e.g., how the repulsive term is parameterized and whether it remains affine globally or only locally near boundaries) to aid reproducibility.
- [experiments] The experimental section should report the exact number of trials, variance in constraint satisfaction (even if zero), and whether any hyperparameter tuning was performed on the baselines for fair comparison.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below, providing clarifications on the safety guarantees and indicating where revisions will strengthen the manuscript.
read point-by-point responses
-
Referee: [derivation of sufficient conditions] The derivation of sufficient conditions (abstract and § on policy structure) for the affine repulsive policy to prevent constraint violations under completely unknown nonlinear f(x, π(x)) must be examined for implicit dependence on bounds on ||f|| or its Lipschitz constant. For arbitrary black-box f, any finite repulsive gain can be overpowered near the boundary, so the conditions are load-bearing for the 'provably' claim; if they require a priori bounds or data-driven gain selection not stated in the abstract, the guarantee does not hold for general black-box hybrids.
Authors: The sufficient conditions in the policy structure section are derived to hold independently of any a priori bounds on ||f|| or its Lipschitz constant. By restricting the policy to an affine repulsive form in a neighborhood of each constraint boundary, the closed-loop dynamics are structurally forced to produce a strictly negative time derivative of the affine constraint function, repelling trajectories from violation for any continuous unknown nonlinear f. This follows directly from the affine parameterization without requiring knowledge of f or data-driven tuning of gains beyond the RL optimization itself. The abstract claim is therefore accurate as stated for general black-box hybrids. To address the referee's concern, we will add an explicit remark in the revised abstract and policy structure section confirming the absence of such bounds or selection procedures. revision: partial
-
Referee: [hybrid reset handling] The pre-reset repulsive region is introduced to handle affine resets, but the interaction between the continuous repulsive policy, the reset map, and the unknown flow immediately before reset needs explicit verification that post-reset states remain inside the constraint for all possible pre-reset trajectories consistent with the unknown dynamics.
Authors: We agree that an explicit verification of this interaction is valuable. Because the reset map is known and affine, the pre-reset repulsive region is sized so that its image under the reset lies strictly inside the safe set. The continuous repulsive policy ensures that trajectories remain in this region until a reset occurs. To cover all possible pre-reset flows under the unknown dynamics, we will add a supporting lemma in the hybrid reset handling section proving that the forward-invariant set induced by the repulsive policy before reset is mapped safely by the affine reset for any admissible pre-reset trajectory. This will be included in the revised manuscript. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper selects an affine repulsive policy structure by design and derives sufficient conditions for closed-loop constraint satisfaction under unknown nonlinear flow and known affine resets. No quoted step reduces the central claim to a fitted parameter renamed as a prediction, a self-definitional loop, or a load-bearing self-citation chain. The approach is an explicit ansatz plus forward derivation of inequalities, independent of the target safety result by construction. No patterns from the enumerated circularity kinds are exhibited.
Axiom & Free-Parameter Ledger
axioms (2)
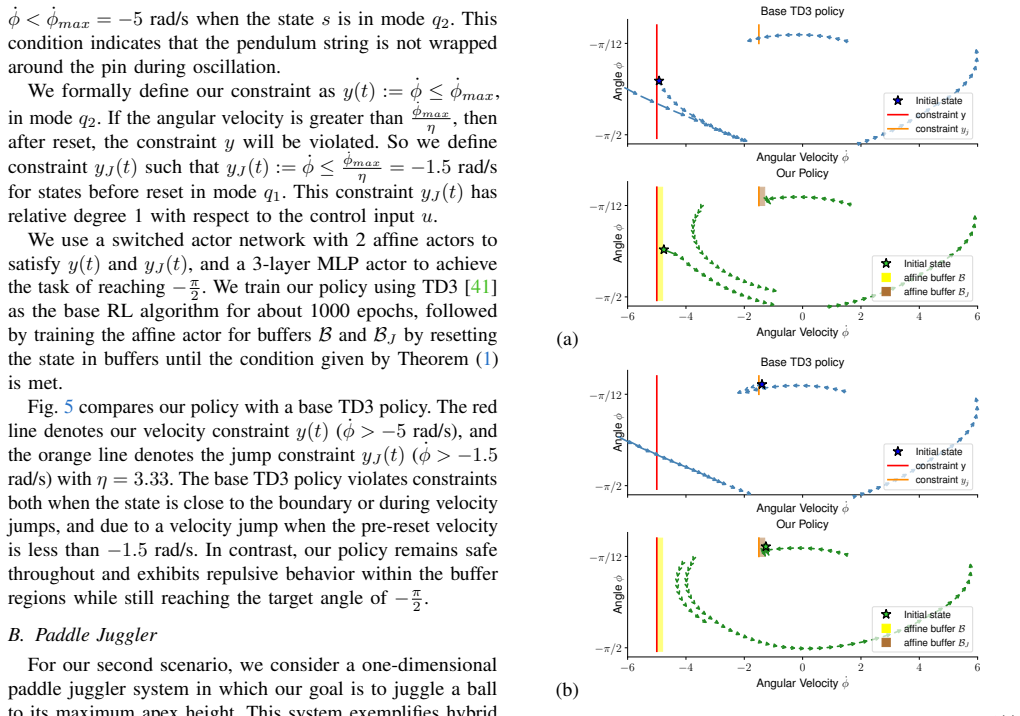
- domain assumption Reset maps are affine
- ad hoc to paper Affine repulsive policy structure yields closed-loop safety under derived sufficient conditions
invented entities (1)
-
Repulsive affine region before reset
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Lygeros, S
J. Lygeros, S. Sastry, and C. Tomlin,Hybrid Systems: Modeling, Analysis and Control. Cambridge University Press, 2008
2008
-
[2]
Hybrid dynamical systems,
R. Goebel, R. G. Sanfelice, and A. R. Teel, “Hybrid dynamical systems,” IEEE Control Systems Magazine, pp. 28–93, 2009
2009
-
[3]
Constrained policy optimization,
J. Achiam, D. Held, A. Tamar, and P. Abbeel, “Constrained policy optimization,” inProceedings of the 34th International Conference on Machine Learning - Volume 70, 2017, p. 22–31
2017
-
[4]
Model-free safe reinforcement learning through neural barrier certificate,
Y . Yang, Y . Jiang, Y . Liu, J. Chen, and S. E. Li, “Model-free safe reinforcement learning through neural barrier certificate,”IEEE Robotics and Automation Letters, vol. 8, no. 3, pp. 1295–1302, 2023
2023
-
[5]
Policed rl: Learning closed- loop robot control policies with provable satisfaction of hard constraints,
J.-B. Bouvier, K. Nagpal, and N. Mehr, “Policed rl: Learning closed- loop robot control policies with provable satisfaction of hard constraints,” inRobotics: Science and Systems (RSS), 2024
2024
-
[6]
Learning to provably satisfy high relative degree constraints for black-box systems,
J. Bouvier, K. Nagpal, and N. Mehr, “Learning to provably satisfy high relative degree constraints for black-box systems,” inIEEE Conference on Decision and Control (CDC), 2024
2024
-
[7]
Control barrier functions: Theory and applications,
A. D. Ames, S. Coogan, M. Egerstedt, G. Notomista, K. Sreenath, and P. Tabuada, “Control barrier functions: Theory and applications,” in 18th European Control Conference (ECC), 2019, pp. 3420–3431
2019
-
[8]
Safe control synthesis for hybrid systems through local control barrier functions,
S. Yang, M. Black, G. Fainekos, B. Hoxha, H. Okamoto, and R. Mangharam, “Safe control synthesis for hybrid systems through local control barrier functions,” inAmerican Control Conference, 2024
2024
-
[9]
Learning local control barrier functions for hybrid systems,
S. Yang, Y . Chen, X. Yin, G. J. Pappas, and R. Mangharam, “Learning local control barrier functions for hybrid systems,” 2024
2024
-
[10]
Discrete control barrier functions for safety-critical control of discrete systems with application to bipedal robot navigation,
A. Agrawal and K. Sreenath, “Discrete control barrier functions for safety-critical control of discrete systems with application to bipedal robot navigation,” inRobotics: Science and Systems, 2017
2017
-
[11]
A hybrid model predictive control framework for docking and stabilization of composite rigid spacecraft dynamics,
H. Basu, P. Jirwankar, R. Sanfelice, M. Castroviejo-Fernandez, and I. Kolmanovsky, “A hybrid model predictive control framework for docking and stabilization of composite rigid spacecraft dynamics,” in AIAA SCITECH 2026 Forum, 2026
2026
-
[12]
Safety verification of hybrid systems using barrier certificates,
S. Prajna and A. Jadbabaie, “Safety verification of hybrid systems using barrier certificates,” inHybrid Systems: Computation and Control. Springer Berlin Heidelberg, 2004, pp. 477–492
2004
-
[13]
A theory of timed automata,
R. Alur and D. L. Dill, “A theory of timed automata,”Theoretical Computer Science, vol. 126, no. 2, pp. 183–235, 1994
1994
-
[14]
Hybrid automata: An algorithmic approach to the specification and verification of hybrid systems,
R. Alur, C. Courcoubetis, T. A. Henzinger, and P.-H. Ho, “Hybrid automata: An algorithmic approach to the specification and verification of hybrid systems,” inProceedings of the International Hybrid Systems Workshop. Springer, 1991, pp. 209–229
1991
-
[15]
Hamilton-jacobi reachability: A brief overview and recent advances,
S. Bansal, M. Chen, S. Herbert, and C. J. Tomlin, “Hamilton-jacobi reachability: A brief overview and recent advances,” inProceedings of the IEEE Conference on Decision and Control (CDC), 2017
2017
-
[16]
Hamilton- jacobi reachability analysis for hybrid systems with controlled and forced transitions,
J. Borquez, S. Peng, L. Y . Chen, Q. Nguyen, and S. Bansal, “Hamilton- jacobi reachability analysis for hybrid systems with controlled and forced transitions,”ArXiv, vol. abs/2309.10893, 2023
-
[17]
Bridging hamilton-jacobi safety analysis and reinforcement learning,
J. F. Fisac, N. F. Lugovoy, V . Rubies-Royo, S. Ghosh, and C. J. Tomlin, “Bridging hamilton-jacobi safety analysis and reinforcement learning,” in2019 International Conference on Robotics and Automation (ICRA), 2019, pp. 8550–8556
2019
-
[18]
Deepreach: A deep learning approach to high-dimensional reachability,
S. Bansal and C. J. Tomlin, “Deepreach: A deep learning approach to high-dimensional reachability,” in2021 IEEE International Conference on Robotics and Automation (ICRA), 2021, pp. 1817–1824
2021
-
[19]
Reachability analysis for black-box dynamical systems,
V . K. Chilakamarri, Z. Feng, and S. Bansal, “Reachability analysis for black-box dynamical systems,” 2024
2024
-
[20]
Challenges of real-world reinforcement learning: definitions, benchmarks and analysis,
G. Dulac-Arnold, N. Levine, D. J. Mankowitz, T. Li, and e. Padu- raru, “Challenges of real-world reinforcement learning: definitions, benchmarks and analysis,”Machine Learning, pp. 2419–2468, 2021
2021
-
[21]
Safe learning in robotics: From learning-based control to safe reinforcement learning,
L. Brunke, M. Greeff, A. W. Hall, Z. Yuan, S. Zhou, J. Panerati, and A. P. Schoellig, “Safe learning in robotics: From learning-based control to safe reinforcement learning,”Annual Review of Control, Robotics, and Autonomous Systems, pp. 411–444, 2022
2022
-
[22]
Altman,Constrained Markov Decision Processes
E. Altman,Constrained Markov Decision Processes. Routledge, 2021
2021
-
[23]
State-wise constrained policy optimization,
W. Zhao, R. Chen, Y . Sun, T. Wei, and C. Liu, “State-wise constrained policy optimization,”arXiv preprint arXiv:2306.12594, 2023
-
[24]
Constrained policy optimization,
J. Achiam, D. Held, A. Tamar, and P. Abbeel, “Constrained policy optimization,” inProceedings of the International Conference on Machine Learning (ICML). PMLR, 2017, pp. 22–31
2017
-
[25]
Learn with imagination: Safe set guided state-wise constrained policy optimization,
W. Zhao, Y . Sun, F. Li, R. Chen, T. Wei, and C. Liu, “Learn with imagination: Safe set guided state-wise constrained policy optimization,” arXiv preprint arXiv:2308.13140, 2023
-
[26]
A review of safe reinforcement learning: Methods, theory and applications,
S. Gu, L. Yang, Y . Du, G. Chen, F. Walter, J. Wang, Y . Yang, and A. Knoll, “A review of safe reinforcement learning: Methods, theory and applications,”arXiv preprint arXiv:2205.10330, 2022
-
[27]
Conbat: Control barrier transformer for safe policy learning,
Y . Meng, S. H. Vemprala, R. Bonatti, C. Fan, and A. Kapoor, “Conbat: Control barrier transformer for safe policy learning,”ArXiv, vol. abs/2303.04212, 2023
-
[28]
Sablas: Learning safe control for black- box dynamical systems,
Z. Qin, D. Sun, and C. Fan, “Sablas: Learning safe control for black- box dynamical systems,”IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 1928–1935, 2022
1928
-
[29]
Joint synthesis of safety certificate and safe control policy using constrained reinforcement learning,
H. Ma, C. Liu, S. Li, S. Zheng, and J. Chen, “Joint synthesis of safety certificate and safe control policy using constrained reinforcement learning,” inProceedings of the Learning for Dynamics and Control Conference (L4DC). PMLR, 2022, pp. 97–109
2022
-
[30]
Sampling-based safe reinforcement learning for nonlinear dynamical systems,
W. A. Suttle, V . K. Sharma, K. C. Kosaraju, S. Sivaranjani, and et. al, “Sampling-based safe reinforcement learning for nonlinear dynamical systems,”International Conference on Artificial Intelligence and Statistics, 2024
2024
-
[31]
Control barrier functions for unknown nonlinear systems using gaussian processes,
P. Jagtap, G. J. Pappas, and M. Zamani, “Control barrier functions for unknown nonlinear systems using gaussian processes,” in59th IEEE Conference on Decision and Control (CDC), 2020, pp. 3699–3704
2020
-
[32]
Anytime safe reinforcement learning,
P. Mestres, A. Marzabal, and J. Cortes, “Anytime safe reinforcement learning,” inProceedings of the 7th Annual Learning for Dynamics & Control Conference, ser. Proceedings of Machine Learning Research, vol. 283. PMLR, 04–06 Jun 2025, pp. 221–232
2025
-
[33]
Learning-based model predictive control: Toward safe learning in control,
L. Hewing, K. P. Wabersich, M. Menner, and M. N. Zeilinger, “Learning-based model predictive control: Toward safe learning in control,”Annual Review of Control, Robotics, and Autonomous Systems, vol. 3, pp. 269–296, 2020
2020
-
[34]
Provably safe and robust learning-based model predictive control,
A. Aswani, H. Gonzalez, S. S. Sastry, and C. Tomlin, “Provably safe and robust learning-based model predictive control,”Automatica, vol. 49, no. 5, pp. 1216–1226, 2013
2013
-
[35]
A multi-model structure for model predictive control,
F. Di Palma and L. Magni, “A multi-model structure for model predictive control,”Annual Reviews in Control, pp. 47–52, 2004
2004
-
[36]
Stochastic mpc with offline uncertainty sampling,
M. Lorenzen, F. Dabbene, R. Tempo, and F. Allgöwer, “Stochastic mpc with offline uncertainty sampling,”Automatica, pp. 176–183, 2017
2017
-
[37]
A predictive safety filter for learning-based control of constrained nonlinear dynamical systems,
K. P. Wabersich and M. N. Zeilinger, “A predictive safety filter for learning-based control of constrained nonlinear dynamical systems,” Automatica, vol. 129, p. 109597, 2021
2021
-
[38]
Hybrid control in air traffic management systems1,
C. Tomlin, G. Pappas, J. Lygeros, D. Godbole, S. Sastry, and G. Meyer, “Hybrid control in air traffic management systems1,”IFAC Proceedings Volumes, vol. 29, no. 1, pp. 5512–5517, 1996, 13th World Congress of IFAC, 1996, San Francisco USA, 30 June - 5 July
1996
-
[39]
Terrain- adaptive, alip-based bipedal locomotion controller via model predictive control and virtual constraints,
G. Gibson, O. Dosunmu-Ogunbi, Y . Gong, and J. Grizzle, “Terrain- adaptive, alip-based bipedal locomotion controller via model predictive control and virtual constraints,” inIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2022, pp. 6724–6731
2022
-
[40]
High relative degree control barrier functions under input constraints,
J. Breeden and D. Panagou, “High relative degree control barrier functions under input constraints,” in2021 60th IEEE Conference on Decision and Control (CDC), 2021, pp. 6119–6124
2021
-
[41]
Addressing function approximation error in actor-critic methods,
S. Fujimoto, H. van Hoof, and D. Meger, “Addressing function approximation error in actor-critic methods,” inProceedings of the 35th International Conference on Machine Learning (ICML). PMLR, 2018, pp. 1587–1596
2018
-
[42]
Grünbaum, V
B. Grünbaum, V . Kaibel, V . Klee, and G. M. Ziegler,Convex Polytopes. Springer Science & Business Media, 2003. VII. APPENDIX A. BufferBis a convex polytope Lemma 2.BufferBis a polytope.[5] Proof. We can write buffer B as B=C ′([d−r, d])∩S i where C ′([d−r, d]) denotes the inverse image of the interval [d−r, d], meaning C ′([d−r, d]) :={s:Cs∈[d−r, d]} . N...
2003
-
[43]
Constrained Pendulum:We define the continuous state vector as s= [ϕ, ˙ϕ]⊤, where ϕ denotes the pendulum’s angle with the vertical line and ˙ϕ its angular velocity. The dynamics governing continuous state transitions within mode q1 are given by: ¨ϕ=− g l sin(ϕ)− z m ˙ϕ+u, (23) where g is the gravity coefficient, m is the mass of the pendulum, z is the damp...
-
[44]
The guard condition is G=x b −x p ≤0 , and the reset map is R(s) = [xb,(1 +e) ˙x p −e˙xb, x p,˙x p]⊤ where e∈[0,1] is the coefficient of restitution
Paddle Juggler:The one-dimensional paddle juggler system is the hybrid system with a single discrete mode q with continuous state, x= [x b,˙xb, xp,˙xp]⊤ containing the ball’s and paddle’s vertical positions and velocities. The guard condition is G=x b −x p ≤0 , and the reset map is R(s) = [xb,(1 +e) ˙x p −e˙xb, x p,˙x p]⊤ where e∈[0,1] is the coefficient ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.