Recognition: unknown
Listening with Time: Precise Temporal Awareness for Long-Form Audio Understanding
Pith reviewed 2026-05-08 09:05 UTC · model grok-4.3
The pith
LAT-Audio maintains temporal accuracy on long audio by constructing a global timeline before applying iterative local reasoning through tool use.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that temporal awareness in long-form audio can be achieved through a progressive global-to-local reasoning paradigm where a global timeline serves as an aligned temporal-semantic context, followed by the Think-With-Audio Chain-of-Thought (TWA-CoT) that performs iterative reasoning by incorporating local audio information via tool use.
What carries the argument
The Think-With-Audio Chain-of-Thought (TWA-CoT), which carries out iterative local reasoning by tool-calling after the construction of a global timeline as aligned context.
If this is right
- LAT-Audio outperforms prior models on dense audio captioning, temporal audio grounding, and targeted captioning for long inputs.
- The method shows improved robustness as input audio duration increases up to 30 minutes.
- Global timeline construction combined with tool-based local reasoning corrects temporal misalignments effectively.
- Releasing the dataset and benchmark enables further research on long-form audio temporal tasks.
Where Pith is reading between the lines
- Similar global-to-local strategies could be adapted for long-form video understanding or multimodal timelines.
- Reducing reliance on tool-calling errors might further improve performance on very long recordings.
- Applications in audio surveillance or podcast analysis could benefit from precise temporal grounding.
- Future work might test the approach on audio longer than 30 minutes or in noisy conditions.
Load-bearing premise
That the global timeline construction followed by iterative tool-use reasoning will reliably fix temporal misalignments without adding new errors from the tool calls or dataset issues as duration grows.
What would settle it
A test showing that LAT-Audio's temporal error rates on LAT-Bench increase with audio length beyond a point, or that the tool-calling step introduces more misalignments than it fixes.
Figures


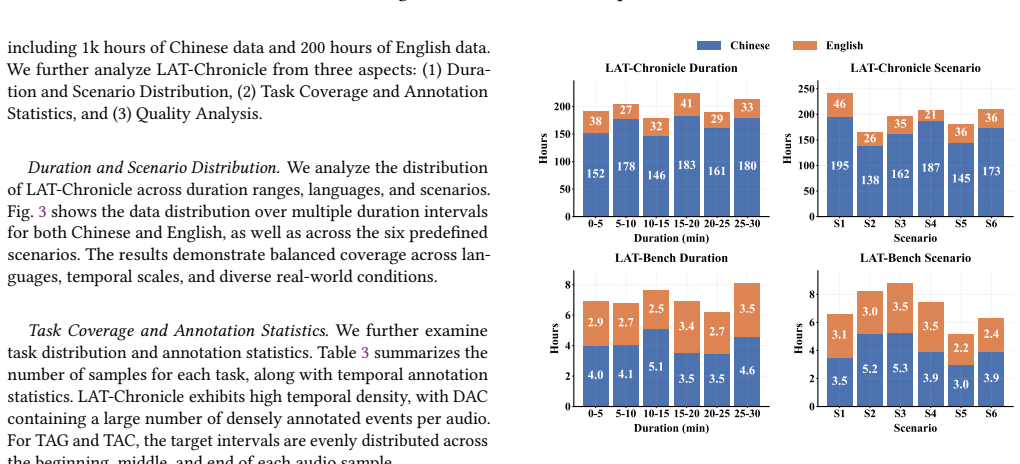
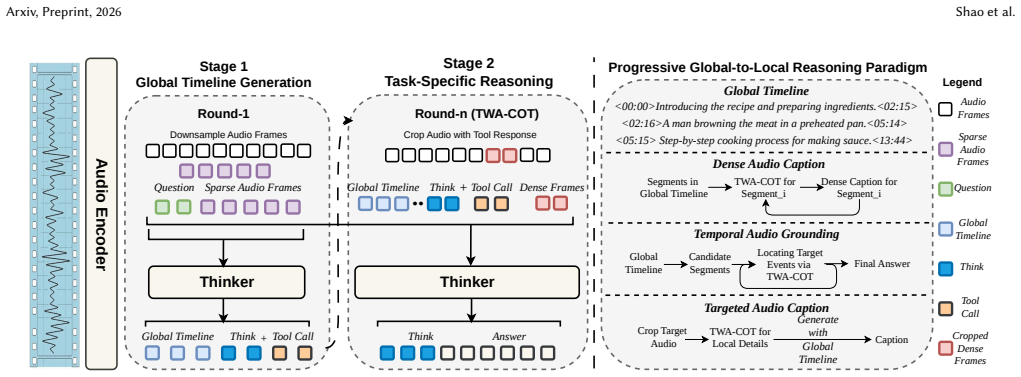
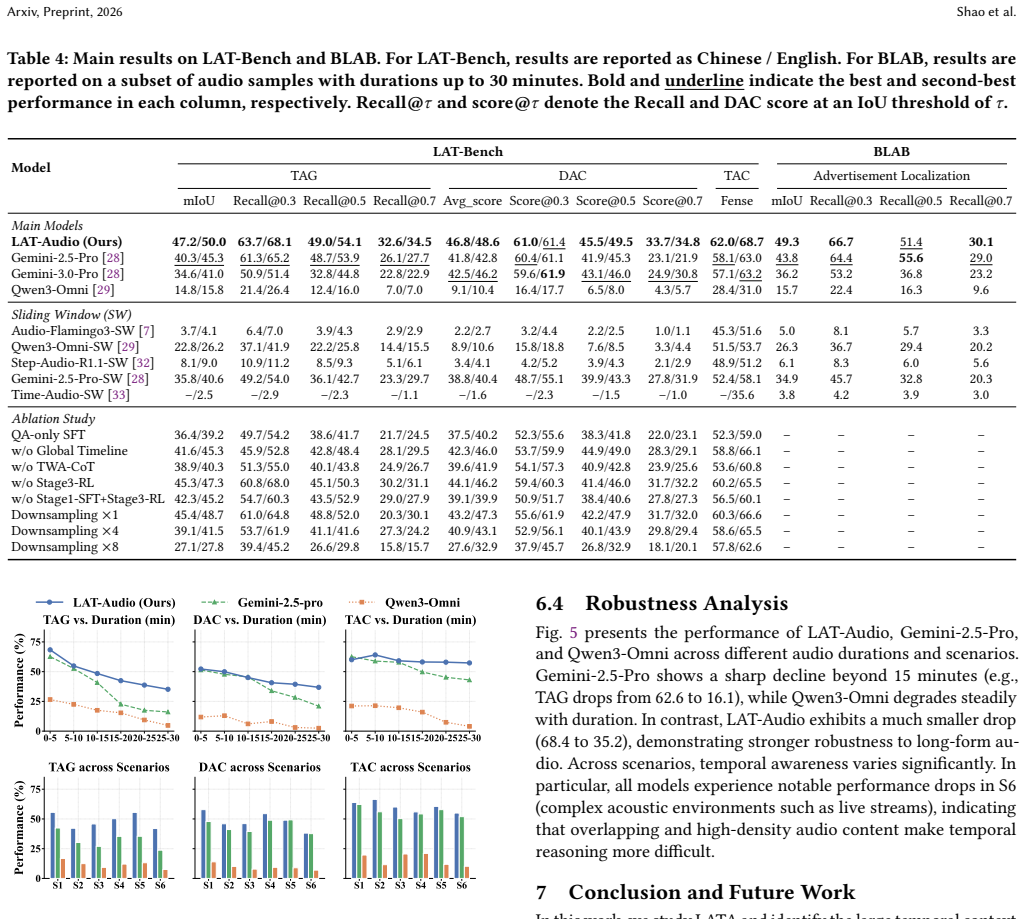
read the original abstract
While Large Audio Language Models (LALMs) achieve strong performance on short audio, they degrade on long-form inputs. This degradation is more severe in temporal awareness tasks, where temporal alignment becomes increasingly inaccurate as audio duration grows. We attribute these limitations to the lack of data, benchmarks, and modeling approaches tailored for long-form temporal awareness. To bridge this gap, we first construct LAT-Chronicle, a 1.2k hour long-form audio dataset with temporal annotations across real-world scenarios. We further develop LAT-Bench, the first human-verified benchmark supporting audio up to 30 minutes while covering three core tasks: Dense Audio Caption, Temporal Audio Grounding, and Targeted Audio Caption. Leveraging these resources, we propose LAT-Audio, formulating temporal awareness as a progressive global-to-local reasoning paradigm. A global timeline is first constructed as an aligned temporal-semantic context,and the Think-With-Audio Chain-of-Thought (TWA-CoT) is then introduced to perform iterative reasoning by incorporating local audio information via tool use. Experiments show that LAT-Audio surpasses existing models on long-form audio temporal awareness tasks and improves robustness to input duration. We release the dataset, benchmark, and model to facilitate future research at https://github.com/alanshaoTT/LAT-Audio-Repo.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LAT-Chronicle, a 1.2k-hour long-form audio dataset with temporal annotations, and LAT-Bench, a human-verified benchmark for audio up to 30 minutes covering Dense Audio Caption, Temporal Audio Grounding, and Targeted Audio Caption. It proposes LAT-Audio, which formulates temporal awareness via a global-to-local paradigm: first building an aligned temporal-semantic global timeline, then applying Think-With-Audio Chain-of-Thought (TWA-CoT) for iterative local reasoning through tool use on audio segments. Experiments are reported to show that LAT-Audio outperforms existing LALMs on long-form temporal awareness tasks while improving robustness as input duration increases.
Significance. If the performance and robustness claims hold after addressing the noted concerns, the work supplies the first large-scale resources and a structured reasoning approach for long-form audio temporal tasks, where current LALMs degrade. The release of dataset, benchmark, and model would enable reproducible follow-up research on extended audio understanding.
major comments (3)
- [Method (TWA-CoT description) and Experiments] The central robustness claim (improved performance as duration grows to 30 min) rests on the global-to-local paradigm with TWA-CoT iterative tool calls reliably correcting misalignment. However, the manuscript provides no quantitative analysis or bound on error propagation from tool-call failures (timestamp parsing, retrieval noise, or incorrect segment selection), whose frequency would scale with audio length and iteration count. This is load-bearing for the claim that gains are due to the reasoning paradigm rather than dataset-specific effects.
- [Experiments] No ablation studies isolate the contribution of TWA-CoT tool-use from the scale of the newly constructed LAT-Chronicle dataset or the global timeline construction. Without such controls, it remains unclear whether observed gains on LAT-Bench tasks stem from the proposed paradigm or from training data volume and annotation quality.
- [Experiments] The abstract and method claim superiority over existing models, yet the provided text lacks explicit baseline details, error bars, statistical significance tests, or per-duration breakdowns that would substantiate the robustness improvement. These elements are required to verify the central experimental result.
minor comments (2)
- [Dataset and Benchmark] The GitHub release link is provided, but the manuscript should include a brief description of the exact train/validation/test splits used for LAT-Chronicle to allow independent verification of no leakage into LAT-Bench.
- [Method] Notation for the global timeline construction and tool interface could be formalized with a diagram or pseudocode to improve clarity of the iterative process.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments correctly identify areas where additional analysis is needed to substantiate the robustness claims. We address each major comment below and will revise the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Method (TWA-CoT description) and Experiments] The central robustness claim (improved performance as duration grows to 30 min) rests on the global-to-local paradigm with TWA-CoT iterative tool calls reliably correcting misalignment. However, the manuscript provides no quantitative analysis or bound on error propagation from tool-call failures (timestamp parsing, retrieval noise, or incorrect segment selection), whose frequency would scale with audio length and iteration count. This is load-bearing for the claim that gains are due to the reasoning paradigm rather than dataset-specific effects.
Authors: We agree that quantifying error propagation is essential to support the robustness claims. In the revised manuscript, we will add a dedicated analysis section that reports tool-call success rates (for timestamp parsing, retrieval, and segment selection) across varying audio lengths and iteration counts. We will also provide empirical bounds on error accumulation derived from logged failure cases and a simple propagation model. This will help demonstrate that the observed gains are attributable to the TWA-CoT paradigm. revision: yes
-
Referee: [Experiments] No ablation studies isolate the contribution of TWA-CoT tool-use from the scale of the newly constructed LAT-Chronicle dataset or the global timeline construction. Without such controls, it remains unclear whether observed gains on LAT-Bench tasks stem from the proposed paradigm or from training data volume and annotation quality.
Authors: We acknowledge the absence of isolating ablations. The revised version will include new ablation experiments that (1) disable TWA-CoT while retaining the global timeline, (2) train on progressively smaller subsets of LAT-Chronicle, and (3) compare against a baseline that uses only dataset scale without the global-to-local structure. These controls will clarify the individual contributions of the reasoning paradigm versus data volume. revision: yes
-
Referee: [Experiments] The abstract and method claim superiority over existing models, yet the provided text lacks explicit baseline details, error bars, statistical significance tests, or per-duration breakdowns that would substantiate the robustness improvement. These elements are required to verify the central experimental result.
Authors: We agree that the experimental reporting requires strengthening. The revision will expand the results section with: full baseline model specifications and training details, error bars computed over multiple random seeds, statistical significance tests (paired t-tests with p-values), and per-duration performance breakdowns (e.g., 5 min, 10 min, 15 min, 30 min intervals). These additions will provide transparent verification of the robustness improvements. revision: yes
Circularity Check
No significant circularity; new dataset, benchmark, and paradigm are independently constructed and empirically evaluated
full rationale
The paper's chain begins with identifying limitations in existing LALMs for long-form audio, then independently constructs LAT-Chronicle (1.2k hours with annotations) and LAT-Bench (human-verified, up to 30 min, three tasks) as new resources. It then proposes the global-to-local paradigm with TWA-CoT tool-use reasoning as a modeling approach, and reports empirical outperformance on the new benchmark. No equations, fitted parameters, or self-citations are shown to reduce the central claims (robustness to duration, temporal alignment) to the inputs by construction. The evaluation uses the newly introduced benchmark rather than recycling prior fitted quantities, and the derivation remains self-contained without load-bearing self-citation chains or ansatz smuggling.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Think-With-Audio Chain-of-Thought (TWA-CoT)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Smith, Yulia Tsvetkov, and Sachin Kumar
Orevaoghene Ahia, Martijn Bartelds, Kabir Ahuja, Hila Gonen, Valentin Hofmann, Siddhant Arora, Shuyue Stella Li, Vishal Puttagunta, Mofetoluwa Adeyemi, Char- ishma Buchireddy, Ben Walls, Noah Bennett, Shinji Watanabe, Noah A. Smith, Yulia Tsvetkov, and Sachin Kumar. 2025. BLAB: Brutally Long Audio Bench. CoRRabs/2505.03054 (2025)
-
[2]
Max Bain, Jaesung Huh, Tengda Han, and Andrew Zisserman. 2023. WhisperX: Time-Accurate Speech Transcription of Long-Form Audio. InProc. Interspeech. 4489–4493
2023
-
[3]
Yuatyong Chaichana, Pittawat Taveekitworachai, Warit Sirichotedumrong, Pot- sawee Manakul, and Kunat Pipatanakul. 2026. Extending Audio Context for Long-Form Understanding in Large Audio-Language Models. InProc. EACL. 6046–6066
2026
-
[4]
DeepSeek-AI. 2025. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.CoRRabs/2501.12948 (2025)
work page internal anchor Pith review arXiv 2025
- [5]
-
[6]
Bernard Ghanem, Juan Carlos Niebles, Cees Snoek, Fabian Caba Heilbron, Hu- mam Alwassel, Ranjay Krishna, Victor Escorcia, Kenji Hata, and Shyamal Buch
- [7]
-
[8]
Arushi Goel, Sreyan Ghosh, Jaehyeon Kim, Sonal Kumar, Zhifeng Kong, Sang-gil Lee, Chao-Han Huck Yang, Ramani Duraiswami, Dinesh Manocha, Rafael Valle, and Bryan Catanzaro. 2025. Audio Flamingo 3: Advancing Audio Intelligence with Fully Open Large Audio Language Models.CoRRabs/2507.08128 (2025)
-
[9]
Liu, Leonid Karlinsky, and James R
Yuan Gong, Hongyin Luo, Alexander H. Liu, Leonid Karlinsky, and James R. Glass. 2024. Listen, Think, and Understand. InProc. ICLR
2024
-
[10]
Albert Gu and Tri Dao. 2023. Mamba: Linear-Time Sequence Modeling with Selective State Spaces.CoRRabs/2312.00752 (2023)
work page internal anchor Pith review arXiv 2023
-
[11]
Yongxin Guo, Jingyu Liu, Mingda Li, Qingbin Liu, Xi Chen, and Xiaoying Tang
-
[12]
TRACE: Temporal Grounding Video LLM via Causal Event Modeling. In Proc. ICLR
-
[13]
Peize He, Zichen Wen, Yubo Wang, Yuxuan Wang, Xiaoqian Liu, Jiajie Huang, Ze- hui Lei, Zhuangcheng Gu, Xiangqi Jin, Jiabing Yang, Kai Li, Zhifei Liu, Weijia Li, Cunxiang Wang, Conghui He, and Linfeng Zhang. 2025. AudioMarathon: A Com- prehensive Benchmark for Long-Context Audio Understanding and Efficiency in Audio LLMs.CoRRabs/2510.07293 (2025)
-
[14]
Fabian Caba Heilbron, Victor Escorcia, Bernard Ghanem, and Juan Carlos Niebles
-
[15]
ActivityNet: A large-scale video benchmark for human activity understand- ing. InProc. CVPR. 961–970
-
[16]
Shawn Hershey, Daniel P. W. Ellis, Eduardo Fonseca, Aren Jansen, Caroline Liu, R. Channing Moore, and Manoj Plakal. 2021. The Benefit of Temporally-Strong Labels in Audio Event Classification. InProc. ICASSP. IEEE, 366–370
2021
- [17]
- [18]
-
[19]
Ranjay Krishna, Kenji Hata, Frederic Ren, Li Fei-Fei, and Juan Carlos Niebles
-
[20]
Dense-Captioning Events in Videos. InProc. ICCV. 706–715
- [21]
- [22]
-
[23]
Microsoft. 2024. Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone.CoRRabs/2404.14219 (2024)
work page internal anchor Pith review arXiv 2024
- [24]
-
[25]
OpenAI. 2023. GPT-4 Technical Report.CoRRabs/2303.08774 (2023)
work page internal anchor Pith review arXiv 2023
-
[26]
OpenAI. 2024. GPT-4o System Card.CoRRabs/2410.21276 (2024)
work page internal anchor Pith review arXiv 2024
-
[27]
Paul Primus, Florian Schmid, and Gerhard Widmer. 2025. TACOS: Temporally- aligned Audio CaptiOnS for Language-Audio Pretraining. InProc. W ASPAA. 1–5
2025
-
[28]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. 2024. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models.CoRRabs/2402.03300 (2024)
work page internal anchor Pith review arXiv 2024
-
[29]
Arvind Krishna Sridhar, Yinyi Guo, and Erik Visser. 2025. Enhancing Temporal Understanding in Audio Question Answering for Large Audio Language Models. InProc. NAACL. 1026–1035
2025
-
[30]
Thinking with Images for Multimodal Reasoning: Foundations, Methods, and Future Frontiers
Zhaochen Su, Peng Xiang, Hangyu Guo, Zhenhua Liu, Yan Ma, Xiaoye Qu, Jiaqi Liu, Yanshu Li, Kaide Zeng, Zhengyuan Yang, Linjie Li, Yu Cheng, Heng Ji, Junxian He, and Yi R. (May) Fung. 2025. Thinking with Images for Multimodal Reasoning: Foundations, Methods, and Future Frontiers.CoRRabs/2506.23918 (2025)
work page internal anchor Pith review arXiv 2025
- [31]
-
[32]
Gemini Team. 2025. Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities.CoRR abs/2507.06261 (2025)
work page internal anchor Pith review arXiv 2025
-
[33]
Qwen Team. 2025. Qwen3-Omni Technical Report.CoRRabs/2509.17765 (2025)
work page internal anchor Pith review arXiv 2025
-
[34]
Qwen Team. 2025. Qwen3 Technical Report.CoRRabs/2505.09388 (2025)
work page internal anchor Pith review arXiv 2025
-
[35]
Qwen Team. 2025. Qwen3-VL Technical Report.CoRRabs/2511.21631 (2025)
work page internal anchor Pith review arXiv 2025
-
[36]
Fei Tian, Xiangyu Tony Zhang, Yuxin Zhang, Haoyang Zhang, Yuxin Li, Daijiao Liu, Yayue Deng, Donghang Wu, Jun Chen, Liang Zhao, Chengyuan Yao, Hexin Liu, Eng Siong Chng, Xuerui Yang, Xiangyu Zhang, Daxin Jiang, and Gang Yu
- [37]
-
[38]
Hualei Wang, Yiming Li, Shuo Ma, Hong Liu, and Xiangdong Wang. 2026. Lis- tening Between the Frames: Bridging Temporal Gaps in Large Audio-Language Models. InProc. AAAI. 26233–26241
2026
-
[39]
Junda Wu, Warren Li, Zachary Novack, Amit Namburi, Carol Chen, and Julian J. McAuley. 2025. CoLLAP: Contrastive Long-form Language-Audio Pretraining with Musical Temporal Structure Augmentation. InProc. ICASSP. 1–5
2025
- [40]
-
[41]
Zeyu Xie, Xuenan Xu, Zhizheng Wu, and Mengyue Wu. 2025. AudioTime: A Temporally-aligned Audio-text Benchmark Dataset. InProc. ICASSP. 1–5
2025
- [42]
-
[43]
Senqiao Yang, Yukang Chen, Zhuotao Tian, Chengyao Wang, Jingyao Li, Bei Yu, and Jiaya Jia. 2025. VisionZip: Longer is Better but Not Necessary in Vision Language Models. InProc. CVPR. 19792–19802
2025
-
[44]
Zuhao Yang, Sudong Wang, Kaichen Zhang, Keming Wu, Sicong Leng, Yifan Zhang, Bo Li, Chengwei Qin, Shijian Lu, Xingxuan Li, and Lidong Bing. 2025. LongVT: Incentivizing "Thinking with Long Videos" via Native Tool Calling. CoRRabs/2511.20785 (2025)
- [45]
-
[46]
Yuze Zhao, Jintao Huang, Jinghan Hu, Xingjun Wang, Yunlin Mao, Daoze Zhang, Zeyinzi Jiang, Zhikai Wu, Baole Ai, Ang Wang, Wenmeng Zhou, and Yingda Chen. 2025. SWIFT: A Scalable Lightweight Infrastructure for Fine-Tuning. In Proc. AAAI. 29733–29735
2025
-
[47]
Zelin Zhou, Zhiling Zhang, Xuenan Xu, Zeyu Xie, Mengyue Wu, and Kenny Q. Zhu. 2022. Can Audio Captions Be Evaluated With Image Caption Metrics?. In Proc. ICASSP. 981–985
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.