Recognition: unknown
Bridging the Long-Tail Gap: Robust Retrieval-Augmented Relation Completion via Multi-Stage Paraphrase Infusion
Pith reviewed 2026-05-08 11:44 UTC · model grok-4.3
The pith
Multi-stage infusion of relation paraphrases improves long-tail relation completion in large language models without fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
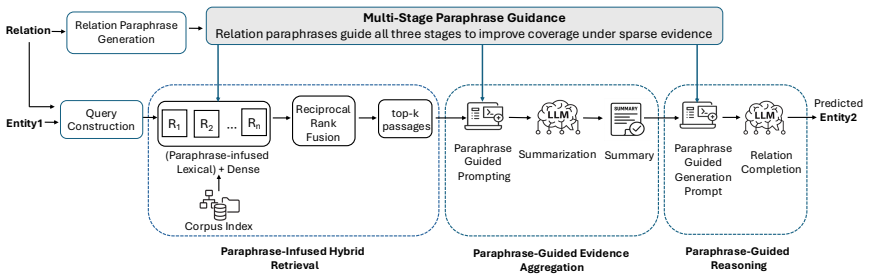
RC-RAG infuses relation paraphrases across three stages to improve relation completion: paraphrases expand lexical coverage during retrieval, produce relation-aware summaries, and guide reasoning during generation. The framework requires no model fine-tuning and yields consistent gains over RAG baselines, with especially large benefits when the required information is rare or long-tail.
What carries the argument
The multi-stage paraphrase infusion process that broadens lexical coverage in retrieval, creates relation-focused summaries, and steers generation with paraphrases.
If this is right
- The best-performing large language model with RC-RAG gains 40.6 exact match points over its standalone performance in long-tail settings.
- RC-RAG exceeds two strong RAG baselines by 16.0 and 13.8 exact match points respectively in those settings.
- Improvements appear consistently across five large language models and two benchmark datasets.
- The approach adds only low computational overhead.
Where Pith is reading between the lines
- Similar multi-stage paraphrase use could help other retrieval-heavy tasks where facts about rare entities are needed.
- High-quality paraphrases might reduce the frequency of incorrect completions on uncommon relations by offering multiple ways to match evidence.
- Evaluating the method on queries with even rarer relations or in new domains would test how far the current paraphrase generation scales.
Load-bearing premise
Automatically generated relation paraphrases will expand lexical coverage and guide reasoning without introducing semantic drift or noise that degrades retrieval or generation quality on long-tail cases.
What would settle it
A new long-tail test set in which the added paraphrases retrieve irrelevant passages or produce lower exact-match scores than simple RAG baselines would falsify the robustness claim.
Figures





read the original abstract
Large language models (LLMs) struggle with relation completion (RC), both with and without retrieval-augmented generation (RAG), particularly when the required information is rare or sparsely represented. To address this, we propose a novel multi-stage paraphrase-guided relation-completion framework, RC-RAG, that systematically incorporates relation paraphrases across multiple stages. In particular, RC-RAG: (a) integrates paraphrases into retrieval to expand lexical coverage of the relation, (b) uses paraphrases to generate relation-aware summaries, and (c) leverages paraphrases during generation to guide reasoning for relation completion. Importantly, our method does not require any model fine-tuning. Experiments with five LLMs on two benchmark datasets show that RC-RAG consistently outperforms several RAG baselines. In long-tail settings, the best-performing LLM augmented with RC-RAG improves by 40.6 Exact Match (EM) points over its standalone performance and surpasses two strong RAG baselines by 16.0 and 13.8 EM points, respectively, while maintaining low computational overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RC-RAG, a training-free multi-stage framework for relation completion that infuses automatically generated relation paraphrases into retrieval (to expand lexical coverage), summarization (to produce relation-aware summaries), and generation (to guide reasoning). Experiments with five LLMs on two benchmarks report consistent gains over RAG baselines, including a 40.6 EM point improvement in long-tail settings for the best LLM, plus 16.0 and 13.8 point margins over two strong baselines, with low overhead.
Significance. If the gains prove robust, the work provides a practical, parameter-free (no fine-tuning) route to improving LLM handling of sparse/long-tail relations via RAG, addressing a recognized limitation in current systems. The multi-stage design and empirical validation across multiple models and datasets are strengths that could influence follow-on work on paraphrase-augmented retrieval.
major comments (3)
- [§3] §3 (Method description): The paraphrase generation procedure is not detailed (e.g., no prompt template, source LLM, or temperature settings), and no quantitative fidelity check (semantic similarity, entailment score, or human validation on long-tail relations) is reported; this directly undermines the central claim that paraphrases reliably expand coverage without drift or noise.
- [§4] §4 (Experiments): No ablation is presented that removes or isolates individual paraphrase stages (retrieval-only, summary-only, or generation-only) versus the full multi-stage pipeline; without this, the 40.6 EM long-tail gain cannot be attributed to the proposed design rather than generic paraphrase augmentation or baseline RAG effects.
- [§4.2] §4.2 / results tables: The reported EM improvements (including the 16.0 and 13.8 point margins) are given as point estimates only, with no error bars, standard deviations across runs, or statistical significance tests; this weakens support for the claim of consistent outperformance across five LLMs and long-tail subsets.
minor comments (2)
- [Abstract] Abstract: The phrase 'low computational overhead' is asserted but never quantified (e.g., no token counts or latency comparison to the two strong RAG baselines).
- [§3] Notation: The distinction between 'relation paraphrases' and 'relation-aware summaries' could be clarified with an example in the method section to avoid reader confusion about stage outputs.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [§3] §3 (Method description): The paraphrase generation procedure is not detailed (e.g., no prompt template, source LLM, or temperature settings), and no quantitative fidelity check (semantic similarity, entailment score, or human validation on long-tail relations) is reported; this directly undermines the central claim that paraphrases reliably expand coverage without drift or noise.
Authors: We agree that the original submission lacked sufficient detail on paraphrase generation. In the revised manuscript we will add the exact prompt templates, specify the source LLM and temperature settings used, and include quantitative fidelity analysis (semantic similarity via embeddings plus entailment scores) on long-tail relation samples to confirm minimal drift. These additions will appear in Section 3. revision: yes
-
Referee: [§4] §4 (Experiments): No ablation is presented that removes or isolates individual paraphrase stages (retrieval-only, summary-only, or generation-only) versus the full multi-stage pipeline; without this, the 40.6 EM long-tail gain cannot be attributed to the proposed design rather than generic paraphrase augmentation or baseline RAG effects.
Authors: We recognize the value of stage-specific ablations. The revised version will include new experiments applying paraphrases to retrieval only, summarization only, and generation only, with direct comparisons to the full pipeline and baselines. Results will be reported in Section 4 to isolate the contribution of the multi-stage design. revision: yes
-
Referee: [§4.2] §4.2 / results tables: The reported EM improvements (including the 16.0 and 13.8 point margins) are given as point estimates only, with no error bars, standard deviations across runs, or statistical significance tests; this weakens support for the claim of consistent outperformance across five LLMs and long-tail subsets.
Authors: We agree that variability measures and significance testing would strengthen the results. Because LLM decoding is stochastic, we will rerun all experiments with multiple seeds, report means and standard deviations, and add statistical tests (e.g., paired t-tests) between RC-RAG and baselines. Updated tables with these statistics will appear in Section 4.2. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper presents an empirical procedural method (RC-RAG) that incorporates automatically generated relation paraphrases into retrieval, summarization, and generation stages for long-tail relation completion. No equations, derivations, fitted parameters, or mathematical predictions appear in the described framework; performance claims rest on experiments across five LLMs and two external benchmark datasets rather than any reduction to self-referential inputs. The contribution does not invoke self-citations for uniqueness theorems, smuggle ansatzes, or rename known results as novel derivations, rendering the chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Relation paraphrases preserve core meaning while increasing lexical variety for retrieval and reasoning
Reference graph
Works this paper leans on
-
[1]
Quantifying Memorization Across Neural Language Models
Quantifying memorization across neural lan- guage models.Preprint, arXiv:2202.07646. Lihu Chen, Simon Razniewski, and Gerhard Weikum
work page internal anchor Pith review arXiv
-
[2]
REALM: Retrieval-Augmented Language Model Pre-Training
Knowledge base completion for long-tail entities. InProceedings of the First Workshop on Matching From Unstructured and Structured Data (MATCHING 2023), pages 99–108, Toronto, ON, Canada. Association for Computational Linguistics. Gordon V . Cormack, Charles L A Clarke, and Stefan Buettcher. 2009. Reciprocal rank fusion outperforms condorcet and individua...
work page internal anchor Pith review arXiv 2023
-
[3]
Unsupervised Dense Information Retrieval with Contrastive Learning
A framework to retrieve relevant laws for will execution. InProceedings of the Natural Legal Language Processing Workshop 2025, pages 338– 350, Suzhou, China. Association for Computational Linguistics. Gautier Izacard, Mathilde Caron, Lucas Hosseini, Sebas- tian Riedel, Piotr Bojanowski, Armand Joulin, and Edouard Grave. 2022a. Unsupervised dense infor- m...
work page internal anchor Pith review arXiv 2025
-
[4]
Recomp: Improving retrieval- augmented lms with compression and selective augmentation,
KICGPT: Large language model with knowl- edge in context for knowledge graph completion. In Findings of the Association for Computational Lin- guistics: EMNLP 2023, pages 8667–8683, Singapore. Association for Computational Linguistics. Fangyuan Xu, Weijia Shi, and Eunsol Choi. 2023. Recomp: Improving retrieval-augmented lms with compression and selective ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.