Recognition: unknown
DocPrune:Efficient Document Question Answering via Background, Question, and Comprehension-aware Token Pruning
Pith reviewed 2026-05-08 12:38 UTC · model grok-4.3
The pith
A training-free pruning method removes background and question-irrelevant tokens from document images to raise both speed and accuracy in question answering.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
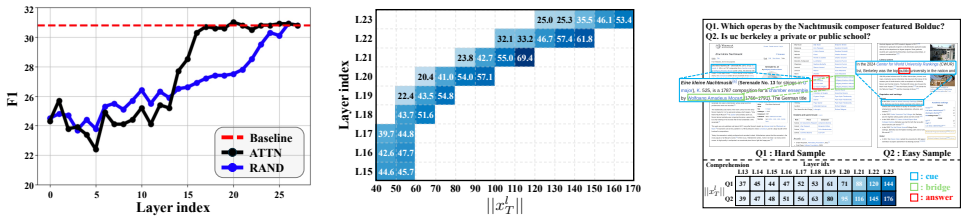
DocPrune is a training-free progressive document token pruning framework that preserves only the essential tokens for the task while removing unnecessary ones such as background or question-irrelevant tokens. It automatically selects the appropriate layers to initiate token pruning based on the model's level of comprehension. This design enables efficient long-document understanding in vision-language models.
What carries the argument
DocPrune, a progressive token-pruning procedure that applies background, question-relevance, and comprehension-level criteria to decide which tokens to retain or discard at selected layers.
If this is right
- Encoder throughput rises by a factor of 3.0 on the tested benchmark.
- Decoder throughput rises by a factor of 3.3 on the tested benchmark.
- F1 score on the M3DocRAG benchmark increases by 1.0 point.
- The efficiency gains require no additional model training.
- The method targets long documents that contain structured visual elements such as text and tables.
Where Pith is reading between the lines
- The same background-and-relevance signals could be applied to prune tokens in other sparse multimodal tasks such as chart or slide understanding.
- Layer-selection logic based on internal comprehension might be combined with existing early-exit techniques to further reduce latency.
- Because pruning is training-free, it could be inserted into existing deployed document models with minimal engineering effort.
Load-bearing premise
Automatically selecting pruning layers according to the model's level of comprehension will keep every token needed for a correct answer.
What would settle it
A document-question pair in which a token required for the correct answer is pruned at the chosen layer, producing an incorrect model output that the F1 metric does not register as an error.
Figures






read the original abstract
Recent advances in vision-language models have demonstrated remarkable performance across diverse multi-modal tasks, including document question answering that leverages structured visual cues from text, tables, and figures. However, unlike natural images, document images contain large backgrounds and only sparse supporting evidence, leading to the inefficient consumption of substantial computational resources, especially for long documents. We observe that existing token-reduction methods for natural images and videos fall short in utilizing the structural sparsity unique to documents. To address this, we propose DocPrune, a training-free and progressive document token pruning framework designed for efficient long-document understanding. The proposed method preserves only the essential tokens for the task while removing unnecessary ones, such as background or question-irrelevant tokens. Moreover, it automatically selects the appropriate layers to initiate token pruning based on the model's level of comprehension. Our experiments on the M3DocRAG show that DocPrune improves throughput by 3.0x and 3.3x in the encoder and decoder, respectively, while boosting the F1 score by +1.0, achieving both higher accuracy and efficiency without any additional training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DocPrune, a training-free and progressive token pruning framework for vision-language models in document question answering. It removes background and question-irrelevant tokens while preserving task-essential ones, automatically selects pruning start layers based on an internal 'level of comprehension' signal, and reports 3.0x encoder and 3.3x decoder throughput gains with a +1.0 F1 improvement on the M3DocRAG benchmark without any additional training.
Significance. If the empirical claims hold under scrutiny, the work offers a practical, training-free route to efficient long-document VLM inference by exploiting document-specific sparsity. The reported simultaneous gains in speed and accuracy, plus the absence of retraining, would be valuable for deployment scenarios. The approach's novelty lies in combining background/question awareness with comprehension-driven layer selection, but verification of these mechanisms is essential for impact.
major comments (2)
- [Method description (pruning layer selection)] The comprehension-aware layer selection mechanism is described only at a high level in the abstract and method overview; no explicit metric (e.g., attention statistic, entropy threshold, or validation procedure) is provided for determining the 'level of comprehension' or the pruning start layer. This is load-bearing for the central efficiency claim, as premature pruning on documents with late-emerging evidence (tables/figures) could drop critical tokens before decoder attention.
- [Experiments and results] Experiments section reports concrete throughput (3.0x/3.3x) and F1 (+1.0) gains on M3DocRAG but supplies no ablation studies, pruning threshold values, layer-selection logic details, or error analysis. Without these, it is impossible to confirm that the F1 metric captures potential increases in hallucination or partial evidence loss on harder cases, undermining the 'higher accuracy and efficiency' claim.
minor comments (2)
- [Abstract] The abstract states that existing token-reduction methods 'fall short in utilizing the structural sparsity unique to documents' but does not cite or briefly contrast with the most relevant prior works on document-specific pruning or token reduction in VLMs.
- [Method] Notation for the progressive pruning process (e.g., how background vs. question awareness is quantified per token) is not introduced with equations or pseudocode, reducing clarity for readers attempting to reimplement the framework.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point by point below and commit to revisions that will strengthen the clarity and empirical support of the claims.
read point-by-point responses
-
Referee: [Method description (pruning layer selection)] The comprehension-aware layer selection mechanism is described only at a high level in the abstract and method overview; no explicit metric (e.g., attention statistic, entropy threshold, or validation procedure) is provided for determining the 'level of comprehension' or the pruning start layer. This is load-bearing for the central efficiency claim, as premature pruning on documents with late-emerging evidence (tables/figures) could drop critical tokens before decoder attention.
Authors: We agree that the current description of the comprehension-aware layer selection is high-level. In the revised manuscript we will add a dedicated subsection that explicitly defines the metric (entropy of cross-attention distributions between question tokens and visual tokens, computed per layer) together with the threshold and small-scale validation procedure used to select the pruning start layer. This addition will allow readers to reproduce the mechanism and directly address concerns about premature pruning on documents containing late-emerging evidence such as tables or figures. revision: yes
-
Referee: [Experiments and results] Experiments section reports concrete throughput (3.0x/3.3x) and F1 (+1.0) gains on M3DocRAG but supplies no ablation studies, pruning threshold values, layer-selection logic details, or error analysis. Without these, it is impossible to confirm that the F1 metric captures potential increases in hallucination or partial evidence loss on harder cases, undermining the 'higher accuracy and efficiency' claim.
Authors: We acknowledge that the experiments section currently lacks the requested supporting analyses. In the revision we will add: (i) ablation tables varying the pruning threshold and reporting its effect on both throughput and F1, (ii) concrete layer-selection logic with per-document examples, (iii) specific threshold values used in all reported runs, and (iv) a targeted error analysis on harder M3DocRAG subsets (tables, figures, multi-page evidence) that measures hallucination rate and evidence coverage. These additions will substantiate that the observed +1.0 F1 does not mask degradation on complex cases. revision: yes
Circularity Check
No circularity in empirical token-pruning method
full rationale
The paper describes a training-free heuristic framework for progressive token pruning in document VLM inference, with all performance claims (3.0x/3.3x throughput, +1.0 F1 on M3DocRAG) presented as direct experimental measurements rather than derived predictions. No equations, first-principles derivations, fitted parameters renamed as outputs, or self-citation chains appear in the provided text; layer selection via 'level of comprehension' is described as an automatic heuristic without reducing to a self-referential definition or input fit. The work is therefore self-contained as an engineering contribution evaluated on external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Divprune: Diversity-based visual token pruning for large multimodal models
Saeed Ranjbar Alvar, Gursimran Singh, Mohammad Akbari, and Yong Zhang. Divprune: Diversity-based visual token pruning for large multimodal models. InCVPR, 2025. 6, 11
2025
-
[2]
Token merg- ing: your ViT but faster
Daniel Bolya, Cheng-Yang Fu, Xi Dai, Peizhao Zhang, Christoph Feichtenhofer, and Judy Hoffman. Token merg- ing: your ViT but faster. InICLR, 2023. 1
2023
-
[3]
Sv-rag: Lora-contextualizing adaptation of mllms for long document understanding.ICLR, 2025
Jian Chen, Ruiyi Zhang, Yufan Zhou, Tong Yu, Franck Der- noncourt, Jiuxiang Gu, Ryan A Rossi, Changyou Chen, and Tong Sun. Sv-rag: Lora-contextualizing adaptation of mllms for long document understanding.ICLR, 2025. 3
2025
-
[4]
An image is worth 1/2 tokens after layer 2: plug-and-play inference acceleration for large vision–language models
Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. An image is worth 1/2 tokens after layer 2: plug-and-play inference acceleration for large vision–language models. InECCV, 2024. 1, 6, 8, 11
2024
-
[5]
Internvl: scaling up vision foundation mod- els and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: scaling up vision foundation mod- els and aligning for generic visual-linguistic tasks. InCVPR,
-
[6]
Jaemin Cho, Debanjan Mahata, Ozan Irsoy, Yujie He, and Mohit Bansal. M3docrag: Multi-modal retrieval is what you need for multi-page multi-document understanding.arXiv preprint arXiv:2411.04952, 2024. 1, 2, 3, 6, 8, 11
-
[7]
vid-tldr: Training free token merging for light-weight video transformer
Joonmyung Choi, Sanghyeok Lee, Jaewon Chu, Minhyuk Choi, and Hyunwoo J Kim. vid-tldr: Training free token merging for light-weight video transformer. InCVPR, 2024. 1
2024
-
[8]
Representation shift: Unifying token compression with flashattention
Joonmyung Choi, Sanghyeok Lee, Byungoh Ko, Eunseo Kim, Jihyung Kil, and Hyunwoo J Kim. Representation shift: Unifying token compression with flashattention. In ICCV, 2025. 1, 8
2025
-
[9]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Tri Dao. Flashattention-2: Faster attention with bet- ter parallelism and work partitioning.arXiv preprint arXiv:2307.08691, 2023. 11
work page internal anchor Pith review arXiv 2023
-
[10]
Col- pali: Efficient document retrieval with vision language mod- els
Manuel Faysse, Hugues Sibille, Tony Wu, Bilel Omrani, Gautier Viaud, C ´eline Hudelot, and Pierre Colombo. Col- pali: Efficient document retrieval with vision language mod- els. InICLR, 2025. 6, 8
2025
-
[11]
Framefusion: Combining similarity and importance for video token reduction on large vision language models
Tianyu Fu, Tengxuan Liu, Qinghao Han, Guohao Dai, Shen- gen Yan, Huazhong Yang, Xuefei Ning, and Yu Wang. Framefusion: Combining similarity and importance for video token reduction on large vision language models. In ICCV, 2024. 1
2024
-
[12]
Siwei Han, Peng Xia, Ruiyi Zhang, Tong Sun, Yun Li, Hongtu Zhu, and Huaxiu Yao. Mdocagent: A multi-modal multi-agent framework for document understanding.arXiv preprint arXiv:2503.13964, 2025. 1, 8
-
[13]
Prunevid: Visual token pruning for efficient video large language models
Xiaohu Huang, Hao Zhou, and Kai Han. Prunevid: Visual token pruning for efficient video large language models. In ACL Findings, 2025. 1
2025
-
[14]
Layoutlmv3: pre-training for document ai with unified text and image masking
Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, and Furu Wei. Layoutlmv3: pre-training for document ai with unified text and image masking. InACM MM, 2022. 1
2022
-
[15]
Tabflash: Efficient table understanding with progressive question conditioning and token focusing
Jongha Kim, Minseong Bae, Sanghyeok Lee, Jinsung Yoon, and Hyunwoo J Kim. Tabflash: Efficient table understanding with progressive question conditioning and token focusing. InAAAI, 2026. 1
2026
-
[16]
Multi-criteria token fusion with one-step-ahead attention for efficient vision transformers
Sanghyeok Lee, Joonmyung Choi, and Hyunwoo J Kim. Multi-criteria token fusion with one-step-ahead attention for efficient vision transformers. InCVPR, 2024. 1
2024
-
[17]
Ming Li, Ruiyi Zhang, Jian Chen, Chenguang Wang, Jiux- iang Gu, Yufan Zhou, Franck Dernoncourt, Wanrong Zhu, Tianyi Zhou, and Tong Sun. Towards visual text ground- ing of multimodal large language model.arXiv preprint arXiv:2504.04974, 2025. 1
-
[18]
LLaMA-VID: an image is worth 2 tokens in large language models
Yanwei Li, Chengyao Wang, and Jiaya Jia. LLaMA-VID: an image is worth 2 tokens in large language models. InECCV,
-
[19]
Mini-gemini: Mining the potential of multi-modality vision language models.TPAMI, 2025
Yanwei Li, Yuechen Zhang, Chengyao Wang, Zhisheng Zhong, Yixin Chen, Ruihang Chu, Shaoteng Liu, and Jiaya Jia. Mini-gemini: Mining the potential of multi-modality vision language models.TPAMI, 2025. 8
2025
-
[20]
Not all patches are what you need: Expediting vision transformers via token reorganizations
Youwei Liang, Chongjian Ge, Zhan Tong, Yibing Song, Jue Wang, and Pengtao Xie. Not all patches are what you need: Expediting vision transformers via token reorganizations. In ICLR Spotlight, 2022. 1
2022
-
[21]
Boosting multimodal large language models with visual to- kens withdrawal for rapid inference
Zhihang Lin, Mingbao Lin, Luxi Lin, and Rongrong Ji. Boosting multimodal large language models with visual to- kens withdrawal for rapid inference. InAAAI, 2025. 6, 11
2025
-
[22]
Visual instruction tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. InNeurIPS, 2023. 1, 8
2023
-
[23]
Beyond attentive tokens: Incorporating to- ken importance and diversity for efficient vision transform- ers
Sifan Long, Zhen Zhao, Jimin Pi, Shengsheng Wang, and Jingdong Wang. Beyond attentive tokens: Incorporating to- ken importance and diversity for efficient vision transform- ers. InCVPR, 2023. 1
2023
-
[24]
MMLongBench-Doc: benchmarking long-context document understanding with visualizations
Yubo Ma, Yuhang Zang, Liangyu Chen, Meiqi Chen, Yizhu Jiao, Xinze Li, Xinyuan Lu, Ziyu Liu, Yan Ma, Xiaoyi Dong, et al. MMLongBench-Doc: benchmarking long-context document understanding with visualizations. InNeurIPS Datasets and Benchmarks Track, 2024. 1, 8
2024
-
[25]
Docvqa: A dataset for vqa on document images
Minesh Mathew, Dimosthenis Karatzas, and CV Jawahar. Docvqa: A dataset for vqa on document images. InWACV,
-
[26]
Doc-rag: Asr language model personalization with domain- distributed co-occurrence retrieval augmentation
Puneet Mathur, Zhe Liu, Ke Li, Yingyi Ma, Gil Karen, Zeeshan Ahmed, Dinesh Manocha, and Xuedong Zhang. Doc-rag: Asr language model personalization with domain- distributed co-occurrence retrieval augmentation. InLREC- COLING, 2024. 1
2024
-
[27]
Ocr-vqa: visual question answering by reading text in images
Anand Mishra, Shashank Shekhar, Ajeet Kumar Singh, and Anirban Chakraborty. Ocr-vqa: visual question answering by reading text in images. InICDAR, 2019. 1, 8
2019
-
[28]
Video, how do your tokens merge? InCVPR, 2025
Sam Pollard and Michael Wray. Video, how do your tokens merge? InCVPR, 2025. 1
2025
-
[29]
Dynamicvit: efficient vision transformers with dynamic token sparsification
Yongming Rao, Wenliang Zhao, Benlin Liu, Jiwen Lu, Jie Zhou, and Cho-Jui Hsieh. Dynamicvit: efficient vision transformers with dynamic token sparsification. InNeurIPS,
-
[30]
Longvu: Spa- tiotemporal adaptive compression for long video-language understanding
Xiaoqian Shen, Yunyang Xiong, Changsheng Zhao, Lemeng Wu, Jun Chen, Chenchen Zhu, Zechun Liu, Fanyi Xiao, Bal- akrishnan Varadarajan, Florian Bordes, et al. Longvu: Spa- tiotemporal adaptive compression for long video-language understanding. InICML, 2025. 1
2025
-
[31]
Vdocrag: Retrieval- augmented generation over visually-rich documents
Ryota Tanaka, Taichi Iki, Taku Hasegawa, Kyosuke Nishida, Kuniko Saito, and Jun Suzuki. Vdocrag: Retrieval- augmented generation over visually-rich documents. In CVPR, 2025. 1, 3, 6, 8
2025
-
[32]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean- Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023. 1
work page internal anchor Pith review arXiv 2023
-
[33]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024. 1, 6
work page internal anchor Pith review arXiv 2024
-
[34]
Yonghui Wang, Wengang Zhou, Hao Feng, Keyi Zhou, and Houqiang Li. Towards improving document understanding: An exploration on text-grounding via mllms.arXiv preprint arXiv:2311.13194, 2023. 1
-
[35]
Linli Yao, Lei Li, Shuhuai Ren, Lean Wang, Yuanxin Liu, Xu Sun, and Lu Hou. Deco: Decoupling token compres- sion from semantic abstraction in multimodal large language models.arXiv preprint arXiv:2405.20985, 2024. 8
-
[36]
V oCo-LLaMA: towards vision compression with large language models
Xubing Ye, Yukang Gan, Xiaoke Huang, Yixiao Ge, and Yansong Tang. V oCo-LLaMA: towards vision compression with large language models. InCVPR, 2025. 8
2025
-
[37]
Visrag: Vision-based retrieval-augmented generation on multi-modality documents
Shi Yu, Chaoyue Tang, Bokai Xu, Junbo Cui, Junhao Ran, Yukun Yan, Zhenghao Liu, Shuo Wang, Xu Han, Zhiyuan Liu, et al. Visrag: Vision-based retrieval-augmented generation on multi-modality documents.arXiv preprint arXiv:2410.10594, 2024. 1
-
[38]
Video-llama: An instruction-tuned audio-visual language model for video un- derstanding
Hang Zhang, Xin Li, and Lidong Bing. Video-llama: An instruction-tuned audio-visual language model for video un- derstanding. InEMNLP, 2023. 8
2023
-
[39]
SparseVLM: vi- sual token sparsification for efficient vision–language model inference
Yuan Zhang, Chun-Kai Fan, Junpeng Ma, Wenzhao Zheng, Tao Huang, Kuan Cheng, Denis Gudovskiy, Tomoyuki Okuno, Yohei Nakata, Kurt Keutzer, et al. SparseVLM: vi- sual token sparsification for efficient vision–language model inference. InICML, 2025. 1, 8
2025
-
[40]
Flexselect: Flexible token selection for efficient long video understanding
Yunzhu Zhang, Yu Lu, Tianyi Wang, Fengyun Rao, Yi Yang, and Linchao Zhu. Flexselect: Flexible token selection for efficient long video understanding. InNeurIPS, 2025. 2
2025
-
[41]
Dogr: Towards versatile visual document grounding and referring
Yinan Zhou, Yuxin Chen, Haokun Lin, Yichen Wu, Shuyu Yang, Zhongang Qi, Chen Ma, and Li Zhu. Dogr: Towards versatile visual document grounding and referring. InICCV,
-
[42]
85C7j7cmphwRW1iNUNVnLI2HR2w=
1 DOCPRUNE: Efficient Document Question Answering via Background, Question, and Comprehension-aware Token Pruning Supplementary Material Value Throughput Overall Value Throughput Overall ENC DEC EM F1 ENC DEC EM F1 (a) Background thresholdτbg (b) Relevance thresholdτqst 1.0 4.9 5.5 28.1 32.1 0.1 4.5 5.0 27.9 31.9 0.9 5.3 5.8 27.9 32.0 0.2 4.8 5.5 27.7 31....
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.