Recognition: unknown
Knowledge Visualization: A Benchmark and Method for Knowledge-Intensive Text-to-Image Generation
Pith reviewed 2026-05-08 12:27 UTC · model grok-4.3
The pith
A two-stage refinement process called KE-Check improves the scientific accuracy of images produced by text-to-image models and reduces the advantage of proprietary systems over open-source ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
KVBench is a curriculum-grounded benchmark consisting of 1,800 expert-curated prompts from over 30 authoritative textbooks across Biology, Chemistry, Geography, History, Mathematics, and Physics. Evaluation of 14 state-of-the-art T2I models on this benchmark reveals substantial deficiencies in logical reasoning, symbolic precision, and multilingual robustness, with open-source models underperforming closed-source ones. KE-Check is introduced as a two-stage framework that performs Knowledge Elaboration for structured prompt enrichment and Checklist-Guided Refinement to enforce constraints through violation identification and editing, thereby mitigating scientific hallucinations and narrowing
What carries the argument
KE-Check, a two-stage framework for knowledge elaboration to enrich prompts followed by checklist-guided refinement to identify and correct constraint violations in generated images.
Load-bearing premise
The prompts curated by experts from authoritative textbooks adequately represent the necessary domain knowledge, structural constraints, and symbolic conventions for assessing scientific correctness in generated images.
What would settle it
If independent domain experts find no significant reduction in scientific errors when comparing KE-Check outputs to baseline generations on a held-out set of prompts from different sources, the effectiveness claim would be falsified.
Figures

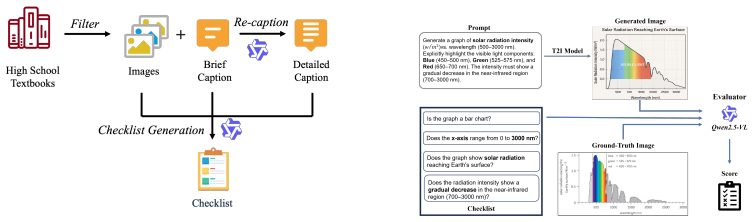

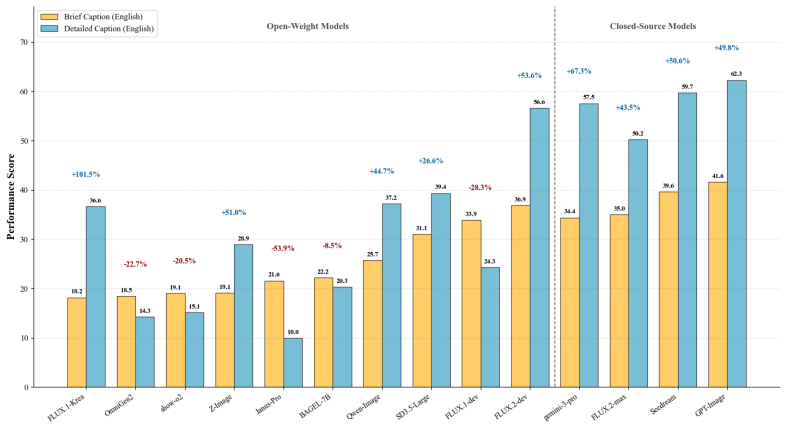











read the original abstract
Recent text-to-image (T2I) models have demonstrated impressive capabilities in photorealistic synthesis and instruction following. However, their reliability in knowledge-intensive settings remains largely unexplored. Unlike natural image generation, knowledge visualization requires not only semantic alignment but also strict adherence to domain knowledge, structural constraints, and symbolic conventions, exposing a critical gap between visual plausibility and scientific correctness. To systematically study this problem, we introduce KVBench, a curriculum-grounded benchmark for evaluating knowledge-intensive T2I generation. KVBench covers six senior high-school subjects: Biology, Chemistry, Geography, History, Mathematics, and Physics. The benchmark consists of 1,800 expert-curated prompts derived from over 30 authoritative textbooks. Using this benchmark, we evaluate 14 state-of-the-art open- and closed-source models, revealing substantial deficiencies in logical reasoning, symbolic precision, and multilingual robustness, with open-source models consistently underperforming proprietary systems. To address these limitations, we further propose KE-Check, a two-stage framework that improves scientific fidelity via (1) Knowledge Elaboration for structured prompt enrichment, and (2) Checklist-Guided Refinement for explicit constraint enforcement through violation identification and constraint-guided editing. KE-Check effectively mitigates scientific hallucinations, narrowing the performance gap between open-source and leading closed-source models. Data and codes are publicly available at https://github.com/zhaoran66/KVBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces KVBench, a benchmark of 1,800 expert-curated prompts drawn from over 30 high-school textbooks across Biology, Chemistry, Geography, History, Mathematics, and Physics, to evaluate knowledge-intensive text-to-image generation. It reports evaluation results on 14 open- and closed-source models that reveal deficiencies in logical reasoning, symbolic precision, and multilingual robustness, with open-source models lagging behind proprietary ones. The authors further propose KE-Check, a two-stage method consisting of Knowledge Elaboration for prompt enrichment followed by Checklist-Guided Refinement for violation detection and editing, claiming that it mitigates scientific hallucinations and narrows the performance gap between model classes.
Significance. If KVBench's scoring protocol reliably isolates scientific correctness (structural constraints, symbolic conventions, and domain accuracy) rather than general prompt adherence, and if KE-Check's gains prove robust and reproducible, the work would meaningfully advance reliable knowledge visualization in T2I systems. The public release of the benchmark, prompts, and code is a clear strength that supports reproducibility and community follow-up.
major comments (3)
- [§3] §3 (Benchmark Construction): The manuscript states that prompts are 'expert-curated' from authoritative textbooks but provides no explicit protocol or validation step ensuring that prompts test structural constraints, symbolic conventions, and domain-specific correctness (e.g., correct molecular geometry, equation rendering, or map projections) rather than semantic plausibility alone. This is load-bearing for the claim that KVBench measures scientific hallucinations.
- [§5] §5 (Experiments and Evaluation): The reported narrowing of the open-to-closed model gap after KE-Check is presented without accompanying quantitative tables, per-subject or per-model scores, statistical significance tests, or error analysis. In addition, the image-level correctness protocol (expert rubric scoring on specific criteria, automated symbolic verification, or semantic similarity) is not described, leaving the central empirical claim unsupported.
- [§4.2] §4.2 (Checklist-Guided Refinement): The violation identification and constraint-guided editing steps are described at a high level but lack implementation details on whether violation detection is automated, how checklists are instantiated per subject, or whether human intervention is required; this directly affects reproducibility of the claimed performance gains.
minor comments (2)
- [Abstract] The abstract claims evaluation of 'multilingual robustness' yet the benchmark description centers on English-language textbooks; a brief clarification of language coverage or additional non-English prompts would improve completeness.
- [§5] Figure captions and axis labels in the experimental results section could be expanded to explicitly state the correctness metric being plotted (e.g., 'scientific accuracy score' vs. 'CLIP similarity').
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important areas where additional clarity and documentation will strengthen the manuscript. We address each major comment point by point below and will revise the paper accordingly to improve reproducibility and support for our claims.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction): The manuscript states that prompts are 'expert-curated' from authoritative textbooks but provides no explicit protocol or validation step ensuring that prompts test structural constraints, symbolic conventions, and domain-specific correctness (e.g., correct molecular geometry, equation rendering, or map projections) rather than semantic plausibility alone. This is load-bearing for the claim that KVBench measures scientific hallucinations.
Authors: We agree that §3 would benefit from an expanded description of the curation protocol to make explicit how prompts were designed to target structural, symbolic, and domain-specific elements. In the revised manuscript we will add a dedicated subsection outlining the multi-stage process: (1) initial selection by subject experts (PhD candidates and high-school teachers) from the 30+ textbooks, focusing on items that require precise rendering of diagrams, equations, maps, or molecular structures; (2) a validation checklist applied to each prompt to confirm it tests correctness rather than mere plausibility; and (3) cross-review of a 20% random sample by a second expert with inter-annotator agreement reported. This will directly address the concern while preserving the benchmark's grounding in authoritative sources. revision: yes
-
Referee: [§5] §5 (Experiments and Evaluation): The reported narrowing of the open-to-closed model gap after KE-Check is presented without accompanying quantitative tables, per-subject or per-model scores, statistical significance tests, or error analysis. In addition, the image-level correctness protocol (expert rubric scoring on specific criteria, automated symbolic verification, or semantic similarity) is not described, leaving the central empirical claim unsupported.
Authors: We acknowledge that the current presentation of results in §5 is insufficiently detailed. We will add comprehensive tables reporting per-subject and per-model scores (both pre- and post-KE-Check), including mean and standard deviation across multiple runs. Paired statistical significance tests (e.g., Wilcoxon signed-rank) will be included to quantify the gap reduction. The evaluation protocol will be fully specified: a hybrid approach combining (a) expert rubric scoring on four criteria (factual accuracy, structural fidelity, symbolic precision, and constraint adherence) by two independent annotators per image, (b) automated symbolic verification for math and chemistry elements using rule-based parsers, and (c) semantic similarity as a supplementary metric. A new error-analysis subsection will categorize failure modes. These additions will make the empirical claims fully supported and reproducible. revision: yes
-
Referee: [§4.2] §4.2 (Checklist-Guided Refinement): The violation identification and constraint-guided editing steps are described at a high level but lack implementation details on whether violation detection is automated, how checklists are instantiated per subject, or whether human intervention is required; this directly affects reproducibility of the claimed performance gains.
Authors: We will substantially expand §4.2 with concrete implementation details. Violation detection is fully automated: an LLM-based checker compares the generated image description against the subject-specific checklist, augmented by deterministic rule-based verifiers for symbolic content (e.g., equation syntax, molecular bond counts). Checklists are instantiated automatically from a template library derived from the six subject categories in KVBench; we will release the exact templates and generation code. No human intervention is required at inference time—the pipeline runs end-to-end. We will include pseudocode, per-subject checklist examples, and ablation results showing the contribution of each component. These details will enable direct reproduction of the reported gains. revision: yes
Circularity Check
No circularity: benchmark and method are empirically grounded without self-referential reductions
full rationale
The paper constructs KVBench as a new curriculum-grounded benchmark with 1,800 expert-curated prompts from over 30 textbooks and evaluates 14 models empirically. KE-Check is introduced as a two-stage prompt enrichment and refinement framework whose effectiveness is measured via direct performance comparisons on the benchmark. No equations, fitted parameters, uniqueness theorems, or self-citations are invoked as load-bearing steps in any derivation chain. All central claims (deficiencies in models, gap narrowing after KE-Check) rest on new data collection and testing rather than reducing to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expert-curated prompts from authoritative high-school textbooks accurately represent the requirements for knowledge-intensive text-to-image generation.
Reference graph
Works this paper leans on
-
[1]
Improving image generation with better captions
James Betker, Gabriel Goh, Li Jing, Tim Brooks, Jianfeng Wang, Linjie Li, Long Ouyang, Juntang Zhuang, Joyce Lee, Yufei Guo, et al. Improving image generation with better captions. Computer Science. https://cdn. openai. com/papers/dall-e-3. pdf, 2(3):8, 2023
2023
-
[2]
Flux.1: Flowing from foundations to frontiers
Black Forest Labs. Flux.1: Flowing from foundations to frontiers. Technical report, Black Forest Labs, 2024. Technical Report
2024
-
[3]
Flux.2: The next generation of rectified flow transformers
Black Forest Labs. Flux.2: The next generation of rectified flow transformers. https:// blackforestlabs.ai/, 2025. Technical Report. Includes FLUX.2-dev and FLUX.2-max variants
2025
-
[4]
Benchlmm: Benchmarking cross-style visual capability of large multimodal models, 2023
Rizhao Cai, Zirui Song, Dayan Guan, Zhenhao Chen, Xing Luo, Chenyu Yi, and Alex Kot. Benchlmm: Benchmarking cross-style visual capability of large multimodal models, 2023
2023
-
[5]
Sd3.5-large-gguf (revision bd9682c)
calcuis. Sd3.5-large-gguf (revision bd9682c). https://huggingface.co/calcuis/sd3. 5-large-gguf, 2024
2024
-
[6]
Oneig-bench: Omni-dimensional nuanced evaluation for image generation
Jingjing Chang, Yixiao Fang, Peng Xing, Shuhan Wu, Wei Cheng, Rui Wang, Xianfang Zeng, Gang Yu, and Hai-Bao Chen. OneIG-Bench: Omni-dimensional nuanced evaluation for image generation. arXiv preprint arXiv:2506.07977, 2025. arXiv:2506.07977
-
[7]
Sridbench: Benchmark of scientific research illustration drawing of image generation model, 2025
Yifan Chang, Yukang Feng, Jianwen Sun, Jiaxin Ai, Chuanhao Li, S Kevin Zhou, and Kaipeng Zhang. Sridbench: Benchmark of scientific research illustration drawing of image generation model, 2025
2025
-
[8]
Janus-pro: Unified multimodal understanding and generation with data and model scaling, 2025
Xiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, and Chong Ruan. Janus-pro: Unified multimodal understanding and generation with data and model scaling, 2025
2025
-
[9]
Visual programming for step-by-step text-to-image generation and evaluation.Advances in Neural Information Processing Systems, 36:6048–6069, 2023
Jaemin Cho, Abhay Zala, and Mohit Bansal. Visual programming for step-by-step text-to-image generation and evaluation.Advances in Neural Information Processing Systems, 36:6048–6069, 2023
2023
-
[10]
Physbench: Benchmarking and enhancing vision-language models for physical world understanding, 2025
Wei Chow, Jiageng Mao, Boyi Li, Daniel Seita, Vitor Guizilini, and Yue Wang. Physbench: Benchmarking and enhancing vision-language models for physical world understanding, 2025
2025
-
[11]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review arXiv 2025
-
[12]
Gemini 3 pro image model card
Google DeepMind. Gemini 3 pro image model card. https://storage.googleapis.com/ deepmind-media/Model-Cards/Gemini-3-Pro-Image-Model-Card.pdf, 11 2025. 10
2025
-
[14]
Emerging properties in unified multimodal pretraining, 2025
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, Guang Shi, and Haoqi Fan. Emerging properties in unified multimodal pretraining, 2025
2025
-
[15]
Diffusion models beat gans on image synthesis
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis. Advances in neural information processing systems, 34:8780–8794, 2021
2021
-
[16]
Scaling rectified flow transformers for high-resolution image synthesis, 2024
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, Kyle Lacey, Alex Goodwin, Yannik Marek, and Robin Rombach. Scaling rectified flow transformers for high-resolution image synthesis, 2024
2024
-
[17]
Geobench: Rethinking multimodal geometric problem-solving via hierarchical evaluation, 2025
Yuan Feng, Yue Yang, Xiaohan He, Jiatong Zhao, Jianlong Chen, Zijun Chen, Daocheng Fu, Qi Liu, Renqiu Xia, Bo Zhang, and Junchi Yan. Geobench: Rethinking multimodal geometric problem-solving via hierarchical evaluation, 2025
2025
-
[18]
Commonsense-t2i challenge: Can text-to-image generation models understand commonsense?, 2024
Xingyu Fu, Muyu He, Yujie Lu, William Yang Wang, and Dan Roth. Commonsense-t2i challenge: Can text-to-image generation models understand commonsense?, 2024
2024
-
[19]
PhD thesis, University of Washington, 2025
Yujuan Fu.Evaluating and Enhancing Large Language Models (LLMs) in the Clinical Domain. PhD thesis, University of Washington, 2025
2025
-
[20]
Seed-x: Multimodal models with unified multi-granularity comprehension and generation, 2025
Yuying Ge, Sijie Zhao, Jinguo Zhu, Yixiao Ge, Kun Yi, Lin Song, Chen Li, Xiaohan Ding, and Ying Shan. Seed-x: Multimodal models with unified multi-granularity comprehension and generation, 2025
2025
-
[21]
Repairing the cracked foundation: A survey of obstacles in evaluation practices for generated text.Journal of Artificial Intelligence Research, 77:103–166, 2023
Sebastian Gehrmann, Elizabeth Clark, and Thibault Sellam. Repairing the cracked foundation: A survey of obstacles in evaluation practices for generated text.Journal of Artificial Intelligence Research, 77:103–166, 2023
2023
-
[22]
Geneval: An object-focused framework for evaluating text-to-image alignment.Advances in Neural Information Processing Systems, 36:52132–52152, 2023
Dhruba Ghosh, Hannaneh Hajishirzi, and Ludwig Schmidt. Geneval: An object-focused framework for evaluating text-to-image alignment.Advances in Neural Information Processing Systems, 36:52132–52152, 2023
2023
-
[23]
Space-10: A comprehensive benchmark for multimodal large language models in compositional spatial intelligence, 2025
Ziyang Gong, Wenhao Li, Oliver Ma, Songyuan Li, Zhaokai Wang, Songyuan Li, Jiayi Ji, Xue Yang, Gen Luo, Junchi Yan, and Rongrong Ji. Space-10: A comprehensive benchmark for multimodal large language models in compositional spatial intelligence, 2025
2025
-
[24]
Introducing gemini 2.5 flash image, our state-of-the-art image model
Google. Introducing gemini 2.5 flash image, our state-of-the-art image model. https:// developers.googleblog.com/en/introducing-gemini-2-5-flash-image/, 2025
2025
-
[25]
Gemini 3.1 pro: Frontier multimodal models with advanced reasoning and agentic capabilities
Google DeepMind. Gemini 3.1 pro: Frontier multimodal models with advanced reasoning and agentic capabilities. Technical report, Google DeepMind, 2026. Technical Report
2026
-
[26]
Clipscore: A reference-free evaluation metric for image captioning, 2022
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. Clipscore: A reference-free evaluation metric for image captioning, 2022
2022
-
[27]
Gans trained by a two time-scale update rule converge to a local nash equilibrium, 2018
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium, 2018
2018
-
[28]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[29]
Tifa: Accurate and interpretable text-to-image faithfulness evaluation with question answering, 2023
Yushi Hu, Benlin Liu, Jungo Kasai, Yizhong Wang, Mari Ostendorf, Ranjay Krishna, and Noah A Smith. Tifa: Accurate and interpretable text-to-image faithfulness evaluation with question answering, 2023
2023
-
[30]
T2i-compbench: A compre- hensive benchmark for open-world compositional text-to-image generation.Advances in Neural Information Processing Systems, 36:78723–78747, 2023
Kaiyi Huang, Kaiyue Sun, Enze Xie, Zhenguo Li, and Xihui Liu. T2i-compbench: A compre- hensive benchmark for open-world compositional text-to-image generation.Advances in Neural Information Processing Systems, 36:78723–78747, 2023. 11
2023
-
[31]
Vchain: Chain-of-visual-thought for reasoning in video generation, 2025
Ziqi Huang, Ning Yu, Gordon Chen, Haonan Qiu, Paul Debevec, and Ziwei Liu. Vchain: Chain-of-visual-thought for reasoning in video generation, 2025
2025
-
[32]
Survey of hallucination in natural language generation
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation. ACM computing surveys, 55(12):1–38, 2023
2023
-
[33]
Are you smarter than a sixth grader? textbook question answering for multimodal machine comprehension
Aniruddha Kembhavi, Minjoon Seo, Dustin Schwenk, Jonghyun Choi, Ali Farhadi, and Han- naneh Hajishirzi. Are you smarter than a sixth grader? textbook question answering for multimodal machine comprehension. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 4999–5008, Washington, DC, USA, 2017. IEEE Computer Society
2017
-
[34]
Think-then-generate: Reasoning-aware text-to-image diffusion with llm encoders, 2026
Siqi Kou, Jiachun Jin, Zetong Zhou, Ye Ma, Yugang Wang, Quan Chen, Peng Jiang, Xiao Yang, Jun Zhu, Kai Yu, and Zhijie Deng. Think-then-generate: Reasoning-aware text-to-image diffusion with llm encoders, 2026
2026
-
[35]
Flux.https://github.com/black-forest-labs/flux, 2024
Black Forest Labs. Flux.https://github.com/black-forest-labs/flux, 2024
2024
-
[36]
FLUX.2: Frontier Visual Intelligence
Black Forest Labs. FLUX.2: Frontier Visual Intelligence. https://bfl.ai/blog/flux-2, 2025
2025
-
[37]
Flux.1 krea [dev]
Sangwu Lee, Titus Ebbecke, Erwann Millon, Will Beddow, Le Zhuo, Iker García-Ferrero, Liam Esparraguera, Mihai Petrescu, Gian Saß, Gabriel Menezes, and Victor Perez. Flux.1 krea [dev]. https://github.com/krea-ai/flux-krea, 2025
2025
-
[38]
Checkeval: A reliable llm-as-a-judge framework for evaluating text generation using checklists, 2025
Yukyung Lee, Joonghoon Kim, Jaehee Kim, Hyowon Cho, Jaewook Kang, Pilsung Kang, and Najoung Kim. Checkeval: A reliable llm-as-a-judge framework for evaluating text generation using checklists, 2025
2025
-
[39]
Evaluating object hallucination in large vision-language models, 2023
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models, 2023
2023
-
[40]
Llm-grounded diffusion: Enhancing prompt understanding of text-to-image diffusion models with large language models, 2024
Long Lian, Boyi Li, Adam Yala, and Trevor Darrell. Llm-grounded diffusion: Enhancing prompt understanding of text-to-image diffusion models with large language models, 2024
2024
-
[41]
Evaluating text-to-visual generation with image-to-text generation, 2024
Zhiqiu Lin, Deepak Pathak, Baiqi Li, Jiayao Li, Xide Xia, Graham Neubig, Pengchuan Zhang, and Deva Ramanan. Evaluating text-to-visual generation with image-to-text generation, 2024
2024
-
[42]
Mmbench: Is your multi-modal model an all-around player?, 2024
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, Kai Chen, and Dahua Lin. Mmbench: Is your multi-modal model an all-around player?, 2024
2024
-
[43]
Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts, 2024
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts, 2024
2024
-
[44]
Learn to explain: Multimodal reasoning via thought chains for science question answering.Advances in Neural Information Processing Systems, 35:2507–2521, 2022
Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multimodal reasoning via thought chains for science question answering.Advances in Neural Information Processing Systems, 35:2507–2521, 2022
2022
-
[45]
Mmmg: A massive, multidisciplinary, multi-tier generation benchmark for text-to-image reasoning, 2025
Yuxuan Luo, Yuhui Yuan, Junwen Chen, Haonan Cai, Ziyi Yue, Yuwei Yang, Fatima Zohra Daha, Ji Li, and Zhouhui Lian. Mmmg: A massive, multidisciplinary, multi-tier generation benchmark for text-to-image reasoning, 2025
2025
-
[46]
Janusflow: Harmonizing autoregression and rectified flow for unified multimodal understanding and generation, 2025
Yiyang Ma, Xingchao Liu, Xiaokang Chen, Wen Liu, Chengyue Wu, Zhiyu Wu, Zizheng Pan, Zhenda Xie, Haowei Zhang, Xingkai yu, Liang Zhao, Yisong Wang, Jiaying Liu, and Chong Ruan. Janusflow: Harmonizing autoregression and rectified flow for unified multimodal understanding and generation, 2025
2025
-
[47]
Phybench: A physical commonsense benchmark for evaluating text-to-image models, 2024
Fanqing Meng, Wenqi Shao, Lixin Luo, Yahong Wang, Yiran Chen, Quanfeng Lu, Yue Yang, Tianshuo Yang, Kaipeng Zhang, Yu Qiao, and Ping Luo. Phybench: A physical commonsense benchmark for evaluating text-to-image models, 2024. 12
2024
-
[48]
Khapra, and Pratyush Kumar
Nitesh Methani, Pritha Ganguly, Mitesh M. Khapra, and Pratyush Kumar. Plotqa: Reasoning over scientific plots, 2020
2020
-
[49]
Wise: A world knowledge-informed semantic evaluation for text-to-image generation, 2025
Yuwei Niu, Munan Ning, Mengren Zheng, Weiyang Jin, Bin Lin, Peng Jin, Jiaqi Liao, Chaoran Feng, Kunpeng Ning, Bin Zhu, and Li Yuan. Wise: A world knowledge-informed semantic evaluation for text-to-image generation, 2025
2025
-
[50]
OpenAI, :, Aaron Hurst, Adam Lerer, Adam P. Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, Aleksander M ˛ adry, Alex Baker-Whitcomb, Alex Beutel, Alex Borzunov, Alex Carney, Alex Chow, Alex Kirillov, Alex Nichol, Alex Paino, Alex Renzin, Alex Tachard Passos, Alexander Kirillov, Alexi Christakis, A...
2024
-
[51]
Gpt-image-1.https://openai.com/index/image-generation-api/, 2025
OpenAI. Gpt-image-1.https://openai.com/index/image-generation-api/, 2025
2025
-
[52]
Layoutllm-t2i: Eliciting layout guidance from llm for text-to-image generation, 2023
Leigang Qu, Shengqiong Wu, Hao Fei, Liqiang Nie, and Tat-Seng Chua. Layoutllm-t2i: Eliciting layout guidance from llm for text-to-image generation, 2023
2023
-
[53]
Zero-shot text-to-image generation, 2021
Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea V oss, Alec Radford, Mark Chen, and Ilya Sutskever. Zero-shot text-to-image generation, 2021
2021
-
[54]
High-resolution image synthesis with latent diffusion models, 2022
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models, 2022
2022
-
[55]
Seedream 4.0: Toward next-generation multimodal image generation, 2025
Team Seedream, :, Yunpeng Chen, Yu Gao, Lixue Gong, Meng Guo, Qiushan Guo, Zhiyao Guo, Xiaoxia Hou, Weilin Huang, Yixuan Huang, Xiaowen Jian, Huafeng Kuang, Zhichao Lai, Fanshi Li, Liang Li, Xiaochen Lian, Chao Liao, Liyang Liu, Wei Liu, Yanzuo Lu, Zhengxiong Luo, Tongtong Ou, Guang Shi, Yichun Shi, Shiqi Sun, Yu Tian, Zhi Tian, Peng Wang, Rui Wang, Xun W...
2025
-
[56]
T2i-reasonbench: Benchmarking reasoning-informed text-to-image generation, 2025
Kaiyue Sun, Rongyao Fang, Chengqi Duan, Xian Liu, and Xihui Liu. T2i-reasonbench: Benchmarking reasoning-informed text-to-image generation, 2025
2025
-
[57]
Autoregressive model beats diffusion: Llama for scalable image generation, 2024
Peize Sun, Yi Jiang, Shoufa Chen, Shilong Zhang, Bingyue Peng, Ping Luo, and Zehuan Yuan. Autoregressive model beats diffusion: Llama for scalable image generation, 2024
2024
-
[58]
Vipergpt: Visual inference via python execution for reasoning, 2023
Dídac Surís, Sachit Menon, and Carl V ondrick. Vipergpt: Visual inference via python execution for reasoning, 2023
2023
-
[59]
Chameleon: Mixed-modal early-fusion foundation models, 2025
Chameleon Team. Chameleon: Mixed-modal early-fusion foundation models, 2025
2025
-
[61]
Z-image: An efficient image generation foundation model with single-stream diffusion transformer, 2025
Image Team, Huanqia Cai, Sihan Cao, Ruoyi Du, Peng Gao, Steven Hoi, Zhaohui Hou, Shijie Huang, Dengyang Jiang, Xin Jin, Liangchen Li, Zhen Li, Zhong-Yu Li, David Liu, Dongyang Liu, Junhan Shi, Qilong Wu, Feng Yu, Chi Zhang, Shifeng Zhang, and Shilin Zhou. Z-image: An efficient image generation foundation model with single-stream diffusion transformer, 2025
2025
-
[62]
Visual autoregressive modeling: Scalable image generation via next-scale prediction.Advances in neural information processing systems, 37:84839–84865, 2024
Keyu Tian, Yi Jiang, Zehuan Yuan, Bingyue Peng, and Liwei Wang. Visual autoregressive modeling: Scalable image generation via next-scale prediction.Advances in neural information processing systems, 37:84839–84865, 2024. 14
2024
-
[63]
Chartgpt: Leveraging llms to generate charts from abstract natural language.IEEE Transactions on Visualization and Computer Graphics, 31(3):1731–1745, 2024
Yuan Tian, Weiwei Cui, Dazhen Deng, Xinjing Yi, Yurun Yang, Haidong Zhang, and Yingcai Wu. Chartgpt: Leveraging llms to generate charts from abstract natural language.IEEE Transactions on Visualization and Computer Graphics, 31(3):1731–1745, 2024
2024
-
[64]
Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency, 2025
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, Zhaokai Wang, Zhe Chen, Hongjie Zhang, Ganlin Yang, Haomin Wang, Qi Wei, Jinhui Yin, Wenhao Li, Erfei Cui, Guanzhou Chen, Zichen Ding, Changyao Tian, Zhenyu Wu, Jingjing Xie, Zehao Li, Bowen Yang, Yuchen Duan, Xuehui Wang, Zhi Hou,...
2025
-
[65]
Emu3: Next-token prediction is all you need, 2024
Xinlong Wang, Xiaosong Zhang, Zhengxiong Luo, Quan Sun, Yufeng Cui, Jinsheng Wang, Fan Zhang, Yueze Wang, Zhen Li, Qiying Yu, Yingli Zhao, Yulong Ao, Xuebin Min, Tao Li, Boya Wu, Bo Zhao, Bowen Zhang, Liangdong Wang, Guang Liu, Zheqi He, Xi Yang, Jingjing Liu, Yonghua Lin, Tiejun Huang, and Zhongyuan Wang. Emu3: Next-token prediction is all you need, 2024
2024
-
[66]
Genexam: A multidisciplinary text-to-image exam, 2026
Zhaokai Wang, Penghao Yin, Xiangyu Zhao, Changyao Tian, Yu Qiao, Wenhai Wang, Jifeng Dai, and Gen Luo. Genexam: A multidisciplinary text-to-image exam, 2026
2026
-
[68]
Qwen-image technical report, 2025
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, Yuxiang Chen, Zecheng Tang, Zekai Zhang, Zhengyi Wang, An Yang, Bowen Yu, Chen Cheng, Dayiheng Liu, Deqing Li, Hang Zhang, Hao Meng, Hu Wei, Jingyuan Ni, Kai Chen, Kuan Cao, Liang Peng, Lin Qu, Minggang Wu, Peng Wang, Shuting Yu, Tingkun...
2025
-
[69]
Omnigen2: Exploration to advanced multimodal generation, 2025
Chenyuan Wu, Pengfei Zheng, Ruiran Yan, Shitao Xiao, Xin Luo, Yueze Wang, Wanli Li, Xiyan Jiang, Yexin Liu, Junjie Zhou, Ze Liu, Ziyi Xia, Chaofan Li, Haoge Deng, Jiahao Wang, Kun Luo, Bo Zhang, Defu Lian, Xinlong Wang, Zhongyuan Wang, Tiejun Huang, and Zheng Liu. Omnigen2: Exploration to advanced multimodal generation, 2025
2025
-
[70]
Omnigen: Unified image generation, 2024
Shitao Xiao, Yueze Wang, Junjie Zhou, Huaying Yuan, Xingrun Xing, Ruiran Yan, Chaofan Li, Shuting Wang, Tiejun Huang, and Zheng Liu. Omnigen: Unified image generation, 2024
2024
-
[72]
Show-o2: Improved native unified multimodal models, 2025
Jinheng Xie, Zhenheng Yang, and Mike Zheng Shou. Show-o2: Improved native unified multimodal models, 2025
2025
-
[74]
Chartbench: A benchmark for complex visual reasoning in charts, 2024
Zhengzhuo Xu, Sinan Du, Yiyan Qi, Chengjin Xu, Chun Yuan, and Jian Guo. Chartbench: A benchmark for complex visual reasoning in charts, 2024
2024
-
[75]
The dawn of lmms: Preliminary explorations with gpt-4v(ision), 2023
Zhengyuan Yang, Linjie Li, Kevin Lin, Jianfeng Wang, Chung-Ching Lin, Zicheng Liu, and Lijuan Wang. The dawn of lmms: Preliminary explorations with gpt-4v(ision), 2023. 15
2023
-
[76]
Scaling Autoregressive Models for Content-Rich Text-to-Image Generation
Jiahui Yu, Yuanzhong Xu, Jing Yu Koh, Thang Luong, Gunjan Baid, Zirui Wang, Vijay Vasudevan, Alexander Ku, Yinfei Yang, Burcu Karagol Ayan, et al. Scaling autoregressive models for content-rich text-to-image generation.arXiv preprint arXiv:2206.10789, 2(3):5, 2022
work page internal anchor Pith review arXiv 2022
-
[77]
Mm-vet: Evaluating large multimodal models for integrated capabilities, 2024
Weihao Yu, Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Zicheng Liu, Xinchao Wang, and Lijuan Wang. Mm-vet: Evaluating large multimodal models for integrated capabilities, 2024
2024
-
[78]
Zhongwei Zhang, Fuchen Long, Wei Li, Zhaofan Qiu, Wu Liu, Ting Yao, and Tao Mei. Region-Constraint In-Context Generation for Instructional Video Editing.arXiv preprint arXiv:2512.17650, 2025
-
[79]
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623, 2023
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623, 2023
2023
-
[80]
Yuhao Zhou, Yiheng Wang, Xuming He, Ao Shen, Ruoyao Xiao, Zhiwei Li, Qiantai Feng, Zijie Guo, Yuejin Yang, Hao Wu, Wenxuan Huang, Jiaqi Wei, Dan Si, Xiuqi Yao, Jia Bu, Haiwen Huang, Manning Wang, Tianfan Fu, Shixiang Tang, Ben Fei, Dongzhan Zhou, Fenghua Ling, Yan Lu, Siqi Sun, Chenhui Li, Guanjie Zheng, Jiancheng Lv, Wenlong Zhang, and Lei Bai. Scientist...
-
[81]
Interpretation of the original educational concept or theme
-
[82]
Identification of major knowledge elements, entities, symbols, labels, formulas, charts, or processes to be visualized
-
[83]
Spatial structure analysis: layout areas, panels, foreground/background layers, arrows, annotations, grouping boxes, coordinate axes, and flow directions
-
[84]
Classification of scene and media type: textbook diagram, infographic, blackboard sketch, whiteboard drawing, classroom poster, digital schematic, slide-style chart, etc
-
[85]
The above dimensions are default expectations
Description coverage self-check: Ensure that, where visually inferable, the final description includes: - All core concepts and visual components; - Symbol shapes, colors, and line types; - Relative positions and layout structures; - Directional relationships and process flows; - Scene type (e.g., classroom, digital slide, isolated chart on a white backgr...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.