Recognition: unknown
Finite element model updating of building structures under seismic excitation: A parallelized latent space-based Bayesian framework
Pith reviewed 2026-05-08 09:13 UTC · model grok-4.3
The pith
A latent-space variational autoencoder combined with GPU-parallel sequential Monte Carlo sampling enables efficient Bayesian updating of finite-element building models from seismic response data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
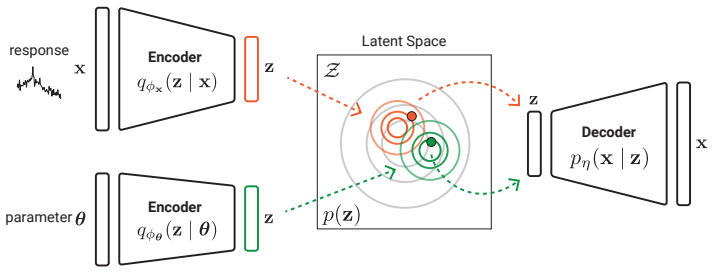
Projecting high-dimensional structural response data into a low-dimensional latent space via a multimodal variational autoencoder permits tractable likelihood evaluation in the original observation space, while a GPU-parallelized sequential Monte Carlo sampler performs robust posterior sampling without further simulator calls once the surrogate is trained.
What carries the argument
The multimodal variational autoencoder that maps seismic response time histories or frequency response functions into a low-dimensional latent representation, paired with a GPU-accelerated sequential Monte Carlo sampler for amortized Bayesian inference.
If this is right
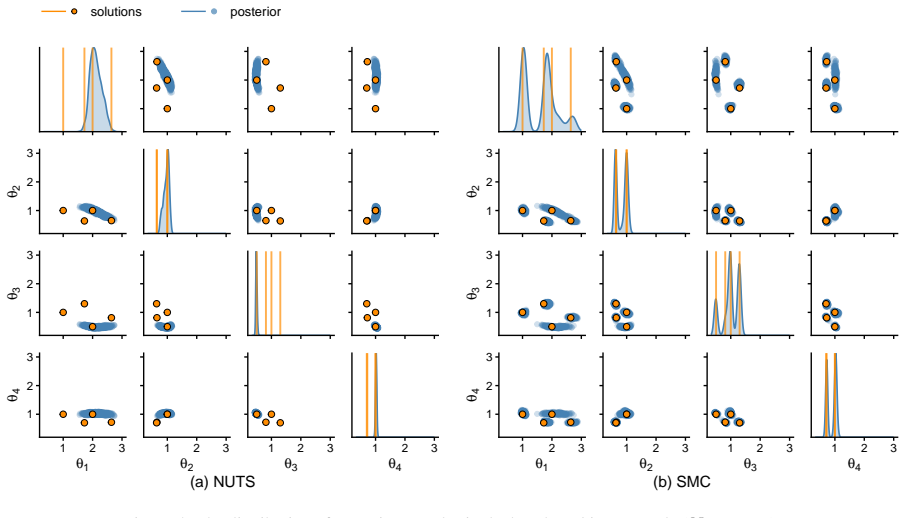
- Structural stiffness and damping parameters are recovered with quantified uncertainties from both numerical and experimental seismic data.
- After training, posterior sampling requires no additional finite-element simulator evaluations.
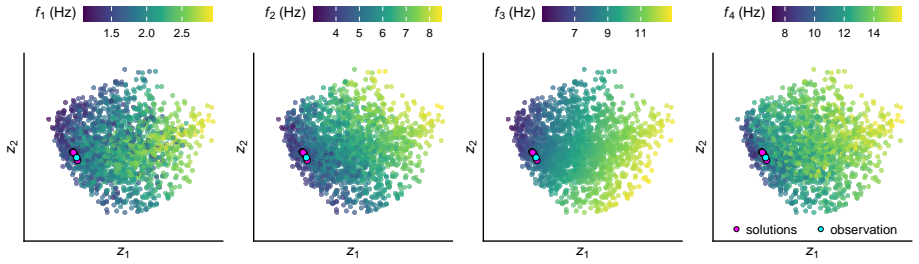
- GPU parallelization yields fast inference even when observations are sparse and induce multimodal posteriors.
- The framework supports robust inference for building structures under seismic excitation without explicit modeling in the full observation space.
Where Pith is reading between the lines
- The amortized property could support online model updating as new seismic records arrive in structural health monitoring systems.
- Similar latent-space compression might reduce costs for real-time fragility assessment of other civil infrastructure beyond nuclear facilities.
- The approach opens a route to hybrid physics-informed surrogates that combine the variational autoencoder with additional sensor modalities.
Load-bearing premise
The latent-space projection must retain enough information from the original high-dimensional responses that the resulting approximate likelihood still yields reliable posterior distributions.
What would settle it
Direct high-dimensional Bayesian updating performed on the same shaking-table dataset without the latent-space compression should produce posterior parameter distributions and uncertainty widths that differ materially from those obtained by the proposed method.
Figures



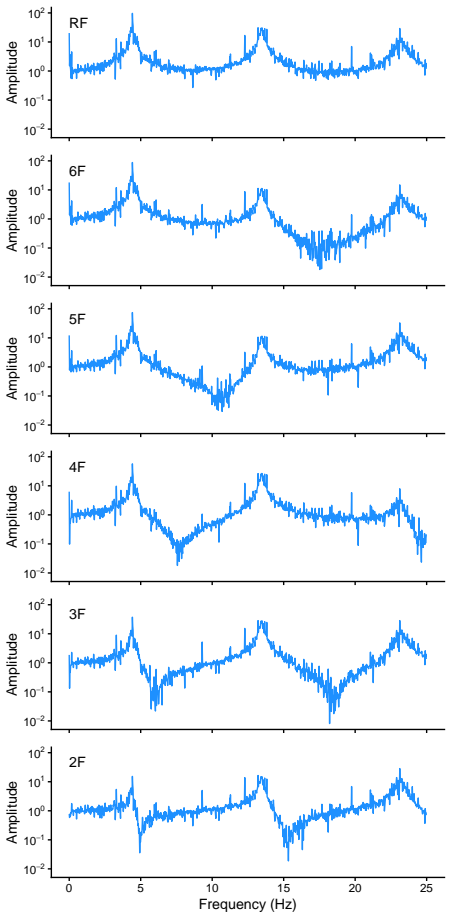
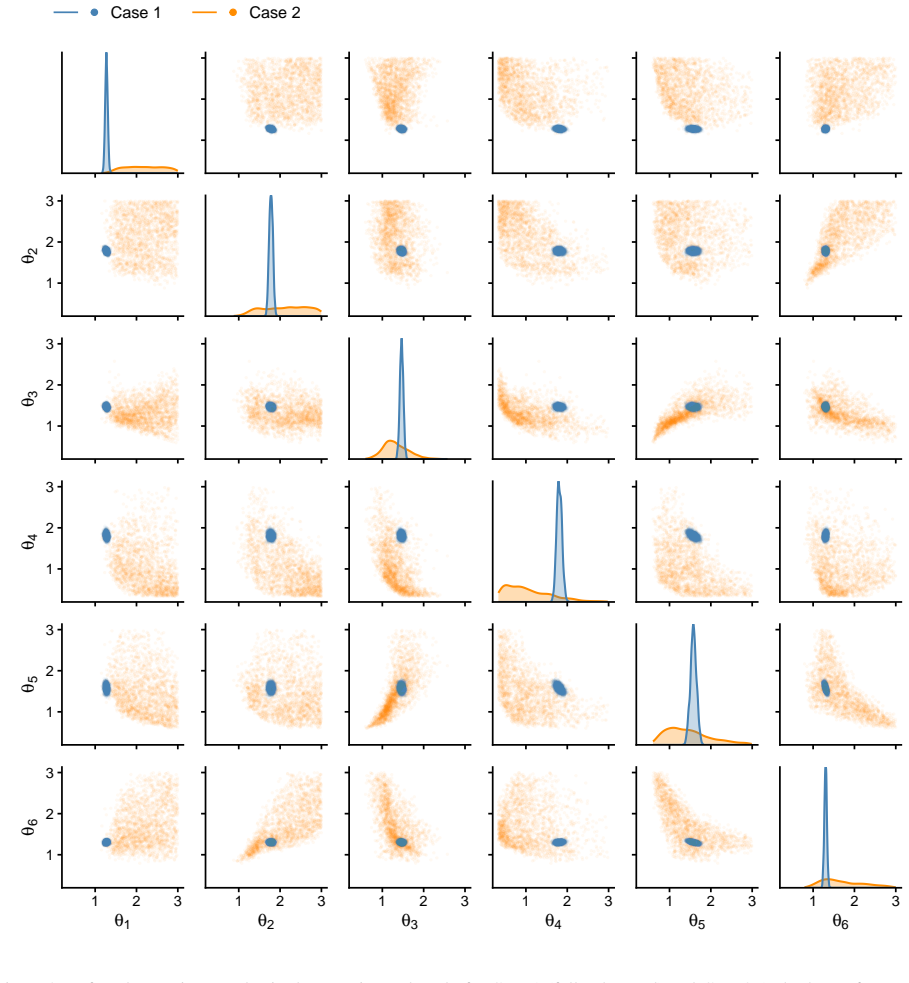
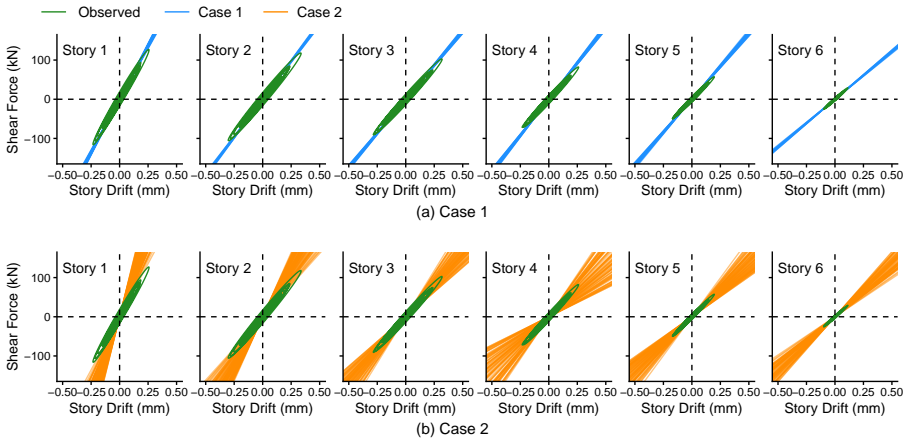

read the original abstract
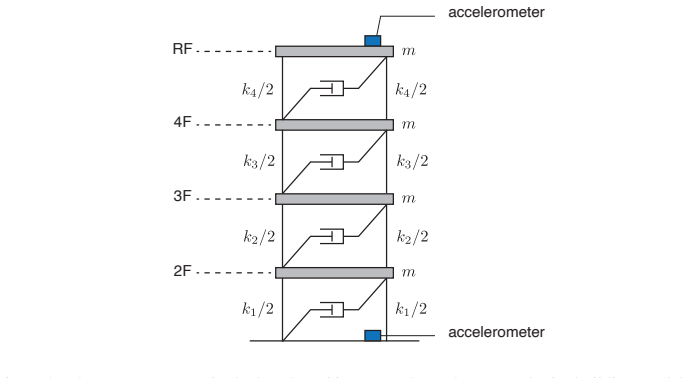
Enhancing seismic fragility and risk assessment of nuclear power plants relies on accurate prediction of reactor building responses to seismic hazards, which can be further improved through dynamic analysis of high-fidelity finite element (FE) models. However, FE models often exhibit non-negligible discrepancies from actual structures due to various sources of uncertainty, necessitating FE model updating with rigorous quantification of associated uncertainties. This paper presents a GPU-accelerated latent space--based Bayesian framework for FE model updating of building structures. In the proposed framework, high-dimensional structural response data (e.g., time histories or frequency response functions) are projected into a low-dimensional latent space using a multimodal variational autoencoder (MVAE), thereby enabling efficient and tractable likelihood evaluation without explicit modeling in the original observation space. Once trained, the surrogate enables amortized inference, allowing posterior sampling to be performed without additional simulator evaluations. We specifically employ a sequential Monte Carlo (SMC) sampler, whose population-based formulation allows parallel evaluation of the approximate likelihood on GPUs, resulting in computational efficiency and robustness against multimodal and complex posterior distributions. The proposed framework is validated through both numerical benchmarking and experimental data from a shaking table test of a reinforced concrete building structure. The results demonstrate that the method accurately estimates structural parameters with well-quantified uncertainties, while achieving fast and efficient inference through GPU-based parallelization, and enabling robust inference even in the presence of sparse observations that induce multimodal and highly complex posterior distributions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a GPU-accelerated Bayesian framework for finite element model updating of building structures under seismic excitation. High-dimensional structural responses (time histories or frequency response functions) are projected into a low-dimensional latent space via a multimodal variational autoencoder (MVAE) to enable tractable likelihood evaluation. Posterior inference is performed with a sequential Monte Carlo (SMC) sampler that exploits GPU parallelization for efficiency and robustness to multimodal posteriors induced by sparse data. The approach is validated on numerical benchmarks and shaking-table experiments on a reinforced concrete structure, with claims of accurate structural parameter estimation and well-quantified uncertainties.
Significance. If the latent-space approximation preserves posterior fidelity, the framework offers a practical route to uncertainty-aware FE model updating for seismic fragility assessment of critical infrastructure such as nuclear power plants. The combination of amortized MVAE inference with parallel SMC is a clear computational strength, and the experimental validation on real shaking-table data adds relevance. However, the absence of direct fidelity diagnostics for the surrogate likelihood limits the strength of the accuracy claims.
major comments (1)
- [Validation sections (numerical benchmarking and shaking-table experiments)] Validation sections (numerical benchmarking and shaking-table experiments): The central claim that the method 'accurately estimates structural parameters with well-quantified uncertainties' while remaining robust under sparse observations rests on the MVAE latent-space likelihood being a faithful surrogate. No quantitative fidelity check is reported (e.g., KL divergence between latent-space and full observation-space likelihoods, or differences in posterior moments/credible-interval coverage on identical datasets). This comparison is load-bearing for the accuracy and calibration assertions, especially given the paper's emphasis on multimodal posteriors.
minor comments (3)
- [Abstract] Abstract: The phrase 'multimodal variational autoencoder (MVAE)' is introduced without a brief parenthetical description of its key architectural feature (joint encoding of multiple data modalities) that distinguishes it from a standard VAE.
- [Methodology] Methodology: The latent dimension is treated as a free hyperparameter; a sensitivity study showing how posterior estimates and uncertainty quantification vary with this choice would clarify robustness.
- [Figures and tables] Figures and tables: Posterior marginal plots should explicitly label whether they derive from the latent-space or full-space likelihood when both are feasible, to allow visual assessment of approximation quality.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive review. The single major comment raises an important point about the need for explicit quantitative validation of the latent-space surrogate likelihood. We address this below and will incorporate the requested diagnostics in the revised manuscript.
read point-by-point responses
-
Referee: Validation sections (numerical benchmarking and shaking-table experiments): The central claim that the method 'accurately estimates structural parameters with well-quantified uncertainties' while remaining robust under sparse observations rests on the MVAE latent-space likelihood being a faithful surrogate. No quantitative fidelity check is reported (e.g., KL divergence between latent-space and full observation-space likelihoods, or differences in posterior moments/credible-interval coverage on identical datasets). This comparison is load-bearing for the accuracy and calibration assertions, especially given the paper's emphasis on multimodal posteriors.
Authors: We agree that direct quantitative fidelity diagnostics for the MVAE surrogate would strengthen the accuracy and calibration claims. The current manuscript validates the framework by showing that parameter estimates recover ground-truth values within credible intervals on numerical benchmarks and match independent experimental measurements on the shaking-table data, with the SMC sampler demonstrating robustness to the multimodal posteriors induced by sparse observations. However, we did not include explicit side-by-side comparisons of posteriors obtained with the full high-dimensional likelihood versus the latent-space approximation. In the revised manuscript we will add such a comparison on the numerical benchmark cases (where the full likelihood remains tractable for low-dimensional subsets of the data). We will report differences in posterior means and variances, credible-interval coverage rates, and, where feasible, estimated KL divergence between the two likelihoods. This addition will directly address the load-bearing nature of the surrogate for the stated claims. revision: yes
Circularity Check
No circularity detected; framework applies standard MVAE projection and SMC sampling to FE model updating
full rationale
The derivation chain consists of projecting high-dimensional response data into a latent space via a multimodal variational autoencoder, followed by amortized likelihood evaluation and GPU-parallelized sequential Monte Carlo sampling. These steps rely on established variational inference and Monte Carlo methods applied to a new application domain. Validation occurs through independent numerical benchmarks and shaking-table experiments on a reinforced concrete structure, with no equations or claims reducing the reported parameter estimates or uncertainty quantification to quantities defined by the same fitted inputs or self-citations. The central efficiency and robustness results therefore remain self-contained against external data.
Axiom & Free-Parameter Ledger
free parameters (1)
- latent dimension
axioms (1)
- domain assumption The multimodal variational autoencoder provides a sufficiently accurate approximation to the true data-generating process for tractable likelihood evaluation in the latent space.
Reference graph
Works this paper leans on
-
[1]
Accessed: 2026-04-11
ARKInformationSystems,Inc.,.TDAPIII:General-purpose3-DimensionalDynamicAnalysisProgramfor Civil Engineering and Architectural Use.https://www.ark-info-sys.co.jp/jp/product/tdap/ english/. Accessed: 2026-04-11. Beck, J.L., Katafygiotis, L.S.,
2026
-
[2]
A kernel two-sample test. J. Mach. Learn. Res. 13, 723–773. Hoffman,M.D.,Gelman,A.,2014. TheNo-U-Turnsampler: AdaptivelysettingpathlengthsinHamiltonian Monte Carlo. Journal of Machine Learning Research 15, 1593–1623. Huang, Y., Shao, C., Wu, B., Beck, J.L., Li, H.,
2014
-
[3]
Shake Table Experiment of Downsized 6-story RC Building with Earthquake Resisting Wall Frame
E-Defense Experimental Data Archive (ASEBI): Project Name "Shake Table Experiment of Downsized 6-story RC Building with Earthquake Resisting Wall Frame" Experiment No. E201401. doi:10.17598/NIED.0020-E201401. Neal, R.M.,
-
[4]
A survey of multimodal deep generative models. Adv. Robot. 36, 261–278. Wang,T.,Bi,S.,2026. Stochasticmodelupdatingusingconditionaldiffusion-basedprobabilisticgenerative models. Mech. Syst. Signal Process. 246, 113891. Wang, T., Bi, S., Zhao, Y., Dinh, L., Mottershead, J.,
2026
-
[5]
Data-driven stochastic model updating and damage detection with deep generative model. Mech. Syst. Signal Process. 232, 112743. Yaoyama,T.,Itoi,T.,Iyama,J.,2024. Probabilisticmodelupdatingofsteelframestructuresusingstrainand accelerationmeasurements: Amultitasklearningframework. StructuralSafety108,102442. doi:https: //doi.org/10.1016/j.strusafe.2024.1024...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.