Recognition: unknown
FILTR: Extracting Topological Features from Pretrained 3D Models
Pith reviewed 2026-05-08 12:31 UTC · model grok-4.3
The pith
FILTR recovers persistence diagrams from the internal features of frozen pretrained 3D point cloud encoders via a transformer decoder.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FILTR adapts a transformer decoder to map features from frozen 3D encoders to persistence diagrams by framing diagram generation as set prediction, and experiments on the DONUT benchmark demonstrate that the resulting approximations are feasible even though the encoders retain only limited global topological signals.
What carries the argument
FILTR, a transformer decoder that takes features from a frozen pretrained 3D encoder and outputs persistence diagrams as a set prediction task.
If this is right
- Persistence diagrams become accessible as a downstream output from any frozen 3D encoder without recomputing filtrations.
- Topological analysis can be performed in a single forward pass after the encoder step.
- Synthetic benchmarks with controlled topology can guide development of learnable topological extractors.
- Existing pretrained models can be reused for topological tasks without full retraining.
Where Pith is reading between the lines
- If the approach generalizes beyond DONUT, topological data analysis could be added to standard 3D pipelines as a lightweight post-processing step.
- The set-prediction formulation may extend to other topological invariants or to variable diagram sizes without architectural changes.
- Success on synthetic data raises the question of whether similar decoders could extract topology from 2D image encoders or graph neural networks.
Load-bearing premise
The internal features of frozen 3D encoders contain enough topological signal for a transformer decoder to recover accurate persistence diagrams.
What would settle it
FILTR producing persistently inaccurate or topologically meaningless persistence diagrams on the DONUT benchmark across multiple pretrained encoders, or showing no improvement over direct topological computation baselines.
Figures












read the original abstract
Recent advances in pretraining 3D point cloud encoders (e.g., Point-BERT, Point-MAE) have produced powerful models, whose abilities are typically evaluated on geometric or semantic tasks. At the same time, topological descriptors have been shown to provide informative summaries of a shape's multiscale structure. In this paper we pose the question whether topological information can be derived from features produced by 3D encoders. To address this question, we first introduce DONUT, a synthetic benchmark with controlled topological complexity, and propose FILTR (Filtration Transformer), a learnable framework to predict persistence diagrams directly from frozen encoders. FILTR adapts a transformer decoder to treat diagram generation as a set prediction task. Our analysis on DONUT reveals that existing encoders retain only limited global topological signals, yet FILTR successfully leverages information produced by these encoders to approximate persistence diagrams. Our approach enables, for the first time, data-driven extraction of persistence diagrams from raw point clouds through an efficient learnable feed-forward mechanism.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DONUT, a synthetic benchmark dataset with controlled topological complexity for 3D point clouds, and FILTR (Filtration Transformer), a learnable transformer-decoder framework that treats persistence diagram prediction as a set-prediction task. It claims that pretrained 3D encoders (Point-BERT, Point-MAE) retain only limited global topological signals in their frozen features, yet FILTR can still approximate persistence diagrams from those features, enabling the first data-driven feed-forward extraction of topological descriptors directly from raw point clouds.
Significance. If the empirical claims hold with proper controls, the work would usefully connect self-supervised 3D representation learning to topological data analysis by offering a computationally efficient alternative to direct persistent-homology computation. The DONUT benchmark itself is a constructive contribution for isolating topological signal retention. The set-prediction formulation for diagrams is a reasonable technical choice that aligns with recent transformer-based set predictors.
major comments (2)
- [§5] §5 (Ablation studies): The central claim that FILTR 'successfully leverages information produced by these encoders' to approximate diagrams is not supported by any ablation that replaces the pretrained encoder with a randomly initialized network of identical architecture. Without this control experiment it is impossible to determine whether the reported performance arises from topological signals retained in the pretrained features or simply from the capacity of the transformer decoder operating on point-cloud-derived inputs.
- [§6] §6 (Generalization): All quantitative results are confined to the synthetic DONUT benchmark. No evaluation on real-world point-cloud datasets (ModelNet, ShapeNet, or noisy scans) is presented, leaving the claim that the method enables extraction 'from raw point clouds' without demonstrated transfer or robustness to realistic noise and sampling variation.
minor comments (2)
- [Abstract] Abstract: The statement that 'FILTR successfully leverages information' is presented without any numerical metrics, error statistics, or baseline comparisons; a one-sentence quantitative summary would improve readability.
- [§3] §3 (Method): The precise formulation of the set-prediction loss (Hungarian matching cost, diagram cardinality handling) should be given explicitly with an equation number rather than described at high level.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the scope and evidence needed for our claims. We address each major point below and commit to revisions that strengthen the manuscript without altering its core contributions.
read point-by-point responses
-
Referee: §5 (Ablation studies): The central claim that FILTR 'successfully leverages information produced by these encoders' to approximate diagrams is not supported by any ablation that replaces the pretrained encoder with a randomly initialized network of identical architecture. Without this control experiment it is impossible to determine whether the reported performance arises from topological signals retained in the pretrained features or simply from the capacity of the transformer decoder operating on point-cloud-derived inputs.
Authors: We agree that the requested control is necessary to isolate whether performance stems from retained topological signals in the pretrained encoders or from the decoder's general capacity. In the revised version we will add an ablation replacing the frozen pretrained encoder (Point-BERT and Point-MAE) with a randomly initialized network of identical architecture, keeping the FILTR decoder unchanged. Results on DONUT will be reported side-by-side with the original pretrained setting, allowing direct comparison of whether the limited topological signals we already observe are meaningfully exploited. revision: yes
-
Referee: §6 (Generalization): All quantitative results are confined to the synthetic DONUT benchmark. No evaluation on real-world point-cloud datasets (ModelNet, ShapeNet, or noisy scans) is presented, leaving the claim that the method enables extraction 'from raw point clouds' without demonstrated transfer or robustness to realistic noise and sampling variation.
Authors: We acknowledge that the current evaluation is restricted to the controlled synthetic DONUT benchmark. While DONUT was intentionally designed to isolate topological complexity, we agree that transfer to real-world data is required to support the broader claim of feed-forward extraction from raw point clouds. In the revision we will add quantitative results on ModelNet and ShapeNet using the same pretrained encoders and FILTR decoder, including a controlled noise-injection study on ShapeNet to assess robustness to sampling variation and sensor noise. revision: yes
Circularity Check
No circularity: empirical proposal with independent experimental validation
full rationale
The paper introduces DONUT as a synthetic benchmark and FILTR as a transformer-based predictor of persistence diagrams from frozen pretrained 3D encoders. All central claims (limited topological signal in encoders, successful approximation via FILTR) are framed as outcomes of training and evaluation on controlled data rather than as mathematical derivations, fitted parameters renamed as predictions, or results forced by self-citation chains. No equations, ansatzes, or uniqueness theorems appear in the provided text that reduce the method to its inputs by construction; the work is therefore self-contained as an empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Crosspoint: Self-supervised cross-modal contrastive learning for 3d point cloud understanding
Mohamed Afham, Isuru Dissanayake, Dinithi Dissanayake, Amaya Dharmasiri, Kanchana Thilakarathna, and Ranga Ro- drigo. Crosspoint: Self-supervised cross-modal contrastive learning for 3d point cloud understanding. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9902–9912, 2022. 2
2022
-
[2]
Statistical topological data analysis using persistence landscapes.The Journal of Machine Learning Research, 16(1):77–102, 2015
Peter Bubenik. Statistical topological data analysis using persistence landscapes.The Journal of Machine Learning Research, 16(1):77–102, 2015. 5
2015
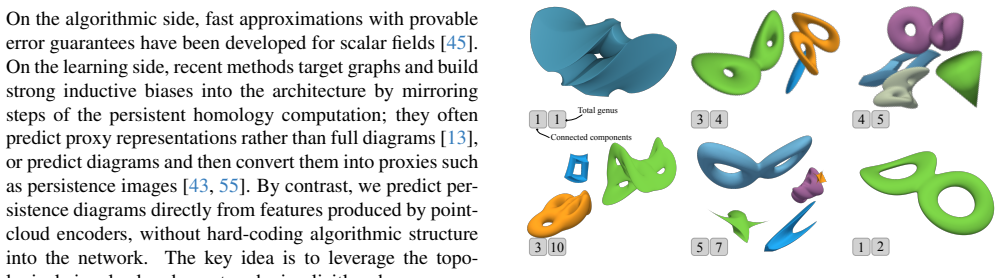
-
[3]
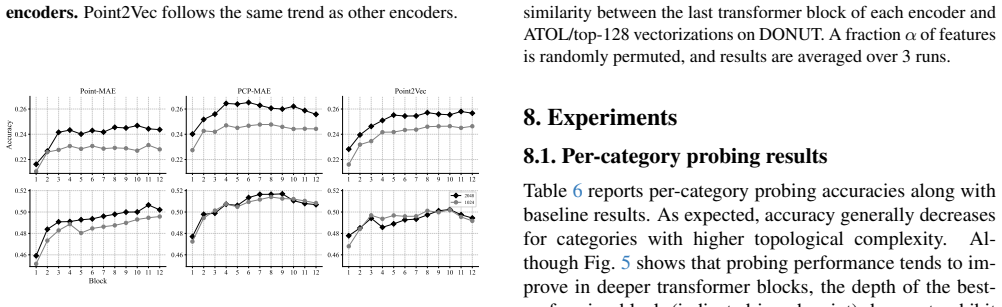
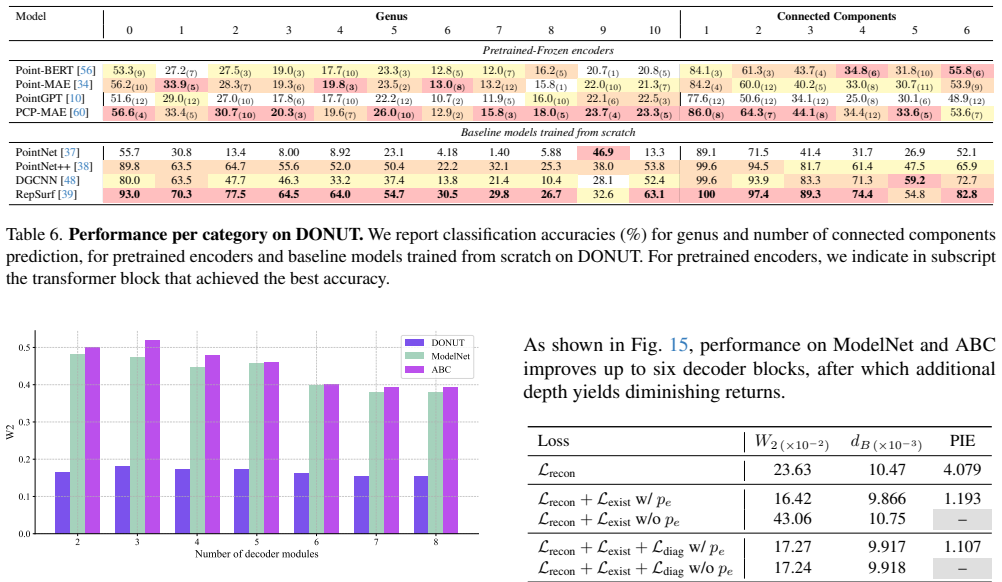
End-to- end object detection with transformers
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to- end object detection with transformers. InEuropean confer- ence on computer vision, pages 213–229. Springer, 2020. 3, 6
2020
-
[4]
Topology and data.Bulletin of the Ameri- can Mathematical Society, 46(2):255–308, 2009
Gunnar Carlsson. Topology and data.Bulletin of the Ameri- can Mathematical Society, 46(2):255–308, 2009. 2
2009
-
[5]
Persistence barcodes for shapes
Gunnar Carlsson, Afra Zomorodian, Anne Collins, and Leonidas Guibas. Persistence barcodes for shapes. InPro- ceedings of the 2004 Eurographics/ACM SIGGRAPH sym- posium on Geometry processing, pages 124–135, 2004. 2
2004
-
[6]
Sliced wasserstein kernel for persistence diagrams
Mathieu Carriere, Marco Cuturi, and Steve Oudot. Sliced wasserstein kernel for persistence diagrams. InInternational conference on machine learning, pages 664–673. PMLR,
-
[7]
Perslay: A neural network layer for persistence diagrams and new graph topo- logical signatures
Mathieu Carri `ere, Fr ´ed´eric Chazal, Yuichi Ike, Th ´eo La- combe, Martin Royer, and Yuhei Umeda. Perslay: A neural network layer for persistence diagrams and new graph topo- logical signatures. InInternational Conference on Artificial Intelligence and Statistics, pages 2786–2796. PMLR, 2020. 2, 6
2020
-
[8]
ShapeNet: An Information-Rich 3D Model Repository
Angel X Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, et al. Shapenet: An information-rich 3d model repository.arXiv preprint arXiv:1512.03012, 2015. 3, 4
work page internal anchor Pith review arXiv 2015
-
[9]
Sub- sampling methods for persistent homology
Fr ´ed´eric Chazal, Brittany Fasy, Fabrizio Lecci, Bertrand Michel, Alessandro Rinaldo, and Larry Wasserman. Sub- sampling methods for persistent homology. InInternational Conference on Machine Learning, pages 2143–2151. PMLR,
-
[10]
Pointgpt: Auto-regressively generative pre- training from point clouds.Advances in Neural Information Processing Systems, 36:29667–29679, 2023
Guangyan Chen, Meiling Wang, Yi Yang, Kai Yu, Li Yuan, and Yufeng Yue. Pointgpt: Auto-regressively generative pre- training from point clouds.Advances in Neural Information Processing Systems, 36:29667–29679, 2023. 1, 2, 4, 3, 5
2023
-
[11]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Ge- offrey Hinton. A simple framework for contrastive learning of visual representations. InInternational conference on ma- chine learning, pages 1597–1607. PmLR, 2020. 2
2020
-
[12]
Reliability of cka as a similarity measure in deep learning.arXiv preprint arXiv:2210.16156(2022)
MohammadReza Davari, Stefan Horoi, Amine Natik, Guil- laume Lajoie, Guy Wolf, and Eugene Belilovsky. Reliabil- ity of cka as a similarity measure in deep learning.arXiv preprint arXiv:2210.16156, 2022. 5
-
[13]
Ripsnet: a general architecture for fast and robust estimation of the persistent homology of point clouds
Thibault de Surrel, Felix Hensel, Mathieu Carri `ere, Th ´eo Lacombe, Yuichi Ike, Hiroaki Kurihara, Marc Glisse, and Fr´ed´eric Chazal. Ripsnet: a general architecture for fast and robust estimation of the persistent homology of point clouds. InTopological, algebraic and geometric learning workshops 2022, pages 96–106. PMLR, 2022. 3
2022
-
[14]
Bert: Pre-training of deep bidirectional trans- formers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional trans- formers for language understanding. InProceedings of the 2019 conference of the North American chapter of the asso- ciation for computational linguistics: human language tech- nologies, volume 1 (long and short papers), pages 4171– 4186, 2019. 2
2019
-
[15]
Three- dimensional alpha shapes.ACM Transactions On Graphics (TOG), 13(1):43–72, 1994
Herbert Edelsbrunner and Ernst P M ¨ucke. Three- dimensional alpha shapes.ACM Transactions On Graphics (TOG), 13(1):43–72, 1994. 5
1994
-
[16]
Confidence sets for persistence diagrams
Brittany Terese Fasy, Fabrizio Lecci, Alessandro Rinaldo, Larry Wasserman, Sivaraman Balakrishnan, and Aarti Singh. Confidence sets for persistence diagrams. 2014. 6
2014
-
[17]
Eulearn: A 3d database for learning euler characteristics.arXiv preprint arXiv:2505.13539, 2025
Rodrigo Fritz, Pablo Su ´arez-Serrato, Victor Mijangos, Anayanzi D Martinez-Hernandez, and Eduardo Ivan Ve- lazquez Richards. Eulearn: A 3d database for learning euler characteristics.arXiv preprint arXiv:2505.13539, 2025. 3
-
[18]
Clique topology reveals intrinsic geometric structure in neural correlations.Proceedings of the National Academy of Sciences, 112(44):13455–13460, 2015
Chad Giusti, Eva Pastalkova, Carina Curto, and Vladimir It- skov. Clique topology reveals intrinsic geometric structure in neural correlations.Proceedings of the National Academy of Sciences, 112(44):13455–13460, 2015. 5
2015
-
[19]
Bootstrap your own latent-a new approach to self-supervised learning.Advances in neural information processing systems, 33:21271–21284, 2020
Jean-Bastien Grill, Florian Strub, Florent Altch ´e, Corentin Tallec, Pierre Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Guo, Mohammad Ghesh- laghi Azar, et al. Bootstrap your own latent-a new approach to self-supervised learning.Advances in neural information processing systems, 33:21271–21284, 2020. 2
2020
-
[20]
Momentum contrast for unsupervised visual rep- resentation learning
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual rep- resentation learning. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 9729–9738, 2020. 2
2020
-
[21]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Doll´ar, and Ross Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000– 16009, 2022. 2
2022
-
[22]
Deep learning with topological signatures.Ad- vances in neural information processing systems, 30, 2017
Christoph Hofer, Roland Kwitt, Marc Niethammer, and An- dreas Uhl. Deep learning with topological signatures.Ad- vances in neural information processing systems, 30, 2017. 2
2017
-
[23]
Geodynamics of a global plate reorgani- zation from topological data analysis.Nature Geoscience, pages 1–7, 2025
Alexandre Janin, Nicolas Coltice, Nicolas Chamot-Rooke, and Julien Tierny. Geodynamics of a global plate reorgani- zation from topological data analysis.Nature Geoscience, pages 1–7, 2025. 2
2025
-
[24]
Point2vec for self-supervised representation learning on point clouds.arXiv e-prints, pages arXiv–2303,
Karim Knaebel, Jonas Schult, Alexander Hermans, and Bas- tian Leibe. Point2vec for self-supervised representation learning on point clouds.arXiv e-prints, pages arXiv–2303,
-
[25]
Abc: A big cad model dataset for geometric deep learning
Sebastian Koch, Albert Matveev, Zhongshi Jiang, Francis Williams, Alexey Artemov, Evgeny Burnaev, Marc Alexa, 9 Denis Zorin, and Daniele Panozzo. Abc: A big cad model dataset for geometric deep learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9601–9611, 2019. 3, 7
2019
-
[26]
Similarity of neural network represen- tations revisited
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. Similarity of neural network represen- tations revisited. InInternational conference on machine learning, pages 3519–3529. PMlR, 2019. 5
2019
-
[27]
Statistical topological data analysis-a ker- nel perspective.Advances in neural information processing systems, 28, 2015
Roland Kwitt, Stefan Huber, Marc Niethammer, Weili Lin, and Ulrich Bauer. Statistical topological data analysis-a ker- nel perspective.Advances in neural information processing systems, 28, 2015. 6
2015
-
[28]
Persistence fisher kernel: A riemannian manifold kernel for persistence diagrams.Ad- vances in neural information processing systems, 31, 2018
Tam Le and Makoto Yamada. Persistence fisher kernel: A riemannian manifold kernel for persistence diagrams.Ad- vances in neural information processing systems, 31, 2018. 2
2018
-
[29]
Set transformer: A frame- work for attention-based permutation-invariant neural net- works
Juho Lee, Yoonho Lee, Jungtaek Kim, Adam Kosiorek, Se- ungjin Choi, and Yee Whye Teh. Set transformer: A frame- work for attention-based permutation-invariant neural net- works. InInternational conference on machine learning, pages 3744–3753. PMLR, 2019. 3
2019
-
[30]
Masked dis- crimination for self-supervised learning on point clouds
Haotian Liu, Mu Cai, and Yong Jae Lee. Masked dis- crimination for self-supervised learning on point clouds. In European Conference on Computer Vision, pages 657–675. Springer, 2022. 2
2022
-
[31]
Persistent topological features of dynamical systems.Chaos: An Inter- disciplinary Journal of Nonlinear Science, 26(5), 2016
Slobodan Maleti ´c, Yi Zhao, and Milan Rajkovi ´c. Persistent topological features of dynamical systems.Chaos: An Inter- disciplinary Journal of Nonlinear Science, 26(5), 2016. 2
2016
-
[32]
An end-to- end transformer model for 3d object detection
Ishan Misra, Rohit Girdhar, and Armand Joulin. An end-to- end transformer model for 3d object detection. InProceed- ings of the IEEE/CVF international conference on computer vision, pages 2906–2917, 2021. 3
2021
-
[33]
Persistent homology analysis for materials research and per- sistent homology software: Homcloud.journal of the physi- cal society of japan, 91(9):091013, 2022
Ippei Obayashi, Takenobu Nakamura, and Yasuaki Hiraoka. Persistent homology analysis for materials research and per- sistent homology software: Homcloud.journal of the physi- cal society of japan, 91(9):091013, 2022. 2
2022
-
[34]
Masked autoencoders for 3d point cloud self- supervised learning.World Scientific Annual Review of Arti- ficial Intelligence, 1:2440001, 2023
Yatian Pang, Eng Hock Francis Tay, Li Yuan, and Zhenghua Chen. Masked autoencoders for 3d point cloud self- supervised learning.World Scientific Annual Review of Arti- ficial Intelligence, 1:2440001, 2023. 1, 2, 4, 3, 5
2023
-
[35]
Revisiting point cloud completion: Are we ready for the real-world? In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 25388–25398, 2025
Stuti Pathak, Prashant Kumar, Dheeraj Baiju, Nicholus Mboga, Gunther Steenackers, and Rudi Penne. Revisiting point cloud completion: Are we ready for the real-world? In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 25388–25398, 2025. 2
2025
-
[36]
GUDHI Editorial Board, 3.11.0 edition, 2025
The GUDHI Project.GUDHI User and Reference Manual. GUDHI Editorial Board, 3.11.0 edition, 2025. 3
2025
-
[37]
Pointnet: Deep learning on point sets for 3d classification and segmentation
Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 652–660,
-
[38]
Pointnet++: Deep hierarchical feature learning on point sets in a metric space.Advances in neural information processing systems, 30, 2017
Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space.Advances in neural information processing systems, 30, 2017. 4, 5
2017
-
[39]
Surface representa- tion for point clouds
Haoxi Ran, Jun Liu, and Chengjie Wang. Surface representa- tion for point clouds. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 18942–18952, 2022. 4, 5
2022
-
[40]
A stable multi-scale kernel for topological ma- chine learning
Jan Reininghaus, Stefan Huber, Ulrich Bauer, and Roland Kwitt. A stable multi-scale kernel for topological ma- chine learning. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 4741–4748,
-
[41]
Atol: measure vectorization for automatic topologically-oriented learning
Martin Royer, Fr ´ed´eric Chazal, Cl ´ement Levrard, Yuhei Umeda, and Yuichi Ike. Atol: measure vectorization for automatic topologically-oriented learning. InInternational conference on artificial intelligence and statistics, pages 1000–1008. PMLR, 2021. 5
2021
-
[42]
Point-jepa: A joint embedding predictive architecture for self-supervised learning on point cloud
Ayumu Saito, Prachi Kudeshia, and Jiju Poovvancheri. Point-jepa: A joint embedding predictive architecture for self-supervised learning on point cloud. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 7348–7357. IEEE, 2025. 2, 4
2025
-
[43]
Persistent homology through image segmentation (student abstract)
Joshua Slater and Thomas Weighill. Persistent homology through image segmentation (student abstract). InProceed- ings of the AAAI Conference on Artificial Intelligence, pages 16332–16333, 2023. 3
2023
-
[44]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017. 2
2017
-
[45]
Fast approximation of persis- tence diagrams with guarantees
Jules Vidal and Julien Tierny. Fast approximation of persis- tence diagrams with guarantees. In2021 IEEE 11th Sym- posium on Large Data Analysis and Visualization (LDAV), pages 1–11. IEEE, 2021. 3
2021
-
[46]
Unsupervised point cloud pre-training via oc- clusion completion
Hanchen Wang, Qi Liu, Xiangyu Yue, Joan Lasenby, and Matt J Kusner. Unsupervised point cloud pre-training via oc- clusion completion. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 9782–9792,
-
[47]
Minghua Wang, Ziyun Huang, and Jinhui Xu. Multiset trans- former: Advancing representation learning in persistence di- agrams.arXiv preprint arXiv:2411.14662, 2024. 3
-
[48]
Dynamic graph cnn for learning on point clouds.ACM Transactions on Graphics (tog), 38(5):1–12, 2019
Yue Wang, Yongbin Sun, Ziwei Liu, Sanjay E Sarma, Michael M Bronstein, and Justin M Solomon. Dynamic graph cnn for learning on point clouds.ACM Transactions on Graphics (tog), 38(5):1–12, 2019. 4, 5
2019
-
[49]
T-mae: Temporal masked autoencoders for point cloud representation learning
Weijie Wei, Fatemeh Karimi Nejadasl, Theo Gevers, and Martin R Oswald. T-mae: Temporal masked autoencoders for point cloud representation learning. InEuropean Con- ference on Computer Vision, pages 178–195. Springer, 2024. 2
2024
-
[50]
On the estimation of persistence intensity functions and linear rep- resentations of persistence diagrams
Weichen Wu, Jisu Kim, and Alessandro Rinaldo. On the estimation of persistence intensity functions and linear rep- resentations of persistence diagrams. InInternational Con- ference on Artificial Intelligence and Statistics, pages 3610–
-
[51]
Point transformer v3: Simpler faster stronger
Xiaoyang Wu, Li Jiang, Peng-Shuai Wang, Zhijian Liu, Xi- hui Liu, Yu Qiao, Wanli Ouyang, Tong He, and Hengshuang Zhao. Point transformer v3: Simpler faster stronger. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4840–4851, 2024. 1 10
2024
-
[52]
3d shapenets: A deep representation for volumetric shapes
Zhirong Wu, Shuran Song, Aditya Khosla, Fisher Yu, Lin- guang Zhang, Xiaoou Tang, and Jianxiong Xiao. 3d shapenets: A deep representation for volumetric shapes. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1912–1920, 2015. 3, 7
1912
-
[53]
Persistent homology analysis of protein structure, flexibility, and folding.International journal for numerical methods in biomedical engineering, 30(8):814–844, 2014
Kelin Xia and Guo-Wei Wei. Persistent homology analysis of protein structure, flexibility, and folding.International journal for numerical methods in biomedical engineering, 30(8):814–844, 2014. 2
2014
-
[54]
Pointcontrast: Unsupervised pre- training for 3d point cloud understanding
Saining Xie, Jiatao Gu, Demi Guo, Charles R Qi, Leonidas Guibas, and Or Litany. Pointcontrast: Unsupervised pre- training for 3d point cloud understanding. InEuropean con- ference on computer vision, pages 574–591. Springer, 2020. 2
2020
-
[55]
Neural approximation of graph topo- logical features.Advances in neural information processing systems, 35:33357–33370, 2022
Zuoyu Yan, Tengfei Ma, Liangcai Gao, Zhi Tang, Yusu Wang, and Chao Chen. Neural approximation of graph topo- logical features.Advances in neural information processing systems, 35:33357–33370, 2022. 3, 6, 7
2022
-
[56]
Point-bert: Pre-training 3d point cloud transformers with masked point modeling
Xumin Yu, Lulu Tang, Yongming Rao, Tiejun Huang, Jie Zhou, and Jiwen Lu. Point-bert: Pre-training 3d point cloud transformers with masked point modeling. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19313–19322, 2022. 1, 2, 4, 3, 5
2022
-
[57]
Deep sets.Advances in neural information processing sys- tems, 30, 2017
Manzil Zaheer, Satwik Kottur, Siamak Ravanbakhsh, Barn- abas Poczos, Russ R Salakhutdinov, and Alexander J Smola. Deep sets.Advances in neural information processing sys- tems, 30, 2017. 3
2017
-
[58]
Point-m2ae: multi-scale masked autoencoders for hierarchical point cloud pre-training.Advances in neural information processing sys- tems, 35:27061–27074, 2022
Renrui Zhang, Ziyu Guo, Peng Gao, Rongyao Fang, Bin Zhao, Dong Wang, Yu Qiao, and Hongsheng Li. Point-m2ae: multi-scale masked autoencoders for hierarchical point cloud pre-training.Advances in neural information processing sys- tems, 35:27061–27074, 2022. 2
2022
-
[59]
Simon Zhang, Mengbai Xiao, and Hao Wang. Gpu- accelerated computation of vietoris-rips persistence bar- codes.arXiv preprint arXiv:2003.07989, 2020. 5
-
[60]
Pcp- mae: Learning to predict centers for point masked autoen- coders.Advances in Neural Information Processing Systems, 37:80303–80327, 2024
Xiangdong Zhang, Shaofeng Zhang, and Junchi Yan. Pcp- mae: Learning to predict centers for point masked autoen- coders.Advances in Neural Information Processing Systems, 37:80303–80327, 2024. 4, 3, 5
2024
-
[61]
Deep set prediction networks.Advances in Neural Information Processing Systems, 32, 2019
Yan Zhang, Jonathon Hare, and Adam Prugel-Bennett. Deep set prediction networks.Advances in Neural Information Processing Systems, 32, 2019. 3
2019
-
[62]
Qingnan Zhou and Alec Jacobson. Thingi10k: A dataset of 10,000 3d-printing models.arXiv preprint arXiv:1605.04797, 2016. 3 11 FILTR: Extracting Topological Features from Pretrained 3D Models Supplementary Material We provide implementation details, including the cre- ation of DONUT (Sec. 6.1) and the architecture of FILTR and baselines (Sec. 6.3) along wi...
-
[63]
Creation of DONUT The primary goal in constructing DONUT is to obtain re- liable and balanced topological annotations
Implementation details 6.1. Creation of DONUT The primary goal in constructing DONUT is to obtain re- liable and balanced topological annotations. The genera- tion pipeline (Fig. 9) therefore first samples valid global la- bels, then distributes them across components, and finally produces geometrically diverse meshes consistent with the prescribed topolo...
-
[64]
latent prediction pretraining In this work, we focus on encoders pretrained with a 3D re- construction objective
3D vs. latent prediction pretraining In this work, we focus on encoders pretrained with a 3D re- construction objective. This choice is motivated by the ge- ometric guarantees naturally provided by optimizing spatial reconstruction metrics. 7.1. Theoretical justification LetXand ˆX∈R N×3 be the ground-truth and recon- structed point clouds. 3D-prediction ...
2048
-
[65]
Per-category probing results Table 6 reports per-category probing accuracies along with baseline results
Experiments 8.1. Per-category probing results Table 6 reports per-category probing accuracies along with baseline results. As expected, accuracy generally decreases for categories with higher topological complexity. Al- though Fig. 5 shows that probing performance tends to im- prove in deeper transformer blocks, the depth of the best- performing block (in...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.