Recognition: unknown
Selective Contrastive Learning For Gloss Free Sign Language Translation
Pith reviewed 2026-05-08 11:38 UTC · model grok-4.3
The pith
Selective contrastive learning improves gloss-free sign language translation by dynamically selecting informative negatives based on their similarity trajectories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
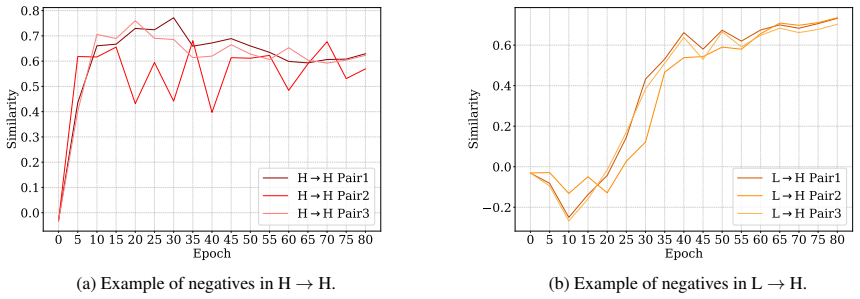
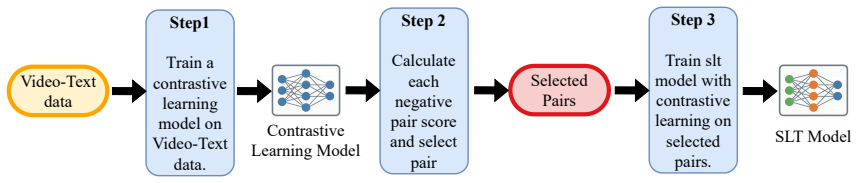
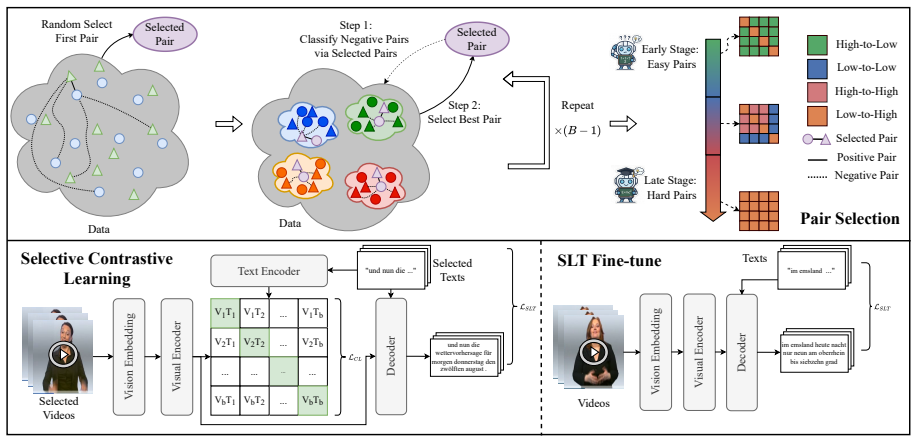
In gloss-free sign language translation, random in-batch contrastive negatives frequently fail to provide effective supervision because most display heterogeneous and non-decreasing similarity dynamics over training. By scoring candidate negatives according to similarity trajectories observed from reference checkpoints and constructing mini-batches via a curriculum that progressively emphasizes more challenging negatives, selective contrastive learning strengthens cross-modal alignment while reducing the impact of noisy or semantically invalid pairs.
What carries the argument
The Pair Selection (PS) strategy that scores negatives by their similarity dynamics from reference checkpoints and builds curriculum-based mini-batches to emphasize progressively harder negatives.
If this is right
- Contrastive supervision becomes stronger because only negatives with consistent repulsion trajectories are retained in batches.
- The influence of noisy or semantically invalid negatives is reduced through the dynamic scoring and curriculum.
- Cross-modal alignment between sign videos and text improves as training focuses on genuinely difficult negatives.
- The method can be integrated into existing CLIP-like vision-language pretraining pipelines for SLT without changing the overall architecture.
Where Pith is reading between the lines
- The trajectory analysis technique could be applied to diagnose contrastive learning problems in other video-text tasks beyond sign language.
- A fully online version of the selection process without separate reference checkpoints might reduce computational overhead while preserving gains.
- The curriculum ordering may interact with other training schedules such as learning rate decay in ways that could be tuned for further gains.
Load-bearing premise
Similarity dynamics observed from reference checkpoints can reliably identify informative and valid negatives without introducing selection bias or overlooking semantically similar pairs that should stay as negatives.
What would settle it
If retraining with the proposed pair selection yields no improvement in translation metrics on standard gloss-free benchmarks such as RWTH-PHOENIX-Weather 2014T compared to random in-batch negatives, the central claim would be falsified.
Figures



read the original abstract
Sign language translation (SLT) converts continuous sign videos into spoken-language text, yet it remains challenging due to the intrinsic modality mismatch between visual signs and written text, particularly in gloss-free settings. Recent SLT systems increasingly adopt CLIP-like Vision-Language pretraining (VLP) for cross-modal alignment, but the random in-batch contrast provides few, batch-dependent negatives and may mislabel semantically similar (or even identical) pairs as negatives, introducing noisy and potentially inconsistent alignment supervision. In this work, we first conduct a preliminary trajectory-based analysis that tracks negative video-text similarity over training. The results show that only a small subset of negatives exhibits the desired behavior of being consistently pushed away, while the remaining negatives display heterogeneous and often non-decreasing similarity dynamics, suggesting that random in-batch negatives are frequently uninformative for effective alignment. Inspired by this, we propose Selective Contrastive Learning for SLT (SCL-SLT) with a Pair Selection (PS) strategy. PS scores candidate negatives using similarity dynamics from reference checkpoints and constructs mini-batches via a curriculum that progressively emphasizes more challenging negatives, thereby strengthening contrastive supervision while reducing the influence of noisy or semantically invalid negatives.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Selective Contrastive Learning for Gloss-Free Sign Language Translation (SCL-SLT) using a Pair Selection (PS) strategy. PS scores candidate negatives via similarity dynamics observed at reference checkpoints during training and applies a curriculum to progressively emphasize harder negatives, aiming to strengthen cross-modal alignment in CLIP-like VLP for SLT while mitigating noisy or semantically invalid in-batch negatives identified through preliminary trajectory analysis.
Significance. If empirically validated, the approach could improve negative sampling in contrastive vision-language pretraining for sign language translation by leveraging observed similarity trajectories, potentially yielding more robust cross-modal representations than standard random in-batch negatives. The preliminary analysis offers a grounded empirical motivation, but the absence of any quantitative results, ablations, or implementation details prevents assessment of practical impact or superiority over baselines.
major comments (2)
- [Abstract] Abstract: the central claim that PS strengthens supervision by reducing noisy negatives rests on the unvalidated assumption that similarity dynamics from same-run reference checkpoints correlate with true semantic invalidity rather than model-internal representation changes; no independent validation (e.g., human semantic judgments or external metrics) is provided to rule out selection bias.
- [Abstract] Abstract: the preliminary trajectory-based analysis is invoked to motivate the method but supplies no quantitative details, figures, statistics, or dataset specifics on the fraction of negatives showing non-decreasing similarity or the exact checkpoint selection protocol, leaving the empirical foundation for PS unsupported.
minor comments (2)
- [Abstract] Abstract: the acronym SCL-SLT is defined on first use but the full expansion 'Selective Contrastive Learning for SLT' could be stated explicitly for clarity.
- [Abstract] Abstract: implementation specifics such as how reference checkpoints are chosen, the exact scoring formula for dynamics, curriculum schedule, or loss formulation are omitted, hindering reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point-by-point below, providing clarifications and indicating revisions where the concerns are valid and can be addressed without new experiments.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that PS strengthens supervision by reducing noisy negatives rests on the unvalidated assumption that similarity dynamics from same-run reference checkpoints correlate with true semantic invalidity rather than model-internal representation changes; no independent validation (e.g., human semantic judgments or external metrics) is provided to rule out selection bias.
Authors: We acknowledge that our preliminary analysis relies on intra-run similarity trajectories without external corroboration such as human semantic judgments. The Pair Selection strategy uses these dynamics as a practical proxy to downweight negatives that fail to be contrasted away, based on the empirical observation that random in-batch negatives often exhibit non-decreasing similarity. We agree this leaves open the possibility of model-internal effects rather than true semantic invalidity. In the revised manuscript we have added an explicit discussion of this assumption and its limitations in Section 3.1, but we do not introduce new validation experiments as they fall outside the current scope. revision: partial
-
Referee: [Abstract] Abstract: the preliminary trajectory-based analysis is invoked to motivate the method but supplies no quantitative details, figures, statistics, or dataset specifics on the fraction of negatives showing non-decreasing similarity or the exact checkpoint selection protocol, leaving the empirical foundation for PS unsupported.
Authors: The referee is correct that the abstract omitted quantitative details. The full manuscript presents the trajectory analysis in Section 3.1, including figures, dataset information (PHOENIX14T), and the checkpoint protocol. We have revised the abstract to summarize the key statistics on the fraction of negatives with non-decreasing similarity and to specify the reference checkpoint selection procedure, thereby better grounding the motivation for the Pair Selection strategy. revision: yes
Circularity Check
No significant circularity; empirical heuristic grounded in observed training dynamics
full rationale
The paper's central contribution is an empirical trajectory analysis of negative similarities during training, followed by a heuristic Pair Selection strategy that scores negatives using reference checkpoint dynamics and applies a curriculum. No equations, derivations, or first-principles claims are presented that reduce to fitted parameters, self-definitions, or self-citation chains by construction. The method is explicitly described as inspired by preliminary observations rather than a closed mathematical loop, and the provided abstract and description contain no load-bearing self-citations or renamed known results that would trigger circularity under the specified criteria.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Similarity dynamics from reference checkpoints reliably distinguish informative negatives from noisy or invalid ones for contrastive alignment in SLT.
Reference graph
Works this paper leans on
-
[1]
Neural Machine Translation by Jointly Learning to Align and Translate
Neural machine translation by jointly learning to align and translate.arXiv preprint arXiv:1409.0473. Yoshua Bengio, Jérôme Louradour, Ronan Collobert, and Jason Weston
work page internal anchor Pith review arXiv
-
[2]
arXiv preprint arXiv:2307.08701 , year=
Alpagasus: Training a better alpaca with fewer data. arXiv preprint arXiv:2307.08701. Yutong Chen, Fangyun Wei, Xiao Sun, Zhirong Wu, and Stephen Lin
-
[3]
Yiting Cheng, Fangyun Wei, Jianmin Bao, Dong Chen, and Wenqiang Zhang
Factorized learning assisted with large language model for gloss-free sign language translation.arXiv preprint arXiv:2403.12556. Yiting Cheng, Fangyun Wei, Jianmin Bao, Dong Chen, and Wenqiang Zhang
-
[4]
InFindings of the Association for Computational Linguistics: NAACL 2024, pages 2182–2193, Mexico City, Mex- ico
Signer diversity-driven data augmentation for signer- independent sign language translation. InFindings of the Association for Computational Linguistics: NAACL 2024, pages 2182–2193, Mexico City, Mex- ico. Association for Computational Linguistics. Jia Gong, Lin Geng Foo, Yixuan He, Hossein Rahmani, and Jun Liu
2024
-
[5]
An efficient gloss-free sign lan- guage translation using spatial configurations and mo- tion dynamics with llms. InProceedings of the 2025 Conference of the Nations of the Americas Chap- ter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Pa- pers), pages 3901–3920. Jungeun Kim, Hyeongwoo Jeon, Jongseong Bae,...
2025
-
[6]
Llava-slt: Visual language tun- ing for sign language translation.arXiv preprint arXiv:2412.16524. Chin-Yew Lin
-
[7]
Rho-1: Not all tokens are what you need.arXiv preprint arXiv:2404.07965. Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, and Luke Zettlemoyer
-
[8]
SGDR: Stochastic Gradient Descent with Warm Restarts
Sgdr: Stochas- tic gradient descent with warm restarts.arXiv preprint arXiv:1608.03983. Ilya Loshchilov and Frank Hutter
work page internal anchor Pith review arXiv
-
[9]
Decoupled Weight Decay Regularization
Decou- pled weight decay regularization.arXiv preprint arXiv:1711.05101. Minh-Thang Luong, Hieu Pham, and Christopher D Manning
work page internal anchor Pith review arXiv
-
[10]
Effective approaches to attention- based neural machine translation.arXiv preprint arXiv:1508.04025. Kishore Papineni, Salim Roukos, Todd Ward, and Wei- Jing Zhu
-
[11]
Multilingual translation with exten- sible multilingual pretraining and finetuning.arXiv preprint arXiv:2008.00401. Ryan Wong, Necati Cihan Camgoz, and Richard Bow- den
-
[12]
arXiv preprint arXiv:2405.04164
Sign2gpt: Leveraging large language models for gloss-free sign language translation. arXiv preprint arXiv:2405.04164. Mengzhou Xia, Sadhika Malladi, Suchin Gururangan, Sanjeev Arora, and Danqi Chen
-
[13]
arXiv preprint arXiv:2402.04333 , year=
Less: Se- lecting influential data for targeted instruction tuning. arXiv preprint arXiv:2402.04333. Jinhui Ye, Xing Wang, Wenxiang Jiao, Junwei Liang, and Hui Xiong
-
[14]
InFindings of the Association for Com- putational Linguistics: NAACL 2025, pages 6227– 6239, Albuquerque, New Mexico
Dynamic feature fusion for sign language translation using hy- pernetworks. InFindings of the Association for Com- putational Linguistics: NAACL 2025, pages 6227– 6239, Albuquerque, New Mexico. Association for Computational Linguistics. Rui Zhao, Liang Zhang, Biao Fu, Cong Hu, Jinsong Su, and Yidong Chen
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.