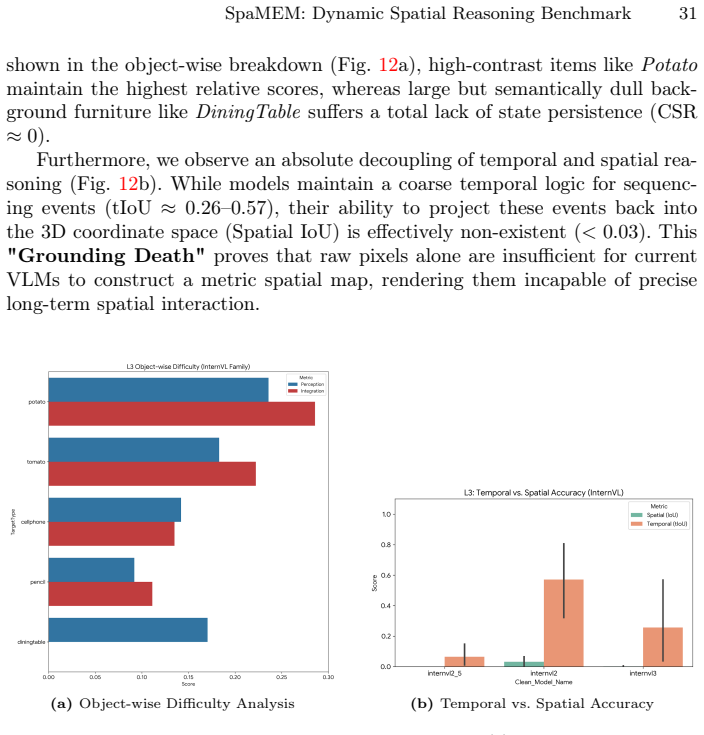
Recognition: unknown
SpaMEM: Benchmarking Dynamic Spatial Reasoning via Perception-Memory Integration in Embodied Environments
Pith reviewed 2026-05-08 12:29 UTC · model grok-4.3
The pith
Vision-language models maintain spatial beliefs only when given text histories and collapse without them in changing environments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SpaMEM formalizes embodied spatial reasoning as a three-level hierarchy over action-conditioned transformations. Level 1 measures atomic perception, Level 2 adds oracle textual histories to remove perceptual noise, and Level 3 demands belief maintenance from raw RGB, depth, and segmentation streams under identical task dimensions. Evaluations across open-source VLM families identify a stacked bottleneck: coordinate-consistent grounding remains difficult, and performance collapses from Level 2 to Level 3, indicating that models succeed via text-based bookkeeping but cannot sustain robust visual memory.
What carries the argument
The three-level task hierarchy (atomic perception, oracle-text temporal reasoning, and raw-visual end-to-end belief maintenance) that isolates perception-memory integration across spawn-place-remove action sequences.
Load-bearing premise
The procedurally generated houses, action sequences, and task levels isolate genuine spatial belief evolution without introducing simulation artifacts that would not appear in physical settings.
What would settle it
Deploy the identical Level-3 tasks on a physical robot that performs the same spawn-place-remove actions in a real room and measure whether spatial reconstruction accuracy matches or exceeds the simulated Level-3 scores.
Figures











read the original abstract
Multimodal large language models (MLLMs) have advanced static visual--spatial reasoning, yet they often fail to preserve long-horizon spatial coherence in embodied settings where beliefs must be continuously revised from egocentric observations under environmental change. We introduce SpaMEM (Spatial Memory from Action Sequences), a large-scale diagnostic benchmark that isolates the mechanics of spatial belief evolution via action-conditioned scene transformations (spawn, place, remove) over long interaction horizons. SpaMEM is built on a physically grounded dataset with 10,601,392 high-fidelity images across four modalities (RGB, depth, instance, semantic segmentation), collected from 25,000+ interaction sequences in 1,000 procedurally generated houses. We formalize embodied spatial reasoning as a three-level hierarchy with 15 diagnostic tasks: Level 1 measures atomic spatial perception from single observations; Level 2 probes temporal reasoning with oracle textual state histories to factor out perceptual noise; and Level 3 requires end-to-end belief maintenance from raw visual streams under the same task dimensions. We further evaluate both short-term (step-wise) updates and long-term (episodic) reconstruction. Benchmarking representative open-source VLM families reveals a consistent stacked bottleneck: coordinate-consistent grounding remains a hard ceiling, and the sharp collapse from Level 2 to Level 3 exposes a pronounced symbolic scaffolding dependency, where models succeed with text-based bookkeeping but struggle to sustain robust visual memory. SpaMEM provides a granular diagnostic standard and motivates explicit mechanisms for state representation, belief revision, and long-horizon episodic integration.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SpaMEM, a large-scale benchmark for dynamic spatial reasoning in embodied environments. It consists of 10,601,392 images across RGB, depth, instance, and semantic modalities collected from 1,000 procedurally generated houses and over 25,000 interaction sequences using spawn, place, and remove actions. The benchmark defines a three-level task hierarchy with 15 diagnostic tasks: Level 1 for atomic spatial perception from single observations, Level 2 for temporal reasoning using oracle textual state histories, and Level 3 for end-to-end belief maintenance from raw visual streams. Evaluations of open-source VLM families show consistent performance collapse from Level 2 to Level 3, which the authors attribute to a symbolic scaffolding dependency where models rely on text-based bookkeeping but fail to sustain visual memory.
Significance. If the central claims hold after addressing potential confounds, the work is significant as a granular diagnostic benchmark that quantifies limitations in current VLMs for long-horizon spatial coherence and belief revision under environmental change. The dataset scale (over 10 million images from 1,000 houses) and structured hierarchy provide a reproducible standard that can drive progress on state representation, belief revision, and episodic integration mechanisms. This is a clear strength for the embodied AI and multimodal reasoning community.
major comments (3)
- [Abstract] The abstract's claim that the sharp collapse from Level 2 to Level 3 'exposes a pronounced symbolic scaffolding dependency' is load-bearing for the main conclusion. However, this attribution assumes the only relevant difference between oracle text and raw visuals is perceptual noise, without controls or analysis to rule out that procedural simulation properties (perfectly consistent lighting, discrete object placements, absence of naturalistic sensor noise) systematically increase visual state-tracking difficulty independently of memory mechanisms.
- [§4 (Benchmarking Results)] The performance claims of a 'consistent stacked bottleneck' and 'hard ceiling' on coordinate-consistent grounding (abstract and §4) are not accompanied by error bars, statistical significance tests, or variance analysis across the 1,000 houses and 25,000+ sequences. This weakens support for the cross-level and cross-model generalizations.
- [§3 (Benchmark Construction)] The three-level hierarchy is presented as cleanly isolating spatial belief evolution, but §3 does not provide explicit verification that the fixed action set and procedural house generation do not introduce task-specific biases or simulation artifacts that affect Level 3 more than Level 2 beyond the intended perceptual noise factor.
minor comments (3)
- [Abstract] The abstract reports '25,000+' sequences but gives an exact image count; ensure numerical consistency and precise reporting of sequence counts in the main text and tables.
- A summary table listing all 15 diagnostic tasks with their level, input type (text vs. visual), and evaluation metric would improve clarity of the task hierarchy.
- [Figures] Figure captions describing the modalities and example action sequences could be expanded for readers unfamiliar with the simulation setup.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major comment below with clarifications and commitments to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract] The abstract's claim that the sharp collapse from Level 2 to Level 3 'exposes a pronounced symbolic scaffolding dependency' is load-bearing for the main conclusion. However, this attribution assumes the only relevant difference between oracle text and raw visuals is perceptual noise, without controls or analysis to rule out that procedural simulation properties (perfectly consistent lighting, discrete object placements, absence of naturalistic sensor noise) systematically increase visual state-tracking difficulty independently of memory mechanisms.
Authors: We appreciate this observation on the attribution. The benchmark design holds the environment, actions, house generation, and task definitions fixed across levels, with the sole controlled difference being the input (oracle text histories in Level 2 versus raw visual streams in Level 3). This isolates the visual memory component. The idealized simulation is a deliberate choice to diagnose reasoning failures without sensor confounds, consistent with standard embodied AI benchmarks. In revision we will expand the abstract and add a dedicated paragraph in §4 (and a limitations subsection) explicitly discussing this design rationale and noting that future extensions could incorporate naturalistic noise. revision: partial
-
Referee: [§4 (Benchmarking Results)] The performance claims of a 'consistent stacked bottleneck' and 'hard ceiling' on coordinate-consistent grounding (abstract and §4) are not accompanied by error bars, statistical significance tests, or variance analysis across the 1,000 houses and 25,000+ sequences. This weakens support for the cross-level and cross-model generalizations.
Authors: We agree that quantitative rigor requires statistical support. In the revised manuscript we will augment all tables and figures in §4 with error bars (standard deviation computed across the 1,000 houses and 25,000+ sequences) and include paired t-test results (with p-values) comparing performance across levels and models to substantiate the reported bottlenecks and generalizations. revision: yes
-
Referee: [§3 (Benchmark Construction)] The three-level hierarchy is presented as cleanly isolating spatial belief evolution, but §3 does not provide explicit verification that the fixed action set and procedural house generation do not introduce task-specific biases or simulation artifacts that affect Level 3 more than Level 2 beyond the intended perceptual noise factor.
Authors: We thank the referee for this point on verification. Section 3 already specifies that the action vocabulary, procedural house generator, and 15 task dimensions are identical across levels. To make this explicit, we will insert a new verification subsection in §3 that (a) confirms instance-level matching of tasks between levels, (b) reports per-house variance statistics demonstrating consistency, and (c) includes qualitative examples illustrating that any simulation artifacts are shared and do not differentially impact Level 3. These additions will be supported by supplementary per-house breakdowns. revision: partial
Circularity Check
No circularity: pure empirical benchmark with direct evaluations
full rationale
The paper introduces a new benchmark (SpaMEM) with procedurally generated data, defines a three-level task hierarchy, and reports model performance on direct evaluations across modalities and horizons. No derivations, equations, fitted parameters, or predictions appear; claims about bottlenecks and scaffolding dependency are interpretive summaries of observed results rather than reductions to self-defined inputs or self-citations. The work is self-contained as an empirical diagnostic standard without load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Embodied spatial reasoning can be formalized as a three-level hierarchy that isolates atomic perception, temporal reasoning with oracle textual histories, and end-to-end belief maintenance from raw visual streams.
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE International Conference on Computer Vision (ICCV) (2015) 20
Antol, S., et al.: Vqa: Visual question answering. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV) (2015) 20
2015
-
[2]
arXiv preprint arXiv:2512.02458 (2025),https://arxiv.org/abs/2512.024582, 4, 20
Cai, Z., Du, Y., Wang, C., Kong, Y.: Vision to geometry: 3d spatial memory for sequential embodied mllm reasoning and exploration. arXiv preprint arXiv:2512.02458 (2025),https://arxiv.org/abs/2512.024582, 4, 20
-
[3]
arXiv preprint arXiv:1902.01385 (2020), https://arxiv.org/abs/1902.01385, iJCAI 2020 3
Chaplot, D.S., Lee, L., Salakhutdinov, R., Parikh, D., Batra, D.: Embod- ied multimodal multitask learning. arXiv preprint arXiv:1902.01385 (2020), https://arxiv.org/abs/1902.01385, iJCAI 2020 3
-
[4]
How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites
Chen, Z., Wang, J., Cao, Z., Liu, M., et al.: How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites. arXiv preprint arXiv:2404.16821 (2024),https://arxiv.org/abs/2404.168218
work page internal anchor Pith review arXiv 2024
-
[5]
Chen, Z., Wang, J., Cao, Z., et al.: Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling. arXiv preprint arXiv:2412.05271 (2024),https://arxiv.org/abs/2412. 052718, 9
work page internal anchor Pith review arXiv 2024
-
[6]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Chen, Z., Wang, J., Cao, Z., et al.: Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models. arXiv preprint arXiv:2504.10479 (2025),https://arxiv.org/abs/2504.104798, 9, 10, 11
work page internal anchor Pith review arXiv 2025
-
[7]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2018) 3
Das, A., Datta, S., Gkioxari, G., Lee, S., Parikh, D., Batra, D.: Embodied question answering. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2018) 3
2018
-
[8]
arXiv preprint arXiv:1810.11181 (2018), https://arxiv.org/abs/1810.111813
Das, A., Gkioxari, G., Lee, S., Parikh, D., Batra, D.: Neural modular control for embodied question answering. arXiv preprint arXiv:1810.11181 (2018), https://arxiv.org/abs/1810.111813
-
[9]
arXiv preprint arXiv:2004.06799 (2020),https://arxiv.org/abs/ 2004.067993
Deitke, M., et al.: Robothor: An open simulation-to-real embodied ai plat- form. arXiv preprint arXiv:2004.06799 (2020),https://arxiv.org/abs/ 2004.067993
-
[10]
Deitke, M., et al.: Procthor: Large-scale embodied ai using procedural gen- eration. In: Advances in Neural Information Processing Systems (NeurIPS) (2022),https://proceedings.neurips.cc/paper_files/paper/2022/ hash/27c546ab1e4f1d7d638e6a8dfbad9a07-Abstract-Conference.html 3, 20
2022
-
[11]
arXiv preprint arXiv:2509.23690 (2025),https://arxiv
Gao, S., Yao, J., Wen, H., Guo, Y., Liu, Z., Huang, H.: Homesafebench: A benchmark for embodied vision-language models in free-exploration home safety inspection. arXiv preprint arXiv:2509.23690 (2025),https://arxiv. org/abs/2509.236903
-
[12]
arXiv preprint arXiv:2305.06178 (2023),https://arxiv.org/abs/2305.061784
Gireesh, N., Agrawal, A., Datta, A., Banerjee, S., Sridharan, M., Bhowmick, B., Krishna, M.: Sequence-agnostic multi-object navigation. arXiv preprint arXiv:2305.06178 (2023),https://arxiv.org/abs/2305.061784
-
[13]
AI2-THOR: An Interactive 3D Environment for Visual AI
Kolve, E., et al.: Ai2-thor: An interactive 3d environment for visual ai. arXiv preprint arXiv:1712.05474 (2017),https://arxiv.org/abs/1712.054743 SpaMEM: Dynamic Spatial Reasoning Benchmark 17
work page internal anchor Pith review arXiv 2017
-
[14]
TVQA: Localized, Compositional Video Question Answering
Lei, J., et al.: Tvqa: Localized, compositional video question answering. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) (2018),https://arxiv.org/abs/1809.0169620
work page Pith review arXiv 2018
-
[15]
LLaVA-OneVision: Easy Visual Task Transfer
Li, B., et al.: Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326 (2024),https://arxiv.org/abs/2408.033268
work page internal anchor Pith review arXiv 2024
-
[16]
igibson 2.0: Object-centric simulation for robot learning of everyday household tasks
Li, C., et al.: igibson 2.0: Object-centric simulation for robot learning of everyday household tasks. arXiv preprint arXiv:2108.03272 (2021),https: //arxiv.org/abs/2108.032723
-
[17]
Egocentric prediction of action target in 3d, 2022
Li,Y.,Cao,Z.,Liang,A.,Liang,B.,Chen,L.,Zhao,H.,Feng,C.:Egocentric prediction of action target in 3d. arXiv preprint arXiv:2203.13116 (2022), https://arxiv.org/abs/2203.131164
-
[18]
Li, Y., et al.: Viewspatial-bench: Evaluating multi-perspective spatial local- ization in vision-language models. arXiv preprint arXiv:2505.21500 (2025), https://arxiv.org/abs/2505.215004
-
[19]
Liu, H., Li, C., Li, Y., et al.: Llava-next: Stronger llms supercharge multi- modal capabilities in the wild.https://llava-vl.github.io/blog/2024- 01-30-llava-next/(2024) 8
2024
-
[20]
arXiv preprint arXiv:2410.15589 (2024), https://arxiv.org/abs/2410.155893
Liu, J., et al.: Explore with long-term memory: Brain-inspired multi-agent memory for embodied exploration. arXiv preprint arXiv:2410.15589 (2024), https://arxiv.org/abs/2410.155893
-
[21]
Transactions of the Association for Computational Linguistics (2024) 3
Liu, N.F., et al.: Lost in the middle: How language models use long contexts. Transactions of the Association for Computational Linguistics (2024) 3
2024
-
[22]
Hoi4d: A 4d egocentric dataset for category-level human-object interaction, 2024
Liu, Y., Liu, Y., Jiang, C., Lyu, K., Wan, W., Shen, H., Liang, B., Fu, Z., Wang, H., Yi, L.: Hoi4d: A 4d egocentric dataset for category- level human-object interaction. arXiv preprint arXiv:2203.01577 (2022), https://arxiv.org/abs/2203.015774
- [23]
-
[24]
arXiv preprint arXiv:2212.06969 (2022),https://arxiv.org/abs/2212.069694
Mai, J., Hamdi, A., Giancola, S., Zhao, C., Ghanem, B.: Egoloc: Revisit- ing 3d object localization from egocentric videos with visual queries. arXiv preprint arXiv:2212.06969 (2022),https://arxiv.org/abs/2212.069694
-
[25]
arXiv preprint arXiv:2505.24257 (2025), https://arxiv.org/abs/2505.242574
Ravi, N., et al.: Out of sight, not out of context? egocentric spatial reason- ing in vlms across disjoint frames. arXiv preprint arXiv:2505.24257 (2025), https://arxiv.org/abs/2505.242574
-
[26]
arXiv preprint arXiv:2304.03696 (2023),https://arxiv.org/abs/2304.036964
Raychaudhuri, S., Campari, T., Jain, U., Savva, M., Chang, A.X.: Re- duce, reuse, recycle: Modular multi-object navigation. arXiv preprint arXiv:2304.03696 (2023),https://arxiv.org/abs/2304.036964
-
[27]
Habitat: A platform for embodied ai research
Savva, M., et al.: Habitat: A platform for embodied ai research. In: Pro- ceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2019),https://arxiv.org/abs/1904.01201, arXiv:1904.01201 3
-
[28]
arXiv preprint arXiv:2012.02924 (2020),https: //arxiv.org/abs/2012.029243
Shen, B., et al.: igibson 1.0: A simulation environment for interactive tasks in large realistic scenes. arXiv preprint arXiv:2012.02924 (2020),https: //arxiv.org/abs/2012.029243
-
[29]
Maniskill-hab: A benchmark for low-level manipulation in home rearrangement tasks,
Shukla, A., Tao, S., Su, H.: Maniskill-hab: A benchmark for low-level ma- nipulation in home rearrangement tasks. arXiv preprint arXiv:2412.13211 (2024),https://arxiv.org/abs/2412.132113 18 Liao et al
-
[30]
Team,Q.:Qwen2.5-vltechnicalreport.https://qwenlm.github.io/blog/ qwen2.5-vl/(2025) 8
2025
-
[31]
Team, Q.: Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025),https://arxiv.org/abs/2511.216318, 9, 10, 11
work page internal anchor Pith review arXiv 2025
-
[32]
arXiv preprint arXiv:2512.00736 (2025),https://arxiv.org/abs/2512.007363, 4
Thompson, J., Garcia-Lopez, E., Bisk, Y.: Rem: Evaluating llm em- bodied spatial reasoning through multi-frame trajectories. arXiv preprint arXiv:2512.00736 (2025),https://arxiv.org/abs/2512.007363, 4
-
[33]
arXiv preprint arXiv:2206.13396 (2022),https://arxiv
Trabucco, B., Sigurdsson, G., Piramuthu, R., Sukhatme, G.S., Salakhut- dinov, R.: A simple approach for visual rearrangement: 3d mapping and semantic search. arXiv preprint arXiv:2206.13396 (2022),https://arxiv. org/abs/2206.133963
-
[34]
arXiv preprint arXiv:2602.07082 (2026),https://arxiv.org/ abs/2602.070824
Wang, H., Xue, Q., Liu, W., Gao, W.: Mosaicthinker: On-device visual spatial reasoning for embodied ai via iterative construction of space rep- resentation. arXiv preprint arXiv:2602.07082 (2026),https://arxiv.org/ abs/2602.070824
-
[35]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Wang, P., Bai, S., Tan, S., et al.: Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191 (2024),https://arxiv.org/abs/2409.121918
work page internal anchor Pith review arXiv 2024
-
[36]
Wani, S., Patel, S., Jain, U., Chang, A.X., Savva, M.: Multion: Bench- marking semantic map memory using multi-object navigation. In: Ad- vances in Neural Information Processing Systems (NeurIPS) (2020),https: //arxiv.org/abs/2012.03912, arXiv:2012.03912 4
-
[37]
arXiv preprint arXiv:2103.16544 (2021),https://arxiv.org/abs/ 2103.165443
Weihs, L., Deitke, M., Kembhavi, A., Mottaghi, R.: Visual room rearrange- ment. arXiv preprint arXiv:2103.16544 (2021),https://arxiv.org/abs/ 2103.165443
-
[38]
SpatialScore: Towards Comprehensive Evaluation for Spatial Intelligence
Wu, H., Huang, X., Chen, Y., Zhang, Y., Wang, Y., Xie, W.: Spatialscore: Towards unified evaluation for multimodal spatial understanding. arXiv preprint arXiv:2505.17012 (2025),https://arxiv.org/abs/2505.17012 3, 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
In: CIRA (1997) 20
Yamauchi, B.: A frontier-based approach for autonomous exploration. In: CIRA (1997) 20
1997
-
[40]
arXiv preprint arXiv:2411.01859 (2024),https://arxiv
Ye, G., et al.: Thinking in space: A visual-spatial intelligence benchmark for multimodal llms. arXiv preprint arXiv:2411.01859 (2024),https://arxiv. org/abs/2411.0185920
- [41]
- [42]
-
[43]
Zhang, W., Zhou, Z., Zheng, Z., Gao, C., Cui, J., Li, Y., Chen, X., Zhang, X.P.: Open3dvqa: A benchmark for comprehensive spatial reason- ing with multimodal large language model in open space. arXiv preprint arXiv:2503.11094 (2025),https://arxiv.org/abs/2503.110943, 4 SpaMEM: Dynamic Spatial Reasoning Benchmark 19
-
[44]
arXiv preprint arXiv:2503.11089 (2025),https: //arxiv.org/abs/2503.110894
Zhang, Y., Zhang, Q., Ju, X., Liu, Z., Mao, J., Sun, J., Wu, J., Gao, S., Cai, S., Qin, Z., Liang, L., Wang, J., Duan, Y., Cao, J., Xu, R., Tang, J.: Embodiedvsr: Dynamic scene graph-guided chain-of-thought reasoning for visual spatial tasks. arXiv preprint arXiv:2503.11089 (2025),https: //arxiv.org/abs/2503.110894
-
[45]
Spatial reasoning in multimodal large language models: A survey of tasks, benchmarks and methods
Zhao, Y., et al.: Spatial reasoning in multimodal large language models: A survey of tasks, benchmarks and methods. arXiv preprint arXiv:2511.15722 (2025),https://arxiv.org/abs/2511.157223, 4
-
[46]
quality of action
Zhu, Y., et al.: 3dllm-mem: Long-term spatial-temporal memory for embod- ied 3d large language model. In: Advances in Neural Information Processing Systems (NeurIPS) (2025) 4 20 Liao et al. 7 Additional Related Work Passive Perception vs. Embodied Exploration.Traditional visual-spatial reasoning has largely been framed as a disembodied task, where models ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.