Recognition: unknown
A Model-Driven Approach to Database Migration with a Unified Data Model
Pith reviewed 2026-05-08 09:21 UTC · model grok-4.3
The pith
A unified data model acts as a pivot to enable generic migration between different database systems while preserving structure and queries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
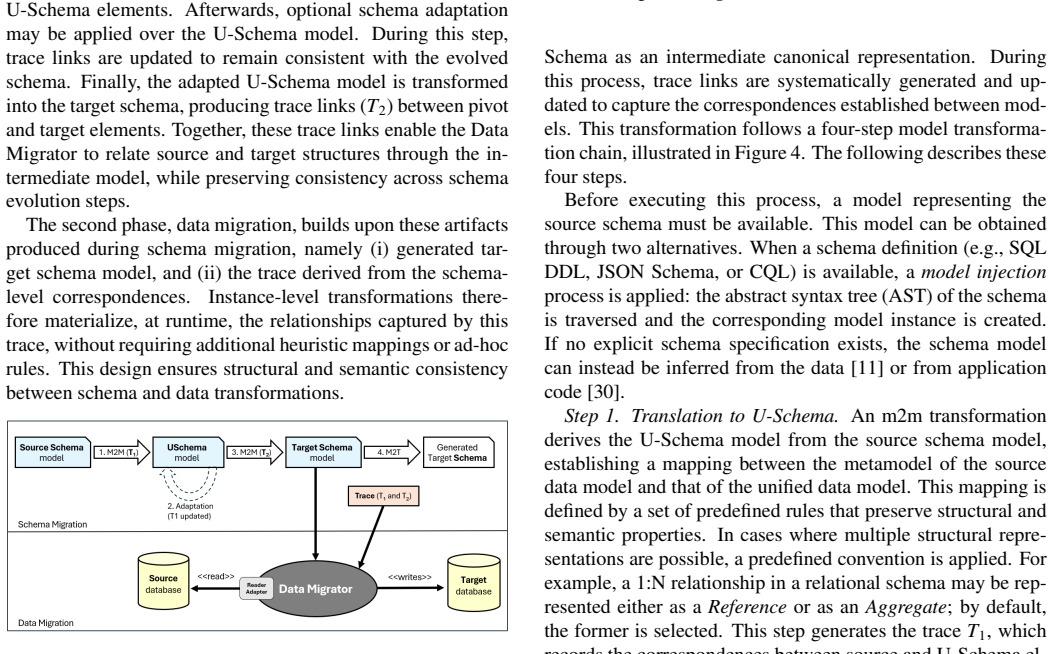
The approach defines mappings from source and target data models to U-Schema to perform schema transformations in two steps, generates trace information to link corresponding elements, and uses those traces to migrate data independently, achieving high structural preservation in round-trip tests and maintaining query semantics for various patterns on relational to document migrations using synthetic and Northwind data.
What carries the argument
U-Schema, the unified data model that serves as a pivot for defining mappings from individual data models and for generating trace information during schema conversion.
If this is right
- The number of mappings required grows linearly with the number of supported data models rather than quadratically.
- Schema validation and data migration can be performed separately using the generated traces.
- Query performance and results remain consistent for joins, aggregations, and nested structures after migration.
- The method supports datasets of increasing size without loss of feasibility.
Where Pith is reading between the lines
- Extending the mappings to additional models such as graph or key-value stores would allow broader multi-model support with the same core mechanism.
- The trace information could also support reverse migrations or incremental updates in evolving systems.
- If U-Schema captures all common features, it might enable automatic detection of schema differences across heterogeneous sources.
Load-bearing premise
Complete and lossless mappings exist between U-Schema and all features of the source and target data models.
What would settle it
A specific database feature in the source model that cannot be mapped to U-Schema without losing information, leading to altered structure or query results upon reconstruction in the target model.
Figures











read the original abstract
Database migration is a key task in software modernization, increasingly involving transformations across heterogeneous data models such as relational and NoSQL systems. Existing approaches are typically designed for specific source-target combinations, which limits their applicability in multi-model environments. This paper proposes a generic database migration approach based on the U-Schema unified data model, which acts as a pivot representation. By defining mappings between each data model and U-Schema, the approach reduces the number of required transformations and enables schema conversion across heterogeneous paradigms. Trace information is generated during schema transformation to capture correspondences between source and target elements, and is subsequently used to guide data migration in a decoupled manner. The approach has been implemented and evaluated through experiments covering schema-level validation, data-level semantic preservation, and performance analysis. The results show that the migration pipeline achieves high structural preservation under round-trip reconstruction, produces document schemas consistent with the intended design decisions, and preserves query behavior across a variety of access patterns, including joins, aggregations, and nested structures. Performance results demonstrate the feasibility of the approach for datasets of increasing size. The evaluation focuses on relational-to-document migration using both synthetic datasets and the Northwind benchmark. While this scenario provides a concrete instantiation, the approach is designed to support multiple data models within a unified framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a model-driven approach to database migration across heterogeneous models (e.g., relational and NoSQL) that uses a unified data model called U-Schema as a pivot representation. Mappings are defined from each source/target model to U-Schema to minimize the number of direct transformations; trace information generated during schema conversion then guides decoupled data migration. The approach is implemented and evaluated on relational-to-document migrations using synthetic datasets and the Northwind benchmark, with claims of high structural preservation under round-trip reconstruction, document schemas consistent with design decisions, preservation of query behavior (joins, aggregations, nested structures), and feasible performance on growing datasets.
Significance. If the mappings can be shown to be lossless for model-specific features and the framework generalizes beyond the single evaluated pair, the work would meaningfully reduce the complexity of multi-model migrations by replacing an n-squared set of direct transformations with a linear set of mappings to a common pivot. The trace-based decoupling of schema and data migration is a practical contribution. The current narrow evaluation and lack of quantitative metrics limit the strength of the supporting evidence.
major comments (3)
- [Abstract] Abstract and Evaluation section: positive outcomes are reported for structural preservation, semantic consistency, and query behavior preservation, yet no quantitative metrics, error rates, or construction details for the round-trip tests are provided. This absence makes it impossible to assess how close to complete the preservation actually is.
- [Abstract] Abstract: the evaluation is confined to relational-to-document migration on Northwind and synthetic data. No results or mapping completeness arguments are given for other paradigms (graph, key-value, wide-column), which directly undermines the claim that the U-Schema pivot enables generic multi-model migration.
- [Approach description] Approach description: the central claim that mappings to U-Schema capture every structural, constraint, and behavioral feature without loss (e.g., relational integrity constraints, document array ordering affecting query results) is asserted but not demonstrated beyond the single evaluated case. Without such evidence, round-trip reconstruction and query-behavior preservation cannot be guaranteed.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. We address each major comment below and indicate the revisions we will make to strengthen the manuscript. Our responses focus on clarifying the scope of the current evaluation while improving the presentation of evidence and claims.
read point-by-point responses
-
Referee: [Abstract] Abstract and Evaluation section: positive outcomes are reported for structural preservation, semantic consistency, and query behavior preservation, yet no quantitative metrics, error rates, or construction details for the round-trip tests are provided. This absence makes it impossible to assess how close to complete the preservation actually is.
Authors: We agree that the abstract and evaluation section would be strengthened by explicit quantitative metrics. The current manuscript describes outcomes qualitatively as 'high structural preservation' and 'preserves query behavior' based on round-trip tests using Northwind and synthetic datasets, but does not report specific percentages, error counts, or detailed test construction (e.g., number of structures compared, query equivalence criteria). We will revise both the abstract and evaluation section to include these details, such as structural fidelity rates, the set of queries tested for joins/aggregations/nesting, and any observed discrepancies. This revision will make the degree of preservation assessable. revision: yes
-
Referee: [Abstract] Abstract: the evaluation is confined to relational-to-document migration on Northwind and synthetic data. No results or mapping completeness arguments are given for other paradigms (graph, key-value, wide-column), which directly undermines the claim that the U-Schema pivot enables generic multi-model migration.
Authors: The empirical evaluation is indeed limited to the relational-to-document case as a concrete instantiation, using Northwind and synthetic data. The U-Schema pivot and associated mappings are defined to support additional paradigms, but the manuscript provides no empirical results or explicit completeness arguments for graph, key-value, or wide-column stores. We will revise the abstract and add a dedicated subsection on mapping completeness, including theoretical arguments for how U-Schema captures core features of the other models (e.g., edges for graphs, simple values for key-value). We will also qualify the generality claim to reflect the evaluated scope while noting the framework's design intent. revision: partial
-
Referee: [Approach description] Approach description: the central claim that mappings to U-Schema capture every structural, constraint, and behavioral feature without loss (e.g., relational integrity constraints, document array ordering affecting query results) is asserted but not demonstrated beyond the single evaluated case. Without such evidence, round-trip reconstruction and query-behavior preservation cannot be guaranteed.
Authors: The manuscript asserts that mappings to U-Schema are designed to be lossless for the supported features, with evidence from the relational-to-document round-trips and query tests. However, explicit demonstration for all features (such as full handling of referential integrity constraints or array ordering semantics) is provided only for the evaluated pair. We will expand the approach section with concrete mapping examples for integrity constraints and ordering, plus a discussion of any features that may require model-specific extensions. Full lossless guarantees across every possible feature and paradigm would require broader validation, which we will acknowledge as a limitation and outline for future work. revision: partial
- Empirical results and quantitative metrics for migrations involving graph, key-value, and wide-column stores, which would require new experiments beyond the current relational-to-document focus.
Circularity Check
No circularity: explicit mappings and evaluation support claims independently
full rationale
The paper presents a model-driven migration pipeline that defines mappings from source/target models to U-Schema as a pivot, generates traces during schema transformation, and uses those traces to guide decoupled data migration. Claims of structural preservation, schema consistency, and query behavior preservation (joins, aggregations, nesting) rest on experimental results from relational-to-document cases (Northwind and synthetic data) rather than any self-referential equations, fitted parameters renamed as predictions, or load-bearing self-citations. No derivation reduces to its inputs by construction; the approach is self-contained through explicit definitions and separate validation steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption U-Schema can represent all relevant structural and semantic features of relational and document data models without loss
invented entities (1)
-
U-Schema
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Sadalage, M
P. Sadalage, M. Fowler, NoSQL Distilled. A Brief Guide to the Emerging World of Polyglot Persistence, Addison- Wesley, 2012
2012
-
[2]
DB-Engines, Db-engines ranking,https://db- engines.com/en/ranking, accessed: January 2026 (2026)
2026
- [3]
-
[4]
N. Roy-Hubara, P. Shoval, A. Sturm, Selecting databases for polyglot persistence applications, Data Knowl. Eng. 137 (2022) 101950. URLhttps://doi.org/10.1016/j.datak.2021.101950
-
[5]
Jia, et al., Model transformation and data migra- tion from relational database to mongodb, in: IEEE Int
T. Jia, et al., Model transformation and data migra- tion from relational database to mongodb, in: IEEE Int. Congress on Big Data, 2016, pp. 60–67
2016
-
[6]
H. Kim, E. Ko, Y . Jeon, K. Lee, Techniques and guide- lines for effective migration from RDBMS to nosql, J. Su- percomput. 76 (10) (2020) 7936–7950
2020
-
[7]
E. M. Kuszera, L. M. Peres, M. D. D. Fabro, Toward RDB to nosql: transforming data with metamorfose frame- work, in: C. Hung, G. A. Papadopoulos (Eds.), Pro- ceedings of the 34th ACM/SIGAPP Symposium on Ap- plied Computing, SAC 2019, Limassol, Cyprus, April 8-12, 2019, ACM, 2019, pp. 456–463.doi:10.1145/ 3297280.3299734
-
[8]
Rocha, et al., A framework for migrating relational datasets to nosql, in: Procs
L. Rocha, et al., A framework for migrating relational datasets to nosql, in: Procs. ICCS 2014, V ol. 51 of Pro- cedia Computer Science, Elsevier, 2015, pp. 2593–2602
2014
-
[9]
Scavuzzo, E
M. Scavuzzo, E. D. Nitto, S. Ceri, Interoperable data mi- gration between nosql columnar databases, in: 18th IEEE EDOC Workshops, 2014, pp. 154–162
2014
-
[10]
Schreiner, D
G. Schreiner, D. Duarte, R. dos Santos Mello, Bringing SQL databases to key-based nosql databases: a canonical approach, Computing 102 (1) (2020) 221–246
2020
- [11]
-
[12]
A. H. Chillón, M. Klettke, D. S. Ruiz, J. G. Molina, A generic schema evolution approach for nosql and rela- tional databases, IEEE Trans. Knowl. Data Eng. 36 (7) (2024) 2774–2789.doi:10.1109/TKDE.2024.3362273
-
[13]
URLhttps://cloud.google.com/architecture/ database-migration-concepts-principles-part-1
Google Cloud Architecture Center, Database migration: Concepts and principles, last updated April 29, 2025 (2025). URLhttps://cloud.google.com/architecture/ database-migration-concepts-principles-part-1
2025
-
[14]
Brambilla, J
M. Brambilla, J. Cabot, M. Wimmer, Model-Driven Soft- ware Engineering in Practice, Morgan & Claypool Pub- lishers, 2012
2012
-
[15]
P. A. Bernstein, A. Y . Halevy, R. Pottinger, A vision of management of complex models, SIGMOD Rec. 29 (4) (2000) 55–63
2000
-
[16]
J. Hainaut, The transformational approach to database engineering, in: Generative and Transformational Tech- niques in Software Engineering, International Summer School, GTTSE 2005, Braga, Portugal, July 4-8, 2005. Revised Papers, 2005, pp. 95–143.doi:10.1007/ 11877028\_4
2005
-
[17]
Elmasri, S
R. Elmasri, S. B. Navathe, Fundamentals of Database Sys- tems, 7th Edition, Pearson, 2015
2015
-
[18]
Hick, J.-L
J.-M. Hick, J.-L. Hainaut, Strategy for database applica- tion evolution: The DB-MAIN approach, in: International Conference on Conceptual Modeling, Springer, 2003, pp. 291–306
2003
-
[19]
URLhttps://partiql.org/assets/PartiQL- Specification.pdf
PartiQL Specification Committee, PartiQL Specification, accessed May 2023. URLhttps://partiql.org/assets/PartiQL- Specification.pdf
2023
-
[20]
Atzeni, F
P. Atzeni, F. Bugiotti, L. Rossi, Uniform Access to Non- relational Database Systems: The SOS Platform, in: 24th International Conference on Advanced Information Sys- tems Engineering (CAiSE), Gdansk, Poland, 2012, pp. 160–174
2012
-
[21]
A. Hernández Chillón, D. Sevilla Ruiz, J. Garcia-Molina, Athena: A Database-Independent Schema Definition Lan- guage, in: Advances in Conceptual Modeling - ER 2021 Workshops CoMoNoS, St.John’s, NL, Canada, V ol. 13012, 2021, pp. 33–42.doi:10.1007/978-3-030- 88358-4
-
[22]
Steinberg, F
D. Steinberg, F. Budinsky, M. Paternostro, E. Merks, EMF: Eclipse Modeling Framework 2.0, Addison-Wesley Professional, 2009. 26
2009
-
[23]
Bettini, Implementing Domain Specific Languages with Xtext and Xtend - Second Edition, 2nd Edition, Packt Publishing, 2016
L. Bettini, Implementing Domain Specific Languages with Xtext and Xtend - Second Edition, 2nd Edition, Packt Publishing, 2016
2016
-
[24]
G. Zhao, Q. Lin, L. Li, Z. Li, Schema conversion model of sql database to nosql, in: 9th Int. Conf. on P2P, Paral- lel, Grid, Cloud and Internet Computing, IEEE, 2014, pp. 355–362
2014
-
[25]
Y . Wang, R. Shah, A. Criswell, R. Pan, I. Dillig, Data migration using datalog program synthesis, Proc. VLDB Endow. 13 (7) (2020) 1006–1019. doi:10.14778/3384345.3384350. URLhttp://www.vldb.org/pvldb/vol13/p1006- wang.pdf
-
[26]
Hainaut, V
J. Hainaut, V . Englebert, J. Henrard, J. Hick, D. Roland, Database Evolution: the DB-Main Approach, in: P. Loucopoulos (Ed.), Entity-Relationship Approach - ER’94, Business Modelling and Re-Engineering, 13th International Conference on the Entity-Relationship Ap- proach, Manchester, UK, December 13-16, 1994, Pro- ceedings, V ol. 881 of Lecture Notes in C...
1994
-
[27]
J.-L. Hainaut, A. Cleve, J. Henrard, J.-M. Hick, Migra- tion of Legacy Information Systems, Springer Berlin Hei- delberg, 2008, pp. 105–138.doi:10.1007/978-3-540- 76440-3\_6
-
[28]
Dziedzic, A
A. Dziedzic, A. J. Elmore, M. Stonebraker, Data trans- formation and migration in polystores, in: IEEE HPEC, 2016, pp. 1–6
2016
-
[29]
Chung, H.-P
W.-C. Chung, H.-P. Lin, S.-C. Chen, M.-F. Jiang, Y .-C. Chung, Jackhare: a framework for sql to nosql transla- tion using mapreduce, Automated Software Engineering 21 (2014) 489–508
2014
-
[30]
C. J. F. Candel, A. Cleve, J. J. G. Molina, Towards the automated extraction and refactoring of nosql schemas from application code, J. Syst. Softw. 236 (2026) 112787. doi:10.1016/J.JSS.2026.112787
-
[31]
C. J. F. Candel, J. G. Molina, F. J. B. Ruiz, J. R. H. Barceló, D. S. Ruiz, B. J. C. Viera, Developing a model- driven reengineering approach for migrating PL/SQL triggers to java: A practical experience, Journal Sys- tems and Software 151 (2019) 38–64.doi:10.1016/ j.jss.2019.01.068
2019
-
[32]
C. J. F. Candel, A. Cleve, J. J. G. Molina, Towards the au- tomated extraction and refactoring of nosql schemas from application code, CoRR abs/2505.20230 (2025).doi: 10.48550/ARXIV.2505.20230. 27 Table 7: Comparison of migration approaches according to the proposed criteria. Criterion [28] [18] [5] [6] [7] [8] [9] [10] [24] [25]Our approach C1. Data mode...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.