Recognition: unknown
Inference in Tightly Identified and Large-Scale Sign-Restricted SVARs
Pith reviewed 2026-05-08 09:16 UTC · model grok-4.3
The pith
A differentiable reparameterization turns inequality restrictions into smooth constraints for efficient Hamiltonian Monte Carlo sampling in large-scale sign-restricted SVARs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that reparameterizing the structural parameters via continuously differentiable mappings lets inequality restrictions be imposed directly while preserving the target posterior, so that the density can be evaluated quickly enough to support Hamiltonian Monte Carlo sampling in large-scale and tightly identified SVARs.
What carries the argument
The reparameterization of SVAR parameters through continuously differentiable mappings that enforce shape, ranking, elasticity, and zero restrictions while enabling gradient-based sampling.
If this is right
- Inference becomes practical in high-dimensional SVARs that incorporate economically motivated inequality restrictions.
- Shape, ranking, and elasticity bounds can be imposed alongside zero restrictions without custom Metropolis-Hastings steps.
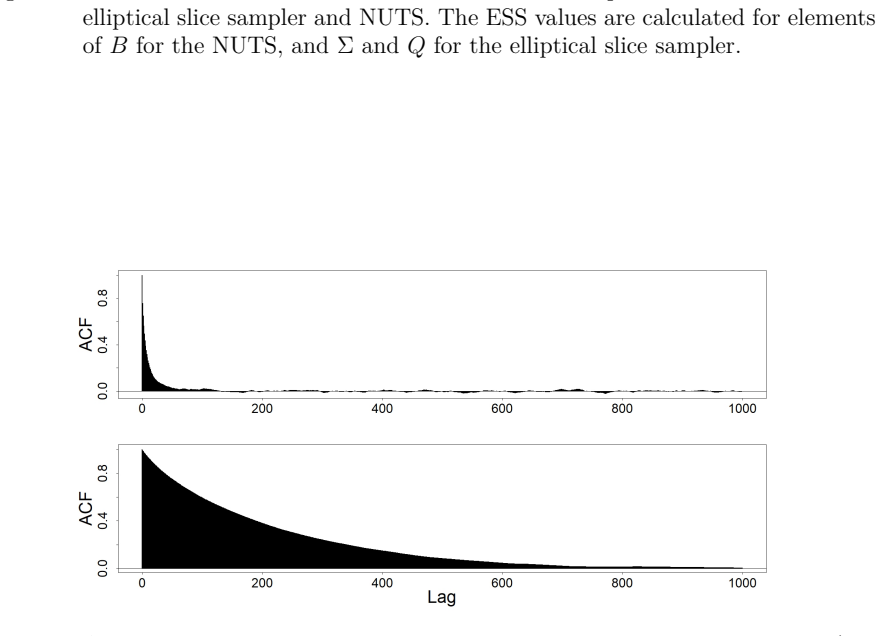
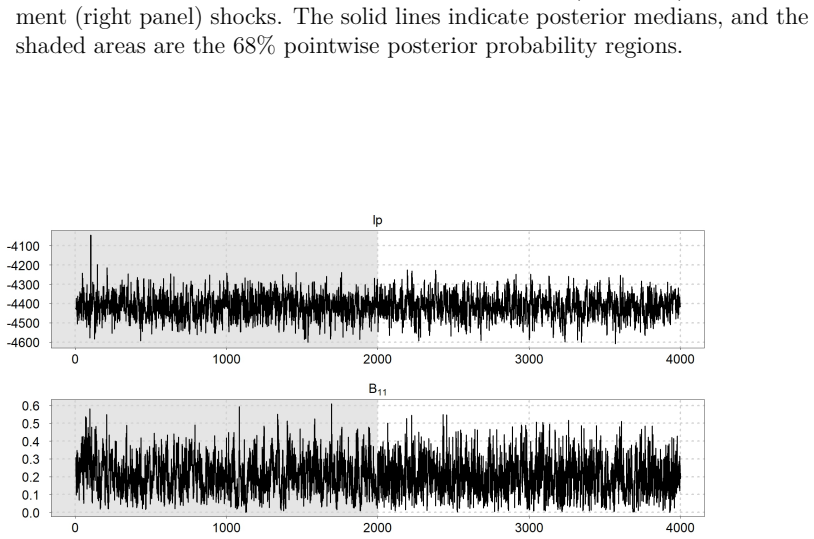
- Markov chains display lower serial dependence and higher effective sample sizes than random-walk or other existing samplers.
- Overall computation time decreases, expanding the feasible size of models used for impulse-response analysis.
Where Pith is reading between the lines
- The same differentiable-mapping idea could be tested on other Bayesian models that rely on inequality constraints, such as DSGE estimation.
- Faster sampling might allow routine use of large SVARs for real-time forecasting or policy counterfactuals that were previously too slow.
- One could check whether the approach extends to time-varying parameter or regime-switching SVARs without losing efficiency gains.
Load-bearing premise
The mappings correctly represent the original identifying constraints and preserve the target posterior distribution without introducing bias or numerical instabilities in high dimensions.
What would settle it
Apply the method and a standard sampler to the same large simulated SVAR with known true parameters, then check whether the recovered posterior means, credible intervals, and effective sample sizes match while the new method records shorter wall-clock time.
Figures









read the original abstract
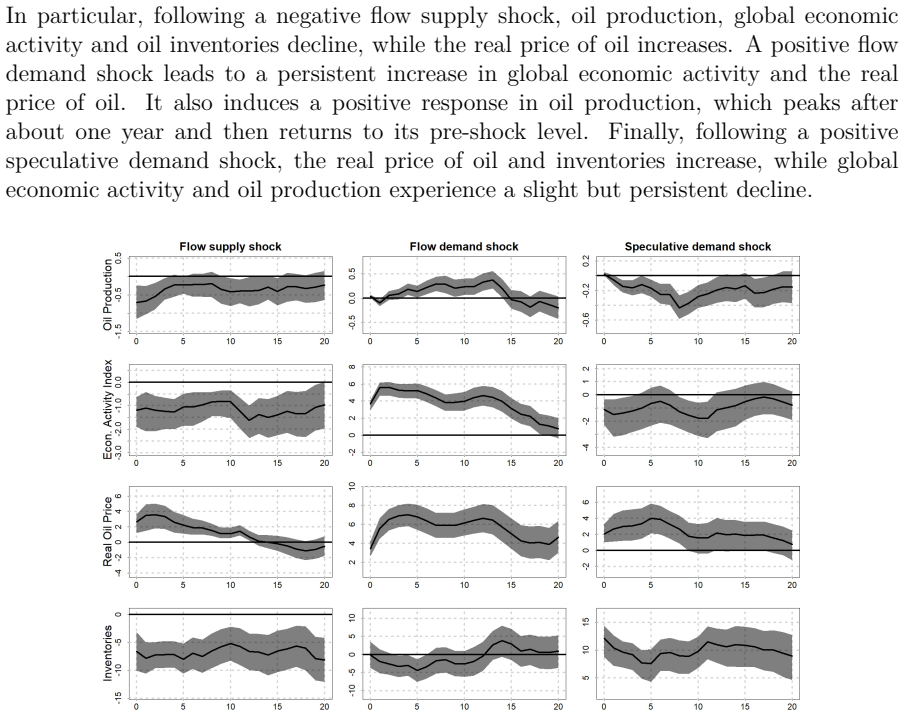
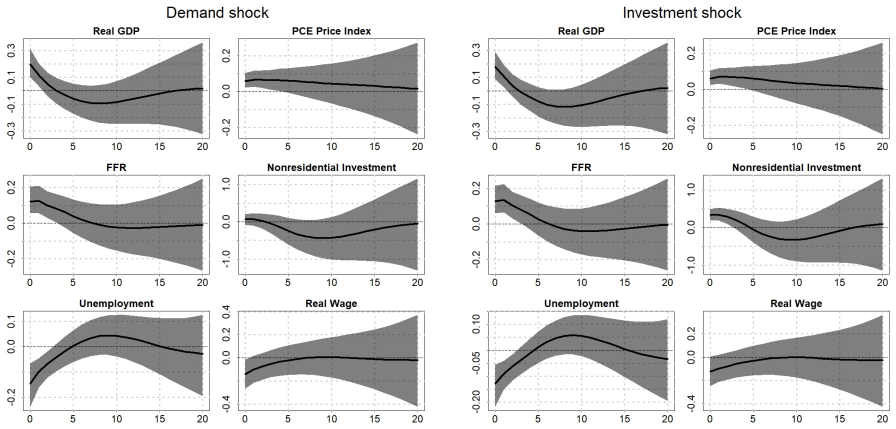
We propose a new approach to inference in tightly identified and large-scale structural vector autoregressions based on a reparameterization that enables imposing identifying inequality restrictions through continuously differentiable mappings. Permitted inequality restrictions include shape and ranking restrictions as well as bounds on economically relevant elasticities, and the approach is also able to accommodate zero restrictions in a straightforward manner. We implement a Hamiltonian Monte Carlo algorithm and show how the posterior density can be rapidly evaluated under the reparameterization, thus facilitating inference in high-dimensional settings. Two empirical applications demonstrate that our approach tends to result in lower serial dependence in Markov chains, larger effective sample sizes and reduced computation time relative to existing methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a reparameterization of sign-restricted SVARs that maps an unconstrained parameter space to the identified set via continuously differentiable functions for shape, ranking, and elasticity restrictions (while accommodating zero restrictions), enabling direct Hamiltonian Monte Carlo sampling with rapid posterior density evaluation in high-dimensional settings. Two empirical applications are used to demonstrate reduced serial dependence, larger effective sample sizes, and shorter computation times relative to existing methods.
Significance. If the reparameterization and associated change-of-variables formula are shown to be bijective and to preserve the target posterior exactly (including the Jacobian term), the approach would offer a practical advance for inference in tightly identified, large-scale SVARs by sidestepping the computational costs of rejection sampling or other indirect methods. The reported MCMC efficiency gains in the applications provide concrete evidence of practical utility when the mappings are correctly implemented.
major comments (3)
- [§3.2] §3.2, the change-of-variables formula for the continuously differentiable mappings: the posterior density under the reparameterization is stated to be evaluable rapidly, but the manuscript does not provide an explicit derivation or numerical verification that the absolute value of the Jacobian determinant is included for all restriction types (shape, ranking, elasticity). Without this, the sampled distribution may not match the original posterior over the identified set.
- [§4.1] §4.1, high-dimensional implementation: the claim that the mappings remain numerically stable and cover the full identified set when zero restrictions are mixed with inequalities is not supported by diagnostics (e.g., coverage checks or singularity tests) in dimensions typical of the applications; this is load-bearing for the efficiency gains reported in §5.
- [Table 2] Table 2 and §5.2, effective sample size comparisons: the reported ESS improvements are presented without reporting the fraction of draws that satisfy the original (pre-mapping) restrictions after transformation, leaving open whether the efficiency gains come at the cost of incomplete coverage of the identified set.
minor comments (2)
- Notation for the mapping functions (e.g., the definition of the elasticity bounds) is introduced without a consolidated table of symbols, making it difficult to track across sections.
- The abstract states performance gains in two applications, but the main text does not include a brief statement of the exact identifying restrictions used in each application until §5.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive comments. We address each major point below and will incorporate revisions to improve the clarity and rigor of the derivations, diagnostics, and reported results.
read point-by-point responses
-
Referee: [§3.2] §3.2, the change-of-variables formula for the continuously differentiable mappings: the posterior density under the reparameterization is stated to be evaluable rapidly, but the manuscript does not provide an explicit derivation or numerical verification that the absolute value of the Jacobian determinant is included for all restriction types (shape, ranking, elasticity). Without this, the sampled distribution may not match the original posterior over the identified set.
Authors: We agree that greater explicitness is warranted. In the revised manuscript we will add a complete step-by-step derivation of the change-of-variables formula that explicitly includes the absolute value of the Jacobian determinant for shape restrictions, ranking restrictions, elasticity bounds, and their combinations with zero restrictions. We will also supply a low-dimensional numerical check (bivariate SVAR) that compares the original and transformed posterior densities to confirm exact preservation of the target distribution. revision: yes
-
Referee: [§4.1] §4.1, high-dimensional implementation: the claim that the mappings remain numerically stable and cover the full identified set when zero restrictions are mixed with inequalities is not supported by diagnostics (e.g., coverage checks or singularity tests) in dimensions typical of the applications; this is load-bearing for the efficiency gains reported in §5.
Authors: The empirical applications already operate in the relevant dimensions, but we accept that explicit diagnostics would strengthen the claims. In revision we will add (i) coverage checks that draw from the identified set, apply the inverse mapping, and verify recovery of the original parameters, and (ii) numerical stability and singularity diagnostics for the Jacobian and mapping functions at the sample sizes and dimensions used in Sections 5.1 and 5.2. revision: yes
-
Referee: [Table 2] Table 2 and §5.2, effective sample size comparisons: the reported ESS improvements are presented without reporting the fraction of draws that satisfy the original (pre-mapping) restrictions after transformation, leaving open whether the efficiency gains come at the cost of incomplete coverage of the identified set.
Authors: The reparameterization is constructed to be bijective onto the identified set, so every draw satisfies the restrictions by design. To address the concern directly we will report, in the revised Table 2 and accompanying text, the fraction of transformed draws that satisfy the original (pre-mapping) restrictions; we will also include supplementary coverage diagnostics confirming that the support of the transformed posterior coincides with the identified set. revision: yes
Circularity Check
No circularity; reparameterization and HMC implementation are independently derived and empirically validated
full rationale
The paper introduces a reparameterization via continuously differentiable mappings to enforce shape, ranking, elasticity, and zero restrictions in SVARs, then derives the transformed posterior density for direct HMC sampling. Performance claims rest on explicit comparisons of serial dependence, effective sample sizes, and runtime against existing methods in two applications, not on any fitted parameter being relabeled as a prediction or on self-referential definitions. No load-bearing self-citation, uniqueness theorem imported from the authors' prior work, or ansatz smuggled via citation appears in the derivation chain; the mappings are presented as a new construction whose Jacobian-adjusted density is evaluated directly. The approach is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Identifying inequality restrictions (shape, ranking, bounds on elasticities) can be represented by continuously differentiable mappings from an unconstrained parameter space.
Reference graph
Works this paper leans on
-
[1]
Amir Ahmadi, P., and Drautzburg, T. (2021). Identification and inference with ranking restrictions.Quantitative Economics,12(1), 1–39. Antolín-Díaz, J., and Rubio-Ramírez, J. F. (2018). Narrative sign restrictions for svars. The American Economic Review,108(10), 2802–2829. Arias, J. E., Rubio-Ramirez, J. F., and Shin, M. (2025).A Gibbs Sampler for Efficie...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
Uhlig, H. (2017). Shocks, sign restrictions, and identification.Advances in Economics and Econometrics,2,
2017
-
[3]
metric” of the algorithm. Given the momentum variables, we define the Hamiltonian as H(θ,ρ) =−logp(θ)−logp(ρ)(C.1) =V(θ) +T(ρ). The termV(θ)is the “potential energy,
Vats, D., Flegal, J. M., and Jones, G. L. (2019). Multivariate output analysis for Markov chain Monte Carlo.Biometrika,106(2), 321–337. 32 Vehtari, A., Gelman, A., Simpson, D., Carpenter, B., and Bürkner, P.-C. (2021). Rank- normalization, folding, and localization: An improvedˆRfor assessing convergence of MCMC (with discussion).Bayesian Analysis,16(2). ...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.