Recognition: unknown
Measuring and Mitigating Persona Distortions from AI Writing Assistance
Pith reviewed 2026-05-08 11:36 UTC · model grok-4.3
The pith
AI writing assistance distorts readers' perceptions of the writer's persona, making them seem more opinionated, competent, positive, and privileged.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
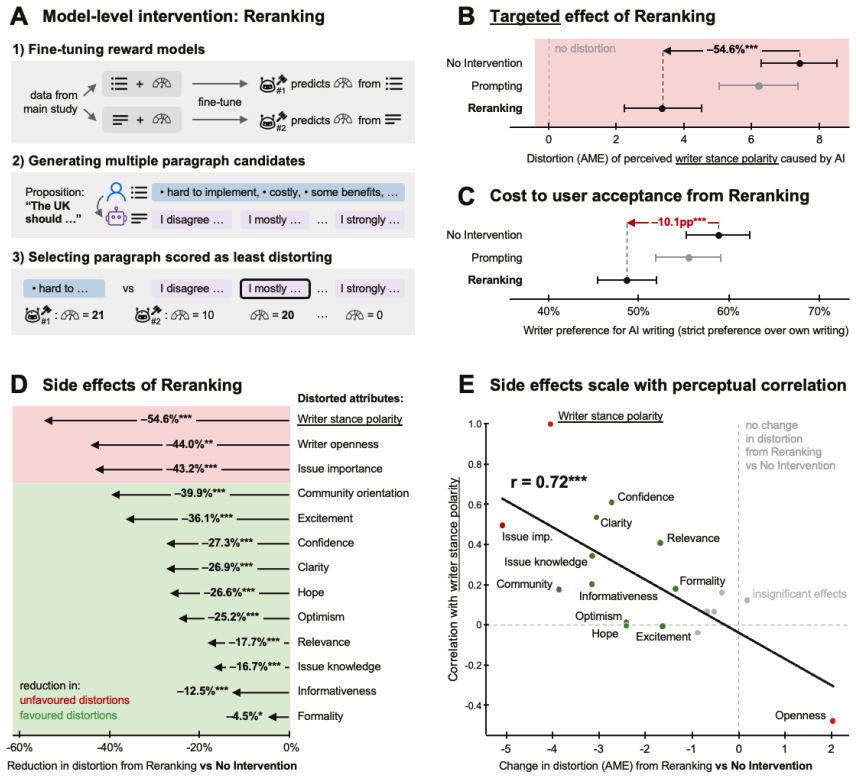
The paper establishes that AI writing assistance produces persona distortions across political opinion, writing quality, writer personality, emotions, and demographics. Assisted writers are perceived as more opinionated, competent, and positive, with demographic profiles shifting toward privileged groups. Writers object to many distortions yet continue to prefer AI-assisted text. Reward models trained on experimental data can steer AI outputs toward faithful representation of writer stance, but this reduces user acceptance.
What carries the argument
Large-scale blind reader evaluations of paragraphs written with versus without AI, using 29 perception dimensions, followed by training reward models on the collected ratings to align AI outputs with the writer's original stance.
Load-bearing premise
The assumption that reader perceptions in this controlled political-paragraph task validly capture real-world persona distortions and that the observed effects generalize beyond the specific experimental conditions and participant pools.
What would settle it
A study showing that in unrestricted, real-world writing scenarios like emails or blog posts, blind readers do not detect the same systematic persona shifts between AI-assisted and unassisted texts.
Figures



read the original abstract
Hundreds of millions of people use artificial intelligence (AI) for writing assistance. Here, we evaluated how AI writing assistance distorts writer personas - their perceived beliefs, personality, and identity. In three large-scale experiments, writers (N=2,939) wrote political opinion paragraphs with and without AI assistance. Separate groups of readers (N=11,091) blindly evaluated these paragraphs across 29 socially salient dimensions of reader perception, spanning political opinion, writing quality, writer personality, emotions, and demographics. AI writing assistance produced persona distortions across all dimensions: with AI, writers seemed more opinionated, competent, and positive, and their perceived demographic profile shifted towards more privileged groups. Writers objected to many of the observed distortions, yet continued to prefer AI-assisted text even when made aware of them. We successfully mitigated objectionable persona distortions at the model level by training reward models on our experimental data (10,008 paragraphs, 2,903,596 ratings) to steer AI outputs towards faithful representation of writer stance. However, this came at a cost to user acceptance, suggesting an entanglement between desirable and undesirable properties of AI writing assistance that may be difficult to resolve. Together, our findings demonstrate that persona distortions from AI writing assistance are pervasive and persistent even under realistic conditions of human oversight, which carries implications for public discourse, trust, and democratic deliberation that scale with AI adoption.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports three large-scale experiments (N=2,939 writers, N=11,091 readers) in which writers produced political opinion paragraphs with and without AI assistance. Blind reader evaluations across 29 dimensions show consistent persona distortions: AI-assisted text makes writers appear more opinionated, competent, positive, and demographically privileged. Writers object to many distortions yet still prefer AI-assisted output even when informed. The authors train reward models on the collected 10,008 paragraphs and 2.9M ratings to steer outputs toward faithful stance representation, achieving mitigation at the cost of reduced user acceptance. The work concludes that such distortions are pervasive even under human oversight.
Significance. If the core empirical patterns hold, the study is significant for AI ethics and computational social science because it supplies unusually large-scale, multi-dimensional evidence on how AI writing tools alter perceived writer identity. The scale (thousands of writers and readers, 29 rating dimensions) and the concrete mitigation experiment are clear strengths; the finding of an entanglement between desirable fluency and undesirable persona shifts supplies a falsifiable, policy-relevant observation about the limits of post-hoc steering.
major comments (2)
- [Abstract and §3 (Experiments)] Abstract and experimental design (three large-scale experiments): the headline claim that distortions are 'pervasive and persistent even under realistic conditions of human oversight' rests on a single-turn, fixed-prompt political-paragraph task. No within-paper tests of multi-turn editing, prompt engineering, post-editing, or non-political topics are reported, yet these factors are load-bearing for the generalization to naturalistic use that underpins the pervasiveness conclusion.
- [Mitigation experiments] Mitigation section (reward-model training on 10,008 paragraphs): the reward models are trained exclusively on the same experimental paragraphs used to demonstrate the distortions. This leaves open whether the observed reduction in distortion is an artifact of task-specific overfitting rather than a general property of the steering method, directly affecting the claim that mitigation is feasible at the model level.
minor comments (2)
- [Abstract] Abstract: reporting of blinding, randomization procedures, and exact statistical controls is abbreviated; fuller specification in the main text would strengthen verifiability of the large-N claims.
- [Results] Results presentation: the 29 dimensions are aggregated into broad categories (opinion, personality, demographics); clearer per-dimension effect-size tables or figures would allow readers to assess whether all dimensions move uniformly or whether some drive the headline pattern.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive feedback. We address each major comment below with clarifications on our experimental scope and mitigation approach, while outlining targeted revisions to improve precision without overstating generalizability.
read point-by-point responses
-
Referee: [Abstract and §3 (Experiments)] Abstract and experimental design (three large-scale experiments): the headline claim that distortions are 'pervasive and persistent even under realistic conditions of human oversight' rests on a single-turn, fixed-prompt political-paragraph task. No within-paper tests of multi-turn editing, prompt engineering, post-editing, or non-political topics are reported, yet these factors are load-bearing for the generalization to naturalistic use that underpins the pervasiveness conclusion.
Authors: We agree that the experiments are confined to a single-turn, fixed-prompt political opinion task and do not include multi-turn editing, prompt engineering, post-editing, or non-political domains. This controlled design enabled the large-scale, blinded reader evaluations (N=11,091) across 29 dimensions while isolating AI assistance effects under human oversight. We do not assert that identical distortion patterns apply to all writing contexts; the pervasiveness claim is scoped to the tested conditions, which reflect common initial-draft uses. In revision we will qualify the abstract, introduction, and discussion to explicitly limit generalization, expand the limitations section with these boundaries, and note that the observed distortions even in this basic setting warrant caution. No new experiments are added, but the claims will be tightened accordingly. revision: partial
-
Referee: [Mitigation experiments] Mitigation section (reward-model training on 10,008 paragraphs): the reward models are trained exclusively on the same experimental paragraphs used to demonstrate the distortions. This leaves open whether the observed reduction in distortion is an artifact of task-specific overfitting rather than a general property of the steering method, directly affecting the claim that mitigation is feasible at the model level.
Authors: The referee correctly notes that the reward models were trained on the 10,008 experimental paragraphs and associated 2.9M ratings. This was intentional to create a steering objective that directly targets the specific persona distortions quantified in our reader study. We will revise the mitigation section to report additional held-out validation metrics, discuss the in-domain nature of the training data, and explicitly frame the results as a proof-of-concept for model-level mitigation rather than a domain-general solution. Future out-of-distribution testing is acknowledged as necessary but outside the current scope. revision: partial
Circularity Check
No circularity: purely empirical study with independent human ratings and standard reward model training
full rationale
The paper reports three experiments collecting writer paragraphs (with/without AI) and reader ratings across 29 dimensions, then trains reward models on the resulting dataset to demonstrate mitigation. No mathematical derivations, predictions, or first-principles results are claimed. The mitigation step uses the collected ratings as training data in the conventional manner for preference modeling; it does not rename a fit as a prediction or reduce any central claim to its own inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The work is self-contained against its own human-subject benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Blind reader ratings provide an unbiased measure of perceived persona attributes
Reference graph
Works this paper leans on
-
[1]
Doubleday, 1959
Erving Goffman.The presentation of self in everyday life. Doubleday, 1959
1959
-
[2]
Psychological aspects of natural language use: Our words, our selves.Annual review of psychology, 54(1):547–577, 2003
James W Pennebaker, Matthias R Mehl, and Kate G Niederhoffer. Psychological aspects of natural language use: Our words, our selves.Annual review of psychology, 54(1):547–577, 2003
2003
-
[3]
Ireland and Matthias R
Molly E. Ireland and Matthias R. Mehl. Natural language use as a marker of personality. In Thomas M. Holtgraves, editor,The Oxford handbook of language and social psychology, pages 201–218. Oxford University Press, 2014
2014
-
[4]
How developments in natural language processing help us in understanding human behaviour.Nature Human Behaviour, 8(10):1877–1889, 2024
Rada Mihalcea, Laura Biester, Ryan L Boyd, Zhijing Jin, Veronica Perez-Rosas, Steven Wilson, and James W Pennebaker. How developments in natural language processing help us in understanding human behaviour.Nature Human Behaviour, 8(10):1877–1889, 2024
2024
-
[5]
How people use chatgpt
Aaron Chatterji, Thomas Cunningham, David J Deming, Zoe Hitzig, Christopher Ong, Carl Yan Shan, and Kevin Wadman. How people use chatgpt. Technical report, National Bureau of Economic Research, 2025
2025
-
[6]
Troy, Dario Amodei, Jared Kaplan, Jack Clark, and Deep Ganguli
Kunal Handa, Alex Tamkin, Miles McCain, Saffron Huang, Esin Durmus, Sarah Heck, Jared Mueller, Jerry Hong, Stuart Ritchie, Tim Belonax, et al. Which economic tasks are performed with ai? evidence from millions of claude conversations.arXiv preprint arXiv:2503.04761, 2025
-
[7]
Kiran Tomlinson, Sonia Jaffe, Will Wang, Scott Counts, and Siddharth Suri. Working with ai: measuring the applicability of generative ai to occupations.arXiv preprint arXiv:2507.07935, 2025
-
[8]
Cnet published ai-generated stories
Caitlin Harrington. Cnet published ai-generated stories. then its staff pushed back.Wired, 2025
2025
-
[9]
Lucio La Cava, Luca Maria Aiello, and Andrea Tagarelli. Machines in the crowd? measuring the footprint of machine-generated text on reddit.arXiv preprint arXiv:2510.07226, 2025
-
[10]
Mps are almost certainly using chatgpt to generate commons speeches.Pimlico Journal, 2025
Pimlico Journal. Mps are almost certainly using chatgpt to generate commons speeches.Pimlico Journal, 2025
2025
-
[11]
Are we in the AI-generated text world already? quantifying and monitoring AIGT on social media
Zhen Sun, Zongmin Zhang, Xinyue Shen, Ziyi Zhang, Yule Liu, Michael Backes, Yang Zhang, and Xinlei He. Are we in the AI-generated text world already? quantifying and monitoring AIGT on social media. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association for Computat...
2025
-
[12]
Federal judges using ai filed court orders with false quotes, fake names.Washington Post, 2025
Daniel Wu. Federal judges using ai filed court orders with false quotes, fake names.Washington Post, 2025
2025
-
[13]
Academic journals’ ai policies fail to curb the surge in ai-assisted academic writing.Proceedings of the National Academy of Sciences, 123(9):e2526734123, 2026
Yongyuan He and Yi Bu. Academic journals’ ai policies fail to curb the surge in ai-assisted academic writing.Proceedings of the National Academy of Sciences, 123(9):e2526734123, 2026
2026
-
[14]
Jinsook Lee, Conrad Borchers, AJ Alvero, Thorsten Joachims, and Rene F Kizilcec. The digital divide in generative ai: Evidence from large language model use in college admissions essays. arXiv preprint arXiv:2602.17791, 2026
-
[15]
Homogenization effects of large language models on human creative ideation
Barrett R Anderson, Jash Hemant Shah, and Max Kreminski. Homogenization effects of large language models on human creative ideation. InProceedings of the 16th conference on creativity & cognition, pages 413–425, 2024
2024
-
[16]
Does writing with language models reduce content diversity? InThe Twelfth International Conference on Learning Representations, 2024
Vishakh Padmakumar and He He. Does writing with language models reduce content diversity? InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[17]
Ai suggestions homogenize writing toward western styles and diminish cultural nuances
Dhruv Agarwal, Mor Naaman, and Aditya Vashistha. Ai suggestions homogenize writing toward western styles and diminish cultural nuances. InProceedings of the 2025 CHI conference on human factors in computing systems, pages 1–21, 2025. 14
2025
-
[18]
Artificial hivemind: The open-ended homogeneity of language models (and beyond)
Liwei Jiang, Yuanjun Chai, Margaret Li, Mickel Liu, Raymond Fok, Nouha Dziri, Yulia Tsvetkov, Maarten Sap, and Yejin Choi. Artificial hivemind: The open-ended homogeneity of language models (and beyond). InThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2025
2025
-
[19]
Zhivar Sourati, Farzan Karimi-Malekabadi, Meltem Ozcan, Colin McDaniel, Alireza Ziabari, Jackson Trager, Ala Tak, Meng Chen, Fred Morstatter, and Morteza Dehghani. The shrink- ing landscape of linguistic diversity in the age of large language models.arXiv preprint arXiv:2502.11266, 2025
-
[20]
How llms distort our written language.arXiv preprint arXiv:2603.18161, 2026
Marwa Abdulhai, Isadora White, Yanming Wan, Ibrahim Qureshi, Joel Leibo, Max Kleiman- Weiner, and Natasha Jaques. How llms distort our written language.arXiv preprint arXiv:2603.18161, 2026
-
[21]
(mis) perceptions of partisan polarization in the american public.Public Opinion Quarterly, 80(S1):378–391, 2016
Matthew S Levendusky and Neil Malhotra. (mis) perceptions of partisan polarization in the american public.Public Opinion Quarterly, 80(S1):378–391, 2016
2016
-
[22]
(mis) estimating affective polarization.The Journal of Politics, 84(2):1106–1117, 2022
James N Druckman, Samara Klar, Yanna Krupnikov, Matthew Levendusky, and John Barry Ryan. (mis) estimating affective polarization.The Journal of Politics, 84(2):1106–1117, 2022
2022
-
[23]
Cognitive–motivational mechanisms of political polarization in social-communicative contexts.Nature reviews psychology, 1(10):560–576, 2022
John T Jost, Delia S Baldassarri, and James N Druckman. Cognitive–motivational mechanisms of political polarization in social-communicative contexts.Nature reviews psychology, 1(10):560–576, 2022
2022
-
[24]
The persuasiveness of source credibility: A critical review of five decades’ evidence.Journal of applied social psychology, 34(2):243–281, 2004
Chanthika Pornpitakpan. The persuasiveness of source credibility: A critical review of five decades’ evidence.Journal of applied social psychology, 34(2):243–281, 2004
2004
-
[25]
G Tarcan Kumkale, Dolores Albarracín, and Paul J Seignourel. The effects of source credibility in thepresenceorabsenceofpriorattitudes: Implicationsforthedesignofpersuasivecommunication campaigns.Journal of applied social psychology, 40(6):1325–1356, 2010
2010
-
[26]
What makes online content viral?Journal of marketing research, 49(2):192–205, 2012
Jonah Berger and Katherine L Milkman. What makes online content viral?Journal of marketing research, 49(2):192–205, 2012
2012
-
[27]
Emotion shapes the diffusion of moralized content in social networks.Proceedings of the National Academy of Sciences, 114(28):7313–7318, 2017
William J Brady, Julian A Wills, John T Jost, Joshua A Tucker, and Jay J Van Bavel. Emotion shapes the diffusion of moralized content in social networks.Proceedings of the National Academy of Sciences, 114(28):7313–7318, 2017
2017
-
[28]
Out-group animosity drives engage- ment on social media.Proceedings of the national academy of sciences, 118(26):e2024292118, 2021
Steve Rathje, Jay J Van Bavel, and Sander Van Der Linden. Out-group animosity drives engage- ment on social media.Proceedings of the national academy of sciences, 118(26):e2024292118, 2021
2021
-
[29]
Are emily and greg more employable than lakisha and jamal? a field experiment on labor market discrimination.American economic review, 94(4):991–1013, 2004
Marianne Bertrand and Sendhil Mullainathan. Are emily and greg more employable than lakisha and jamal? a field experiment on labor market discrimination.American economic review, 94(4):991–1013, 2004
2004
-
[30]
Science faculty’s subtle gender biases favor male students.Proceedings of the national academy of sciences, 109(41):16474–16479, 2012
Corinne A Moss-Racusin, John F Dovidio, Victoria L Brescoll, Mark J Graham, and Jo Han- delsman. Science faculty’s subtle gender biases favor male students.Proceedings of the national academy of sciences, 109(41):16474–16479, 2012
2012
-
[31]
Meta-analysis of field experiments shows no change in racial discrimination in hiring over time.Proceedings of the National Academy of Sciences, 114(41):10870–10875, 2017
Lincoln Quillian, Devah Pager, Ole Hexel, and Arnfinn H Midtbøen. Meta-analysis of field experiments shows no change in racial discrimination in hiring over time.Proceedings of the National Academy of Sciences, 114(41):10870–10875, 2017
2017
-
[32]
Signaling in the age of ai: Evidence from cover letters
Jingyi Cui, Gabriel Dias, and Justin Ye. Signaling in the age of ai: Evidence from cover letters. arXiv preprint arXiv:2509.25054, 2025
-
[33]
Making talk cheap: Generative ai and labor market signaling
Anais Galdin and Jesse Silbert. Making talk cheap: Generative ai and labor market signaling. arXiv preprint arXiv:2511.08785, 2025
-
[34]
The role of inclusion, control, and ownership in workplace ai-mediated communication
Kowe Kadoma, Marianne Aubin Le Quere, Xiyu Jenny Fu, Christin Munsch, Danaë Metaxa, and Mor Naaman. The role of inclusion, control, and ownership in workplace ai-mediated communication. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems, pages 1–10, 2024. 15
2024
-
[35]
Reactive writers: How co-writing with ai changes how we engage with ideas, 2026
Advait Bhat, Marianne Aubin Le Quéré, Mor Naaman, and Maurice Jakesch. Reactive writers: How co-writing with ai changes how we engage with ideas, 2026
2026
-
[36]
The homogenizing effect of large language models on human expression and thought.Trends in Cognitive Sciences, 2026
Zhivar Sourati, Alireza S Ziabari, and Morteza Dehghani. The homogenizing effect of large language models on human expression and thought.Trends in Cognitive Sciences, 2026
2026
-
[37]
always check important information!
Angelica Lermann Henestrosa and Joachim Kimmerle. “always check important information!”- the role of disclaimers in the perception of ai-generated content.Computers in Human Behavior: Artificial Humans, 4:100142, 2025
2025
-
[38]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Gray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback...
2022
-
[39]
Self-diagnosis and self-debiasing: A proposal for reducing corpus-based bias in nlp.Transactions of the Association for Computational Linguistics, 9:1408–1424, 2021
Timo Schick, Sahana Udupa, and Hinrich Schütze. Self-diagnosis and self-debiasing: A proposal for reducing corpus-based bias in nlp.Transactions of the Association for Computational Linguistics, 9:1408–1424, 2021
2021
-
[40]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. Constitutional ai: Harmlessness from ai feedback.arXiv preprint arXiv:2212.08073, 2022
work page internal anchor Pith review arXiv 2022
-
[41]
The levers of political persuasion with conversational artificial intelligence.Science, 390(6777):eaea3884, 2025
Kobi Hackenburg, Ben M Tappin, Luke Hewitt, Ed Saunders, Sid Black, Hause Lin, Catherine Fist, Helen Margetts, David G Rand, and Christopher Summerfield. The levers of political persuasion with conversational artificial intelligence.Science, 390(6777):eaea3884, 2025
2025
-
[42]
Jiayi Zhang, Simon Yu, Derek Chong, Anthony Sicilia, Michael R Tomz, Christopher D Manning, and Weiyan Shi. Verbalized sampling: How to mitigate mode collapse and unlock llm diversity. arXiv preprint arXiv:2510.01171, 2025
-
[43]
Scaling laws for reward model overoptimization
Leo Gao, John Schulman, and Jacob Hilton. Scaling laws for reward model overoptimization. In International Conference on Machine Learning, pages 10835–10866. PMLR, 2023
2023
-
[44]
Elizabeth Clark, Tal August, Sofia Serrano, Nikita Haduong, Suchin Gururangan, and Noah A. Smith. All that’s ‘human’ is not gold: Evaluating human evaluation of generated text. In Chengqing Zong, Fei Xia, Wenjie Li, and Roberto Navigli, editors,Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th Internation...
2021
-
[45]
Human heuristics for ai-generated language are flawed.Proceedings of the National Academy of Sciences, 120(11):e2208839120, 2023
Maurice Jakesch, Jeffrey T Hancock, and Mor Naaman. Human heuristics for ai-generated language are flawed.Proceedings of the National Academy of Sciences, 120(11):e2208839120, 2023
2023
-
[46]
Large language models can consistently generate high-quality content for election disinformation operations.PloS one, 20(3):e0317421, 2025
Angus R Williams, Liam Burke-Moore, Ryan Sze-Yin Chan, Florence E Enock, Federico Nanni, Tvesha Sippy, Yi-Ling Chung, Evelina Gabasova, Kobi Hackenburg, and Jonathan Bright. Large language models can consistently generate high-quality content for election disinformation operations.PloS one, 20(3):e0317421, 2025
2025
-
[47]
Engagement, user satisfaction, and the amplification of divisive content on social media.PNAS nexus, 4(3):pgaf062, 2025
Smitha Milli, Micah Carroll, Yike Wang, Sashrika Pandey, Sebastian Zhao, and Anca D Dragan. Engagement, user satisfaction, and the amplification of divisive content on social media.PNAS nexus, 4(3):pgaf062, 2025
2025
-
[48]
The rapid adoption of generative ai
Alexander Bick, Adam Blandin, and David J Deming. The rapid adoption of generative ai. Management Science, 2026
2026
-
[49]
The labor market effects of generative artificial intelligence.SSRN, 2026
Jonathan S Hartley, Filip Jolevski, Vitor Melo, and Brendan Moore. The labor market effects of generative artificial intelligence.SSRN, 2026. 16
2026
-
[50]
Paul Röttger, Musashi Hinck, Valentin Hofmann, Kobi Hackenburg, Valentina Pyatkin, Faeze Brahman, and Dirk Hovy. Issuebench: Millions of realistic prompts for measuring issue bias in llm writing assistance.arXiv preprint arXiv:2502.08395, 2025
-
[51]
System card: Claude opus 4 & claude sonnet 4.anthropic.com, 2025
Anthropic. System card: Claude opus 4 & claude sonnet 4.anthropic.com, 2025
2025
-
[52]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review arXiv 2024
-
[53]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024. 17
work page internal anchor Pith review arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.