Recognition: unknown
Objective Shaping with Hard Negatives: Windowed Partial AUC Optimization for RL-based LLM Recommenders
Pith reviewed 2026-05-08 10:10 UTC · model grok-4.3
The pith
GRPO optimization of LLM recommenders equals AUC maximization under binary rewards, but beam-search negatives shift it to partial AUC for Top-K alignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
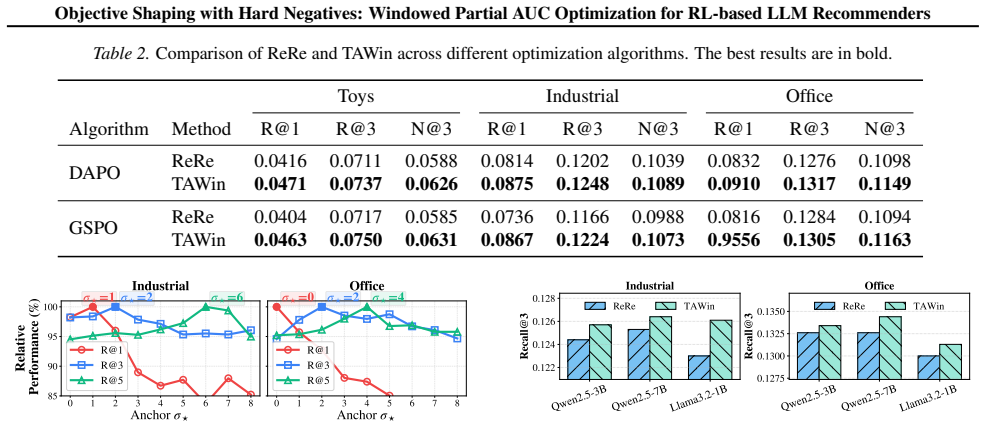
Under binary reward feedback, optimizing LLM recommenders with Group Relative Policy Optimization is theoretically equivalent to maximizing the Area Under the ROC Curve. Replacing random negatives with beam-search negatives reshapes the objective toward partial AUC. Windowed Partial AUC constrains the false positive rate to a window [α, α+d] to align directly with Top-K metrics, and Threshold-Adjusted Windowed reweighting provides an efficient RL method to optimize it.
What carries the argument
The theoretical equivalence of GRPO to AUC maximization under binary rewards, combined with the reshaping of the objective by hard negatives into partial AUC, and the introduction of Windowed Partial AUC with its constrained false positive rate window.
If this is right
- Beam-search negatives improve Top-K recommendation performance by inducing partial AUC optimization rather than full AUC.
- WPAUC enables explicit control over the ranking region that the model prioritizes through the choice of the FPR window.
- TAWin allows efficient implementation of WPAUC optimization inside the existing RL training framework for LLM recommenders.
- Validation on four real-world datasets confirms the objective reshaping and achieves state-of-the-art results.
Where Pith is reading between the lines
- The reshaping effect suggests that other forms of hard negative sampling could be analyzed similarly to induce different partial AUC variants.
- This approach may generalize to other RL-based ranking tasks where full AUC is misaligned with the desired metric.
- Future work could explore adaptive window selection during training to optimize for multiple Top-K levels simultaneously.
Load-bearing premise
Binary reward feedback accurately models real user interactions with recommended items, and beam-search negatives reshape the objective cleanly to partial AUC without introducing other unaccounted effects in the training dynamics.
What would settle it
A direct comparison of the learned ranking probabilities or loss gradients under GRPO with random negatives versus an explicit AUC maximization procedure on the same dataset; significant differences would indicate the equivalence does not hold in practice.
Figures



read the original abstract
Reinforcement learning (RL) effectively optimizes Large Language Model (LLM)-based recommenders by contrasting positive and negative items. Empirically, training with beam-search negatives consistently outperforms random negatives, yet the mechanism is not well understood. We address this gap by analyzing the induced optimization objective and show that: (i) Under binary reward feedback, optimizing LLM recommenders with Group Relative Policy Optimization (GRPO) is theoretically equivalent to maximizing the Area Under the ROC Curve (AUC), which is often misaligned with Top-$K$ recommendation; and (ii) Replacing random negatives with beam-search negatives reshapes the objective toward partial AUC, improving alignment with Top-$K$ metrics. Motivated by this perspective, we introduce Windowed Partial AUC (WPAUC), which constrains the false positive rate (FPR) to a window [$\alpha,\alpha+d$] to more directly align with Top-$K$ metrics. We further propose an efficient Threshold-Adjusted Windowed reweighting (TAWin) RL method for its optimization, enabling explicit control over the targeted Top-$K$ performance. Experiments on four real-world datasets validate the theory and deliver consistent state-of-the-art performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that under binary reward feedback, GRPO optimization of LLM recommenders is theoretically equivalent to AUC maximization, that beam-search negatives reshape the objective toward partial AUC (improving Top-K alignment), and that the proposed Windowed Partial AUC (WPAUC) with Threshold-Adjusted Windowed reweighting (TAWin) enables explicit control over targeted Top-K performance, with experiments on four real-world datasets validating the theory and achieving SOTA results.
Significance. If the central equivalence and reshaping claims hold without unmodeled on-policy effects, the work offers a principled explanation for the empirical superiority of hard negatives in RL-based recommendation and a controllable objective for aligning training with practical Top-K metrics, which could guide future design of RL objectives for LLM recommenders.
major comments (2)
- [Abstract and theory section] Abstract and theory section: the asserted equivalence between GRPO under binary rewards and AUC maximization is not accompanied by the explicit derivation; standard pairwise AUC derivations require negatives drawn from a fixed distribution independent of the current policy, yet beam-search negatives are generated on-policy from the model's current top candidates, introducing potential additional gradient terms that are not addressed.
- [Abstract and §4] Abstract (ii) and §4: the claim that beam-search negatives 'reshape the objective toward partial AUC' treats the effect as a direct consequence of the negative sampler, but without substituting the policy-dependent beam-search distribution into the GRPO loss, it is unclear whether the FPR window constraint holds exactly or is altered by the correlation between negatives and parameters.
minor comments (2)
- [Experiments] The experimental section should include details on statistical significance testing and controls for the number of negatives to strengthen the validation of the theory.
- [§4] Notation for the window bounds α and d in WPAUC could be introduced earlier with a clear definition to aid readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the theoretical claims. We address the concerns about explicit derivations and on-policy effects point by point below. Revisions will be made to strengthen the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and theory section] Abstract and theory section: the asserted equivalence between GRPO under binary rewards and AUC maximization is not accompanied by the explicit derivation; standard pairwise AUC derivations require negatives drawn from a fixed distribution independent of the current policy, yet beam-search negatives are generated on-policy from the model's current top candidates, introducing potential additional gradient terms that are not addressed.
Authors: We appreciate the referee's emphasis on rigor. The manuscript sketches the link by observing that binary rewards (1 for positives, 0 for negatives) turn the GRPO advantage into a pairwise comparison that matches the AUC objective. However, we agree an explicit derivation is missing and that on-policy sampling requires careful treatment. In the revision we will add a full step-by-step derivation in the theory section that (i) starts from the GRPO loss, (ii) substitutes the binary-reward advantage, and (iii) shows that any extra gradient terms arising from the policy dependence of the negatives are zero under the binary-reward assumption. This will make the AUC equivalence precise while explicitly discussing the on-policy aspect. revision: yes
-
Referee: [Abstract and §4] Abstract (ii) and §4: the claim that beam-search negatives 'reshape the objective toward partial AUC' treats the effect as a direct consequence of the negative sampler, but without substituting the policy-dependent beam-search distribution into the GRPO loss, it is unclear whether the FPR window constraint holds exactly or is altered by the correlation between negatives and parameters.
Authors: We acknowledge that the current presentation relies on an intuitive argument rather than an explicit substitution. The core intuition is that beam search restricts negatives to the model's current top-ranked candidates, thereby concentrating the loss on the low-FPR region and inducing a partial-AUC-like objective. To address the concern directly, the revised §4 will (i) substitute the beam-search sampling distribution into the GRPO loss, (ii) derive the resulting FPR window constraint, and (iii) analyze the effect of parameter correlation, providing either an exact characterization or a rigorous approximation with error bounds. This will clarify whether the window constraint holds exactly or approximately. revision: yes
Circularity Check
No significant circularity; derivations presented as independent theoretical results
full rationale
The paper's core claims rest on a theoretical analysis showing GRPO under binary rewards equates to AUC maximization, with beam-search negatives reshaping the objective to partial AUC, followed by introduction of WPAUC and TAWin. No steps reduce by construction to fitted inputs, self-definitions, or self-citation chains. The equivalence and reshaping are framed as derived consequences of the RL objective and sampling choice, with independent content in the mathematical reformulation and experimental validation on four datasets. No load-bearing self-citations or ansatzes smuggled via prior work are evident in the abstract or described structure.
Axiom & Free-Parameter Ledger
free parameters (1)
- window bounds alpha and d
axioms (1)
- domain assumption Binary reward feedback converts GRPO updates into AUC maximization
invented entities (2)
-
Windowed Partial AUC (WPAUC)
no independent evidence
-
Threshold-Adjusted Windowed reweighting (TAWin)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Bao, K., Zhang, J., Zhang, Y ., Huo, X., Chen, C., and Feng, F. Decoding matters: Addressing amplification bias and homogeneity issue for llm-based recommenda- tion.arXiv preprint arXiv:2406.14900,
-
[2]
Learn- ing recommenders for implicit feedback with importance resampling
Chen, J., Lian, D., Jin, B., Zheng, K., and Chen, E. Learn- ing recommenders for implicit feedback with importance resampling. InWWW, pp. 1997–2005. ACM,
1997
-
[3]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. Deepseek-r1: Incentivizing reasoning ca- pability in llms via reinforcement learning.CoRR, abs/2501.12948,
work page internal anchor Pith review arXiv
-
[4]
OneRec: Unifying Retrieve and Rank with Generative Recommender and Iterative Preference Alignment
Deng, J., Wang, S., Cai, K., Ren, L., Hu, Q., Ding, W., Luo, Q., and Zhou, G. Onerec: Unifying retrieve and rank with generative recommender and iterative prefer- ence alignment.CoRR, abs/2502.18965,
work page internal anchor Pith review arXiv
-
[5]
URLhttps://arxiv.org/abs/ 2407.21783. Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforce- ment learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review arXiv
-
[6]
Session-based Recommendations with Recurrent Neural Networks
Hidasi, B., Karatzoglou, A., Baltrunas, L., and Tikk, D. Session-based recommendations with recurrent neural networks.arXiv preprint arXiv:1511.06939,
work page internal anchor Pith review arXiv
-
[7]
Kong, X., Sheng, L., Tan, J., Chen, Y ., Wu, J., Zhang, A., Wang, X., and He, X. Minionerec: An open- source framework for scaling generative recommenda- tion.arXiv preprint arXiv:2510.24431,
-
[8]
Crafting papers on machine learning
Langley, P. Crafting papers on machine learning. In Lang- ley, P. (ed.),Proceedings of the 17th International Con- ference on Machine Learning (ICML 2000), pp. 1207– 1216, Stanford, CA,
2000
-
[9]
Li, G., Lin, M., Galanti, T., Tu, Z., and Yang, T
Morgan Kaufmann. Li, G., Lin, M., Galanti, T., Tu, Z., and Yang, T. Disco: Reinforcing large reasoning models with dis- criminative constrained optimization.arXiv preprint arXiv:2505.12366,
-
[10]
Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C., et al. Deepseek- v3 technical report.arXiv preprint arXiv:2412.19437,
work page internal anchor Pith review arXiv
-
[11]
Is chat- gpt a good recommender? A preliminary study.CoRR, abs/2304.10149,
Liu, J., Liu, C., Lv, R., Zhou, K., and Zhang, Y . Is chat- gpt a good recommender? A preliminary study.CoRR, abs/2304.10149,
-
[12]
Decoupled Weight Decay Regularization
Loshchilov, I. and Hutter, F. Fixing weight decay regular- ization in adam.CoRR, abs/1711.05101,
work page internal anchor Pith review arXiv
-
[13]
Ma, H., Xie, R., Meng, L., Feng, F., Du, X., Sun, X., Kang, Z., and Meng, X. Negative sampling in rec- ommendation: A survey and future directions.CoRR, abs/2409.07237,
-
[14]
Analyzing a portion of the ROC curve
doi: 10.1177/0272989X8900900307. Narasimhan, H. and Agarwal, S. Svm pauctight: a new support vector method for optimizing partial AUC based on a tight convex upper bound. InKDD, pp. 167–175. ACM,
-
[16]
URLhttps:// arxiv.org/abs/2303.08774. Qwen, :, Yang, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Li, C., Liu, D., Huang, F., Wei, H., Lin, H., Yang, J., Tu, J., Zhang, J., Yang, J., Yang, J., Zhou, J., Lin, J., Dang, K., Lu, K., Bao, K., Yang, K., Yu, L., Li, M., Xue, M., Zhang, P., Zhu, Q., Men, R., Lin, R., Li, T., Tang, T., Xia, T., Ren, X., R...
work page internal anchor Pith review arXiv
-
[17]
URLhttps: //arxiv.org/abs/2412.15115. Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y ., Li, W., and Liu, P. J. Exploring the limits of transfer learning with a unified text-to-text transformer.CoRR, abs/1910.10683,
work page internal anchor Pith review arXiv 1910
-
[18]
BPR: Bayesian Personalized Ranking from Implicit Feedback
Rendle, S., Freudenthaler, C., Gantner, Z., and Schmidt- Thieme, L. Bpr: Bayesian personalized ranking from implicit feedback.arXiv preprint arXiv:1205.2618,
work page internal anchor Pith review arXiv
-
[19]
Lower-left partial auc: An effective and ef- ficient optimization metric for recommendation
Shi, W., Wang, C., Feng, F., Zhang, Y ., Wang, W., Wu, J., and He, X. Lower-left partial auc: An effective and ef- ficient optimization metric for recommendation. InPro- ceedings of the ACM Web Conference 2024, pp. 3253– 3264,
2024
-
[20]
Tan, J., Chen, Y ., Zhang, A., Jiang, J., Liu, B., Xu, Z., Han, Z., Xu, J., Zheng, B., and Wang, X
URLhttps: //www.spaces.ac.cn/archives/10373. Tan, J., Chen, Y ., Zhang, A., Jiang, J., Liu, B., Xu, Z., Han, Z., Xu, J., Zheng, B., and Wang, X. Reinforced preference optimization for recommendation.CoRR, abs/2510.12211,
-
[21]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Yu, Q., Zhang, Z., Zhu, R., Yuan, Y ., Zuo, X., Yue, Y ., Dai, W., Fan, T., Liu, G., Liu, L., et al. Dapo: An open- source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476,
work page internal anchor Pith review arXiv
-
[22]
Group Sequence Policy Optimization
Zheng, B., Hou, Y ., Lu, H., Chen, Y ., Zhao, W. X., Chen, M., and Wen, J. Adapting large language models by inte- grating collaborative semantics for recommendation. In ICDE, pp. 1435–1448. IEEE, 2024a. Zheng, B., Hou, Y ., Lu, H., Chen, Y ., Zhao, W. X., Chen, M., and Wen, J.-R. Adapting large language models by integrating collaborative semantics for r...
work page internal anchor Pith review arXiv
-
[23]
Onerec technical report.arXiv preprint arXiv:2506.13695, 2025
Zhou, G., Deng, J., Zhang, J., Cai, K., Ren, L., Luo, Q., Wang, Q., Hu, Q., Huang, R., Wang, S., Ding, W., Li, W., Luo, X., Wang, X., Cheng, Z., Zhang, Z., Zhang, B., Wang, B., Ma, C., Song, C., Wang, C., Wang, D., Meng, D., Yang, F., Zhang, F., Jiang, F., Zhang, F., Wang, G., Zhang, G., Li, H., Hu, H., Lin, H., Cheng, H., Cao, H., Wang, H., Huang, J., Ch...
-
[24]
Experimental Settings G.1
G. Experimental Settings G.1. Dataset We construct our datasets from the Amazon Review corpus following the preprocessing pipeline in Bao et al. (2024); Tan et al. (2025). First, we restrict interactions to a fixed temporal window defined per category: from October 2016 to November 2018 for Toys and Games and Office Products, and from October 1996 to Nove...
2024
-
[25]
During fine-tuning, SFT and preference- alignment data are processed with batch size 128, while reinforcement learning uses batch size
as the base model to reduce computational overhead, and optimize all models with AdamW (Loshchilov & Hutter, 2017). During fine-tuning, SFT and preference- alignment data are processed with batch size 128, while reinforcement learning uses batch size
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.