Recognition: unknown
ICPR 2026 Competition on Low-Resolution License Plate Recognition
Pith reviewed 2026-05-08 12:38 UTC · model grok-4.3
The pith
The first low-resolution license plate recognition competition yields a top score of 82.13% on real-world data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
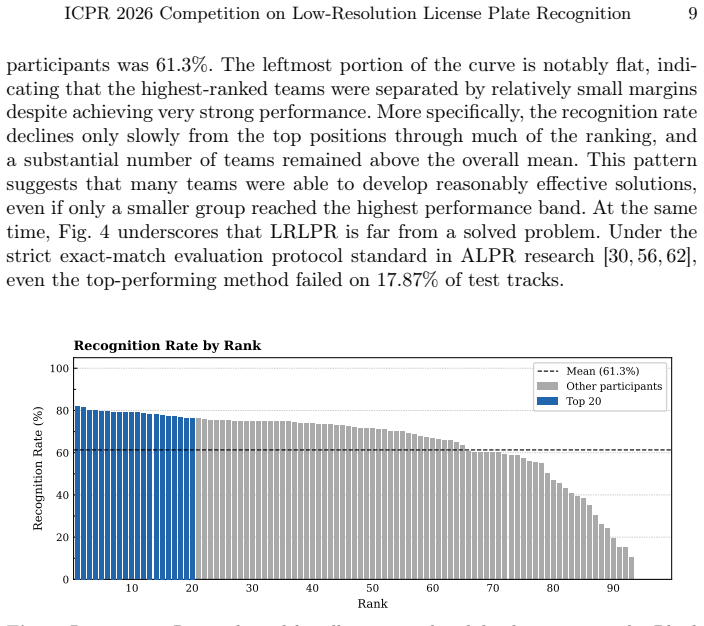
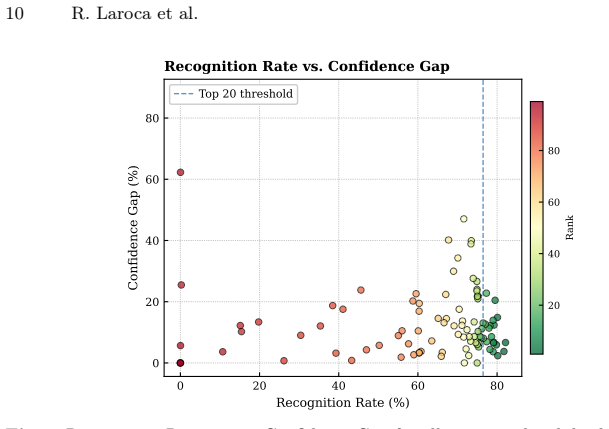
Organized as the first competition focused on low-resolution license plate recognition with real data, the event demonstrates that despite substantial participation from 269 registered teams across 41 countries, the highest recognition rate on the blind test set reached only 82.13%.
What carries the argument
The LRLPR-26 dataset and its track-based evaluation protocol, which pairs multiple low- and high-resolution images per license plate to test methods under operational degradation.
If this is right
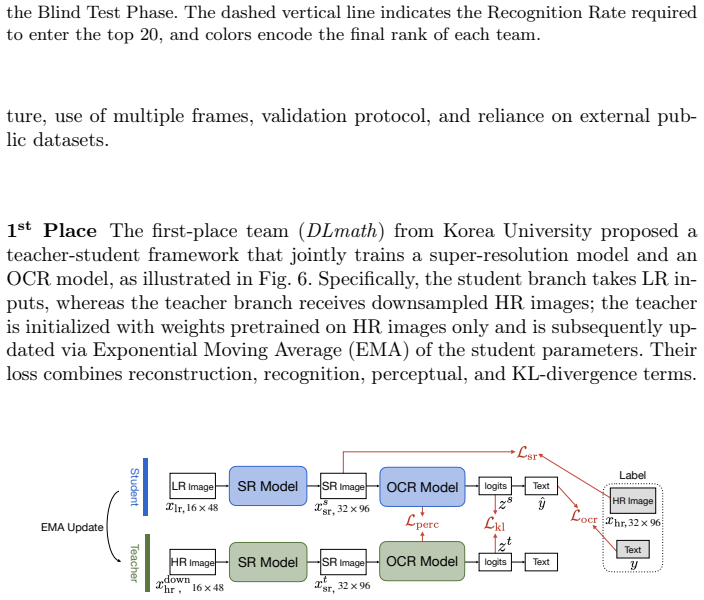
- Methods that effectively fuse information from the five low-resolution frames per track performed best.
- Handling compression artifacts and adverse conditions remains a key challenge for further improvements.
- The summary of top approaches highlights the use of deep learning models adapted for low-quality inputs.
- Continued progress will likely require new techniques beyond current state-of-the-art to close the gap to 100% accuracy.
Where Pith is reading between the lines
- This benchmark may encourage the creation of more robust models that perform well across different surveillance setups.
- Future work could explore integrating the high-resolution images more directly into test-time inference if available.
- The high number of participants indicates growing practical interest in improving automatic plate reading for security applications.
Load-bearing premise
The LRLPR-26 dataset and evaluation protocol accurately capture the distribution of real-world low-resolution license plate images encountered in operational surveillance scenarios.
What would settle it
Re-evaluating the winning methods on license plate images from a different set of cameras or locations that were not represented in the competition data would show whether the 82.13% rate generalizes or drops.
Figures






read the original abstract
Low-Resolution License Plate Recognition (LRLPR) remains a challenging problem in real-world surveillance scenarios, where long capture distances, compression artifacts, and adverse imaging conditions can severely degrade license plate legibility. To promote progress in this area, we organized the ICPR 2026 Competition on Low-Resolution License Plate Recognition, the first competition specifically dedicated to LRLPR using real low-quality data collected under operationally relevant conditions. The competition was based on the LRLPR-26 dataset, which comprises 20,000 training tracks and 3,000 test tracks; each training track contains five low-resolution and five high-resolution images of the same license plate. Notably, a total of 269 teams from 41 countries registered for the competition, and 99 teams submitted valid entries in the Blind Test Phase. The winning team achieved a Recognition Rate of 82.13%, and four teams surpassed the 80% mark, highlighting both the high level of competition at the top of the leaderboard and the continued difficulty of the task. In addition to presenting the competition design, evaluation protocol, and main results, this paper summarizes the methods adopted by the top-5 teams and discusses current trends and promising directions for future research on LRLPR. The competition webpage is available at https://icpr26lrlpr.github.io/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports on the organization of the ICPR 2026 Competition on Low-Resolution License Plate Recognition. It introduces the LRLPR-26 dataset (20,000 training tracks each containing five low-resolution and five high-resolution images of the same plate, plus 3,000 test tracks), documents participation (269 teams from 41 countries registered, 99 valid blind-test submissions), states that the winning team reached a recognition rate of 82.13% with four teams above 80%, summarizes the methods of the top-5 teams, and discusses trends and future directions for LRLPR.
Significance. If the reported facts hold, the paper supplies a concrete, publicly documented benchmark and dataset for low-resolution license plate recognition under operationally relevant conditions. The verifiable participation statistics, submission counts, and leaderboard results provide a clear snapshot of current performance levels and field interest. Credit is given for the factual, non-derivational reporting style and for releasing the competition webpage, which together offer a reusable reference for researchers working on surveillance imagery degraded by distance, compression, and adverse conditions.
minor comments (1)
- [Abstract and §4] The abstract and results section could explicitly state the precise definition of the Recognition Rate metric (e.g., character-level accuracy threshold or full-plate match) to make the 82.13% figure immediately interpretable without consulting the competition webpage.
Simulated Author's Rebuttal
We thank the referee for the positive review, accurate summary of the manuscript, and recommendation to accept. The report correctly identifies the key elements of the ICPR 2026 LRLPR competition, including the dataset design, participation statistics, results, and future directions.
Circularity Check
No significant circularity: purely descriptive competition report
full rationale
The paper is a factual competition summary documenting dataset construction (LRLPR-26 with 20k training and 3k test tracks), registration statistics (269 teams, 99 submissions), evaluation protocol, and observed leaderboard outcomes (top RR 82.13%). No derivations, equations, fitted parameters, predictions, or modeling steps exist. Claims rest on direct event results rather than self-referential definitions or unverified self-citations. The interpretive note on task difficulty follows immediately from the reported scores without circular reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aharon, N., Orfaig, R., Bobrovsky, B.Z.: BoT-SORT: Robust associations multi- pedestrian tracking. arXiv preprint arXiv:2104.07636 pp. 1–13 (2022)
-
[2]
In: IEEE/CVF International Conference on Computer Vision (ICCV)
Baek, J., Kim, G., Lee, J., Park, S., Han, D., Yun, S., Oh, S.J., Lee, H.: What is wrong with scene text recognition model comparisons? dataset and model analysis. In: IEEE/CVF International Conference on Computer Vision (ICCV). pp. 4714– 4722 (2019).https://doi.org/10.1109/ICCV.2019.00481
-
[3]
In: European Conference on Computer Vision (ECCV)
Bautista, D., Atienza, R.: Scene text recognition with permuted autoregressive sequence models. In: European Conference on Computer Vision (ECCV). pp. 178– 196 (2022).https://doi.org/10.1007/978-3-031-19815-1_11
-
[4]
In: European Conference on Computer Vision (ECCV)
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S.: End-to-end object detection with transformers. In: European Conference on Computer Vision (ECCV). pp. 213–229 (2020).https://doi.org/10.1007/ 978-3-030-58452-8_13
2020
-
[5]
Chen, X., Wang, X., Zhang, W., Kong, X., Qiao, Y., Zhou, J., Dong, C.: HAT: Hybrid attention transformer for image restoration. IEEE Transactions on Pattern Analysis and Machine Intelligence48(3), 2676–2694 (2026).https://doi.org/10. 1109/TPAMI.2025.3628275
-
[6]
Ev-flying: An event-based dataset for in-the-wild recognition of flying objects
Chen, Z., et al.: NTIRE 2025 challenge on image super-resolution (×4): Methods and results. In: IEEE/CVF Conference on Computer Vision and Pattern Recog- nition Workshops (CVPRW). pp. 1516–1526 (2025).https://doi.org/10.1109/ CVPRW67362.2025.00141
-
[7]
In: International Joint Conference on Neural Networks (IJCNN)
Coluccia, A., Fascista, A., Dimou, A., Zarpalas, D., Sommer, L., Schumann, A., Mele, E.: The drone-vs-bird detection grand challenge at IJCNN 2025. In: International Joint Conference on Neural Networks (IJCNN). pp. 1–8 (2025). https://doi.org/10.1109/IJCNN64981.2025.11228314
-
[8]
Multimedia Tools and Applications82(6), 9243–9275 (2023).https://doi.org/10.1007/ s11042-022-13644-y
Diwan, T., Anirudh, G., Tembhurne, J.V.: Object detection using YOLO: challenges, architectural successors, datasets and applications. Multimedia Tools and Applications82(6), 9243–9275 (2023).https://doi.org/10.1007/ s11042-022-13644-y
2023
-
[9]
In: International Joint Confer- ence on Artificial Intelligence (IJCAI)
Du, Y., Chen, Z., Jia, C., Yin, X., Zheng, T., Li, C., Du, Y., Jiang, Y.G.: SVTR: Scene text recognition with a single visual model. In: International Joint Confer- ence on Artificial Intelligence (IJCAI). pp. 884–890 (2022).https://doi.org/10. 24963/ijcai.2022/124
2022
-
[10]
In: IEEE/CVF International Conference on Computer Vision (ICCV)
Du, Y., Chen, Z., Xie, H., Jia, C., Jiang, Y.G.: SVTRv2: CTC beats encoder- decoder models in scene text recognition. In: IEEE/CVF International Conference on Computer Vision (ICCV). pp. 20147–20156 (Oct 2025)
2025
-
[11]
In: AAAI Conference on Artificial Intelli- gence
Du, Y., Zhao, M., Fan, S., Chen, Z., Jia, C., Jiang, Y.G.: MDiff4STR: Mask dif- fusion model for scene text recognition. In: AAAI Conference on Artificial Intelli- gence. pp. 3705–3713 (Mar 2026).https://doi.org/10.1609/aaai.v40i5.37370
-
[12]
Gonçalves, G.R., Diniz, M.A., Laroca, R., Menotti, D., Schwartz, W.R.: Real- time automatic license plate recognition through deep multi-task networks. In: ICPR 2026 Competition on Low-Resolution License Plate Recognition 17 Conference on Graphics, Patterns and Images (SIBGRAPI). pp. 110–117 (Oct 2018).https://doi.org/10.1109/SIBGRAPI.2018.00021
-
[13]
In: Iberoamerican Congress on Pattern Recognition (CIARP)
Gonçalves, G.R., Diniz, M.A., Laroca, R., Menotti, D., Schwartz, W.R.: Multi-task learning for low-resolution license plate recognition. In: Iberoamerican Congress on Pattern Recognition (CIARP). pp. 251–261 (Oct 2019).https://doi.org/10. 1007/978-3-030-33904-3_23
2019
-
[14]
In: International Joint Conference on Artificial Intelligence (IJCAI)
Gong, H., Feng, Y., Zhang, Z., Hou, X., Liu, J., Huang, S., Liu, H.: A dataset and model for realistic license plate deblurring. In: International Joint Conference on Artificial Intelligence (IJCAI). pp. 1–9 (2024).https://doi.org/10.24963/ ijcai.2024/86
2024
-
[15]
In: IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR)
Gong, H., Zhang, Z., Feng, Y., Nguyen, A., Liu, H.: LP-Diff: Towards improved restoration of real-world degraded license plate. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 17831–17840 (2025). https://doi.org/10.1109/CVPR52734.2025.01661
-
[16]
In: International Conference on Machine Learning (ICML)
Graves, A., Fernández, S., Gomez, F., Schmidhuber, J.: Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural net- works. In: International Conference on Machine Learning (ICML). pp. 369–376 (2006).https://doi.org/10.1145/1143844.1143891
-
[17]
In: IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR)
Guo, H., Guo, Y., Zha, Y., Zhang, Y., Li, W., Dai, T., Xia, S.T., Li, Y.: Mam- baIRv2: Attentive state space restoration. In: IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR). pp. 28124–28133 (2025).https: //doi.org/10.1109/CVPR52734.2025.02619
-
[18]
In: European Conference on Computer Vision (ECCV)
Guo, H., Li, J., Dai, T., Ouyang, Z., Ren, X., Xia, S.T.: MambaIR: A simple baseline for image restoration with state-space model. In: European Conference on Computer Vision (ECCV). pp. 222–241 (2025).https://doi.org/10.1007/ 978-3-031-72649-1_13
2025
-
[19]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
He, T., Zhang, Z., Zhang, H., Zhang, Z., Xie, J., Li, M.: Bag of tricks for image classification with convolutional neural networks. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 558–567 (2019).https: //doi.org/10.1109/CVPR.2019.00065
-
[20]
Hsu, G.S., Chen, J.C., Chung, Y.Z.: Application-oriented license plate recognition. IEEE Transactions on Vehicular Technology62(2), 552–561 (Feb 2013).https: //doi.org/10.1109/TVT.2012.2226218
-
[21]
In: IEEE/CVF Con- ference on Computer Vision and Pattern Recognition
Hu, J., Shen, L., Sun, G.: Squeeze-and-excitation networks. In: IEEE/CVF Con- ference on Computer Vision and Pattern Recognition. pp. 7132–7141 (2018). https://doi.org/10.1109/CVPR.2018.00745
-
[22]
Hugging Face model hub (2025), timm-remapped image-encoder-only variant
Hugging Face: Model card and pretrained weights for pe-core-l-14-336. Hugging Face model hub (2025), timm-remapped image-encoder-only variant
2025
-
[23]
IEEE Access13, 145387–145415 (2025).https://doi.org/ 10.1109/ACCESS.2025.3598971
Ismail, A., Mehri, M., Sahbani, A., Essoukri Ben Amara, N.: Automatic license plate recognition in in-the-wild scenarios: A comprehensive review, open issues, and future directions. IEEE Access13, 145387–145415 (2025).https://doi.org/ 10.1109/ACCESS.2025.3598971
-
[24]
In: International Conference on Neural Information Processing Systems (NeurIPS)
Jaderberg, M., Simonyan, K., Zisserman, A., Kavukcuoglu, K.: Spatial trans- former networks. In: International Conference on Neural Information Processing Systems (NeurIPS). pp. 2017–2025 (2015)
2017
-
[25]
In: 2023 IEEE/CVF International Conference on Computer Vision (ICCV)
Jiang, Q., Wang, J., Peng, D., Liu, C., Jin, L.: Revisiting scene text recogni- tion: A data perspective. In: IEEE/CVF International Conference on Computer Vision (ICCV). pp. 20486–20497 (2023).https://doi.org/10.1109/ICCV51070. 2023.01878 18 R. Laroca et al
-
[26]
Ke, X., Zeng, G., Guo, W.: An ultra-fast automatic license plate recognition ap- proach for unconstrained scenarios. IEEE Transactions on Intelligent Transporta- tion Systems24(5), 5172–5185 (2023).https://doi.org/10.1109/TITS.2023. 3237581
-
[27]
Kim, D., Kim, J., Park, E.: AFA-Net: Adaptive feature attention network in image deblurring and super-resolution for improving license plate recognition. Computer Vision and Image Understanding238, 103879 (2024).https://doi.org/10.1016/ j.cviu.2023.103879
-
[28]
Laroca, R., Cardoso, E.V., Lucio, D.R., Estevam, V., Menotti, D.: On the cross- dataset generalization in license plate recognition. In: International Conference on Computer Vision Theory and Applications (VISAPP). pp. 166–178 (Feb 2022). https://doi.org/10.5220/0010846800003124
-
[29]
Latent Space Alignment for AI -Native MIMO Semantic Communications,
Laroca, R., dos Santos, M., Menotti, D.: Improving small drone detection through multi-scale processing and data augmentation. In: International Joint Conference on Neural Networks (IJCNN). pp. 1–8 (June 2025).https://doi.org/10.1109/ IJCNN64981.2025.11227421
-
[30]
In: In- ternational Joint Conference on Neural Networks (IJCNN)
Laroca, R., Estevam, V., Britto Jr., A.S., Minetto, R., Menotti, D.: Do we train on test data? The impact of near-duplicates on license plate recognition. In: In- ternational Joint Conference on Neural Networks (IJCNN). pp. 1–8 (June 2023). https://doi.org/10.1109/IJCNN54540.2023.10191584
-
[31]
In: International Joint Conference on Neural Networks (IJCNN)
Laroca, R., Severo, E., Zanlorensi, L.A., Oliveira, L.S., Gonçalves, G.R., Schwartz, W.R., Menotti, D.: A robust real-time automatic license plate recognition based on the YOLO detector. In: International Joint Conference on Neural Networks (IJCNN). pp. 1–10 (July 2018).https://doi.org/10.1109/IJCNN.2018.8489629
-
[32]
In: Iberoamerican Congress on Pattern Recognition (CIARP)
Laroca, R., Zanlorensi, L.A., Estevam, V., Minetto, R., Menotti, D.: Leveraging model fusion for improved license plate recognition. In: Iberoamerican Congress on Pattern Recognition (CIARP). pp. 60–75 (Nov 2023).https://doi.org/10.1007/ 978-3-031-49249-5_5
2023
-
[33]
Laroca, R., Zanlorensi, L.A., Gonçalves, G.R., Todt, E., Schwartz, W.R., Menotti, D.: An efficient and layout-independent automatic license plate recognition system based on the YOLO detector. IET Intelligent Transport Systems15(4), 483–503 (2021).https://doi.org/10.1049/itr2.12030
-
[34]
https://doi.org/10.1049/itr2.70086
Laroca, R., Estevam, V., Moreira, G.J.P., Minetto, R., Menotti, D.: Advancing multinational license plate recognition through synthetic and real data fusion: A comprehensiveevaluation.IETIntelligentTransportSystems19(1),e70086(2025). https://doi.org/10.1049/itr2.70086
-
[35]
Journal of the Brazilian Computer Society32(1), 783–799 (2026)
Lima, G.E., Nascimento, V., Santos, E., Nascimento Jr., E., Laroca, R., Menotti, D.: Toward unified fine-grained vehicle classification and automatic license plate recognition. Journal of the Brazilian Computer Society32(1), 783–799 (2026). https://doi.org/10.5753/jbcs.2026.5899
-
[36]
In: International Conference on Multimedia Modeling
Liu,Y.Y.,Liu,Q.,Chen,F.,Yin,X.C.:Irregularlicenseplaterecognitionviaglobal information integration. In: International Conference on Multimedia Modeling. pp. 325–339 (2024).https://doi.org/10.1007/978-3-031-53308-2_24
-
[37]
In: International Conference on Learning Representations (ICLR)
Loshchilov, I., Hutter, F.: SGDR: Stochastic gradient descent with warm restarts. In: International Conference on Learning Representations (ICLR). pp. 1–16 (2017)
2017
-
[38]
In: International Conference on Learning Representations (ICLR)
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. In: International Conference on Learning Representations (ICLR). pp. 1–19 (2019)
2019
-
[39]
In: IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS)
Maier, A., Moussa, D., Spruck, A., Seiler, J., Riess, C.: Reliability scoring for the recognition of degraded license plates. In: IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS). pp. 1–8 (2022).https: //doi.org/10.1109/AVSS56176.2022.9959390 ICPR 2026 Competition on Low-Resolution License Plate Recognition 19
-
[40]
In: International Conference on Learning Representations (ICLR)
Micikevicius, P., et al.: Mixed precision training. In: International Conference on Learning Representations (ICLR). pp. 1–12 (2018)
2018
-
[41]
In: IEEE International Conference on Image Processing (ICIP)
Moussa, D., Maier, A., Spruck, A., Seiler, J., Riess, C.: Forensic license plate recog- nition with compression-informed transformers. In: IEEE International Conference on Image Processing (ICIP). pp. 406–410 (Oct 2022).https://doi.org/10.1109/ ICIP46576.2022.9897178
-
[42]
Na, K., Oh, J., Cho, Y., Kim, B., Cho, S., Choi, J., Kim, I.: MF-LPR2: Multi- frame license plate image restoration and recognition using optical flow. Computer Vision and Image Understanding256, 104361 (2025).https://doi.org/10.1016/ j.cviu.2025.104361
-
[43]
In: Con- ference on Graphics, Patterns and Images (SIBGRAPI)
Nascimento, V., Laroca, R., Lambert, J.A., Schwartz, W.R., Menotti, D.: Combin- ing attention module and pixel shuffle for license plate super-resolution. In: Con- ference on Graphics, Patterns and Images (SIBGRAPI). pp. 228–233 (Oct 2022). https://doi.org/10.1109/SIBGRAPI55357.2022.9991753
-
[44]
Nascimento, V., Laroca, R., Ribeiro, R.O., Schwartz, W.R., Menotti, D.: En- hancing license plate super-resolution: A layout-aware and character-driven ap- proach. Conference on Graphics, Patterns and Images (SIBGRAPI) pp. 1–6 (2024). https://doi.org/10.1109/SIBGRAPI62404.2024.10716303
-
[45]
Nascimento, V., Lima, G.E., Ribeiro, R.O., Schwartz, W.R., Laroca, R., Menotti, D.: Toward advancing license plate super-resolution in real-world scenarios: A dataset and benchmark. Journal of the Brazilian Computer Society1(31), 435– 449 (2025).https://doi.org/10.5753/jbcs.2025.5159
-
[46]
IEEE Access9, 101065–101077 (2021).https://doi.org/10
Oliveira, I.O., Laroca, R., Menotti, D., Fonseca, K.V.O., Minetto, R.: Vehicle-Rear: Anewdatasettoexplorefeaturefusionforvehicleidentificationusingconvolutional neural networks. IEEE Access9, 101065–101077 (2021).https://doi.org/10. 1109/ACCESS.2021.3097964
-
[47]
arXiv preprint arXiv:2110.11314 (2021)
Olpadkar, K., Gavas, E.: Center loss regularization for continual learning. arXiv preprint arXiv:2110.11314 (2021)
-
[48]
OpenALPR: OpenALPR-BR dataset.https://github.com/openalpr/ benchmarks/tree/master/endtoend/br(2016)
2016
-
[49]
Transactions on Machine Learning Research (2024),https://openreview.net/ forum?id=a68SUt6zFt
Oquab, M., et al.: DINOv2: Learning robust visual features without supervision. Transactions on Machine Learning Research (2024),https://openreview.net/ forum?id=a68SUt6zFt
2024
-
[50]
Neurocomputing580, 127426 (2024)
Pan, Y., Tang, J., Tjahjadi, T.: LPSRGAN: Generative adversarial networks for super-resolution of license plate image. Neurocomputing580, 127426 (2024). https://doi.org/10.1016/j.neucom.2024.127426
-
[51]
Ex- pert Systems with Applications243, 122878 (2024).https://doi.org/10.1016/ j.eswa.2023.122878
Rao, Z., Yang, D., Chen, N., Liu, J.: License plate recognition system in un- constrained scenes via a new image correction scheme and improved CRNN. Ex- pert Systems with Applications243, 122878 (2024).https://doi.org/10.1016/ j.eswa.2023.122878
-
[52]
In: Medical Image Compu ting and Computer-Assisted Intervention – MICCAI 2015
Ronneberger, O., Fischer, P., Brox, T.: U-Net: Convolutional networks for biomed- ical image segmentation. In: International Conference on Medical Image Comput- ing and Computer Assisted Intervention (MICCAI). pp. 234–241 (2015).https: //doi.org/10.1007/978-3-319-24574-4_28
-
[53]
IEEE Transactions on In- telligent Transportation Systems24(9), 9203–9216 (2023).https://doi.org/10
Schirrmacher, F., Lorch, B., Maier, A., Riess, C.: Benchmarking probabilistic deep learning methods for license plate recognition. IEEE Transactions on In- telligent Transportation Systems24(9), 9203–9216 (2023).https://doi.org/10. 1109/TITS.2023.3278533
-
[54]
Shi, B., Bai, X., Yao, C.: An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE Transac- 20 R. Laroca et al. tions on Pattern Analysis and Machine Intelligence39(11), 2298–2304 (Nov 2017). https://doi.org/10.1109/TPAMI.2016.2646371
-
[55]
In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Shrivastava, A., Gupta, A., Girshick, R.: Training region-based object detectors with online hard example mining. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 761–769 (2016).https://doi.org/10.1109/ CVPR.2016.89
2016
-
[56]
Silva, S.M., Jung, C.R.: A flexible approach for automatic license plate recogni- tion in unconstrained scenarios. IEEE Transactions on Intelligent Transportation Systems23(6), 5693–5703 (2022).https://doi.org/10.1109/TITS.2021.3055946
-
[57]
Siméoni, O., et al.: DINOv3. arXiv preprint arXiv:2508.10104 pp. 1–67 (2025)
work page internal anchor Pith review arXiv 2025
-
[58]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Sun, K., Xiao, B., Liu, D., Wang, J.: Deep high-resolution representation learning for human pose estimation. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 5686–5696 (2019).https://doi.org/10.1109/ CVPR.2019.00584
-
[59]
Machine Learning and Knowledge Extraction5(4), 1680–1716 (2023)
Terven, J., Córdova-Esparza, D.M., Romero-González, J.A.: A comprehensive re- view of YOLO architectures in computer vision: From YOLOv1 to YOLOv8 and YOLO-NAS. Machine Learning and Knowledge Extraction5(4), 1680–1716 (2023)
2023
-
[60]
Ultralytics: YOLOv11 (2026),https://docs.ultralytics.com/models/yolo11/, accessed: 2026-03-30
2026
-
[61]
In: International Conference on Neural Information Processing Systems (NeurIPS)
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, L., Polosukhin, I.: Attention is all you need. In: International Conference on Neural Information Processing Systems (NeurIPS). p. 6000–6010 (2017)
2017
-
[62]
Wei, C., Han, F., Fan, Z., Shi, L., Peng, C.: Efficient license plate recognition in unconstrained scenarios. Journal of Visual Communication and Image Represen- tation104, 104314 (2024).https://doi.org/10.1016/j.jvcir.2024.104314
-
[63]
IEEE Access8, 91661–91675 (2020)
Weihong, W., Jiaoyang, T.: Research on license plate recognition algorithms based on deep learning in complex environment. IEEE Access8, 91661–91675 (2020). https://doi.org/10.1109/ACCESS.2020.2994287
-
[64]
International Joint Conference on Neural Networks (IJCNN) pp
Wojcik, L., Machoski, E.A.F., Nascimento Jr., E., Laroca, R., Menotti, D.: LPLCv2: An expanded dataset for fine-grained license plate legibility classifica- tion. International Joint Conference on Neural Networks (IJCNN) pp. 1–7 (2026)
2026
-
[65]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Woo, S., Debnath, S., Hu, R., Chen, X., Liu, Z., Kweon, I.S., Xie, S.: ConvNeXt V2: Co-designing and scaling convnets with masked autoencoders. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 16133– 16142 (2023).https://doi.org/10.1109/CVPR52729.2023.01548
-
[66]
Patterns3(7), 100543 (2022).https://doi.org/10.1016/j.patter.2022.100543
Xu, Z., Escalera, S., Pavão, A., Richard, M., Tu, W.W., Yao, Q., Zhao, H., Guyon, I.: Codabench: Flexible, easy-to-use, and reproducible meta-benchmark platform. Patterns3(7), 100543 (2022).https://doi.org/10.1016/j.patter.2022.100543
-
[67]
In: IEEE/CVF International Conference on Computer Vision (ICCV)
Ye,X.,Du,Y.,Tao,Y.,Chen,Z.:TextSSR:Diffusion-baseddatasynthesisforscene text recognition. In: IEEE/CVF International Conference on Computer Vision (ICCV). pp. 17464–17473 (2025)
2025
-
[68]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2026)
Ye, X., Du, Y., Zhang, J., Li, C., LYU, J., Chen, Z.: What’s wrong with synthetic data for scene text recognition? a strong synthetic engine with diverse simulations and self-evolution. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2026)
2026
-
[69]
arXiv preprint arXiv:2208.11247 pp
Zhang, D., Huang, F., Liu, S., Wang, X., Jin, Z.: SwinFIR: Revisiting the SwinIR with fast fourier convolution and improved training for image super-resolution. arXiv preprint arXiv:2208.11247 pp. 1–14 (2023)
-
[70]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Zhu, X., Hu, H., Lin, S., Dai, J.: Deformable convnets v2: More deformable, better results. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 9300–9308 (2019).https://doi.org/10.1109/CVPR.2019.00953
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.