Recognition: unknown
FlowAnchor: Stabilizing the Editing Signal for Inversion-Free Video Editing
Pith reviewed 2026-05-08 12:30 UTC · model grok-4.3
The pith
FlowAnchor stabilizes the editing signal for inversion-free video editing by explicitly anchoring both location and strength of changes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FlowAnchor is a training-free framework that stabilizes inversion-free, flow-based video editing by anchoring both where to edit and how strongly to edit. It introduces Spatial-aware Attention Refinement to enforce consistent alignment between textual guidance and spatial regions, and Adaptive Magnitude Modulation to adaptively preserve sufficient editing strength against attenuation. These mechanisms together stabilize the editing signal and guide the flow-based evolution toward the desired target distribution, enabling reliable performance in multi-object and fast-motion videos.
What carries the argument
Spatial-aware Attention Refinement and Adaptive Magnitude Modulation, which anchor the spatial location and magnitude of the editing signal in video latent spaces.
If this is right
- Editing becomes feasible in multi-object scenes where previous methods lose track of individual elements.
- Temporal coherence improves in fast-motion videos by maintaining consistent edit strength across frames.
- Computation stays efficient since no inversion step is required even for longer sequences.
- The flow-based sampling trajectory is steered more reliably toward the target distribution.
- Performance scales better with increased frame counts without additional training.
Where Pith is reading between the lines
- The same anchoring idea might stabilize editing signals in other high-dimensional generative tasks such as 3D or audio-conditioned video synthesis.
- It points to a general principle that explicit spatial and magnitude control could reduce reliance on inversion across diffusion-based editing pipelines.
- Future work could test whether combining the two mechanisms with existing attention variants yields further gains in structure preservation.
Load-bearing premise
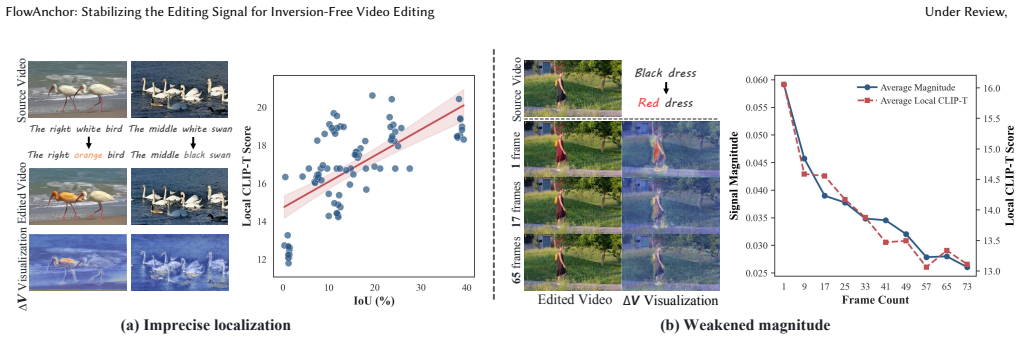
The root cause of failure in extending inversion-free editing to videos is instability of the editing signal from imprecise spatial localization and length-induced magnitude attenuation.
What would settle it
A direct comparison showing that videos edited without the two anchoring mechanisms exhibit the same spatial drift and signal weakening failures as prior inversion-free baselines on multi-object or high-frame-count sequences.
Figures


















read the original abstract
We propose FlowAnchor, a training-free framework for stable and efficient inversion-free, flow-based video editing. Inversion-free editing methods have recently shown impressive efficiency and structure preservation in images by directly steering the sampling trajectory with an editing signal. However, extending this paradigm to videos remains challenging, often failing in multi-object scenes or with increased frame counts. We identify the root cause as the instability of the editing signal in high-dimensional video latent spaces, which arises from imprecise spatial localization and length-induced magnitude attenuation. To overcome this challenge, FlowAnchor explicitly anchors both where to edit and how strongly to edit. It introduces Spatial-aware Attention Refinement, which enforces consistent alignment between textual guidance and spatial regions, and Adaptive Magnitude Modulation, which adaptively preserves sufficient editing strength. Together, these mechanisms stabilize the editing signal and guide the flow-based evolution toward the desired target distribution. Extensive experiments demonstrate that FlowAnchor achieves more faithful, temporally coherent, and computationally efficient video editing across challenging multi-object and fast-motion scenarios. The project page is available at https://cuc-mipg.github.io/FlowAnchor.github.io/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FlowAnchor, a training-free framework for inversion-free, flow-based video editing. It diagnoses failures when extending image-based inversion-free editing to video as arising from instability of the editing signal in high-dimensional video latent spaces, specifically due to imprecise spatial localization and length-induced magnitude attenuation. The method introduces two mechanisms—Spatial-aware Attention Refinement to enforce consistent alignment between textual guidance and spatial regions, and Adaptive Magnitude Modulation to adaptively preserve editing strength—to stabilize the signal and steer the flow-based sampling toward the target distribution. The authors report that these components yield more faithful, temporally coherent, and computationally efficient results than prior approaches, particularly in multi-object and fast-motion scenarios, as demonstrated by extensive experiments.
Significance. If the empirical results hold, the work is significant because it provides a practical, training-free solution to a known scalability bottleneck in video editing without relying on costly inversion steps. The explicit identification of spatial and magnitude instabilities as root causes, followed by targeted anchoring mechanisms, offers a clear and interpretable advance over generic flow-steering baselines. The training-free property and focus on flow-based evolution without added parameters are notable strengths that could improve reproducibility and deployment.
minor comments (3)
- [Abstract] Abstract: the claim of 'extensive experiments' demonstrating improvements would be strengthened by including at least one or two key quantitative metrics (e.g., CLIP similarity or temporal consistency scores) alongside the qualitative description.
- [Method] The manuscript should clarify in the method section whether the two proposed modules (SAR and AMM) interact in a way that could introduce unintended dependencies on video length or object count; a short derivation or pseudocode would help.
- [Experiments] Figure captions and legends should explicitly state the baselines used and the exact metrics plotted to allow readers to assess the claimed gains in faithfulness and coherence without cross-referencing the text.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of our manuscript and the recommendation for minor revision. We appreciate the acknowledgment of the significance of our training-free FlowAnchor framework, particularly its identification of spatial and magnitude instabilities in video latent spaces and the targeted mechanisms to address them.
Circularity Check
No significant circularity detected in the presented framework
full rationale
The paper articulates an externally motivated problem (instability of editing signals in video latents due to spatial imprecision and magnitude attenuation) and proposes two explicit, training-free mechanisms (Spatial-aware Attention Refinement and Adaptive Magnitude Modulation) to stabilize the flow-based editing trajectory. No equations, derivations, or self-citations appear in the abstract or description that reduce the central claim to a fitted parameter, self-definition, or load-bearing prior result from the same authors. The method is presented as a direct engineering response to an identified failure mode rather than a closed logical loop, rendering the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Flow-based generative models for video admit direct steering of sampling trajectories by editing signals
Reference graph
Works this paper leans on
- [1]
-
[2]
Duygu Ceylan, Chun-Hao P Huang, and Niloy J Mitra. 2023. Pix2video: Video edit- ing using image diffusion. InProceedings of the IEEE/CVF international conference on computer vision. 23206–23217
2023
-
[3]
Yuren Cong, Mengmeng Xu, Shoufa Chen, Jiawei Ren, Yanping Xie, Juan-Manuel Perez-Rua, Bodo Rosenhahn, Tao Xiang, Sen He, et al. 2024. FLATTEN: optical FLow-guided ATTENtion for consistent text-to-video editing. InThe Twelfth International Conference on Learning Representations
2024
-
[4]
Michal Geyer, Omer Bar-Tal, Shai Bagon, and Tali Dekel. 2024. TokenFlow: Consis- tent Diffusion Features for Consistent Video Editing. InThe Twelfth International Conference on Learning Representations
2024
-
[5]
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. 2022. Video diffusion models.Advances in neu- ral information processing systems35 (2022), 8633–8646
2022
-
[6]
Quan Huynh-Thu and Mohammed Ghanbari. 2008. Scope of validity of PSNR in image/video quality assessment.Electronics letters44, 13 (2008), 800–801
2008
-
[7]
Zeyinzi Jiang, Zhen Han, Chaojie Mao, Jingfeng Zhang, Yulin Pan, and Yu Liu
-
[8]
InProceedings of the IEEE/CVF International Conference on Computer Vision
Vace: All-in-one video creation and editing. InProceedings of the IEEE/CVF International Conference on Computer Vision. 17191–17202
- [9]
-
[10]
Ozgur Kara, Bariscan Kurtkaya, Hidir Yesiltepe, James M Rehg, and Pinar Ya- nardag. 2024. Rave: Randomized noise shuffling for fast and consistent video editing with diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 6507–6516
2024
- [11]
-
[12]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al
-
[13]
InProceedings of the IEEE/CVF international conference on computer vision
Segment anything. InProceedings of the IEEE/CVF international conference on computer vision. 4015–4026
-
[14]
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. 2024. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603 (2024)
work page internal anchor Pith review arXiv 2024
- [15]
-
[16]
Vladimir Kulikov, Matan Kleiner, Inbar Huberman-Spiegelglas, and Tomer Michaeli. 2025. Flowedit: Inversion-free text-based editing using pre-trained flow models. InProceedings of the IEEE/CVF International Conference on Computer Vision. 19721–19730
2025
-
[17]
Wei-Sheng Lai, Jia-Bin Huang, Oliver Wang, Eli Shechtman, Ersin Yumer, and Ming-Hsuan Yang. 2018. Learning blind video temporal consistency. InProceed- ings of the European conference on computer vision (ECCV). 170–185
2018
- [18]
-
[19]
Minghan Li, Chenxi Xie, Yichen Wu, Lei Zhang, and Mengyu Wang. 2025. Five- bench: A fine-grained video editing benchmark for evaluating emerging diffusion and rectified flow models. InProceedings of the IEEE/CVF International Conference on Computer Vision. 16672–16681
2025
-
[20]
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. 2023. Flow Matching for Generative Modeling. InThe Eleventh International Conference on Learning Representations
2023
-
[21]
Xingchao Liu, Chengyue Gong, et al. 2023. Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow. InThe Eleventh International Conference on Learning Representations
2023
-
[22]
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El- Nouby, et al. 2024. DINOv2: Learning Robust Visual Features without Supervision. Transactions on Machine Learning Research Journal(2024)
2024
-
[23]
William Peebles and Saining Xie. 2023. Scalable diffusion models with transform- ers. InProceedings of the IEEE/CVF international conference on computer vision. 4195–4205
2023
-
[24]
Federico Perazzi, Jordi Pont-Tuset, Brian McWilliams, Luc Van Gool, Markus Gross, and Alexander Sorkine-Hornung. 2016. A benchmark dataset and eval- uation methodology for video object segmentation. InProceedings of the IEEE conference on computer vision and pattern recognition. 724–732
2016
-
[25]
Chenyang Qi, Xiaodong Cun, Yong Zhang, Chenyang Lei, Xintao Wang, Ying Shan, and Qifeng Chen. 2023. Fatezero: Fusing attentions for zero-shot text-based video editing. InProceedings of the IEEE/CVF International Conference on Computer Vision. 15932–15942
2023
-
[26]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. InInternational conference on machine learning. PmLR, 8748–8763
2021
-
[27]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 10684–10695
2022
-
[28]
Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, et al. 2023. Make-A-Video: Text-to-Video Generation without Text-Video Data. InThe Eleventh International Conference on Learning Representations
2023
-
[29]
Zachary Teed and Jia Deng. 2020. Raft: Recurrent all-pairs field transforms for optical flow. InEuropean conference on computer vision. Springer, 402–419
2020
-
[30]
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. 2025. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314(2025)
work page internal anchor Pith review arXiv 2025
-
[31]
Jiangshan Wang, Junfu Pu, Zhongang Qi, Jiayi Guo, Yue Ma, Nisha Huang, Yuxin Chen, Xiu Li, and Ying Shan. 2025. Taming Rectified Flow for Inversion and Editing. InInternational Conference on Machine Learning. PMLR, 64044–64058
2025
-
[32]
Yukun Wang, Longguang Wang, Zhiyuan Ma, Qibin Hu, Kai Xu, and Yulan Guo
-
[33]
InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Videodirector: Precise video editing via text-to-video models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2589– 2598
-
[34]
Sihan Xu, Yidong Huang, Jiayi Pan, Ziqiao Ma, and Joyce Chai. 2024. Inversion- free image editing with language-guided diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 9452–9461
2024
-
[35]
Shuai Yang, Yifan Zhou, Ziwei Liu, and Chen Change Loy. 2023. Rerender a video: Zero-shot text-guided video-to-video translation. InSIGGRAPH Asia 2023 Conference Papers. 1–11
2023
-
[36]
Xiangpeng Yang, Linchao Zhu, Hehe Fan, and Yi Yang. 2025. Videograin: Mod- ulating space-time attention for multi-grained video editing. InThe Thirteenth International Conference on Learning Representations
2025
-
[37]
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al . 2025. CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer. InThe Thirteenth International Conference on Learning Representations
2025
-
[38]
Sung-Hoon Yoon, Minghan Li, Gaspard Beaudouin, Congcong Wen, Muham- mad Rafay Azhar, and Mengyu Wang. 2025. SplitFlow: Flow Decomposition for Inversion-Free Text-to-Image Editing. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
2025
-
[39]
Controlvideo: Training-free controllable text-to-video generation
Yabo Zhang, Yuxiang Wei, Dongsheng Jiang, Xiaopeng Zhang, Wangmeng Zuo, and Qi Tian. 2023. ControlVideo: Training-free Controllable Text-to-Video Gen- eration.arXiv preprint arXiv:2305.13077(2023). Under Review, Chen et al. A Summary In this supplementary material, we provide additional technical details, benchmark descriptions, and qualitative analyses. ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.