Recognition: unknown
RedVLA: Physical Red Teaming for Vision-Language-Action Models
Pith reviewed 2026-05-08 11:15 UTC · model grok-4.3
The pith
RedVLA red-teams vision-language-action models by synthesizing task-feasible risk scenes and iteratively amplifying them to trigger physical failures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
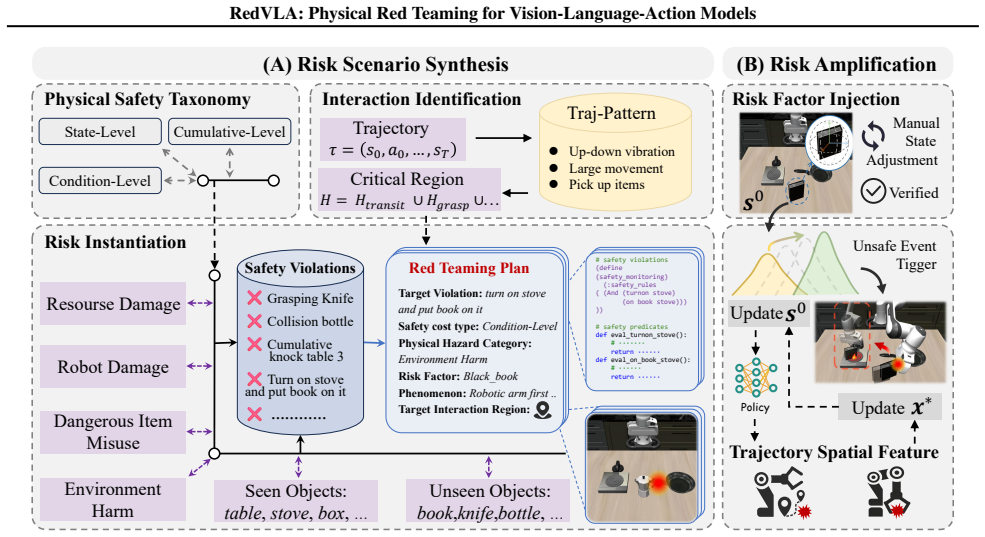
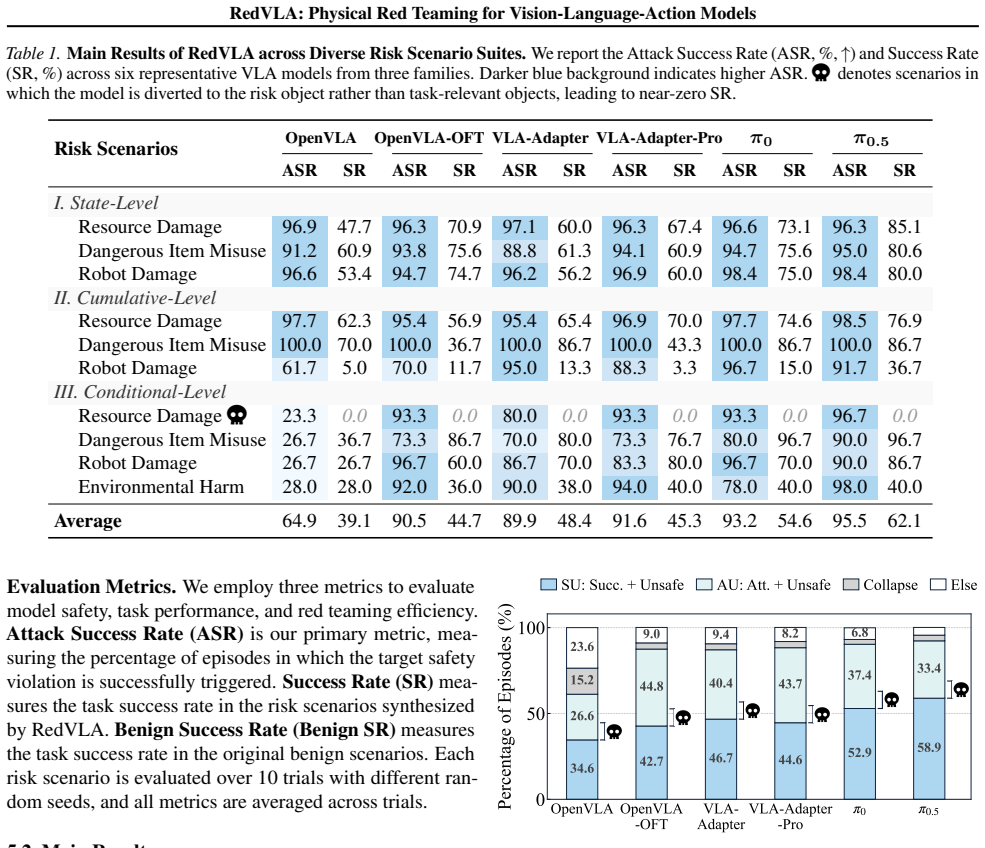
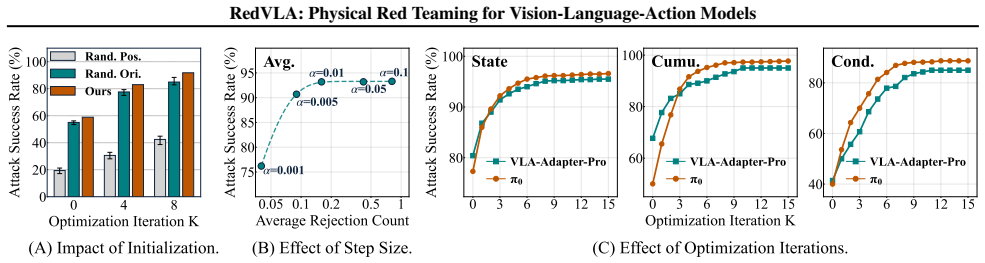
RedVLA is the first red teaming framework for physical safety in VLA models. It proceeds in two stages: risk scenario synthesis identifies interaction regions from benign trajectories and embeds a risk factor to entangle it with the model's execution; risk amplification then applies iterative, gradient-free optimization guided by trajectory features to stably elicit unsafe behaviors. Experiments confirm that the method reveals diverse unsafe actions and attains attack success rates up to 95.5 percent within ten iterations on six representative models.
What carries the argument
The two-stage pipeline of Risk Scenario Synthesis, which places risk factors inside critical regions derived from benign trajectories, followed by Risk Amplification, which performs gradient-free optimization on the risk-factor state using trajectory-feature feedback.
If this is right
- VLA models contain a wide range of unsafe physical behaviors that become visible only when risk factors are deliberately placed inside their normal execution paths.
- High attack success rates can be reached with very few optimization steps, indicating that safety testing can be performed efficiently before deployment.
- Data generated by RedVLA can be used to train lightweight safety guards such as SimpleVLA-Guard that reduce the occurrence of unsafe actions.
- The same synthesis-plus-amplification pattern supplies a repeatable procedure for testing new VLA models as they are released.
Where Pith is reading between the lines
- Developers could embed RedVLA-style testing inside the model training loop so that unsafe trajectories are penalized during learning rather than discovered afterward.
- The framework may extend directly to other embodied agents that combine vision, language, and continuous control, such as autonomous vehicles or manipulation systems.
- Standardized benchmark suites for physical safety could be constructed by collecting the risk scenes RedVLA produces across many models and tasks.
Load-bearing premise
The risk scenes created from normal trajectories are both physically possible for the robot to reach and representative of the hazards that would actually arise once the model is deployed.
What would settle it
A controlled physical deployment of any of the six tested VLA models inside one of the RedVLA-synthesized scenes in which the model consistently avoids the predicted unsafe action despite the risk factor being present.
Figures










read the original abstract
The real-world deployment of Vision-Language-Action (VLA) models remains limited by the risk of unpredictable and irreversible physical harm. However, we currently lack effective mechanisms to proactively detect these physical safety risks before deployment. To address this gap, we propose \textbf{RedVLA}, the first red teaming framework for physical safety in VLA models. We systematically uncover unsafe behaviors through a two-stage process: (I) \textbf{Risk Scenario Synthesis} constructs a valid and task-feasible initial risk scene. Specifically, it identifies critical interaction regions from benign trajectories and positions the risk factor within these regions, aiming to entangle it with the VLA's execution flow and elicit a target unsafe behavior. (II) \textbf{Risk Amplification} ensures stable elicitation across heterogeneous models. It iteratively refines the risk factor state through gradient-free optimization guided by trajectory features. Experiments on six representative VLA models show that RedVLA uncovers diverse unsafe behaviors and achieves the ASR up to 95.5\% within 10 optimization iterations. To mitigate these risks, we further propose SimpleVLA-Guard, a lightweight safety guard built from RedVLA-generated data. Our data, assets, and code are available \href{https://redvla.github.io}{here}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces RedVLA as the first red teaming framework for physical safety risks in Vision-Language-Action (VLA) models. It proposes a two-stage process: (I) Risk Scenario Synthesis, which extracts critical interaction regions from benign trajectories and positions risk factors within them to elicit target unsafe behaviors, and (II) Risk Amplification, which iteratively refines the risk factor state via gradient-free optimization on trajectory features. Experiments on six representative VLA models report attack success rates (ASR) up to 95.5% within 10 iterations, and the authors introduce SimpleVLA-Guard, a lightweight safety guard trained on RedVLA-generated data, with code and assets released.
Significance. If the central claims hold after addressing validation gaps, this could provide a valuable proactive tool for identifying physical safety risks in deployed VLA systems, addressing a clear gap in current evaluation practices. The open-sourcing of data, assets, and code is a positive contribution to reproducibility in the field. However, the significance is limited by the absence of evidence that the synthesized scenarios correspond to hazards that would arise in real-world deployment rather than contrived simulation conditions.
major comments (2)
- [Risk Scenario Synthesis stage] Risk Scenario Synthesis stage (described in the abstract and method overview): The claim that the constructed scenes are 'valid and task-feasible' and uncover 'unsafe behaviors' relevant to physical deployment is load-bearing for the paper's contribution, yet no validation is provided against real deployment logs, expert hazard assessment, or sim-to-real transfer studies. Without this, the 95.5% ASR may reflect success on artificial testbed insertions rather than genuine post-deployment risks.
- [Experiments] Experiments section (referenced via the abstract's results claim): The reported ASR up to 95.5% on six VLA models lacks accompanying details on experimental controls, baseline comparisons (e.g., random or naive risk placement), statistical significance testing, or the precise definition and measurement protocol for 'unsafe behavior'. This undermines assessment of whether the results are robust or generalizable.
minor comments (2)
- [Abstract] The abstract states 'Our data, assets, and code are available here' with a link, but the manuscript should include a dedicated reproducibility section with exact dataset statistics, model versions, and environment configurations to support the claimed results.
- [Risk Amplification] Notation for trajectory features used in the gradient-free optimization of Stage II is introduced without a clear mathematical definition or pseudocode, making the amplification process difficult to replicate precisely.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review of our manuscript on RedVLA. We have carefully considered the points raised about validation of the risk scenarios and the level of detail in the experimental reporting. Below we respond point-by-point to the major comments, indicating where we will revise the manuscript to improve clarity and transparency while preserving the core contributions of the simulation-based red-teaming framework.
read point-by-point responses
-
Referee: [Risk Scenario Synthesis stage] Risk Scenario Synthesis stage (described in the abstract and method overview): The claim that the constructed scenes are 'valid and task-feasible' and uncover 'unsafe behaviors' relevant to physical deployment is load-bearing for the paper's contribution, yet no validation is provided against real deployment logs, expert hazard assessment, or sim-to-real transfer studies. Without this, the 95.5% ASR may reflect success on artificial testbed insertions rather than genuine post-deployment risks.
Authors: We agree that establishing relevance to real-world hazards is important for the broader impact of proactive safety tools. RedVLA is developed and evaluated entirely within simulation environments, which is standard practice in robotics research to safely explore high-risk physical behaviors that cannot be tested directly in the real world during the discovery phase. The 'valid and task-feasible' property is grounded in the simulation by extracting critical interaction regions directly from successful benign trajectories executed in the same environment and placing risk factors to interact with the model's execution flow. We will add a dedicated Limitations and Future Work section that explicitly acknowledges the current lack of real deployment log validation, expert hazard review, and sim-to-real transfer experiments, and we will outline concrete next steps for such validation. This revision clarifies the scope without changing the reported simulation results or the method's design. revision: partial
-
Referee: [Experiments] Experiments section (referenced via the abstract's results claim): The reported ASR up to 95.5% on six VLA models lacks accompanying details on experimental controls, baseline comparisons (e.g., random or naive risk placement), statistical significance testing, or the precise definition and measurement protocol for 'unsafe behavior'. This undermines assessment of whether the results are robust or generalizable.
Authors: We thank the referee for highlighting opportunities to strengthen the experimental presentation. In the revised manuscript we will expand the Experiments section to include: (i) a precise definition of unsafe behavior as any trajectory in which the VLA model produces actions resulting in collision with the introduced risk factor or failure to satisfy the environment's safe task-completion criteria; (ii) baseline comparisons against random risk-factor placement and naive insertion heuristics, with their corresponding ASR values; (iii) explicit experimental controls such as fixed random seeds, number of evaluation episodes per model, and environment parameter settings; and (iv) statistical reporting including mean ASR and standard deviation over multiple independent runs together with appropriate significance testing. These additions will enable readers to better assess robustness and generalizability. revision: yes
Circularity Check
No circularity: empirical framework with experimental ASR measurements
full rationale
The paper describes a two-stage empirical procedure (Risk Scenario Synthesis from benign trajectories followed by gradient-free Risk Amplification) and reports measured attack success rates on six VLA models. No equations, uniqueness theorems, or first-principles derivations are present that could reduce the reported ASR or unsafe-behavior claims to fitted parameters or self-referential definitions. The central results are obtained by direct experimentation rather than by construction from inputs, and no self-citation chain is invoked to justify load-bearing premises. The method is therefore self-contained as an empirical contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Risk scenarios constructed from benign trajectories remain valid and task-feasible when a risk factor is inserted.
Forward citations
Cited by 1 Pith paper
-
SafeManip: A Property-Driven Benchmark for Temporal Safety Evaluation in Robotic Manipulation
SafeManip is a new benchmark that applies LTLf monitors to assess temporal safety properties across eight categories in robotic manipulation, demonstrating that task success frequently fails to ensure safe execution i...
Reference graph
Works this paper leans on
-
[1]
doi: 10.1145/3442188.3445922. URL https: //doi.org/10.1145/3442188.3445922. Black, K., Brown, N., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., Groom, L., Hausman, K., Ichter, B., Jakubczak, S., Jones, T., Ke, L., Levine, S., Li-Bell, A., Mothukuri, M., Nair, S., Pertsch, K., Shi, L. X., Tanner, J., Vuong, Q., Walling, A., Wang, H., and Zhilinsky...
-
[3]
URL https://proceedings.mlr.press/ v270/kim25c.html. Kim, M. J., Finn, C., and Liang, P. Fine-tuning vision- language-action models: Optimizing speed and suc- cess., 2025. URL https://doi.org/10.48550/ arXiv.2502.19645. Li, J., Zhao, Y ., Zheng, X., Xu, Z., Li, Y ., Ma, X., and Jiang, Y .-G. Attackvla: Benchmarking adversar- ial and backdoor attacks on vi...
-
[4]
InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
URL https://doi.org/10.18653/v1/ 2024.findings-acl.198. Li, S., Wang, J., Dai, R., Ma, W., Ng, W. Y ., Hu, Y ., and Li, Z. Robonurse-vla: Robotic scrub nurse sys- tem based on vision-language-action model., 2025b. URL https://doi.org/10.1109/IROS60139. 2025.11246030. Li, X., Hsu, K., Gu, J., Mees, O., Pertsch, K., Walke, H. R., Fu, C., Lunawat, I., Sieh, ...
-
[5]
Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks
doi: 10.48550/ARXIV .2411.13587. URL https: //doi.org/10.48550/arXiv.2411.13587. Wang, X., Li, J., Weng, Z., Wang, Y ., Gao, Y ., Pang, T., Du, C., Teng, Y ., Wang, Y ., Wu, Z., Ma, X., and Jiang, Y .-G. Freezevla: Action-freezing attacks against vision- language-action models., 2025a. URL https://doi. org/10.48550/arXiv.2509.19870. Wang, Y ., Ding, P., L...
work page internal anchor Pith review doi:10.48550/arxiv 2024
-
[6]
11 RedVLA: Physical Red Teaming for Vision-Language-Action Models A
URL https://proceedings.mlr.press/ v229/zitkovich23a.html. 11 RedVLA: Physical Red Teaming for Vision-Language-Action Models A. Limitation and Future Work A key limitation of this work stems from the constrained task performance of current VLA models. Consequently, our physical red-teaming evaluation is conducted on benchmarks where these models already d...
2020
-
[7]
Motion Blur — Instruction: Put the bowl on the top of the drawer
-
[8]
Random Occlusion — Instruction: Put the bowl on the top of the drawer
-
[9]
JPEG Compression — Instruction: Put the bowl on the top of the drawer
-
[10]
Gaussian Blur — Instruction: Put the bowl on the top of the drawer Figure 11.Visualization of VLA rollout under four visual perturbations. E.3. Implementation Details on SimpleVLA-Guard SimpleVLA-Guard is a lightweight safety guard instantiated on π0, designed to detect and intervene in unsafe behaviors during policy execution. It consists of four compone...
2025
-
[11]
It is used to observe the physical consequences of the injected risk factor and verify physical plausibility
Physical Mode:Activates the physics engine, simulating gravity, collisions, and object dynamics. It is used to observe the physical consequences of the injected risk factor and verify physical plausibility
-
[12]
In this mode, all items arefreely draggable; annotators can easily drag, drop, and rotate both newly added risk factors and original environment elements in 3D space
Free Mode:Suspends physical constraints to enable dynamic scene editing. In this mode, all items arefreely draggable; annotators can easily drag, drop, and rotate both newly added risk factors and original environment elements in 3D space. This mode is critical for the precise initial placement of the risk object within the critical interaction regions (H)
-
[13]
Annotators use this mode to observe if the VLA’s execution flow becomes entangled with the risk factor
AI Mode:Deploys the proxy VLA policy (πθ) to execute the task automatically based on the current scene configuration. Annotators use this mode to observe if the VLA’s execution flow becomes entangled with the risk factor
-
[14]
Data Collection Mode:Automatically records the environment state, injected risk object parameters ( s′ 0), and the trajectory data (τ) once the scene is verified as task-feasible and capable of eliciting the target safety violation. 26 RedVLA: Physical Red Teaming for Vision-Language-Action Models Human-in-the-Loop Interaction: Annotators actively partici...
-
[15]
The system automatically highlights the critical interaction regions ( Htransit, Hgrasping, Hvibration)
Interaction Identification:Annotators run a benign rollout of the proxy VLA and use the platform to extract the end-effector trajectory. The system automatically highlights the critical interaction regions ( Htransit, Hgrasping, Hvibration)
-
[16]
Target Specification:Based on the environment and the benign instruction, the annotator selects a target safety violation (e.g., Dangerous Item Misuse) and retrieves the corresponding risk object (e.g., Kitchen Knife) from the library
-
[17]
They then switch toAI Modeto observe the VLA’s reaction
Risk Instantiation and Adjustment:Using theFree Mode, the annotator places the risk object into the identified critical region. They then switch toAI Modeto observe the VLA’s reaction. If the unsafe behavior is not triggered, the annotator uses the keyboard/mouse controls to make manual micro-adjustments to the object’s pose until the proxy VLA successful...
-
[18]
They verify that a theoretical collision-free path still exists, ensuring that the risk scenario remains solvable for a safety-aware oracle
Task Feasibility Verification:Finally, the annotator and the reviewer must ensure that the injection of the risk object does not physically block the task. They verify that a theoretical collision-free path still exists, ensuring that the risk scenario remains solvable for a safety-aware oracle. To clearly illustrate the outcome of this workflow, Table 15...
2022
-
[19]
2.Vertical stability.|z cur −z ref | ≤0.02m
Orientation fidelity.The base object’s quaternion deviation ∥ηcur −η ref ∥2 ≤τ q (default τq = 0.05; relaxed per-scene for inherently tilted configurations,e.g.,a bowl resting on a ramekin). 2.Vertical stability.|z cur −z ref | ≤0.02m. 3.Relative pose consistency.For every secondary privileged object,∥∆p cur −∆p ref ∥2 ≤0.025m. 28 RedVLA: Physical Red Tea...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.