Recognition: unknown
EV-CLIP: Efficient Visual Prompt Adaptation for CLIP in Few-shot Action Recognition under Visual Challenges
Pith reviewed 2026-05-08 12:26 UTC · model grok-4.3
The pith
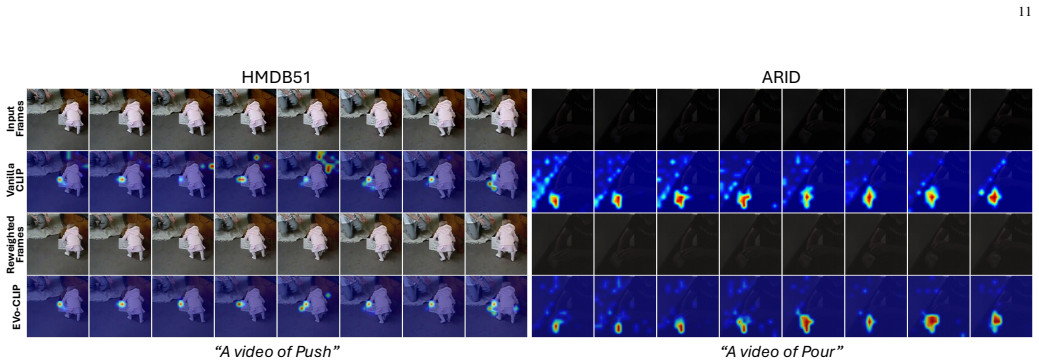
Mask prompts reweight pixels to action-relevant areas while context prompts compress temporal features, allowing CLIP to perform few-shot action recognition effectively under visual challenges such as low light and egocentric views.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
EV-CLIP adapts CLIP using two visual prompts: mask prompts that guide attention by reweighting pixels to action-relevant regions, and context prompts that perform lightweight temporal modeling by compressing frame-wise features into a compact representation, enabling strong performance in few-shot settings across diverse scenes and viewpoints.
What carries the argument
The pair of mask prompts for spatial reweighting and context prompts for temporal compression that together address spatial perception deficits in CLIP for video tasks.
If this is right
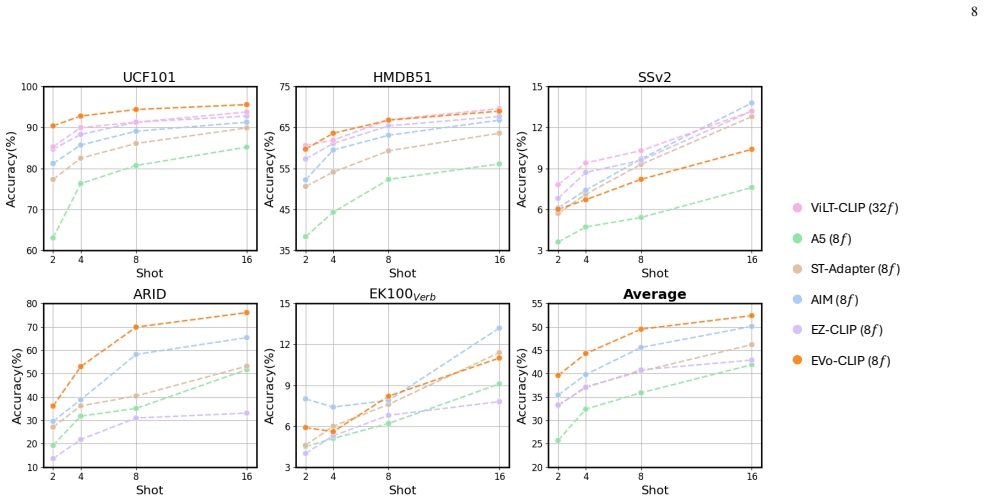
- EV-CLIP achieves higher overall accuracy than other parameter-efficient adaptation methods on five benchmark datasets with visual and semantic domain shifts.
- Its added computational cost does not increase with larger backbone models.
- The framework is suitable for deployment in resource-constrained real-world applications.
- Analysis of domain shifts shows how visual factors like lighting and viewpoints affect recognition performance.
Where Pith is reading between the lines
- Similar prompting strategies could extend to other vision-language models facing spatial degradation in videos.
- Testing on more extreme visual challenges such as heavy occlusion or motion blur would further validate the prompts' robustness.
- The independence from backbone scale suggests potential for scaling to very large models without proportional efficiency loss.
Load-bearing premise
That the mask prompts successfully reweight pixels to highlight action-relevant regions and the context prompts compress frame features without losing critical temporal information, even under severe visual degradations like low light or egocentric viewpoints.
What would settle it
A direct comparison on the curated five benchmark datasets where EV-CLIP fails to exceed the accuracy of competing efficient methods while maintaining similar or lower parameter counts and inference speed.
Figures






read the original abstract
CLIP has demonstrated strong generalization in visual domains through natural language supervision, even for video action recognition. However, most existing approaches that adapt CLIP for action recognition have primarily focused on temporal modeling, often overlooking spatial perception. In real-world scenarios, visual challenges such as low-light environments or egocentric viewpoints can severely impair spatial understanding, an essential precursor for effective temporal reasoning. To address this limitation, we propose Efficient Visual Prompting for CLIP (EV-CLIP), an efficient adaptation framework designed for few-shot video action recognition across diverse scenes and viewpoints. EV-CLIP introduces two visual prompts: mask prompts, which guide the model's attention to action-relevant regions by reweighting pixels, and context prompts, which perform lightweight temporal modeling by compressing frame-wise features into a compact representation. For a comprehensive evaluation, we curate five benchmark datasets and analyze domain shifts to quantify the influence of diverse visual and semantic factors on action recognition. Experimental results demonstrate that EV-CLIP outperforms existing parameter-efficient methods in overall performance. Moreover, its efficiency remains independent of the backbone scale, making it well-suited for deployment in real-world, resource-constrained scenarios. The code is available at https://github.com/AI-CV-Lab/EV-CLIP.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes EV-CLIP, an efficient visual prompting framework for adapting CLIP to few-shot video action recognition under visual challenges such as low-light environments and egocentric viewpoints. It introduces mask prompts to reweight pixels and guide attention to action-relevant regions, along with context prompts to compress frame-wise features for lightweight temporal modeling. The method is evaluated on five curated benchmark datasets analyzing domain shifts, with claims of outperforming existing parameter-efficient methods and maintaining efficiency independent of backbone scale.
Significance. If the performance and efficiency claims hold with proper verification, this could enable practical deployment of large CLIP models in resource-constrained real-world video scenarios involving visual degradations, by providing a prompting approach that avoids scaling costs with model size.
major comments (2)
- Abstract: The central claim that 'its efficiency remains independent of the backbone scale' lacks any described mechanism, equations, or experimental support. Standard visual prompt designs incur parameter counts scaling with hidden_dim and sequence length (e.g., prompt_length × hidden_dim), which increase for larger backbones such as ViT-L versus ViT-B; without an explicit non-scaling design (e.g., shared or frozen components), this undermines the efficiency independence assertion.
- Abstract: The assertion that 'EV-CLIP outperforms existing parameter-efficient methods in overall performance' is presented without quantitative metrics, ablation details, statistical tests, or error analysis. This is load-bearing for the primary experimental claim and requires concrete results tables and comparisons in the evaluation section to be verifiable.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the two major comments point by point below, clarifying the design rationale and committing to revisions that strengthen the abstract and supporting sections without altering the core contributions.
read point-by-point responses
-
Referee: Abstract: The central claim that 'its efficiency remains independent of the backbone scale' lacks any described mechanism, equations, or experimental support. Standard visual prompt designs incur parameter counts scaling with hidden_dim and sequence length (e.g., prompt_length × hidden_dim), which increase for larger backbones such as ViT-L versus ViT-B; without an explicit non-scaling design (e.g., shared or frozen components), this undermines the efficiency independence assertion.
Authors: The mask prompts are generated as a fixed-resolution spatial reweighting map applied directly to the input frames prior to the visual encoder, using a lightweight convolutional head whose parameters are independent of the backbone hidden dimension. The context prompts operate on aggregated frame features via a dimension-agnostic compression module (global pooling followed by a small fixed-size MLP) that produces a compact temporal representation without scaling parameters with model width or depth. We will insert the corresponding equations and a parameter-count comparison table (ViT-B vs. ViT-L) into Section 3 and update the abstract to reference this non-scaling property explicitly. revision: yes
-
Referee: Abstract: The assertion that 'EV-CLIP outperforms existing parameter-efficient methods in overall performance' is presented without quantitative metrics, ablation details, statistical tests, or error analysis. This is load-bearing for the primary experimental claim and requires concrete results tables and comparisons in the evaluation section to be verifiable.
Authors: The full manuscript already contains quantitative comparisons in Tables 1 and 2 across the five curated datasets, reporting mean top-1 accuracy and standard deviation over three random seeds for EV-CLIP versus CoOp, MaPLe, and other baselines under identical few-shot protocols. Ablation results appear in Section 4.3. We will revise the abstract to include specific average accuracy gains (e.g., +X% over the strongest baseline) and ensure all performance claims are cross-referenced to these tables; we did not conduct formal statistical significance tests beyond reporting standard deviations but can add them if the referee deems necessary. revision: partial
Circularity Check
No circularity: paper presents empirical method without derivations or predictions that reduce to inputs
full rationale
The manuscript describes EV-CLIP via two prompt types (mask prompts for spatial reweighting, context prompts for temporal compression) and reports experimental outperformance plus efficiency claims on five datasets. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. All central claims rest on empirical evaluation rather than any algebraic reduction to the method's own definitions or prior self-citations. The efficiency-independence statement is an empirical observation, not a derived result that collapses by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Multimodal human action recognition in assistive human-robot interaction,
I. Rodomagoulakis, N. Kardaris, V . Pitsikalis, E. Mavroudi, A. Katsama- nis, A. Tsiami, and P. Maragos, “Multimodal human action recognition in assistive human-robot interaction,” in2016 IEEE international con- ference on acoustics, speech and signal processing (ICASSP). IEEE, 2016, pp. 2702–2706
2016
-
[2]
Human activity recognition for video surveillance,
W. Lin, M.-T. Sun, R. Poovandran, and Z. Zhang, “Human activity recognition for video surveillance,” in2008 IEEE international sym- posium on circuits and systems (ISCAS). IEEE, 2008, pp. 2737–2740
2008
-
[3]
U-har: A convolu- tional approach to human activity recognition combining head and eye movements for context-aware smart glasses,
J. Meyer, A. Frank, T. Schlebusch, and E. Kasneci, “U-har: A convolu- tional approach to human activity recognition combining head and eye movements for context-aware smart glasses,”Proceedings of the ACM on Human-Computer Interaction, vol. 6, no. ETRA, pp. 1–19, 2022
2022
-
[4]
Learning spatiotemporal features with 3d convolutional networks,
D. Tran, L. Bourdev, R. Fergus, L. Torresani, and M. Paluri, “Learning spatiotemporal features with 3d convolutional networks,” inProceedings of the IEEE international conference on computer vision, 2015, pp. 4489–4497
2015
-
[5]
Learning spatio-temporal representation with pseudo-3d residual networks,
Z. Qiu, T. Yao, and T. Mei, “Learning spatio-temporal representation with pseudo-3d residual networks,” inproceedings of the IEEE Interna- tional Conference on Computer Vision, 2017, pp. 5533–5541
2017
-
[6]
Quo vadis, action recognition? a new model and the kinetics dataset,
J. Carreira and A. Zisserman, “Quo vadis, action recognition? a new model and the kinetics dataset,” inproceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 6299–6308
2017
-
[7]
A closer look at spatiotemporal convolutions for action recognition,
D. Tran, H. Wang, L. Torresani, J. Ray, Y . LeCun, and M. Paluri, “A closer look at spatiotemporal convolutions for action recognition,” in Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, 2018, pp. 6450–6459
2018
-
[8]
Non-local neural net- works,
X. Wang, R. Girshick, A. Gupta, and K. He, “Non-local neural net- works,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 7794–7803
2018
-
[9]
Tsm: Temporal shift module for efficient video understanding,
J. Lin, C. Gan, and S. Han, “Tsm: Temporal shift module for efficient video understanding,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 7083–7093
2019
-
[10]
Tea: Temporal excitation and aggregation for action recognition,
Y . Li, B. Ji, X. Shi, J. Zhang, B. Kang, and L. Wang, “Tea: Temporal excitation and aggregation for action recognition,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 909–918
2020
-
[11]
Tdn: Temporal difference networks for efficient action recognition,
L. Wang, Z. Tong, B. Ji, and G. Wu, “Tdn: Temporal difference networks for efficient action recognition,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 1895– 1904
2021
-
[12]
Vivit: A video vision transformer,
A. Arnab, M. Dehghani, G. Heigold, C. Sun, M. Lu ˇci´c, and C. Schmid, “Vivit: A video vision transformer,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 6836–6846
2021
-
[13]
Is space-time attention all you need for video understanding?
G. Bertasius, H. Wang, and L. Torresani, “Is space-time attention all you need for video understanding?” inProceedings of the International Conference on Machine Learning (ICML), vol. 2, no. 3, 2021, p. 4
2021
-
[14]
Video transformer network,
D. Neimark, O. Bar, M. Zohar, and D. Asselmann, “Video transformer network,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 3163–3172
2021
-
[15]
Video swin transformer,
Z. Liu, J. Ning, Y . Cao, Y . Wei, Z. Zhang, S. Lin, and H. Hu, “Video swin transformer,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 3202–3211
2022
-
[16]
Multiview transformers for video recognition,
S. Yan, X. Xiong, A. Arnab, Z. Lu, M. Zhang, C. Sun, and C. Schmid, “Multiview transformers for video recognition,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 3333–3343
2022
-
[17]
Uniformer: Unified transformer for efficient spatiotemporal representation learning
K. Li, Y . Wang, P. Gao, G. Song, Y . Liu, H. Li, and Y . Qiao, “Uniformer: Unified transformer for efficient spatiotemporal representation learning,” arXiv preprint arXiv:2201.04676, 2022
-
[18]
Temporal attentive alignment for large-scale video domain adaptation,
M.-H. Chen, Z. Kira, G. AlRegib, J. Yoo, R. Chen, and J. Zheng, “Temporal attentive alignment for large-scale video domain adaptation,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 6321–6330
2019
-
[19]
Shuffle and attend: Video domain adaptation,
J. Choi, G. Sharma, S. Schulter, and J.-B. Huang, “Shuffle and attend: Video domain adaptation,” inComputer Vision–ECCV 2020: 16th Euro- pean Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XII 16. Springer, 2020, pp. 678–695. 13
2020
-
[20]
Adversarial cross- domain action recognition with co-attention,
B. Pan, Z. Cao, E. Adeli, and J. C. Niebles, “Adversarial cross- domain action recognition with co-attention,” inProceedings of the AAAI conference on artificial intelligence, vol. 34, no. 07, 2020, pp. 11 815– 11 822
2020
-
[21]
Multi-modal domain adaptation for fine- grained action recognition,
J. Munro and D. Damen, “Multi-modal domain adaptation for fine- grained action recognition,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 122–132
2020
-
[22]
Deep domain adaptation in action space
A. Jamal, V . P. Namboodiri, D. Deodhare, and K. Venkatesh, “Deep domain adaptation in action space.” inBMVC, vol. 2, no. 3. Newcastle, 2018, p. 5
2018
-
[23]
Pairwise two-stream convnets for cross-domain action recognition with small data,
Z. Gao, L. Guo, T. Ren, A.-A. Liu, Z.-Y . Cheng, and S. Chen, “Pairwise two-stream convnets for cross-domain action recognition with small data,”Pairwise two-stream convnets for cross-domain action recognition with small data, vol. 33, no. 3, pp. 1147–1161, 2020
2020
-
[24]
Bridging domain spaces for unsupervised domain adaptation,
J. Na, H. Jung, H. J. Chang, and W. Hwang, “Bridging domain spaces for unsupervised domain adaptation,”Pattern Recognition, vol. 164, p. 111537, 2025
2025
-
[25]
Spatio-temporal contrastive domain adaptation for action recognition,
X. Song, S. Zhao, J. Yang, H. Yue, P. Xu, R. Hu, and H. Chai, “Spatio-temporal contrastive domain adaptation for action recognition,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 9787–9795
2021
-
[26]
Learning cross-modal contrastive features for video domain adaptation,
D. Kim, Y .-H. Tsai, B. Zhuang, X. Yu, S. Sclaroff, K. Saenko, and M. Chandraker, “Learning cross-modal contrastive features for video domain adaptation,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 13 618–13 627
2021
-
[27]
Contrast and mix: Temporal contrastive video domain adaptation with background mixing,
A. Sahoo, R. Shah, R. Panda, K. Saenko, and A. Das, “Contrast and mix: Temporal contrastive video domain adaptation with background mixing,”Advances in Neural Information Processing Systems, vol. 34, pp. 23 386–23 400, 2021
2021
-
[28]
Dual-head contrastive domain adaptation for video action recognition,
V . G. T. Da Costa, G. Zara, P. Rota, T. Oliveira-Santos, N. Sebe, V . Murino, and E. Ricci, “Dual-head contrastive domain adaptation for video action recognition,” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2022, pp. 1181–1190
2022
-
[29]
A pairwise attentive adversarial spatiotemporal network for cross-domain few-shot action recognition-r2,
Z. Gao, L. Guo, W. Guan, A.-A. Liu, T. Ren, and S. Chen, “A pairwise attentive adversarial spatiotemporal network for cross-domain few-shot action recognition-r2,”A pairwise attentive adversarial spatiotemporal network for cross-domain few-shot action recognition-R2, vol. 30, pp. 767–782, 2020
2020
-
[30]
Supervised domain adaptation for few-shot radar-based human activity recognition,
X. Li, Y . He, J. A. Zhang, and X. Jing, “Supervised domain adaptation for few-shot radar-based human activity recognition,”IEEE Sensors Journal, vol. 21, no. 22, pp. 25 880–25 890, 2021
2021
-
[31]
Augmenting and aligning snippets for few-shot video domain adaptation,
Y . Xu, J. Yang, Y . Zhou, Z. Chen, M. Wu, and X. Li, “Augmenting and aligning snippets for few-shot video domain adaptation,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 13 445–13 456
2023
-
[32]
Learning transferable visual models from natural language supervi- sion,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervi- sion,” inProceedings of the 38th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, M. Meila and T. Zhang, ...
2021
-
[33]
Fine- tuned clip models are efficient video learners,
H. Rasheed, M. U. Khattak, M. Maaz, S. Khan, and F. S. Khan, “Fine- tuned clip models are efficient video learners,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 6545–6554
2023
-
[34]
Expanding language-image pretrained models for gen- eral video recognition,
B. Ni, H. Peng, M. Chen, S. Zhang, G. Meng, J. Fu, S. Xiang, and H. Ling, “Expanding language-image pretrained models for gen- eral video recognition,” inEuropean conference on computer vision. Springer, 2022, pp. 1–18
2022
-
[35]
Actionclip: A new paradigm for video action recognition,
M. Wang, J. Xing, and Y . Liu, “Actionclip: A new paradigm for video action recognition,”arXiv:2109.08472, 2021
-
[36]
Kronecker mask and inter- pretive prompts are language-action video learners,
J. Yang, Z. Yu, X. Ni, J. He, and H. Li, “Kronecker mask and inter- pretive prompts are language-action video learners,” inThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[37]
Match, expand and improve: Unsupervised finetuning for zero-shot action recognition with language knowledge,
W. Lin, L. Karlinsky, N. Shvetsova, H. Possegger, M. Kozinski, R. Panda, R. Feris, H. Kuehne, and H. Bischof, “Match, expand and improve: Unsupervised finetuning for zero-shot action recognition with language knowledge,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 2851–2862
2023
-
[38]
Ost: Refining text knowledge with optimal spatio-temporal descriptor for general video recognition,
T. Chen, H. Yu, Z. Yang, Z. Li, W. Sun, and C. Chen, “Ost: Refining text knowledge with optimal spatio-temporal descriptor for general video recognition,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 18 888–18 898
2024
-
[39]
Disentangling spatial and temporal learning for efficient image-to- video transfer learning,
Z. Qing, S. Zhang, Z. Huang, Y . Zhang, C. Gao, D. Zhao, and N. Sang, “Disentangling spatial and temporal learning for efficient image-to- video transfer learning,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 13 934–13 944
2023
-
[40]
Frozen clip models are efficient video learners,
Z. Lin, S. Geng, R. Zhang, P. Gao, G. De Melo, X. Wang, J. Dai, Y . Qiao, and H. Li, “Frozen clip models are efficient video learners,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 388–404
2022
-
[41]
Froster: Frozen clip is a strong teacher for open-vocabulary action recognition,
X. Huang, H. Zhou, K. Yao, and K. Han, “Froster: Frozen clip is a strong teacher for open-vocabulary action recognition,” inInternational Conference on Learning Representations, 2024
2024
-
[42]
Dual-path adaptation from image to video transformers,
J. Park, J. Lee, and K. Sohn, “Dual-path adaptation from image to video transformers,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 2203–2213
2023
-
[43]
Aim: Adapt- ing image models for efficient video understanding,
T. Yang, Y . Zhu, Y . Xie, A. Zhang, C. Chen, and M. Li, “Aim: Adapt- ing image models for efficient video understanding,” inInternational Conference on Learning Representations, 2023
2023
-
[44]
St-adapter: Parameter- efficient image-to-video transfer learning,
J. Pan, Z. Lin, X. Zhu, J. Shao, and H. Li, “St-adapter: Parameter- efficient image-to-video transfer learning,”Advances in Neural Infor- mation Processing Systems, vol. 35, pp. 26 462–26 477, 2022
2022
-
[45]
V op: Text-video co-operative prompt tuning for cross-modal retrieval,
S. Huang, B. Gong, Y . Pan, J. Jiang, Y . Lv, Y . Li, and D. Wang, “V op: Text-video co-operative prompt tuning for cross-modal retrieval,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 6565–6574
2023
-
[46]
Vilt-clip: Video and language tuning clip with multimodal prompt learning and scenario-guided optimization,
H. Wang, F. Liu, L. Jiao, J. Wang, Z. Hao, S. Li, L. Li, P. Chen, and X. Liu, “Vilt-clip: Video and language tuning clip with multimodal prompt learning and scenario-guided optimization,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 6, 2024, pp. 5390–5400
2024
-
[47]
Vita-clip: Video and text adaptive clip via multimodal prompting,
S. T. Wasim, M. Naseer, S. Khan, F. S. Khan, and M. Shah, “Vita-clip: Video and text adaptive clip via multimodal prompting,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion, 2023, pp. 23 034–23 044
2023
-
[48]
Prompting visual- language models for efficient video understanding,
C. Ju, T. Han, K. Zheng, Y . Zhang, and W. Xie, “Prompting visual- language models for efficient video understanding,” inEuropean Con- ference on Computer Vision, 2022, pp. 105–124
2022
-
[49]
Ez-clip: Efficient zeroshot video action recognition,
S. Ahmad, S. Chanda, and Y . S. Rawat, “Ez-clip: Efficient zeroshot video action recognition,”arXiv:2312.08010, 2023
-
[50]
Open-vclip: Transforming clip to an open-vocabulary video model via interpolated weight optimization,
Z. Weng, X. Yang, A. Li, Z. Wu, and Y .-G. Jiang, “Open-vclip: Transforming clip to an open-vocabulary video model via interpolated weight optimization,” inInternational Conference on Machine Learning, 2023, pp. 36 978–36 989
2023
-
[51]
Building an open-vocabulary video clip model with better architectures, optimization and data,
Z. Wu, Z. Weng, W. Peng, X. Yang, A. Li, L. S. Davis, and Y .-G. Jiang, “Building an open-vocabulary video clip model with better architectures, optimization and data,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 7, pp. 4747–4762, 2024
2024
-
[52]
The Kinetics Human Action Video Dataset
W. Kay, J. Carreira, K. Simonyan, B. Zhang, C. Hillier, S. Vijaya- narasimhan, F. Viola, T. Green, T. Back, P. Natsev, M. Suleyman, and A. Zisserman, “The kinetics human action video dataset,”arXiv preprint arXiv:1705.06950, 2017
work page internal anchor Pith review arXiv 2017
-
[53]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review arXiv 2010
-
[54]
Swin transformer: Hierarchical vision transformer using shifted windows,
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 10 012–10 022
2021
-
[55]
Omnivore: A single model for many visual modalities,
R. Girdhar, M. Singh, N. Ravi, L. Van Der Maaten, A. Joulin, and I. Misra, “Omnivore: A single model for many visual modalities,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 16 102–16 112
2022
-
[56]
Source-free video domain adaptation by learning temporal consistency for action recognition,
Y . Xu, J. Yang, H. Cao, K. Wu, M. Wu, and Z. Chen, “Source-free video domain adaptation by learning temporal consistency for action recognition,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 147–164
2022
-
[57]
Anomize: Better open vocabulary video anomaly detection,
F. Li, W. Liu, J. Chen, R. Zhang, Y . Wang, X. Zhong, and Z. Wang, “Anomize: Better open vocabulary video anomaly detection,” inPro- ceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 29 203–29 212
2025
-
[58]
Sato: Stable text-to-motion framework,
W. Chen, H. Xiao, E. Zhang, L. Hu, L. Wang, M. Liu, and C. Chen, “Sato: Stable text-to-motion framework,” inProceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 6989–6997
2024
-
[59]
Scaling up visual and vision-language representation learning with noisy text supervision,
C. Jia, Y . Yang, Y . Xia, Y .-T. Chen, Z. Parekh, H. Pham, Q. Le, Y .-H. Sung, Z. Li, and T. Duerig, “Scaling up visual and vision-language representation learning with noisy text supervision,” inInternational conference on machine learning. PMLR, 2021, pp. 4904–4916
2021
-
[60]
Visual prompt tuning,
M. Jia, L. Tang, B.-C. Chen, C. Cardie, S. Belongie, B. Hariharan, and S.-N. Lim, “Visual prompt tuning,” inEuropean conference on computer vision. Springer, 2022, pp. 709–727. 14
2022
-
[61]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[62]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778
2016
-
[63]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
K. Soomro, A. R. Zamir, and M. Shah, “Ucf101: A dataset of 101 human actions classes from videos in the wild,”arXiv:1212.0402, 2012
work page internal anchor Pith review arXiv 2012
-
[64]
Hmdb: a large video database for human motion recognition,
H. Kuehne, H. Jhuang, E. Garrote, T. Poggio, and T. Serre, “Hmdb: a large video database for human motion recognition,” in2011 Interna- tional conference on computer vision. IEEE, 2011, pp. 2556–2563
2011
-
[65]
The ”something something
R. Goyal, S. Ebrahimi Kahou, V . Michalski, J. Materzynska, S. West- phal, H. Kim, V . Haenel, I. Fruend, P. Yianilos, M. Mueller-Freitag, F. Hoppe, C. Thurau, I. Bax, and R. Memisevic, “The ”something something” video database for learning and evaluating visual common sense,” inProceedings of the IEEE International Conference on Com- puter Vision (ICCV),...
2017
-
[66]
Arid: A new dataset for recognizing action in the dark,
Y . Xu, J. Yang, H. Cao, K. Mao, J. Yin, and S. See, “Arid: A new dataset for recognizing action in the dark,” inInternational workshop on deep learning for human activity recognition. Springer, 2021, pp. 70–84
2021
-
[67]
Rescaling egocentric vision: Collection, pipeline and challenges for epic-kitchens- 100,
D. Damen, H. Doughty, G. M. Farinella, A. Furnari, E. Kazakos, J. Ma, D. Moltisanti, J. Munro, T. Perrett, W. Price, and M. Wray, “Rescaling egocentric vision: Collection, pipeline and challenges for epic-kitchens- 100,”International Journal of Computer Vision, pp. 1–23, 2022
2022
-
[68]
Dreambooth: Fine tuning text-to-image diffusion models for subject- driven generation,
N. Ruiz, Y . Li, V . Jampani, Y . Pritch, M. Rubinstein, and K. Aberman, “Dreambooth: Fine tuning text-to-image diffusion models for subject- driven generation,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 22 500–22 510
2023
-
[69]
Swin-unet: Unet-like pure transformer for medical image segmenta- tion,
H. Cao, Y . Wang, J. Chen, D. Jiang, X. Zhang, Q. Tian, and M. Wang, “Swin-unet: Unet-like pure transformer for medical image segmenta- tion,” inEuropean conference on computer vision. Springer, 2022, pp. 205–218
2022
-
[70]
Learning to prompt for vision- language models,
K. Zhou, J. Yang, C. C. Loy, and Z. Liu, “Learning to prompt for vision- language models,”International Journal of Computer Vision, vol. 130, no. 9, pp. 2337–2348, 2022
2022
-
[71]
X3d: Expanding architectures for efficient video recognition,
C. Feichtenhofer, “X3d: Expanding architectures for efficient video recognition,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 203–213
2020
-
[72]
Maple: Multi-modal prompt learning,
M. U. Khattak, H. Rasheed, M. Maaz, S. Khan, and F. S. Khan, “Maple: Multi-modal prompt learning,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 19 113–19 122
2023
-
[73]
Ta-adapter: Enhancing few-shot clip with task-aware encoders,
W. Zhang, Y . Zhang, Y . Deng, W. Zhang, J. Lin, B. Huang, J. Zhang, and W. Yu, “Ta-adapter: Enhancing few-shot clip with task-aware encoders,” Pattern Recognition, vol. 153, p. 110559, 2024
2024
-
[74]
Grad-cam: Visual explanations from deep networks via gradient-based localization,
R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra, “Grad-cam: Visual explanations from deep networks via gradient-based localization,” inProceedings of the IEEE international conference on computer vision, 2017, pp. 618–626
2017
-
[75]
Watermark and trademark prompts boost video action recognition in visual-language models,
L. Jin, H. Jung, H. J. Jon, and E. Y . Kim, “Watermark and trademark prompts boost video action recognition in visual-language models,” Mathematics, vol. 13, no. 9, p. 1365, 2025
2025
-
[76]
Aa-clip: Enhancing zero-shot anomaly detection via anomaly-aware clip,
W. Ma, X. Zhang, Q. Yao, F. Tang, C. Wu, Y . Li, R. Yan, Z. Jiang, and S. K. Zhou, “Aa-clip: Enhancing zero-shot anomaly detection via anomaly-aware clip,”arXiv preprint arXiv:2503.06661, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.