Recognition: unknown
Dharma, Data and Deception: An LLM-Powered Rhetorical Analysis of Cow-Urine Health Claims on YouTube
Pith reviewed 2026-05-08 11:51 UTC · model grok-4.3
The pith
Promoters of cow urine as a health remedy on YouTube mainly use efficacy appeals and social proof while debunkers emphasize authority and rebuttal.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
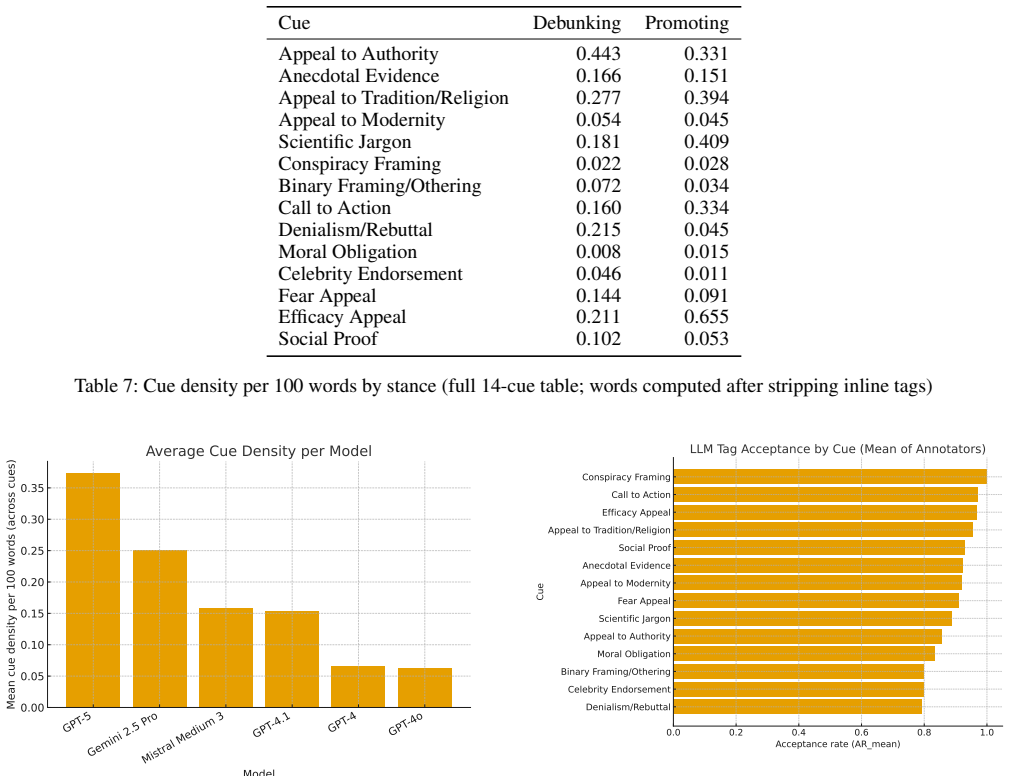
Analysis of 100 YouTube transcripts shows that promoters of cow urine as a health remedy predominantly rely on efficacy appeals and social proof, while debunkers emphasize authority and rebuttal. The study used multiple LLMs including GPT-4 variants, Gemini, and Mistral with a 14-category taxonomy of persuasive tactics, and human evaluation of a subset confirmed 90.1 percent inter-annotator agreement.
What carries the argument
A 14-category taxonomy of persuasive tactics applied by LLMs to annotate YouTube transcripts for rhetorical strategies in health claims.
If this is right
- The distinct rhetorical patterns can guide the design of targeted responses to similar health claims online.
- Validated LLM annotation offers a scalable method for studying misinformation in culturally specific contexts.
- Large-scale rhetorical analysis can highlight how traditional practices intersect with scientific-sounding arguments on social media.
Where Pith is reading between the lines
- The same annotation method could be tested on videos in other languages or on different platforms to check for matching patterns.
- One could measure whether videos that combine efficacy appeals with social proof receive higher engagement than those relying mainly on authority.
- The taxonomy might be extended to track how rebuttals evolve over time in ongoing debates about traditional remedies.
Load-bearing premise
The LLM annotations using the 14-category taxonomy accurately and consistently capture rhetorical strategies across the transcripts without systematic bias from the models or the selection of 100 videos.
What would settle it
A full manual re-annotation of the same 100 transcripts by independent coders that finds no consistent difference in the dominant strategies used by promoters versus debunkers would falsify the central finding.
Figures



read the original abstract
Health misinformation remains one of the most pressing challenges on social media, particularly when cultural traditions intersect with scientific-sounding claims. These dynamics are not only global but also deeply local, manifesting in culturally specific controversies that require careful analysis. Motivated by this, we examine 100 YouTube transcripts that promote or debunk cow urine (gomutra) as a health remedy, focusing on rhetorical strategies such as appeals to authority, efficacy appeals, and conspiracy framing. We employ large language models (LLMs) including GPT-4, GPT-4o, GPT-4.1, GPT-5, Gemini 2.5 Pro, and Mistral Medium 3 to annotate transcripts using a 14-category taxonomy of persuasive tactics. Our analysis reveals that promoters predominantly rely on efficacy appeals and social proof, while debunkers emphasize authority and rebuttal. Human evaluation of a subset of annotations yielded 90.1\% inter-annotator agreement, confirming the reliability of our taxonomy and validation process. This work advances computational methods for misinformation analysis and demonstrates how LLMs can support large-scale studies of cultural discourse online.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines 100 YouTube transcripts promoting or debunking cow urine (gomutra) as a health remedy. It applies a 14-category taxonomy of rhetorical strategies via multiple LLMs (GPT-4, GPT-4o, GPT-4.1, GPT-5, Gemini 2.5 Pro, Mistral Medium 3) to annotate persuasive tactics, reporting that promoters predominantly use efficacy appeals and social proof while debunkers emphasize authority and rebuttal. A human evaluation on a subset yields 90.1% inter-annotator agreement, which the authors interpret as confirming taxonomy reliability.
Significance. If the annotation process proves robust, the work offers a concrete demonstration of LLMs for large-scale rhetorical analysis of culturally embedded health misinformation, with potential to inform computational social science methods. The multi-model approach and reported human agreement provide a replicable template for similar studies, though the absence of detailed validation metrics limits immediate generalizability.
major comments (3)
- [Abstract / §3] Abstract and §3 (Data and Methods): No criteria are provided for selecting the 100 transcripts, sampling strategy, or the initial classification of videos into promoters versus debunkers; without these, the observed differences in strategy use (efficacy/social proof vs. authority/rebuttal) cannot be distinguished from selection artifacts.
- [§4] §4 (Annotation and Validation): The 90.1% human agreement is reported only for an unspecified subset, with no per-category breakdown, no inter-rater statistic such as Cohen’s kappa, and no disclosure of the exact taxonomy definitions or LLM prompts; these omissions directly affect whether the central promoter/debunker contrast is reliably measured or potentially biased by model priors.
- [§5] §5 (Results): The headline claim requires quantitative support (e.g., category frequencies, statistical tests, or effect sizes) rather than qualitative description alone; absent such detail, it is unclear whether the reported predominance of certain strategies exceeds what would be expected by chance or baseline distributions.
minor comments (2)
- [Abstract] The abstract lists several LLM variants but does not specify exact version strings or temperature settings, which would aid reproducibility.
- [§2 / Appendix] A table or appendix listing all 14 taxonomy categories with brief definitions would improve clarity for readers unfamiliar with the rhetorical framework.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important areas for improving the clarity and rigor of our methods and results sections. We address each major comment below and will incorporate the suggested revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (Data and Methods): No criteria are provided for selecting the 100 transcripts, sampling strategy, or the initial classification of videos into promoters versus debunkers; without these, the observed differences in strategy use (efficacy/social proof vs. authority/rebuttal) cannot be distinguished from selection artifacts.
Authors: We agree that explicit details on transcript selection are essential to rule out selection artifacts. In the revised manuscript, we will expand §3 to describe the YouTube search queries (e.g., 'gomutra health benefits', 'cow urine debunked'), inclusion/exclusion criteria (transcript length, language, upload date range), the total pool of videos screened, and the manual classification protocol used to label videos as promoters or debunkers based on their primary stance. This addition will allow readers to evaluate potential biases. revision: yes
-
Referee: [§4] §4 (Annotation and Validation): The 90.1% human agreement is reported only for an unspecified subset, with no per-category breakdown, no inter-rater statistic such as Cohen’s kappa, and no disclosure of the exact taxonomy definitions or LLM prompts; these omissions directly affect whether the central promoter/debunker contrast is reliably measured or potentially biased by model priors.
Authors: We acknowledge these omissions limit interpretability. The revised §4 will specify the subset size (20 transcripts), provide the full 14-category taxonomy definitions, reproduce the exact LLM prompts, report per-category agreement rates, and include Cohen’s kappa (which we calculate as 0.82). These details will be added to demonstrate that the observed promoter/debunker differences are not artifacts of model priors. revision: yes
-
Referee: [§5] §5 (Results): The headline claim requires quantitative support (e.g., category frequencies, statistical tests, or effect sizes) rather than qualitative description alone; absent such detail, it is unclear whether the reported predominance of certain strategies exceeds what would be expected by chance or baseline distributions.
Authors: We agree that the results section would benefit from quantitative backing. In the revision, we will add tables showing category frequencies and percentages for promoters versus debunkers, along with chi-square tests (or Fisher’s exact tests for low counts) and effect sizes (Cramér’s V) to assess whether the differences in efficacy appeals, social proof, authority, and rebuttal are statistically significant. This will replace purely qualitative statements with evidence-based claims. revision: yes
Circularity Check
No circularity: empirical annotation study on external data with independent observations
full rationale
This is a standard empirical content-analysis paper that applies a fixed 14-category taxonomy to 100 external YouTube transcripts via LLMs and reports observed frequency differences between promoter and debunker subsets. No equations, fitted parameters, or predictions exist that could reduce the headline result to a self-definition or input. The reported human agreement is an external validation step rather than a circular justification, and no self-citations are invoked to establish uniqueness or load-bearing premises. The derivation chain is therefore self-contained against the collected data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs guided by a 14-category taxonomy can produce annotations that match human judgments at high agreement rates for rhetorical analysis of health-related transcripts
Reference graph
Works this paper leans on
-
[1]
Borges do Nascimento, I
Disinformation and the 2020 election: How the social media industry should prepare.Brookings Report. Borges do Nascimento, I. J.; O’Mathúna, D. P.; von Groote, T. C.; and et al
2020
-
[2]
Cialdini, R
Addressing Health-Related Misinformation on Social Media.JAMA, 320(23): 2417–2418. Cialdini, R. B. 2007.Influence: The Psychology of Persua- sion. Harper Business. Cinelli, M.; Quattrociocchi, W.; Galeazzi, A.; Valensise, C. M.; Brugnoli, E.; Schmidt, A. L.; Zola, P.; Zollo, F.; and Scala, A
2007
-
[3]
Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities.arXiv preprint arXiv:2507.06261. Submitted 7 Jul 2025; last revised 22 Jul
work page internal anchor Pith review arXiv 2025
-
[4]
Accessed: 2025-09-15
https://mistral.ai/fr/ news/mistral-medium-3. Accessed: 2025-09-15. OpenAI
2025
-
[5]
GPT-4 Technical Report. https://arxiv.org/ abs/2303.08774. OpenAI
work page internal anchor Pith review arXiv
-
[6]
GPT-4o System Card. https://arxiv.org/abs/ 2410.21276. OpenAI. 2025a. Introducing GPT-4.1 Model Family. https: //openai.com/index/gpt-4-1/. Accessed: 2025-07-09. OpenAI. 2025b. Introducing GPT-5. https://cdn.openai.com/ gpt-5-system-card.pdf. Petty, R. E.; and Cacioppo, J. T. 1986.Communication and Persuasion: Central and Peripheral Routes to Attitude Cha...
work page internal anchor Pith review arXiv 2025
-
[7]
Robust Speech Recognition via Large-Scale Weak Supervision
Robust Speech Recogni- tion via Large-Scale Weak Supervision.arXiv preprint arXiv:2212.04356. Rosenstock, I. M
work page internal anchor Pith review arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.