Identifying and typifying demographic unfairness in phoneme-level embeddings of self-supervised speech recognition models
Pith reviewed 2026-05-08 11:38 UTC · model grok-4.3
The pith
Phoneme embeddings in speech models contain both random variance and systematic bias that disadvantage certain speaker groups.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
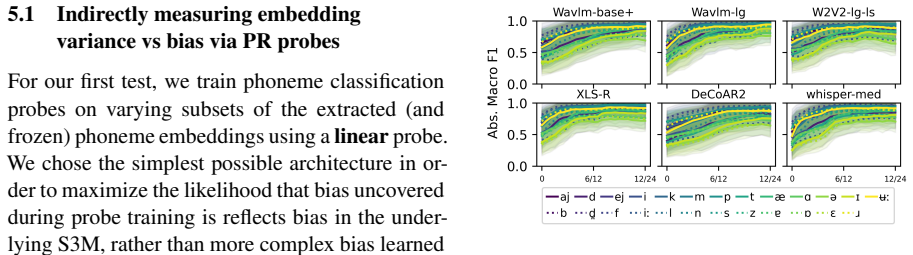
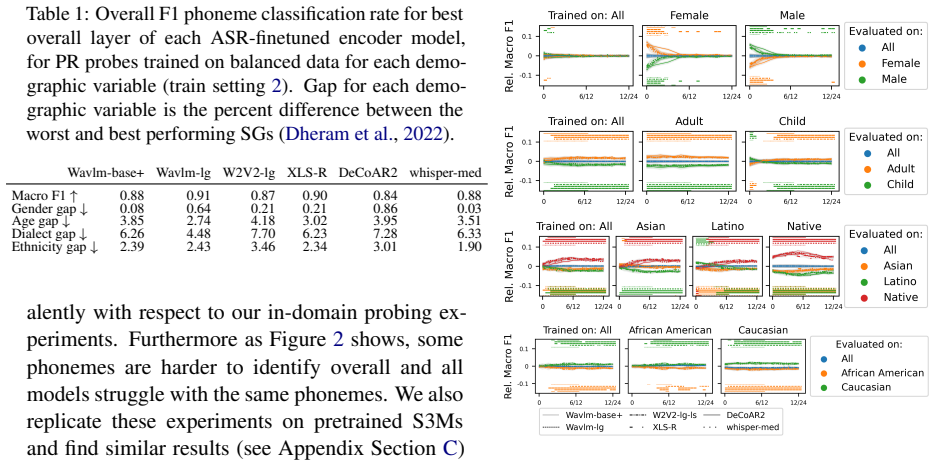
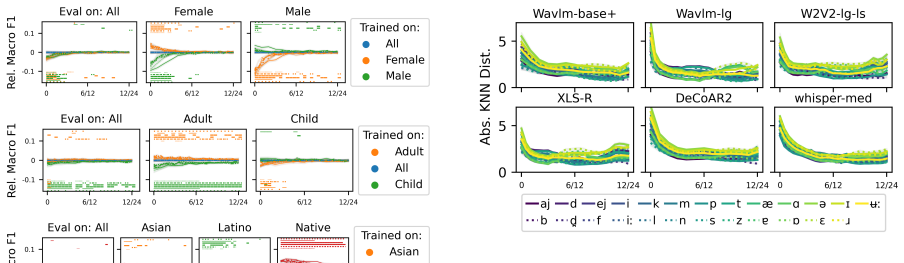
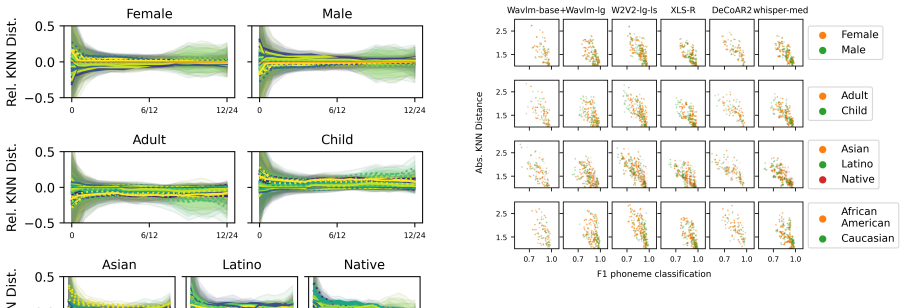
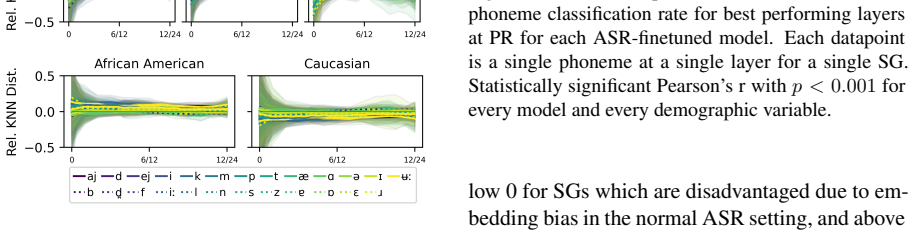
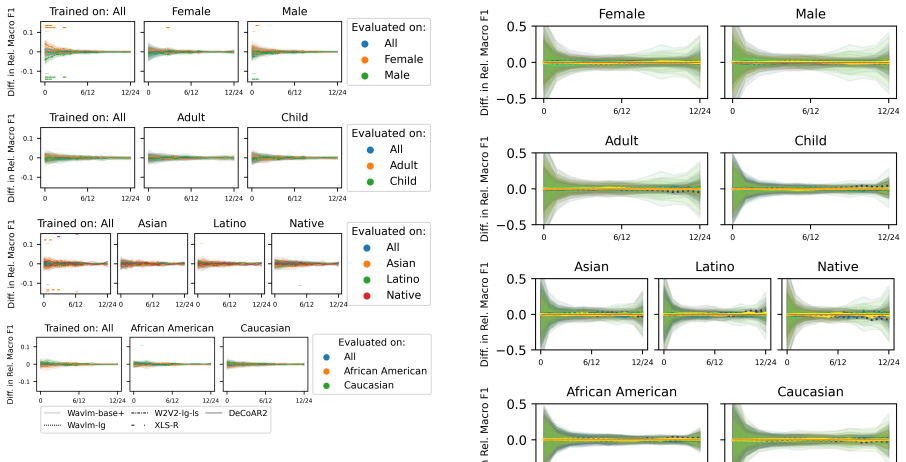
Both types of error—random high-variance embeddings and systematic embedding bias—are present in phoneme-level representations of self-supervised ASR models. Evidence for bias comes from performance gains when phoneme probes are trained on a single disadvantaged speaker group, while random error is shown by the link between higher phoneme variance and lower prediction accuracy. Random error appears to be the larger contributor to demographic unfairness, and standard fairness finetuning does not mitigate either.
What carries the argument
A typification framework distinguishing random error (high variance in phoneme embeddings) from systematic error (embedding bias), measured through phoneme classification probes trained on data from single speaker groups.
If this is right
- Both random variance and systematic bias in phoneme embeddings are candidate causes of speaker group unfairness in ASR.
- Random error likely hinders fairness more than systematic bias.
- Speakers and groups with higher phoneme embedding variance show worse phoneme prediction accuracy.
- Finetuning encoders with domain enhancing and adversarial training leaves both the probe benefits and variance levels unchanged.
Where Pith is reading between the lines
- Methods focused on reducing embedding variance, such as regularization during pretraining, might improve fairness more effectively than current adversarial approaches.
- The probe training technique could serve as a diagnostic tool for measuring demographic bias in other embedding-based systems without retraining the full model.
- Future work might test whether these error types appear similarly in other languages or non-speech audio tasks.
Load-bearing premise
That gains in phoneme probe accuracy from training exclusively on a disadvantaged speaker group reflect bias in the pretrained embeddings rather than artifacts introduced by the probe itself or data selection.
What would settle it
An experiment showing no improvement in phoneme classification when probes are trained only on data from a low-performing speaker group, or finding no correlation between measured phoneme variance and classification error rates across groups.
Figures








read the original abstract
Modern automatic speech recognition (ASR) systems have been observed to function better for certain speaker groups (SGs) than others, despite recent gains in overall performance. One potential impediment to progress towards fairer ASR is a more nuanced understanding of the types of modeling errors that speech encoder models make, and in particular the difference between the structure of embeddings for high-performance and low-performance SGs. This paper proposes a framework typifying two types of error that can occur in modeling phonemes in ASR systems: random error/high variance in phoneme embedding, vs systematic error/embedding bias. We find that training phoneme classification probes only on a single, typically disadvantaged SG, sometimes improves performance for that SG, which is evidence for the existence of SG-level bias in phoneme embeddings. On the other hand, we find that speakers and SGs with higher levels of phoneme variance are the same as those with worse phoneme prediction accuracy. We conclude that both types of error are present in phoneme embeddings and both are candidate causes for SG-level unfairness in ASR, though random error is likely a greater hindrance to fairness than systematic error. Furthermore, we find that finetuning encoder models using a fairness-enhancing algorithm (domain enhancing and adversarial training) changes neither the benefits of in-domain phoneme classification probe training, nor measured levels of random embedding error.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a framework for distinguishing random error (high variance in phoneme embeddings) from systematic error (SG-level embedding bias) in self-supervised ASR models. It reports that phoneme probes trained on a single disadvantaged speaker group (SG) sometimes improve performance for that SG, taken as evidence of systematic bias in the embeddings; it also finds that higher phoneme variance correlates with worse prediction accuracy, suggesting random error is the larger contributor to unfairness. Fairness-enhancing finetuning (domain adaptation and adversarial training) is shown to leave both patterns unchanged.
Significance. If the central experimental claims hold after controls, the typology offers a useful diagnostic lens for phoneme-level sources of demographic unfairness in ASR, separating variance-driven from bias-driven mechanisms. The probe-based detection method and the negative result on standard fairness finetuning are practical contributions that could guide embedding-specific interventions rather than post-hoc fixes.
major comments (2)
- [Probe training results (experiments section describing single-SG probes)] The key evidence for systematic error—that single-SG probe training improves performance for the disadvantaged SG—is presented without isolating the contribution of the frozen encoder embeddings. The probe stage itself can adapt to SG-specific acoustics, label distributions, or selection effects; without reported cross-SG probe evaluation, balanced mixed-data training ablations, or capacity-matched controls, the gain cannot be confidently attributed to pre-existing embedding bias rather than probe adaptation. This directly underpins the claim that systematic error is present and a candidate cause of SG-level unfairness.
- [Abstract and methods/experiments sections] The abstract states that findings support the presence of both error types and that random error is likely greater, yet provides no details on datasets, number of SGs/speakers, statistical tests, error bars, or exclusion criteria. The soundness of the variance-accuracy correlation and the finetuning invariance claims cannot be evaluated without these; if the full paper omits them, the comparative conclusion that random error is the greater hindrance rests on unverified experimental outcomes.
minor comments (1)
- [Introduction and framework section] Notation for speaker groups (SGs) and phoneme variance measures could be defined more explicitly on first use to aid readers unfamiliar with the ASR fairness literature.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address each of the major comments below, providing clarifications and indicating planned revisions to strengthen the paper.
read point-by-point responses
-
Referee: [Probe training results (experiments section describing single-SG probes)] The key evidence for systematic error—that single-SG probe training improves performance for the disadvantaged SG—is presented without isolating the contribution of the frozen encoder embeddings. The probe stage itself can adapt to SG-specific acoustics, label distributions, or selection effects; without reported cross-SG probe evaluation, balanced mixed-data training ablations, or capacity-matched controls, the gain cannot be confidently attributed to pre-existing embedding bias rather than probe adaptation. This directly underpins the claim that systematic error is present and a candidate cause of SG-level unfairness.
Authors: We agree that additional controls are necessary to more confidently attribute the performance gains to biases in the frozen embeddings rather than adaptations during probe training. In the revised manuscript, we will include cross-SG probe evaluations (training on one SG and testing on others), balanced mixed-data training ablations, and capacity-matched controls. These additions will help isolate the contribution of the pre-existing embedding structure. We believe this will support our claim while addressing the concern. revision: yes
-
Referee: [Abstract and methods/experiments sections] The abstract states that findings support the presence of both error types and that random error is likely greater, yet provides no details on datasets, number of SGs/speakers, statistical tests, error bars, or exclusion criteria. The soundness of the variance-accuracy correlation and the finetuning invariance claims cannot be evaluated without these; if the full paper omits them, the comparative conclusion that random error is the greater hindrance rests on unverified experimental outcomes.
Authors: The full manuscript provides the requested details in the methods and experiments sections, including dataset descriptions, the number of speaker groups and speakers, statistical tests performed, error bars on figures, and exclusion criteria. However, we acknowledge that the abstract is too concise and omits these specifics. In the revision, we will expand the abstract to include key information such as the datasets used, number of SGs, and references to the statistical analyses and error reporting. This will allow readers to better evaluate the claims regarding the relative impact of random versus systematic error and the finetuning results. revision: yes
Circularity Check
No circularity; claims rest on independent experimental measurements
full rationale
The paper derives its conclusions from direct experimental results: performance gains when phoneme probes are trained on single disadvantaged speaker groups, and correlations between phoneme variance and prediction accuracy. These measurements are reported as observations rather than derived from definitions or prior self-citations that presuppose the target claims. No equations reduce outputs to inputs by construction, no fitted parameters are relabeled as predictions, and no uniqueness theorems or ansatzes are imported via self-citation. The derivation chain is therefore self-contained against the reported data.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Phoneme classification probes trained on embeddings can reveal underlying bias or variance properties of those embeddings
- domain assumption Defined speaker groups (SGs) are meaningful categories for measuring demographic unfairness in ASR
Reference graph
Works this paper leans on
-
[1]
Exploring simple siamese representation learning, 2020
WavLM: Large-Scale Self-Supervised Pre- Training for Full Stack Speech Processing . IEEE Journal of Selected Topics in Signal Processing , 16(6):1505–1518. Xinlei Chen and Kaiming He. 2020. Exploring Sim- ple Siamese Representation Learning . Preprint, arXiv:2011.10566. Kwanghee Choi, Ankita Pasad, Tomohiko Nakamura, Satoru Fukayama, Karen Livescu, and Sh...
-
[2]
In The 2024 ACM Conference on Fairness, Accountability, and Transparency , pages 1672–1681
Careless Whisper: Speech-to-Text Halluci- nation Harms . In The 2024 ACM Conference on Fairness, Accountability, and Transparency , pages 1672–1681. Jialu Li, Vimal Manohar, Pooja Chitkara, Andros Tjandra, Michael Picheny, Frank Zhang, Xiaohui Zhang, and Y atharth Saraf. 2021. Accent-Robust Automatic Speech Recognition Using Supervised and Unsupervised Wa...
-
[3]
Layer-wise Analysis of a Self-supervised Speech Representation Model . Preprint, arXiv:2107.04734. Ankita Pasad, Bowen Shi, and Karen Livescu. 2023. Comparative layer-wise analysis of self-supervised speech models. Preprint, arXiv:2211.03929. Eliana Pastor, Alkis Koudounas, Giuseppe Attanasio, Dirk Hovy, and Elena Baralis. 2024. Explaining Speech Classific...
-
[4]
Journal of Speech, Language, and Hearing Research, 63(2):533–551
How Does Our V oice Change as We Age? A Systematic Review and Meta-Analysis of Acous- tic and Perceptual V oice Data From Healthy Adults Over 50 Y ears of Age. Journal of Speech, Language, and Hearing Research, 63(2):533–551. Chloe Sekkat, Fanny Leroy, Salima Mdhaffar, Blake Perry Smith, Y annick Estève, Joseph Dureau, and Alice Coucke. 2024. Sonos V oice...
-
[5]
In Interspeech 2008 , pages 2550–
Longitudinal study of ASR performance on ageing voices . In Interspeech 2008 , pages 2550–
work page 2008
-
[6]
A Study of Data Selection Strategies for Pre-training Self-Supervised Speech Models
ISCA. Angelina Wang, Vikram V . Ramaswamy, and Olga Rus- sakovsky. 2022. Towards Intersectionality in Ma- chine Learning: Including More Identities, Handling Underrepresentation, and Performing Evaluation. In 2022 ACM Conference on Fairness Accountability and Transparency, pages 336–349. Ryan Whetten, Titouan Parcollet, Marco Dinarelli, and Y annick Estèv...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[7]
We like- wise repeat out KNN distance analyses on pre- trained S3Ms in Figure 13
We note the same patterns in pretrained mod- els as their ASR-finetuned complements. We like- wise repeat out KNN distance analyses on pre- trained S3Ms in Figure 13. (We excluded Wav2vec 2.0 models to avoid visual contamination by their strange behaving final several layers ( Pasad et al. , 2022)). Note that pretrained models exhibit the same patterns of i...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.