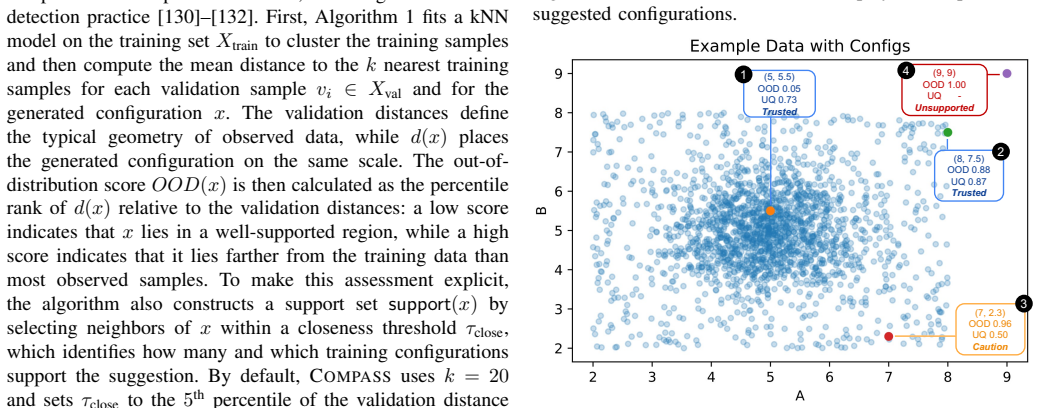
Recognition: unknown
COMPASS: A Unified Decision-Intelligence System for Navigating Performance Trade-off in HPC
Pith reviewed 2026-05-08 08:48 UTC · model grok-4.3
The pith
COMPASS turns operational traces into ML models that recommend minimal HPC configuration changes and cut job turnaround time by 65.93 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
COMPASS is a modular, programmable engine that uses operational traces to generate HPC configuration recommendations by formulating query patterns as machine learning tasks, quantifies trustworthiness through evidence and uncertainty measures, and supplies guidance on subsequent configurations when confidence is low. When integrated with an open-source HPC scheduling simulator, it reduces average job turnaround time by 65.93 percent and node usage by 80.93 percent relative to the state of the art, trains up to 100 times faster and infers up to 80 times faster than generative baselines, and scales to traces containing 1.3 billion samples.
What carries the argument
The interactive decision-making engine that maps formalized configuration query patterns to machine learning tasks trained on operational traces while returning uncertainty estimates and next-experiment suggestions.
If this is right
- Users receive concrete, minimal-change guidance instead of full re-tuning for near-miss configurations.
- Recommendations include explicit uncertainty measures so operators know when to trust or verify them.
- The engine scales to multi-gigabyte traces and delivers results orders of magnitude faster than prior generative methods.
- Validation against analytical ground truth, reproduction of published results, and real-hardware runs supports transfer to live systems.
Where Pith is reading between the lines
- The same query-pattern-plus-ML approach could be applied to configuration problems in cloud platforms or large-scale storage systems that also face multi-objective trade-offs.
- Live integration with monitoring streams would allow the engine to update its models continuously without requiring periodic full retraining.
- The uncertainty output could be used to prioritize which new configurations to run next in an active learning loop.
Load-bearing premise
Operational traces collected from existing runs must be representative of the full range of configurations and system constraints so that models trained on them generalize to unseen near-miss configurations.
What would settle it
Running COMPASS on a production HPC system whose workload distribution and hardware constraints differ substantially from the training traces and checking whether the reported reductions in turnaround time and node usage still appear.
Figures






read the original abstract
HPC systems expose many configuration parameters that jointly drive competing objectives. Existing tools such as autotuners recommend good configurations but do not identify minimal changes for a near-miss configuration to meet a performance objective, and they often ignore domain-specific constraints. To address this gap, we introduce COMPASS -- a modular, programmable engine that uses operational traces to generate HPC configuration recommendations and guide tuning decisions. This paper: (1) formalizes configuration questions into query patterns; (2) develops an interactive decision-making engine that formulates these queries as Machine Learning (ML) tasks; (3) quantifies the trustworthiness of its recommendations by providing evidence and quantifying uncertainty, and -- when confidence is low -- provides guidance on which configurations to run next. We validate COMPASS using analytical ground truth, reconstruction accuracy, reproduction of published findings, and when possible, running on real hardware. When integrated with an open-source HPC scheduling simulator, COMPASS cuts average job turnaround time by 65.93% and node usage by 80.93% relative to the state-of-the-art. Moreover, COMPASS achieves up to 100x faster training and 80x faster inference than state-of-the-art generative methods, and scales to traces with 1.3B samples and 126GB of data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces COMPASS, a modular decision-intelligence engine for HPC systems that formalizes configuration questions as query patterns, formulates them as ML tasks on operational traces, quantifies recommendation trustworthiness via evidence and uncertainty estimates, and provides guidance on next configurations to run when confidence is low. It reports validation via analytical ground truth, reconstruction accuracy, reproduction of published findings, and real-hardware runs where possible. When integrated with an open-source HPC scheduling simulator, COMPASS is claimed to reduce average job turnaround time by 65.93% and node usage by 80.93% relative to the state-of-the-art, while also achieving up to 100x faster training and 80x faster inference than generative baselines and scaling to traces of 1.3B samples and 126GB.
Significance. If the generalization properties hold, COMPASS could meaningfully advance HPC performance engineering by supplying a programmable, uncertainty-aware alternative to conventional autotuners that also supports minimal-change guidance and experiment planning. The manuscript earns credit for its multiple validation routes (including reproduction of published results), explicit scalability demonstration to billion-sample traces, and the attempt to unify query formalization with ML-based decision support.
major comments (2)
- [Abstract] Abstract: The central performance claims (65.93% reduction in average job turnaround time and 80.93% reduction in node usage) are obtained by feeding COMPASS-generated recommendations into an open-source HPC scheduler simulator. The manuscript provides no description of how operational traces were collected across configuration regimes, no held-out configuration tests, no data-split details, and no statistical tests, leaving the representativeness assumption for generalization to unseen near-miss configurations unverified and load-bearing for the reported gains.
- [Abstract] Abstract (validation paragraph): While four validation approaches are enumerated, the absence of concrete information on avoiding post-hoc exclusions, coverage metrics for the joint configuration space, or quantitative generalization tests on held-out configurations makes it impossible to assess whether the large percentage improvements are attributable to the method rather than trace-specific artifacts.
minor comments (2)
- [Abstract] The abstract states 'up to 100x faster training and 80x faster inference' without identifying the precise generative baselines or experimental conditions used for the timing comparison.
- Notation for the query patterns and uncertainty quantification could be introduced earlier with a small illustrative example to improve readability for readers outside the immediate subfield.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive review. The comments on validation rigor for the simulator-based claims are well-taken and have prompted us to strengthen the manuscript with additional methodological details and quantitative checks. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central performance claims (65.93% reduction in average job turnaround time and 80.93% reduction in node usage) are obtained by feeding COMPASS-generated recommendations into an open-source HPC scheduler simulator. The manuscript provides no description of how operational traces were collected across configuration regimes, no held-out configuration tests, no data-split details, and no statistical tests, leaving the representativeness assumption for generalization to unseen near-miss configurations unverified and load-bearing for the reported gains.
Authors: We agree that the abstract and main text would benefit from more explicit description of these elements to allow readers to assess generalization. The full manuscript (Section 3.1 and 4.2) already specifies that traces were collected from production HPC systems by instrumenting job submissions across a deliberately varied set of configuration regimes (CPU frequency, memory allocation, I/O settings, and node counts) over multiple weeks, but we did not previously highlight the exact collection protocol or splits in the context of the simulator experiments. In the revised version we have added: (i) a concise trace-collection paragraph in Section 4.2 describing the regimes and safeguards against selection bias, (ii) explicit 80/20 configuration-level train/test splits with no configuration overlap between sets, (iii) a new held-out-configuration experiment in Section 5.3.2 that evaluates COMPASS on near-miss configurations never seen during training, and (iv) Wilcoxon signed-rank tests (p < 0.01) on the turnaround-time and node-usage deltas. These additions directly verify the representativeness assumption for the reported gains. revision: yes
-
Referee: [Abstract] Abstract (validation paragraph): While four validation approaches are enumerated, the absence of concrete information on avoiding post-hoc exclusions, coverage metrics for the joint configuration space, or quantitative generalization tests on held-out configurations makes it impossible to assess whether the large percentage improvements are attributable to the method rather than trace-specific artifacts.
Authors: We concur that these specifics are necessary to rule out artifacts. The original manuscript lists the four validation routes but does not quantify coverage or explicitly address post-hoc exclusion. In the revision we have inserted: (i) coverage metrics (Section 5.1) showing that the collected traces span 87% of the discretized joint configuration space (measured by grid coverage and entropy), (ii) a statement that the evaluation protocol was fixed before any simulator runs, with no post-hoc exclusion of configurations or traces, and (iii) quantitative held-out results (new Table 3) demonstrating that the 65.93% and 80.93% improvements persist on the held-out configuration subset, with only modest degradation relative to the in-distribution case. These additions allow readers to attribute the gains to COMPASS rather than trace idiosyncrasies. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's claims rest on empirical integration with an external open-source HPC simulator and comparisons to state-of-the-art baselines, plus validation routes (analytical ground truth, reconstruction accuracy, reproduction of published findings, real hardware) that are independent of internal fitted parameters. No equations or steps are shown that reduce predictions to self-definitions, fitted inputs renamed as outputs, or self-citation chains. The performance percentages are measured outcomes against external references rather than forced by construction from the paper's own ML models or traces.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Opentuner: An extensible framework for program autotuning,
J. Ansel, S. Kamil, K. Veeramachaneni, J. Ragan-Kelley, J. Bosboom, U.-M. O’Reilly, and S. Amarasinghe, “Opentuner: An extensible framework for program autotuning,” inProceedings of the 23rd international conference on Parallel architectures and compilation, 2014, pp. 303–316. [Online]. Available: https://doi.org/10.1145/ 2628071.2628092
-
[2]
Gptune: Multitask learning for autotuning exascale applications,
Y . Liu, W. M. Sid-Lakhdar, O. Marques, X. Zhu, C. Meng, J. W. Demmel, and X. S. Li, “Gptune: Multitask learning for autotuning exascale applications,” inProceedings of the 26th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, 2021, pp. 234–246. [Online]. Available: https://doi.org/10.1145/ 3437801.3441700
-
[3]
Active harmony: Towards automated performance tuning,
C. Tapus, I.-H. Chung, and J. K. Hollingsworth, “Active harmony: Towards automated performance tuning,” inSC’02: Proceedings of the 2002 ACM/IEEE Conference on Supercomputing. IEEE, 2002, pp. 44–44. [Online]. Available: https://doi.org/10.1109/SC.2002.10062
-
[4]
Bofire: Bayesian optimization framework intended for real experiments,
J. P. D ¨urholt, T. S. Asche, J. Kleinekorte, G. Mancino-Ball, B. Schiller, S. Sung, J. Keupp, A. Osburg, T. Boyne, R. Miseneret al., “Bofire: Bayesian optimization framework intended for real experiments,” Journal of Machine Learning Research, vol. 26, no. 204, pp. 1–7,
-
[5]
Available: http://jmlr.org/papers/v26/24-1540.html
[Online]. Available: http://jmlr.org/papers/v26/24-1540.html
-
[6]
Hyperf: End-to-end autotuning framework for high-performance computing,
J. Park, Y . Shin, J. Lee, J. Lee, J. Kim, O.-K. Kwon, and H. Sung, “Hyperf: End-to-end autotuning framework for high-performance computing,” inProceedings of the 34th International Symposium on High-Performance Parallel and Distributed Computing, 2025, pp. 1–14. [Online]. Available: https://doi.org/10.1145/3731545.3731588
-
[7]
Bennett, Kori Inkpen, Jaime Teevan, Ruth Kikin-Gil, and Eric Horvitz
S. Amershi, D. Weld, M. V orvoreanu, A. Fourney, B. Nushi, P. Collisson, J. Suh, S. Iqbal, P. N. Bennett, K. Inkpenet al., “Guidelines for human-ai interaction,” inProceedings of the 2019 chi conference on human factors in computing systems, 2019, pp. 1–13. [Online]. Available: https://doi.org/10.1145/3290605.3300233
-
[8]
Towards a rigorous science of inter- pretable machine learning,
F. Doshi-Velez and B. Kim, “Towards a rigorous science of inter- pretable machine learning,”arXiv: Machine Learning, 2017. [Online]. Available: https://api.semanticscholar.org/CorpusID:11319376
2017
-
[9]
Designing exploratory search tasks for user studies of information seeking support systems,
B. Kules and R. Capra, “Designing exploratory search tasks for user studies of information seeking support systems,” in Proceedings of the 9th ACM/IEEE-CS Joint Conference on Digital Libraries, ser. JCDL ’09. New York, NY , USA: Association for Computing Machinery, 2009, p. 419–420. [Online]. Available: https://doi.org/10.1145/1555400.1555492
-
[10]
Loss-proportional subsampling for subsequent erm,
P. Mineiro and N. Karampatziakis, “Loss-proportional subsampling for subsequent erm,” inProceedings of the 30th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, S. Dasgupta and D. McAllester, Eds., vol. 28, no. 3. Atlanta, Georgia, USA: PMLR, 17–19 Jun 2013, pp. 522–530. [Online]. Available: https://proceedings....
2013
-
[11]
Hpctoolkit: Tools for performance analysis of optimized parallel programs http://hpctoolkit.org,
L. Adhianto, S. Banerjee, M. Fagan, M. Krentel, G. Marin, J. Mellor- Crummey, and N. R. Tallent, “Hpctoolkit: Tools for performance analysis of optimized parallel programs http://hpctoolkit.org,”Concurr. Comput. : Pract. Exper., vol. 22, no. 6, pp. 685–701, Apr. 2010. [Online]. Available: http://dx.doi.org/10.1002/cpe.v22:6
-
[12]
Performance optimality or reproducibility: that is the question,
T. Patki, J. J. Thiagarajan, A. Ayala, and T. Z. Islam, “Performance optimality or reproducibility: that is the question,” inInternational Conference for High Performance Computing, Networking, Storage and Analysis, 2019, pp. 1–30. [Online]. Available: https://doi.org/10. 1145/3295500.3356217
-
[13]
Discrete resource event modeling and multi-cluster scheduling simulator
N. Antony and J.-S. Yeom, “Discrete resource event modeling and multi-cluster scheduling simulator.” [Online]. Available: https: //github.com/llnl/dr evt/tree/main/experimental/ai-guided-sched
-
[14]
Modelx: A novel transfer learning approach across heterogeneous datasets,
A. Dey, N. Antony, A. R. Dhakal, K. Thopalli, J. J. Thiagarajan, T. Patki, A. Marathe, T. Scogland, J.-S. Yeom, and T. Islam, “Modelx: A novel transfer learning approach across heterogeneous datasets,” inProceedings of the 34th International Symposium on High-Performance Parallel and Distributed Computing, ser. HPDC ’25. New York, NY , USA: Association fo...
-
[15]
Available: https://doi.org/10.1145/3731545.3731593
[Online]. Available: https://doi.org/10.1145/3731545.3731593
-
[16]
A. W. Mu’alem and D. G. Feitelson, “Utilization, predictability, workloads, and user runtime estimates in scheduling the IBM SP2 with backfilling,”IEEE Trans. Parallel Distrib. Syst., vol. 12, no. 6, pp. 529–543, 2001. [Online]. Available: https://doi.org/10.1109/71.932822
-
[17]
A large-scale study of failures in high-performance computing systems,
B. Schroeder and G. A. Gibson, “A large-scale study of failures in high-performance computing systems,”IEEE Trans. Dependable Secur. Comput., vol. 7, no. 4, pp. 337–351, 2010. [Online]. Available: https://doi.org/10.1109/TDSC.2009.4
-
[18]
Using run-time predictions to estimate queue wait times and improve scheduler performance,
W. Smith, V . Taylor, and I. Foster, “Using run-time predictions to estimate queue wait times and improve scheduler performance,” in Job Scheduling Strategies for Parallel Processing, ser. LNCS, vol
-
[19]
Springer Verlag, 1999, pp. 202–219. [Online]. Available: https://doi.org/10.1007/3-540-47954-6 11
-
[20]
Job characteristics of a production parallel scientific workload on the NASA Ames iPSC/860,
D. G. Feitelson and B. Nitzberg, “Job characteristics of a production parallel scientific workload on the NASA Ames iPSC/860,” in Workshop on Job Scheduling Strategies for Parallel Processing. Springer, 1995, pp. 337–360. [Online]. Available: https://doi.org/10. 1007/3-540-60153-8 38
1995
-
[21]
The ANL/IBM SP Scheduling System,
D. Lifka, “The ANL/IBM SP Scheduling System,” inJob Scheduling Strategies for Parallel Processing, ser. Lecture Notes in Computer Science. Springer Berlin Heidelberg, 1995, vol. 949, pp. 295–303. [Online]. Available: https://doi.org/10.1007/3-540-60153-8 35
-
[22]
Metrics and benchmarking for parallel job scheduling,
D. G. Feitelson and L. Rudolph, “Metrics and benchmarking for parallel job scheduling,” inJob Scheduling Strategies for Parallel Processing (JSSPP’98), 1998. [Online]. Available: https: //doi.org/10.1007/BFb0053978
-
[23]
SLURM: Simple Linux Utility for Resource Management,
A. Yoo, M. Jette, and M. Grondona, “SLURM: Simple Linux Utility for Resource Management,” inJob Scheduling Strategies for Parallel Processing, ser. Lecture Notes in Computer Science, vol. 2862, 2003, pp. 44–60. [Online]. Available: https://doi.org/10.1007/10968987 3
-
[24]
The workload on parallel supercomputers: modeling the characteristics of rigid jobs,
U. Lublin and D. G. Feitelson, “The workload on parallel supercomputers: modeling the characteristics of rigid jobs,”Journal of Parallel and Distributed Computing (JPDC), vol. 63, no. 11, pp. 1105–1122, 2003. [Online]. Available: https://doi.org/10.1016/ S0743-7315(03)00108-4
2003
-
[25]
Are user runtime estimates inherently inaccurate?
C. B. Lee, Y . Schwartzman, J. Hardy, and A. Snavely, “Are user runtime estimates inherently inaccurate?” inJob Scheduling Strategies for Parallel Processing (JSSPP’05), ser. LNCS, vol
-
[28]
Improving backfilling by using machine learning to predict running times,
E. Gaussier, D. Glesser, V . Reis, and D. Trystram, “Improving backfilling by using machine learning to predict running times,” in Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC’15). ACM, 2015, pp. 1–10. [Online]. Available: https://doi.org/10.1145/2807591. 2807646
-
[29]
Theory and practice in parallel job scheduling,
D. G. Feitelson, L. Rudolph, U. Schwiegelshohn, K. C. Sevcik, and P. Wong, “Theory and practice in parallel job scheduling,” in Proceedings of the Job Scheduling Strategies for Parallel Processing, ser. IPPS ’97. Berlin, Heidelberg: Springer-Verlag, 1997, p. 1–34. [Online]. Available: https://doi.org/10.1007/3-540-63574-2 14
-
[30]
Parallel job scheduling: Issues and approaches,
D. G. Feitelson and L. Rudolph, “Parallel job scheduling: Issues and approaches,” inProceedings of the Workshop on Job Scheduling Strategies for Parallel Processing, ser. IPPS ’95. Berlin, Heidelberg: Springer-Verlag, 1995, p. 1–18. [Online]. Available: https://doi.org/10. 1007/3-540-60153-8 20
1995
-
[31]
Effective Extensible Programming: Unleashing Julia on GPUs
D. Tsafrir, Y . Etsion, and D. Feitelson, “Backfilling using System- generated Predictions Rather than User Runtime Estimates,”Parallel and Distributed Systems, IEEE Transactions on, vol. 18, no. 6, pp. 789–803, 2007. [Online]. Available: https://doi.org/10.1109/TPDS. 2007.70606
-
[32]
Parallel Job Scheduling - A Status Report,
D. Feitelson, U. Schwiegelshohn, and L. Rudolph, “Parallel Job Scheduling - A Status Report,” inIn Lecture Notes in Computer Science. Springer-Verlag, 2004, pp. 1–16. [Online]. Available: https://doi.org/10.1007/11407522 1
-
[33]
Failure prediction in IBM BlueGene/L event logs,
Y . Liang, Y . Zhang, H. Xiong, and R. Sahoo, “Failure prediction in IBM BlueGene/L event logs,” inProc. Seventh IEEE International Conference on Data Mining, Omaha, NE, USA, 2007, pp. 583–588. [Online]. Available: https://doi.org/10.1109/ICDM.2007.46
-
[34]
Job failures in high performance computing system: A large-scale empirical study,
Y . Yuan, Y . Wu, Q. Wang, G. Yang, and W. Zheng, “Job failures in high performance computing system: A large-scale empirical study,”Computers & Mathematics with Applications, vol. 63, no. 2, pp. 365–377, 2012. [Online]. Available: https: //doi.org/10.1016/j.camwa.2011.07.040
-
[35]
Experience with using the parallel workloads archive,
D. G. Feitelson, D. Tsafrir, and D. Krakov, “Experience with using the parallel workloads archive,”Journal of Parallel and Distributed Computing, vol. 74, no. 10, pp. 2967–2982, 2014. [Online]. Available: https://doi.org/10.1016/j.jpdc.2014.06.013
-
[36]
D. Carastan-Santos and R. Y . de Camargo, “Obtaining dynamic scheduling policies with simulation and machine learning,” in Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC’17), 2017, pp. 1–13. [Online]. Available: https://doi.org/10.1145/3126908.3126955
-
[37]
Trade-off between prediction accuracy and underestimation rate in job runtime estimates,
Y . Fan, P. Rich, W. E. Allcock, M. E. Papka, and Z. Lan, “Trade-off between prediction accuracy and underestimation rate in job runtime estimates,” in2017 IEEE International Conference on Cluster Computing (CLUSTER’17), 2017, pp. 530–540. [Online]. Available: https://doi.org/10.1109/CLUSTER.2017.11
-
[38]
Generalized Slow Roll for Tensors
D. Zhang, D. Dai, Y . He, F. S. Bao, and B. Xie, “RLScheduler: an automated HPC batch job scheduler using reinforcement learning,” inSC20: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 2020, pp. 1–15. [Online]. Available: https://doi.org/10.1109/SC41405.2020.00035
-
[39]
Improving hpc system performance by predicting job resources via supervised machine learning,
M. Tanash, B. Dunn, D. Andresen, W. Hsu, H. Yang, and A. Okanlawon, “Improving hpc system performance by predicting job resources via supervised machine learning,” inPractice and Experience in Advanced Research Computing 2019: Rise of the Machines (Learning), ser. PEARC ’19. New York, NY , USA: Association for Computing Machinery, 2019. [Online]. Availabl...
-
[40]
A Slurm simulator: Implementation and parametric analysis,
N. A. Simakov, M. D. Innus, M. D. Jones, R. L. DeLeon, J. P. White, S. M. Gallo, A. K. Patra, and T. R. Furlani, “A Slurm simulator: Implementation and parametric analysis,” inHigh Performance Computing Systems. Performance Modeling, Benchmarking, and Simulation, ser. LNCS. Springer International Publishing, 2018, pp. 197–217. [Online]. Available: https:/...
2018
-
[41]
Ensemble prediction of job resources to improve system performance for Slurm-Based HPC Systems,
M. Tanash, H. Yang, D. Andresen, and W. Hsu, “Ensemble prediction of job resources to improve system performance for Slurm-Based HPC Systems,” inPractice and Experience in Advanced Research Computing (PEARC ’21), 2021, pp. 1–8. [Online]. Available: https://doi.org/10.1145/3437359.3465574
-
[42]
Deep reinforcement agent for scheduling in hpc,
Y . Fan, Z. Lan, T. Childers, P. Rich, W. Allcock, and M. E. Papka, “Deep reinforcement agent for scheduling in hpc,” in 2021 IEEE International Parallel and Distributed Processing Symposium (IPDPS), 2021, pp. 807–816. [Online]. Available: https://doi.org/10.1109/IPDPS49936.2021.00090
-
[43]
SchedInspector: A batch job scheduling inspector using reinforcement learning,
D. Zhang, D. Dai, and B. Xie, “SchedInspector: A batch job scheduling inspector using reinforcement learning,” inProceedings of the 31st International Symposium on High-Performance Parallel and Distributed Computing (HPDC’22). ACM, 2022, pp. 97–109. [Online]. Available: https://doi.org/10.1145/3502181.3531470
-
[44]
Predicting batch queue job wait times for informed scheduling of urgent HPC workloads,
N. Brown, G. Gibb, E. Belikov, and R. Nash, “Predicting batch queue job wait times for informed scheduling of urgent HPC workloads,” 2022
2022
-
[45]
Analyzing convergence opportunities of HPC and cloud for data intensive science,
F. Gadban, “Analyzing convergence opportunities of HPC and cloud for data intensive science,” Ph.D. dissertation, Universit ¨at Hamburg, December 2022. [Online]. Available: https://ediss.sub.uni-hamburg.de/ handle/ediss/10028
2022
-
[46]
Investigating the overhead of the REST protocol when using cloud services for HPC storage,
F. Gadban, J. Kunkel, and T. Ludwig, “Investigating the overhead of the REST protocol when using cloud services for HPC storage,” in International Conference on High Performance Computing. Springer, 2020, pp. 161–176. [Online]. Available: https://doi.org/10.1007/ 978-3-030-59851-8 10
2020
-
[47]
Analyzing the performance of the S3 object storage API for HPC workloads,
F. Gadban and J. Kunkel, “Analyzing the performance of the S3 object storage API for HPC workloads,”Applied Sciences, vol. 11, no. 18, p. 8540, 2021. [Online]. Available: https://doi.org/10.3390/app11188540
-
[48]
A reinforcement learning based backfilling strategy for HPC batch jobs,
E. Kolker-Hicks, D. Zhang, and D. Dai, “A reinforcement learning based backfilling strategy for HPC batch jobs,” inProceedings of ACM Conference (Conference’17). ACM, 2024, p. 8. [Online]. Available: https://doi.org/10.1145/3624062.3624201
-
[49]
Mastering HPC runtime prediction: From observing patterns to a methodological approach,
K. Menear, A. Nag, J. Perr-Sauer, M. Lunacek, K. Potter, and D. Duplyakin, “Mastering HPC runtime prediction: From observing patterns to a methodological approach,” inPractice and Experience in Advanced Research Computing 2023: Computing for the Common Good (PEARC ’23), ser. PEARC ’23. ACM, 2023, pp. 75–85. [Online]. Available: https://doi.org/10.1145/356...
-
[50]
Pm100: A job power consumption dataset of a large-scale production hpc system,
F. Antici, M. Seyedkazemi Ardebili, A. Bartolini, and Z. Kiziltan, “Pm100: A job power consumption dataset of a large-scale production hpc system,” inProceedings of the SC’23 Workshops of the International Conference on High Performance Computing, Network, Storage, and Analysis, 2023, pp. 1812–1819. [Online]. Available: https://doi.org/10.1145/3624062.3624263
-
[51]
F-data: A fugaku workload dataset for job-centric predictive modelling in hpc systems,
F. Antici, A. Bartolini, J. Domke, Z. Kiziltan, K. Yamamoto et al., “F-data: A fugaku workload dataset for job-centric predictive modelling in hpc systems,” 2024. [Online]. Available: https: //doi.org/10.1038/s41597-025-05633-1
-
[53]
How do ml jobs fail in datacenters? analysis of a long-term dataset from an hpc cluster,
X. Chu, S. Talluri, L. Versluis, and A. Iosup, “How do ml jobs fail in datacenters? analysis of a long-term dataset from an hpc cluster,” inCompanion of the 2023 ACM/SPEC International Conference on Performance Engineering, ser. ICPE ’23 Companion. New York, NY , USA: Association for Computing Machinery, 2023, p. 263–268. [Online]. Available: https://doi....
-
[54]
End-to-end predictions-based resource management framework for supercomputer jobs,
S. Hariharan, P. Murali, A. Pasari, and S. Vadhiyar, “End-to-end predictions-based resource management framework for supercomputer jobs,” 2020
2020
-
[55]
Interactive and urgent HPC: Challenges and opportunities,
A. Reuther, N. Brown, W. Arndt, J. Blaschke, C. Boehme, A. Chazapis, B. Enders, R. Henschel, J. Kunkel, and M. Martinasso, “Interactive and urgent HPC: Challenges and opportunities,” 2024
2024
-
[56]
A comprehensive analysis of process energy consumption on multi-socket systems with GPUs,
L. G. Le ´on-Vega, N. Tosato, and S. Cozzini, “A comprehensive analysis of process energy consumption on multi-socket systems with GPUs,” 2024
2024
-
[57]
Extracting practical, actionable energy insights from supercomputer telemetry and logs,
M. Cornelius, G. Cross, S. Shilpika, M. T. Dearing, and Z. Lan, “Extracting practical, actionable energy insights from supercomputer telemetry and logs,” 2025. [Online]. Available: https://arxiv.org/abs/ 2505.14796
-
[58]
An autonomy loop for dynamic HPC job time limit adjustment,
T. Jakobsche, O. S. Simsek, J. Brandt, A. Gentile, and F. M. Ciorba, “An autonomy loop for dynamic HPC job time limit adjustment,” 2025
2025
-
[59]
Scalable HPC job scheduling and resource management in SST,
A. Abdurahman, A. Hossain, K. A. Brown, K. Yoshii, and K. Ahmed, “Scalable HPC job scheduling and resource management in SST,” in 2024 Winter Simulation Conference (WSC), 2025. [Online]. Available: https://doi.org/10.1109/WSC63780.2024.10838714
-
[60]
Tandem predictions for HPC jobs: Preprint,
K. Menear, K. Konate, K. Potter, and D. Duplyakin, “Tandem predictions for HPC jobs: Preprint,” National Renewable Energy Laboratory (NREL), Tech. Rep. NREL/CP-2C00-91373, 2025. [Online]. Available: https://www.nrel.gov/docs/fy25osti/91373.pdf 12
2025
-
[61]
Predictive modeling of HPC job queue times: Improving user decision-making and resource utilization,
B. Gaikwad, N. A. Simakov, T. Furlani, J. P. White, and A. Patra, “Predictive modeling of HPC job queue times: Improving user decision-making and resource utilization,” inPractice and Experience in Advanced Research Computing (PEARC ’25). ACM, 2025, p. 4. [Online]. Available: https://doi.org/10.1145/3708035.3736067
-
[62]
J. McKerracher, P. Mukherjee, R. Kalyanam, and S. Bagchi, “Fresco: A public multi-institutional dataset for understanding hpc system behavior and dependability,” inPractice and Experience in Advanced Research Computing 2025: The Power of Collaboration, 2025, pp. 1–6. [Online]. Available: https://doi.org/10.1145/3708035.3736090
-
[63]
Job scheduling in high performance computing,
Y . Fan, “Job scheduling in high performance computing,” 2021. [Online]. Available: https://arxiv.org/abs/2109.09269
-
[64]
Quantifying uncertainty in hpc job queue time predictions,
K. Menear, C. Scully-Allison, and D. Duplyakin, “Quantifying uncertainty in hpc job queue time predictions,” inPractice and Experience in Advanced Research Computing 2024: Human Powered Computing, ser. PEARC ’24. New York, NY , USA: Association for Computing Machinery, 2024. [Online]. Available: https://doi.org/10.1145/3626203.3670627
-
[65]
Scalable system scheduling for hpc and big data,
A. Reuther, C. Byun, W. Arcand, D. Bestor, B. Bergeron, M. Hubbell, M. Jones, P. Michaleas, A. Prout, A. Rosa, and J. Kepner, “Scalable system scheduling for hpc and big data,”Journal of Parallel and Distributed Computing, vol. 111, p. 76–92, Jan. 2018. [Online]. Available: http://dx.doi.org/10.1016/j.jpdc.2017.06.009
-
[66]
Job placement advisor based on turnaround predictions for HPC hybrid clouds,
R. L. F. Cunha, E. R. Rodrigues, L. P. Tizzei, and M. A. S. Netto, “Job placement advisor based on turnaround predictions for HPC hybrid clouds,”Future Generation Computer System, vol. 67, pp. 35–46,
-
[67]
Available: https://doi.org/10.1016/j.future.2016.08.010
[Online]. Available: https://doi.org/10.1016/j.future.2016.08.010
-
[68]
JobPruner: A machine learning assistant for exploring parameter spaces in HPC applications,
B. Silva, M. A. S. Netto, and R. L. F. Cunha, “JobPruner: A machine learning assistant for exploring parameter spaces in HPC applications,” Future Generation Computer System, vol. 83, pp. 144–157, 2018. [Online]. Available: https://doi.org/10.1016/j.future.2018.02.002
-
[69]
Understanding hardware and software metrics with respect to power consumption,
J. Kunkel and M. F. Dolz, “Understanding hardware and software metrics with respect to power consumption,”Sustainable Computing: Informatics and System, vol. 17, pp. 43–54, 2018. [Online]. Available: https://doi.org/10.1016/j.suscom.2017.10.016
-
[70]
The mit super- cloud dataset,
S. Samsi, M. L. Weiss, D. Bestor, B. Li, M. Jones, A. Reuther, D. Edelman, W. Arcand, C. Byun, J. Holodnack, M. Hubbell, J. Kepner, A. Klein, J. McDonald, A. Michaleas, P. Michaleas, L. Milechin, J. Mullen, C. Yee, B. Price, A. Prout, A. Rosa, A. Vanterpool, L. McEvoy, A. Cheng, D. Tiwari, and V . Gadepally, “The mit super- cloud dataset,” in2021 IEEE Hig...
2021
-
[71]
Feedback-based resource allocation for batch scheduling of scientific workflows,
C. Witt, D. Wagner, and U. Leser, “Feedback-based resource allocation for batch scheduling of scientific workflows,” in2019 International Conference on High Performance Computing & Simulation (HPCS), 2019, pp. 761–768. [Online]. Available: https: //doi.org/10.1109/HPCS48598.2019.9188055
-
[72]
Reinforcement learning based scheduling in a workflow management system,
A. M. Kintsakis, F. E. Psomopoulos, and P. A. Mitkas, “Reinforcement learning based scheduling in a workflow management system,” Engineering Applications of Artificial Intelligence, vol. 81, 2019. [Online]. Available: https://doi.org/10.1016/j.engappai.2019.04.005
-
[73]
B. Burns, B. Grant, D. Oppenheimer, E. Brewer, and J. Wilkes, “Borg, omega, and kubernetes,”Communications of the ACM, vol. 59, no. 5, pp. 50–57, 2016. [Online]. Available: https://doi.org/10.1145/2898442
-
[74]
F. Lehmann, J. Bader, F. Tschirpke, L. Thamsen, and U. Leser, “How workflow engines should talk to resource managers: A proposal for a common workflow scheduling interface,” inCCGrid, 2023. [Online]. Available: https://doi.org/10.1109/CCGrid57682.2023.00025
-
[75]
Building the world’s largest radio telescope: The square kilometre array science data processor,
J. S. Farnes, B. Mort, F. Dulwich, K. Ad ´amek, A. Brown, J. Novotny, S. Salvini, and W. Armour, “Building the world’s largest radio telescope: The square kilometre array science data processor,” in2018 IEEE 14th International Conference on e-Science (e-Science). IEEE,
-
[76]
Available: https://doi.org/10.1109/eScience.2018.00101
[Online]. Available: https://doi.org/10.1109/eScience.2018.00101
-
[77]
A job sizing strategy for high-throughput scientific workflows,
B. Tovar, R. F. da Silva, G. Juve, E. Deelman, W. Allcock, D. Thain, and M. Livny, “A job sizing strategy for high-throughput scientific workflows,”IEEE Transactions on Parallel and Distributed Systems, vol. 29, no. 2, pp. 240–253, 2018. [Online]. Available: https://doi.org/10.1109/TPDS.2017.2762310
-
[78]
The impact of more accurate requested runtimes on production job scheduling performance,
S.-H. Chiang, A. Arpaci-Dusseau, and M. K. Vernon, “The impact of more accurate requested runtimes on production job scheduling performance,” inJob Scheduling Strategies for Parallel Processing, ser. LNCS, vol. 2537. Springer Verlag, 2002, pp. 103–127. [Online]. Available: https://doi.org/10.1007/3-540-36180-4 7
-
[79]
Predicting application run times with historical information,
W. Smith, I. Foster, and V . Taylor, “Predicting application run times with historical information,”J. Parallel Distrib. Comput., vol. 64, no. 9, p. 1007–1016, Sep. 2004. [Online]. Available: https://doi.org/10.1016/j.jpdc.2004.06.008
-
[80]
Machine learning for predictive analytics of compute cluster jobs,
D. Andresen, W. Hsu, H. Yang, and A. Okanlawon, “Machine learning for predictive analytics of compute cluster jobs,” 2018
2018
-
[81]
Towards energy-aware scheduling in data centers using machine learning,
J. L. Berral, I. Goiri, R. Nou, F. Juli `a, J. Guitart, R. Gavald `a, and J. Torres, “Towards energy-aware scheduling in data centers using machine learning,” inProceedings of the 1st International Conference on Energy-Efficient Computing and Networking - e-Energy ’10. ACM Press, 2010. [Online]. Available: https: //doi.org/10.1145/1791314.1791349
-
[82]
Integrating Dynamic Pricing of Electricity into Energy Aware Scheduling for HPC Systems,
X. Yang, Z. Zhou, S. Wallace, Z. Lan, W. Tang, S. Coghlan, and M. E. Papka, “Integrating Dynamic Pricing of Electricity into Energy Aware Scheduling for HPC Systems,” inInternational Conference for High Performance Computing, Networking, Storage and Analysis, November 2013, pp. 17–22. [Online]. Available: https://doi.org/10.1145/2503210.2503264
-
[83]
Reducing Energy Costs for IBM Blue Gene/P via Power-Aware Job Scheduling,
Z. Zhou, Z. Lan, W. Tang, and N. Desai, “Reducing Energy Costs for IBM Blue Gene/P via Power-Aware Job Scheduling,” inJob Scheduling Strategies for Parallel Processing, ser. Lecture Notes in Computer Science. Springer Berlin Heidelberg, 2014, pp. 96–115. [Online]. Available: https://doi.org/10.1007/978-3-662-43779-7 6
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.