Recognition: unknown
Long-tail Internet photo reconstruction
Pith reviewed 2026-05-08 12:19 UTC · model grok-4.3
The pith
Simulating sparse photo subsets from dense landmarks lets 3D models handle long-tail Internet scenes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors introduce MegaDepth-X, a dataset of 3D reconstructions supplied with clean dense depth, together with a sampling procedure that selects sets of training images whose camera distributions, noise levels, and coverage gaps match those found in long-tail scenes. Finetuning 3D foundation models on these components produces models that deliver robust reconstructions under extreme sparsity, improve reliability on symmetric and repetitive scenes, and preserve generalization on conventional dense 3D benchmarks.
What carries the argument
MegaDepth-X dataset paired with the sparse-subset sampling strategy that draws training images from dense Internet landmark reconstructions.
If this is right
- Reconstruction succeeds from extremely small numbers of input photos drawn from long-tail scenes.
- Reliability increases on scenes containing symmetry or repetitive textures that normally break correspondence.
- Accuracy on standard dense 3D benchmark datasets remains unchanged after the finetuning step.
- 3D foundation models become adaptable to the long-tail regime without requiring new dense ground-truth capture.
Where Pith is reading between the lines
- Casual tourist photos alone could suffice for 3D modeling of heritage sites or everyday locations.
- The same simulation tactic might be tested on other sparse-data problems such as video-based reconstruction or multi-view stereo in different environments.
- If the simulation proves faithful, it could lower the cost of acquiring training data for future sparse-scene methods.
Load-bearing premise
Sampling sparse subsets from well-reconstructed dense landmarks accurately reproduces the camera distributions, noise patterns, and coverage gaps that occur in genuine long-tail real-world scenes.
What would settle it
Run the finetuned model on a collection of actual long-tail Internet sites that possess independent ground-truth 3D data and were never derived from dense reconstructions; if accuracy does not exceed or match the untuned baseline, the simulation claim fails.
Figures







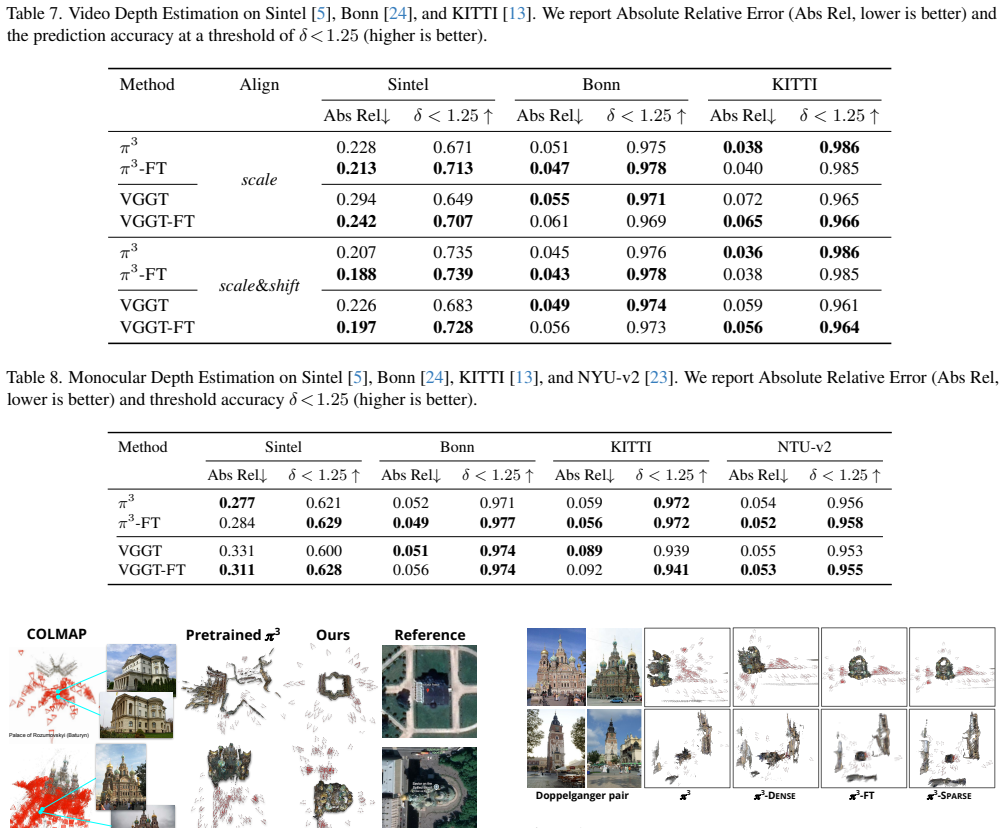



read the original abstract
Internet photo collections exhibit an extremely long-tailed distribution: a few famous landmarks are densely photographed and easily reconstructed in 3D, while most real-world sites are represented with sparse, noisy, uneven imagery beyond the capabilities of both classical and learned 3D methods. We believe that tackling this long-tail regime represents one of the next frontiers for 3D foundation models. Although reliable ground-truth 3D supervision from sparse scenes is challenging to acquire, we observe that it can be effectively simulated by sampling sparse subsets from well-reconstructed Internet landmarks. To this end, we introduce MegaDepth-X, a large dataset of 3D reconstructions with clean, dense depth, together with a strategy for sampling sets of training images that mimic camera distributions in long-tail scenes. Finetuning 3D foundation models with these components yields robust reconstructions under extreme sparsity, and also enables more reliable reconstruction in symmetric and repetitive scenes, while preserving generalization to standard, dense 3D benchmark datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MegaDepth-X, a large dataset of 3D reconstructions with clean dense depth derived from Internet landmarks, together with a sampling strategy that selects sparse image subsets to simulate the camera distributions, noise, and coverage gaps typical of long-tail Internet photo collections. Finetuning 3D foundation models on this data is claimed to produce robust reconstructions under extreme sparsity and in symmetric/repetitive scenes while preserving generalization on standard dense 3D benchmarks.
Significance. If the simulation strategy accurately reproduces the statistical properties of real long-tail scenes, the work would meaningfully advance 3D foundation models toward practical use on the vast majority of Internet sites that lack dense photography. The explicit goal of maintaining performance on conventional benchmarks while improving robustness on challenging cases is a constructive contribution.
major comments (2)
- [Abstract] Abstract: The central effectiveness claims (robustness under extreme sparsity, improved handling of symmetry/repetition) are stated without any quantitative metrics, ablation results, or baseline comparisons, leaving the magnitude and reliability of the reported gains unassessable from the provided summary.
- [Section 3] Section 3 (MegaDepth-X construction and sampling strategy): The load-bearing assumption that sparse subsets drawn exclusively from already-successfully-reconstructed landmarks reproduce the camera-pose clustering, depth noise profiles, and coverage gaps of genuine long-tail scenes that fail classical SfM is not directly validated; without side-by-side statistics or failure-case comparisons against real unsuccessful Internet collections, transfer of the observed improvements remains uncertain.
minor comments (1)
- [Abstract] Abstract: Consider including one or two key quantitative highlights (e.g., percentage improvement on sparsity metrics) to give readers an immediate sense of effect size.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review of our manuscript on long-tail Internet photo reconstruction. We address each major comment below and have revised the paper to strengthen the presentation of our results and the validation of our approach.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central effectiveness claims (robustness under extreme sparsity, improved handling of symmetry/repetition) are stated without any quantitative metrics, ablation results, or baseline comparisons, leaving the magnitude and reliability of the reported gains unassessable from the provided summary.
Authors: We agree that the abstract would benefit from quantitative support to make the effectiveness claims more assessable. In the revised manuscript, we have updated the abstract to include specific metrics from our experiments, such as reconstruction accuracy gains under extreme sparsity, success rates on symmetric and repetitive scenes, and comparisons to baseline methods, while preserving the abstract's conciseness. revision: yes
-
Referee: [Section 3] Section 3 (MegaDepth-X construction and sampling strategy): The load-bearing assumption that sparse subsets drawn exclusively from already-successfully-reconstructed landmarks reproduce the camera-pose clustering, depth noise profiles, and coverage gaps of genuine long-tail scenes that fail classical SfM is not directly validated; without side-by-side statistics or failure-case comparisons against real unsuccessful Internet collections, transfer of the observed improvements remains uncertain.
Authors: We acknowledge the value of further validating the sampling strategy. We have expanded Section 3 with side-by-side statistical comparisons of camera-pose clustering, depth noise profiles, and coverage gaps between our sampled subsets and real sparse Internet photo collections that present challenges for classical SfM. We argue that this supports transferability. However, direct failure-case comparisons to scenes that completely failed SfM remain inherently limited, as such scenes lack reliable ground-truth 3D data by definition. revision: partial
- Direct failure-case comparisons against real unsuccessful Internet collections that failed classical SfM, as these lack ground-truth 3D reconstructions by nature.
Circularity Check
No significant circularity in derivation or claims
full rationale
The paper's chain consists of an empirical methodology: constructing MegaDepth-X via sparse subset sampling from pre-existing dense landmark reconstructions (a heuristic justified by the observation that ground-truth supervision is hard to acquire directly), followed by finetuning of foundation models and evaluation on independent standard dense 3D benchmarks plus the simulated sparse splits. No equations, fitted parameters, or predictions are presented that reduce to the inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The performance claims rest on experimental results rather than tautological re-derivation, keeping the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Sparse subsets sampled from dense Internet landmark reconstructions accurately represent the camera distributions and noise characteristics of long-tail real-world scenes.
invented entities (1)
-
MegaDepth-X dataset
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Building rome in a day.Communications of the ACM, 54(10): 105–112, 2011
Sameer Agarwal, Yasutaka Furukawa, Noah Snavely, Ian Simon, Brian Curless, Steven M Seitz, and Richard Szeliski. Building rome in a day.Communications of the ACM, 54(10): 105–112, 2011. 2
2011
-
[2]
Neural rgb-d surface reconstruction
Dejan Azinovi´c, Ricardo Martin-Brualla, Dan B Goldman, Matthias Nießner, and Justus Thies. Neural rgb-d surface reconstruction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6290–6301, 2022. 6, 7, 8
2022
-
[3]
Extreme rotation estimation in the wild
Hana Bezalel, Dotan Ankri, Ruojin Cai, and Hadar Averbach- Elor. Extreme rotation estimation in the wild. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1061–1070, 2025. 3
2025
-
[4]
Fast unfolding of communities in large networks.Journal of statistical mechanics: theory and experiment, 2008(10):P10008, 2008
Vincent D Blondel, Jean-Loup Guillaume, Renaud Lambiotte, and Etienne Lefebvre. Fast unfolding of communities in large networks.Journal of statistical mechanics: theory and experiment, 2008(10):P10008, 2008. 5
2008
-
[5]
Butler, Jonas Wulff, Garrett B
Daniel J. Butler, Jonas Wulff, Garrett B. Stanley, and Michael J. Black. A naturalistic open source movie for optical flow evaluation. InProceedings of the 12th European Con- ference on Computer Vision - Volume Part VI, page 611–625, Berlin, Heidelberg, 2012. Springer-Verlag. 3, 4
2012
-
[6]
Extreme rotation estimation using dense cor- relation volumes
Ruojin Cai, Bharath Hariharan, Noah Snavely, and Hadar Averbuch-Elor. Extreme rotation estimation using dense cor- relation volumes. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, pages 14566–14575, 2021. 3
2021
-
[7]
Doppelgangers: Learning to disambiguate images of similar structures
Ruojin Cai, Joseph Tung, Qianqian Wang, Hadar Averbuch- Elor, Bharath Hariharan, and Noah Snavely. Doppelgangers: Learning to disambiguate images of similar structures. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 34–44, 2023. 3
2023
-
[8]
Salvation mountain - photogrammetry - terres- trial, photogrammetry - aerial, lidar - terrestrial, lidar - mobile, survey data, 2023
Filiberto Chiabrando, Loren Clark, John Driscoll, Scott McAvoy, Dominique Rissolo, Alessandra Spreafico, and Beat- rice Tanduo. Salvation mountain - photogrammetry - terres- trial, photogrammetry - aerial, lidar - terrestrial, lidar - mobile, survey data, 2023. Distributed by Open Heritage 3D. 4
2023
-
[9]
Great mosque - kilwa kisiwani - lidar - terrestrial, photogrammetry - terrestrial, photogrammetry - aerial, 2020
CyArk. Great mosque - kilwa kisiwani - lidar - terrestrial, photogrammetry - terrestrial, photogrammetry - aerial, 2020. Distributed by Open Heritage 3D. 4
2020
-
[10]
Superpoint: Self-supervised interest point detection and description
Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabi- novich. Superpoint: Self-supervised interest point detection and description. InProceedings of the IEEE conference on computer vision and pattern recognition workshops, pages 224–236, 2018. 3
2018
-
[11]
MASt3r-sfm: a fully-integrated solution for unconstrained structure-from-motion
Bardienus Pieter Duisterhof, Lojze Zust, Philippe Weinza- epfel, Vincent Leroy, Yohann Cabon, and Jerome Revaud. MASt3r-sfm: a fully-integrated solution for unconstrained structure-from-motion. InInternational Conference on 3D Vision 2025, 2025. 6
2025
-
[12]
Building Rome on a Cloudless Day
Jan-Michael Frahm, Pierre Fite-Georgel, David Gallup, Tim Johnson, Rahul Raguram, Changchang Wu, Yi-Hung Jen, Enrique Dunn, Brian Clipp, Svetlana Lazebnik, and Marc Pollefeys. Building Rome on a Cloudless Day. InECCV,
-
[13]
Vision meets robotics: The kitti dataset.Interna- tional Journal of Robotics Research (IJRR), 2013
Andreas Geiger, Philip Lenz, Christoph Stiller, and Raquel Urtasun. Vision meets robotics: The kitti dataset.Interna- tional Journal of Robotics Research (IJRR), 2013. 3, 4
2013
-
[14]
Large scale multi-view stereopsis eval- uation
Rasmus Jensen, Anders Dahl, George V ogiatzis, Engil Tola, and Henrik Aanæs. Large scale multi-view stereopsis eval- uation. In2014 IEEE Conference on Computer Vision and Pattern Recognition, pages 406–413. IEEE, 2014. 7, 8
2014
-
[15]
Omniglue: General- izable feature matching with foundation model guidance
Hanwen Jiang, Hanwen Jiang, Arjun Karpur, Bingyi Cao, Qixing Huang, and Qi-Xing Huang. Omniglue: General- izable feature matching with foundation model guidance. 2024 IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), pages 19865–19875, 2024. 3
2024
-
[16]
Barron, Noah Snavely, and Aleksander Holynski
Haian Jin, Rundi Wu, Tianyuan Zhang, Ruiqi Gao, Jonathan T. Barron, Noah Snavely, and Aleksander Holynski. ZipMap: Linear-time stateful 3d reconstruction via test-time training. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2026. 2
2026
-
[17]
de Ara´ujo
Arjun Karpur, Guilherme Perrotta, Ricardo Martin-Brualla, Howard Zhou, and Andre F. de Ara´ujo. Lfm-3d: Learnable feature matching across wide baselines using 3d signals.2024 International Conference on 3D Vision (3DV), pages 11–20,
2024
-
[18]
A fast algorithm for steiner trees.Acta informatica, 15(2): 141–145, 1981
Lawrence Kou, George Markowsky, and Leonard Berman. A fast algorithm for steiner trees.Acta informatica, 15(2): 141–145, 1981. 5
1981
-
[19]
Ground- ing image matching in 3d with mast3r, 2024
Vincent Leroy, Yohann Cabon, and J´erˆome Revaud. Ground- ing image matching in 3d with mast3r, 2024. 2, 3
2024
-
[20]
Megadepth: Learning single- view depth prediction from internet photos
Zhengqi Li and Noah Snavely. Megadepth: Learning single- view depth prediction from internet photos. InProceedings of the IEEE conference on computer vision and pattern recog- nition, pages 2041–2050, 2018. 2, 3, 1
2041
-
[21]
Lightglue: Local feature matching atokens are frozen
Philipp Lindenberger, Paul-Edouard Sarlin, and Marc Polle- feys. Lightglue: Local feature matching atokens are frozen. arXiv preprint arXiv:2306.13643, 2023. 3
-
[22]
A faster approximation algorithm for the steiner problem in graphs.Information Processing Letters, 27 (3):125–128, 1988
Kurt Mehlhorn. A faster approximation algorithm for the steiner problem in graphs.Information Processing Letters, 27 (3):125–128, 1988. 5
1988
-
[23]
Indoor segmentation and support inference from rgbd images
Pushmeet Kohli Nathan Silberman, Derek Hoiem and Rob Fergus. Indoor segmentation and support inference from rgbd images. InECCV, 2012. 3, 4
2012
-
[24]
Palazzolo, J
E. Palazzolo, J. Behley, P. Lottes, P. Gigu`ere, and C. Stachniss. ReFusion: 3D Reconstruction in Dynamic Environments for RGB-D Cameras Exploiting Residuals.arXiv, 2019. 3, 4
2019
-
[25]
Jeremy Reizenstein, Roman Shapovalov, Philipp Henzler, Luca Sbordone, Patrick Labatut, and David Novotn´y. Com- mon objects in 3d: Large-scale learning and evaluation of real-life 3d category reconstruction.2021 IEEE/CVF In- ternational Conference on Computer Vision (ICCV), pages 10881–10891, 2021. 7
2021
-
[26]
Torre dei baldovinetti - florence - lidar - terrestrial, photogrammetry - terrestrial, 2023
Ashley Richter, Michael Hess, Vid Petrovic, Falko Kuester, Cultural Heritage Engineering Initiative (CHEI), Architecture Center of Interdisciplinary Science for Art, and Archaeology (CISA3). Torre dei baldovinetti - florence - lidar - terrestrial, photogrammetry - terrestrial, 2023. Distributed by Open Heritage 3D. 4
2023
-
[27]
Superglue: Learning feature match- ing with graph neural networks
Paul-Edouard Sarlin, Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. Superglue: Learning feature match- ing with graph neural networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recog- nition, pages 4938–4947, 2020. 3
2020
-
[28]
Structure-from-motion revisited
Johannes Lutz Sch ¨onberger and Jan-Michael Frahm. Structure-from-motion revisited. InConference on Computer Vision and Pattern Recognition (CVPR), 2016. 2, 3
2016
-
[29]
Structure- from-motion revisited
Johannes L Schonberger and Jan-Michael Frahm. Structure- from-motion revisited. InCVPR, 2016. 2, 3
2016
-
[30]
Sch¨onberger, Enliang Zheng, Jan-Michael Frahm, and Marc Pollefeys
Johannes L. Sch¨onberger, Enliang Zheng, Jan-Michael Frahm, and Marc Pollefeys. Pixelwise view selection for unstructured multi-view stereo. InEuropean Conference on Computer Vision, 2016. 2
2016
-
[31]
Pixelwise view selection for un- structured multi-view stereo
Johannes Lutz Sch¨onberger, Enliang Zheng, Marc Pollefeys, and Jan-Michael Frahm. Pixelwise view selection for un- structured multi-view stereo. InEuropean Conference on Computer Vision (ECCV), 2016. 3
2016
-
[32]
Sch¨onberger, Silvano Galliani, Torsten Sattler, Konrad Schindler, Marc Pollefeys, and An- dreas Geiger
Thomas Sch¨ops, Johannes L. Sch¨onberger, Silvano Galliani, Torsten Sattler, Konrad Schindler, Marc Pollefeys, and An- dreas Geiger. A multi-view stereo benchmark with high- resolution images and multi-camera videos. In2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 2538–2547, 2017. 7, 8
2017
-
[33]
Scene coordinate regression forests for camera relocalization in rgb- d images
Jamie Shotton, Ben Glocker, Christopher Zach, Shahram Izadi, Antonio Criminisi, and Andrew Fitzgibbon. Scene coordinate regression forests for camera relocalization in rgb- d images. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2930–2937, 2013. 7, 8
2013
-
[34]
Photo tourism: exploring photo collections in 3d
Noah Snavely, Steven M Seitz, and Richard Szeliski. Photo tourism: exploring photo collections in 3d. InACM siggraph 2006 papers, pages 835–846. 2006. 2
2006
-
[35]
Skeletal graphs for efficient structure from motion
Noah Snavely, Steven M Seitz, and Richard Szeliski. Skeletal graphs for efficient structure from motion. In2008 IEEE Conference on Computer Vision and Pattern Recognition, pages 1–8. IEEE, 2008. 5
2008
-
[36]
Megascenes: Scene-level view synthesis at scale
Joseph Tung, Gene Chou, Ruojin Cai, Guandao Yang, Kai Zhang, Gordon Wetzstein, Bharath Hariharan, and Noah Snavely. Megascenes: Scene-level view synthesis at scale. arXiv preprint arXiv:2406.11819, 2024. 1, 2, 3
-
[37]
Disk: Learning local features with policy gradient.Advances in Neural Information Processing Systems, 33:14254–14265,
Michał Tyszkiewicz, Pascal Fua, and Eduard Trulls. Disk: Learning local features with policy gradient.Advances in Neural Information Processing Systems, 33:14254–14265,
-
[38]
arXiv preprint arXiv:2408.16061 (2024)
Hengyi Wang and Lourdes Agapito. 3d reconstruction with spatial memory.arXiv preprint arXiv:2408.16061, 2024. 6
-
[39]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025. 2, 3, 6
2025
-
[40]
Efros, and Angjoo Kanazawa
Qianqian Wang*, Yifei Zhang*, Aleksander Holynski, Alexei A. Efros, and Angjoo Kanazawa. Continuous 3d per- ception model with persistent state. InCVPR, 2025. 6, 3
2025
-
[41]
Moge: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision
Ruicheng Wang, Sicheng Xu, Cassie Dai, Jianfeng Xiang, Yu Deng, Xin Tong, and Jiaolong Yang. Moge: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5261–5271, 2025. 4
2025
-
[42]
Dust3r: Geometric 3d vision made easy, 2024
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. Dust3r: Geometric 3d vision made easy.arXiv preprint arXiv:2312.14132, 2023. 2, 6
-
[43]
Tartanair: A dataset to push the limits of visual slam
Wenshan Wang, Delong Zhu, Xiangwei Wang, Yaoyu Hu, Yuheng Qiu, Chen Wang, Yafei Hu, Ashish Kapoor, and Sebastian Scherer. Tartanair: A dataset to push the limits of visual slam. In2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 4909–4916. IEEE, 2020. 3
2020
-
[44]
π3: Scalable permutation-equivariant visual geometry learning, 2025
Yifan Wang, Jianjun Zhou, Haoyi Zhu, Wenzheng Chang, Yang Zhou, Zizun Li, Junyi Chen, Jiangmiao Pang, Chunhua Shen, and Tong He. π3: Scalable permutation-equivariant visual geometry learning, 2025. 1, 2, 6, 3
2025
-
[45]
Doppelgangers++: Improved visual disam- biguation with geometric 3d features, 2025
Yuanbo Xiangli, Ruojin Cai, Hanyu Chen, Jeffrey Byrne, and Noah Snavely. Doppelgangers++: Improved visual disam- biguation with geometric 3d features, 2025. 3, 6
2025
-
[46]
Scal3r: Scalable test-time training for large-scale 3d reconstruction, 2026
Tao Xie, Peishan Yang, Yudong Jin, Yingfeng Cai, Wei Yin, Weiqiang Ren, Qian Zhang, Wei Hua, Sida Peng, Xiaoyang Guo, and Xiaowei Zhou. Scal3r: Scalable test-time training for large-scale 3d reconstruction, 2026. 2
2026
-
[47]
Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass
Jianing Yang, Alexander Sax, Kevin J Liang, Mikael Henaff, Hao Tang, Ang Cao, Joyce Chai, Franziska Meier, and Matt Feiszli. Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 21924–21935,
-
[48]
Blendedmvs: A large- scale dataset for generalized multi-view stereo networks
Yao Yao, Zixin Luo, Shiwei Li, Jingyang Zhang, Yufan Ren, Lei Zhou, Tian Fang, and Long Quan. Blendedmvs: A large- scale dataset for generalized multi-view stereo networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1790–1799, 2020. 3
2020
-
[49]
arXiv preprint arXiv:2410.03825 (2024)
Junyi Zhang, Charles Herrmann, Junhwa Hur, Varun Jampani, Trevor Darrell, Forrester Cole, Deqing Sun, and Ming-Hsuan Yang. Monst3r: A simple approach for estimating geometry in the presence of motion.arXiv preprint arxiv:2410.03825,
-
[50]
Flare: Feed-forward geometry, appearance and camera estimation from uncalibrated sparse views
Shangzhan Zhang, Jianyuan Wang, Yinghao Xu, Nan Xue, Christian Rupprecht, Xiaowei Zhou, Yujun Shen, and Gor- don Wetzstein. Flare: Feed-forward geometry, appearance and camera estimation from uncalibrated sparse views. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 21936–21947, 2025. 2
2025
-
[51]
Stereo Magnification: Learning View Synthesis using Multiplane Images
Tinghui Zhou, Richard Tucker, John Flynn, Graham Fyffe, and Noah Snavely. Stereo magnification: Learning view synthesis using multiplane images.arXiv preprint arXiv:1805.09817, 2018. 7 Long-Tail Internet Photo Reconstruction Supplementary Material Visualization Webpage Please refer to our project page for additional visualizations beyond this PDF. The web...
work page internal anchor Pith review arXiv 2018
-
[52]
This encourages the trajectory to enter unex- plored regions of the view graph and reduces redundancy in viewpoint selection
Community novelty: prioritizing candidates whose camera-community has not yet been visited by the sam- pled set. This encourages the trajectory to enter unex- plored regions of the view graph and reduces redundancy in viewpoint selection
-
[53]
This promotes larger baselines and helps diversify the spatial coverage of the sampled views
Spatial distance: among candidates with equal novelty, preferring those that are farther from the current cam- era position. This promotes larger baselines and helps diversify the spatial coverage of the sampled views. Table 6.Dataset statistics and viewpoint-distribution metrics.We report reconstruction statistics and metrics describing camera coverage. ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.