Recognition: unknown
Accelerating Reinforcement Learning for Wind Farm Control via Expert Demonstrations
Pith reviewed 2026-05-10 15:51 UTC · model grok-4.3
The pith
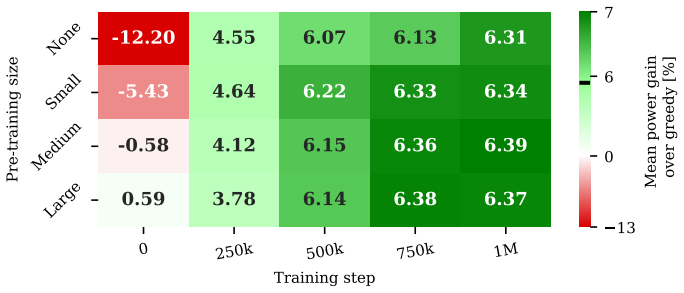
Pretraining with expert demonstrations lets reinforcement learning wind farm controllers start at baseline performance instead of lagging by 12 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Expert demonstrations generated by deploying a steady-state optimizer inside a dynamic wake simulation can initialize both the actor and critic of a reinforcement learning agent through behavior cloning, removing the initial performance penalty and allowing convergence to higher power gains than a lookup-table controller.
What carries the argument
Behavior cloning on expert trajectories from a steady-state optimizer inside the dynamic simulator to initialize the policy and value networks of the reinforcement learning agent.
If this is right
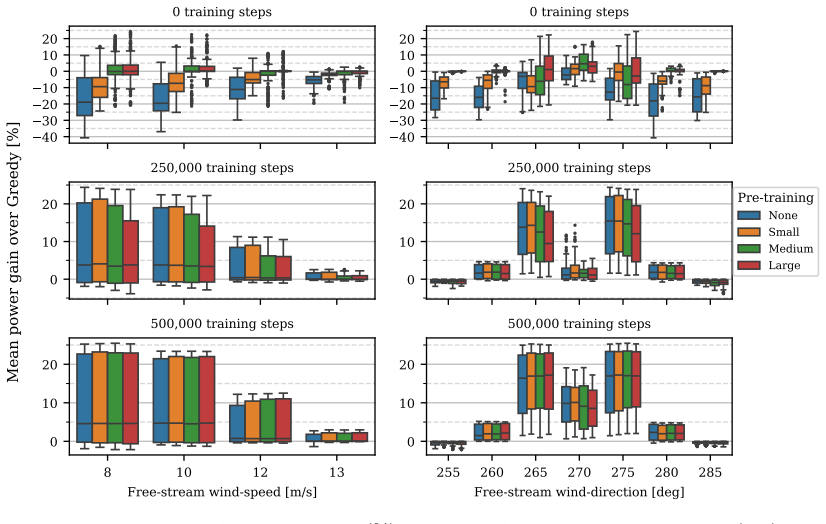
- Pretrained agents begin near baseline performance rather than 12 percent below it.
- All training configurations reach similar final performance within 250,000 steps.
- Final power gains surpass those of a lookup-table controller that requires 500,000 steps for about 7 percent improvement.
- The method avoids extended periods of reduced power output during the learning phase.
Where Pith is reading between the lines
- The same pretraining step could shorten deployment time for reinforcement learning controllers on much larger wind farms.
- The approach might apply to other flow-control problems where steady-state models are available but full dynamics must still be learned online.
- Further gains could come from mixing these demonstrations with other acceleration techniques such as curriculum learning.
Load-bearing premise
Demonstrations created by the steady-state optimizer transfer effectively when used to initialize the networks for continued learning in the dynamic environment.
What would settle it
The pretrained agent showing a large initial performance gap below the zero-yaw baseline or failing to exceed lookup-table performance after fine-tuning would disprove the benefit of this pretraining.
Figures


read the original abstract
Reinforcement learning (RL) offers a promising approach for adaptive wind farm flow control, yet its practical deployment is hindered by slow training convergence and poor initial performance, factors that could translate to years of reduced power output if an untrained agent were deployed directly. This work investigates whether domain knowledge from steady-state wake models can accelerate RL training and improve initial controller performance. We propose a pretraining methodology in which expert demonstrations are generated by deploying a PyWake-based steady-state optimizer within a dynamic wake simulation (WindGym), then used to initialize both the actor and critic networks of a Soft Actor-Critic agent via behavior cloning. Experiments on a 2x2 wind farm show that pretraining eliminates the costly initial learning phase: while an untrained agent underperforms the greedy zero-yaw baseline by approximately 12%, pretraining raises initial performance to near-baseline levels. During online fine-tuning, all configurations converge within 250,000 environment steps to achieve similar performance, ultimately exceeding that of a lookup-table controller, which reaches approximately 7% power gain after 500,000 steps.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes using expert demonstrations generated by a PyWake steady-state optimizer deployed inside the dynamic WindGym simulator to pretrain both actor and critic networks of a Soft Actor-Critic agent via behavior cloning. On a 2x2 wind farm, this pretraining is claimed to eliminate the initial performance dip seen in untrained agents (which underperform the greedy zero-yaw baseline by ~12%), raising initial performance to near-baseline levels; all configurations then converge within 250,000 steps to outperform a lookup-table controller that achieves ~7% power gain after 500,000 steps.
Significance. If the transfer from steady-state expert trajectories to the dynamic simulator holds, the approach offers a practical way to reduce the multi-year power losses that would otherwise occur during RL training in operational wind farms. It demonstrates a hybrid model-based initialization strategy that could generalize to other adaptive flow-control problems in energy systems. The absence of robustness metrics and ablations, however, limits the strength of this assessment.
major comments (2)
- [Abstract] Abstract: the central claim that pretraining eliminates the initial learning phase depends on effective transfer of steady-state PyWake demonstrations to initialize SAC networks in the dynamic WindGym environment. The reported result—that pretraining only reaches 'near-baseline' performance rather than the higher gain expected from the optimizer—suggests possible partial or negative transfer arising from the mismatch between equilibrium wake assumptions and time-varying inflow/wake advection; an ablation isolating demonstration quality (e.g., random vs. expert trajectories) is required to confirm the source of the observed improvement.
- [Abstract] Abstract and Experiments: numerical gains (12% underperformance, 7% power gain, convergence at 250k steps) are reported without error bars, statistical significance tests, hyperparameter schedules, or ablation studies. This omission makes it impossible to determine whether the elimination of the initial dip and final outperformance are robust or sensitive to random seeds and tuning choices.
minor comments (1)
- [Abstract] Abstract: define 'near-baseline levels' quantitatively (e.g., percentage of greedy zero-yaw power) and specify the exact number of independent runs used to obtain the reported figures.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which identify key areas where additional analysis can strengthen the manuscript. We address each major comment below and have revised the paper to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that pretraining eliminates the initial learning phase depends on effective transfer of steady-state PyWake demonstrations to initialize SAC networks in the dynamic WindGym environment. The reported result—that pretraining only reaches 'near-baseline' performance rather than the higher gain expected from the optimizer—suggests possible partial or negative transfer arising from the mismatch between equilibrium wake assumptions and time-varying inflow/wake advection; an ablation isolating demonstration quality (e.g., random vs. expert trajectories) is required to confirm the source of the observed improvement.
Authors: We agree that the gap between the steady-state optimizer gain and the near-baseline performance after pretraining indicates partial transfer attributable to the mismatch between equilibrium assumptions and dynamic wake advection. To isolate the contribution of demonstration quality, we have added an ablation study in the revised manuscript that compares behavior cloning on expert PyWake trajectories against random trajectories of equivalent length. The results show that only the expert demonstrations eliminate the initial dip and accelerate convergence, confirming that the observed benefit arises from the quality of the demonstrations rather than pretraining in general. revision: yes
-
Referee: [Abstract] Abstract and Experiments: numerical gains (12% underperformance, 7% power gain, convergence at 250k steps) are reported without error bars, statistical significance tests, hyperparameter schedules, or ablation studies. This omission makes it impossible to determine whether the elimination of the initial dip and final outperformance are robust or sensitive to random seeds and tuning choices.
Authors: We acknowledge that the absence of error bars, statistical tests, and hyperparameter details limits assessment of robustness. In the revised manuscript we now report all key metrics with error bars computed across five independent random seeds, include statistical significance tests (paired t-tests) for the main performance comparisons, provide the full hyperparameter schedules and training details in an appendix, and expand the set of ablation studies (including the demonstration-quality ablation noted above). These additions confirm that the elimination of the initial dip and the final outperformance are consistent across seeds. revision: yes
Circularity Check
No circularity: empirical results benchmarked against independent external controllers
full rationale
The paper describes an experimental pipeline that generates expert trajectories via a PyWake steady-state optimizer inside the WindGym dynamic simulator, uses them for behavior-cloning initialization of SAC actor and critic networks, and then reports online fine-tuning performance. All quantitative claims (initial performance lift, convergence within 250k steps, final power gain) are obtained by direct comparison to separate, non-derived baselines—the greedy zero-yaw policy and a lookup-table controller—rather than by any equation or fitted parameter that reduces the reported gains to quantities defined from the same data. No self-citations, uniqueness theorems, or ansatzes are invoked to justify the core result; the derivation chain is therefore self-contained and externally falsifiable.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Steady-state wake models produce expert trajectories that are sufficiently informative for initializing policies in dynamic wake simulations
Reference graph
Works this paper leans on
-
[1]
Veers P, Dykes K, Lantz E, Barth S, Bottasso C L, Carlson O, Clifton A, Green J, Green P, Holttinen H et al.2019 Grand challenges in the science of wind energyScience366eaau2027
2019
-
[2]
Meyers J, Bottasso C, Dykes K, Fleming P, Gebraad P, Giebel G, Göçmen T and Van Wingerden J W 2022 Wind farm flow control: prospects and challengesWind Energy Science Discussions20221–56
2022
-
[3]
Howland M F and Dabiri J O 2020 Influence of wake model superposition and secondary steering on model- based wake steering control with SCADA data assimilationEnergies
2020
-
[4]
Abkar M, Zehtabiyan-Rezaie N and Iosifidis A 2023 Reinforcement learning for wind-farm flow control: Current state and future actionsTheoretical and Applied Mechanics Letters100475
2023
-
[5]
Göçmen T, Liew J, Kadoche E, Dimitrov N, Riva R, Andersen S J, Lio A W, Quick J, Réthoré P E and Dykes K 2024 Data-driven wind farm flow control and challenges towards field implementationRenewable and Sustainable Energy ReviewsUnder Review
2024
- [6]
-
[7]
Zhao H, Zhao J, Qiu J, Liang G and Dong Z Y 2020 Cooperative wind farm control with deep reinforcement learning and knowledge-assisted learningIEEE Transactions on Industrial Informatics166912–6921
2020
-
[8]
Stanfel P, Johnson K, Bay C J and King J 2020 A distributed reinforcement learning yaw control approach for wind farm energy capture maximization2020 American Control Conference (ACC)pp 4065–4070
2020
-
[9]
version 4.2.1GitHub repositoryURLhttps://github.com/NREL/floris
NREL 2024 FLORIS. version 4.2.1GitHub repositoryURLhttps://github.com/NREL/floris
2024
-
[10]
Bizon Monroc C, Bušić A, Dubuc D and Zhu J 2024 Towards fine tuning wake steering policies in the field: an imitation-based approachJournal of Physics: Conference Series2767032017 URLhttps://doi.org/ 10.1088/1742-6596/2767/3/032017
-
[11]
DTU 2025 WindgymAvailable:https://github.com/DTUWindEnergy/WindGym[Accessed: 27-05-2025]
2025
-
[12]
Haarnoja T, Zhou A, Abbeel P and Levine S 2018 Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor (Preprint1801.01290) URLhttps://arxiv.org/abs/1801. 01290
work page internal anchor Pith review arXiv 2018
-
[13]
Pedersen M M, Steiner J, Nilsen M B, Lohmann J, Hodgson E L, Riva R, Troldborg N, Andersen S J, Larsen G, Verelst D R and Réthoré P E 2026 Dynamiks 0.0.4: An open-source dynamic wind system simulator URL https://gitlab.windenergy.dtu.dk/DYNAMIKS/dynamiks
2026
-
[14]
org/preprints/wes-2025-200/
Steiner J, Hodgson E L, van der Laan M Pet al.2025 A multi-fidelity model benchmark for wake steering of a large turbine in a neutral ABLWind Energy Science Discussions20251–32 URLhttps://wes.copernicus. org/preprints/wes-2025-200/
2025
-
[15]
Larsen G C, Aagaard Madsen H and Bingöl F 2007 Dynamic wake meandering modeling
2007
-
[16]
Bak C, Zahle F, Bitsche R, Kim T, Yde A, Henriksen L, Hansen M, Blasques J, Gaunaa M and Natarajan A 2013 The DTU 10-MW reference wind turbine danish Wind Power Research 2013; Conference date: 27-05-2013 Through 28-05-2013
2013
-
[17]
Pedersen M M, Forsting A M, van der Laan P, Riva R, Romàn L A A, Risco J C, Friis-Møller M, Quick J, Christiansen J P S, Rodrigues R V, Olsen B T and Réthoré P E 2023 Pywake 2.5.0: An open-source wind farm simulation tool URLhttps://gitlab.windenergy.dtu.dk/TOPFARM/PyWake
2023
-
[18]
Neustroev G, Andringa S P, Verzijlbergh R A and De Weerdt M M 2022 Deep reinforcement learning for active wake controlProceedings of the 21st International Conference on Autonomous Agents and Multiagent Systemspp 944–953
2022
-
[19]
Fleming P A, Stanley A P J, Bay C J, King J, Simley E, Doekemeijer B M and Mudafort R 2022 Serial-refine method for fast wake-steering yaw optimizationJournal of Physics: Conference Series2265032109 URL https://dx.doi.org/10.1088/1742-6596/2265/3/032109
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.