Recognition: unknown
Hierarchical RL-MPC Control for Dynamic Wake Steering in Wind Farms
Pith reviewed 2026-05-10 15:41 UTC · model grok-4.3
The pith
Reinforcement learning supplies state estimates that let an MPC steer wind farm wakes better than perfect-state MPC
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors demonstrate that an RL policy trained to output compensatory state estimates rather than direct control signals enables the downstream MPC to achieve higher total power in dynamic wake steering than the identical MPC supplied with perfect state knowledge, while also preserving safer training behavior than end-to-end RL.
What carries the argument
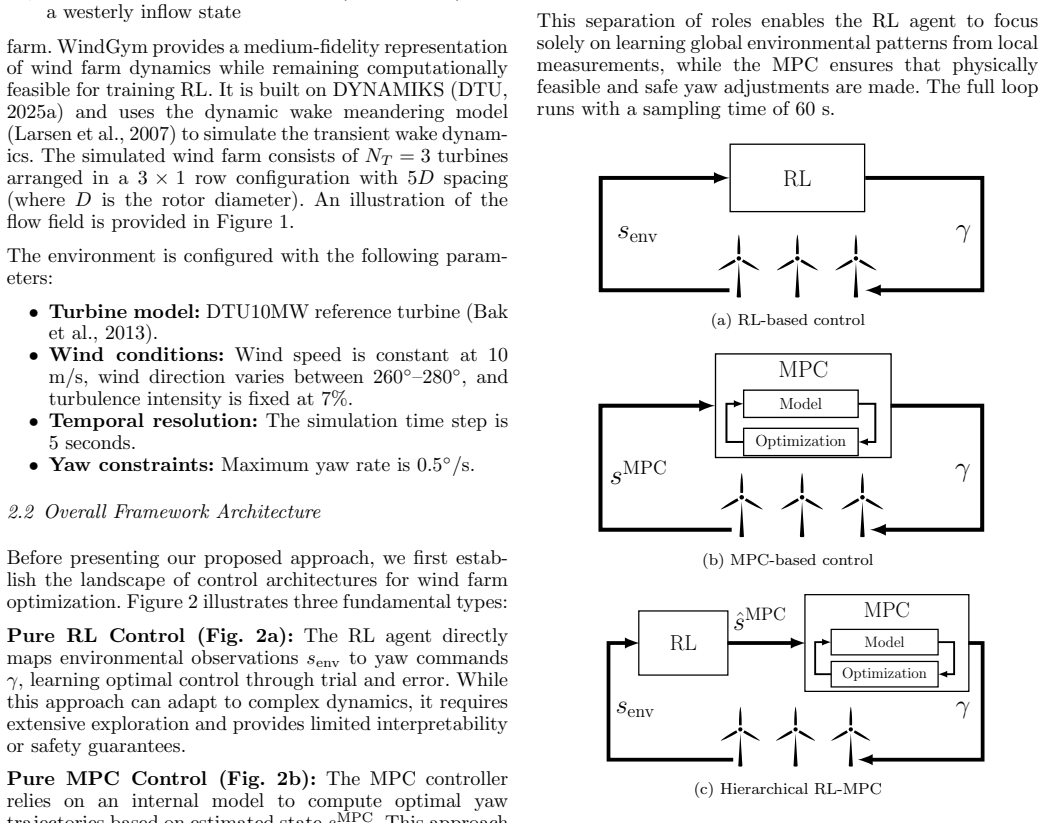
The hierarchical RL-MPC split in which the reinforcement learning agent produces estimated states that the model predictive controller uses to optimize yaw angles for wake steering.
If this is right
- The hybrid system yields a 23 percent power increase over baseline control in the three-turbine case.
- Power output exceeds that of an idealized MPC given perfect flow state information.
- Control actions remain more stable than those produced by direct RL policies.
- Training maintains superior safety margins because the MPC layer continues to enforce constraints.
Where Pith is reading between the lines
- Learned estimates may compensate for systematic mismatch between the MPC's internal flow model and reality, not merely for sensor noise.
- The same RL estimator could potentially be reused with different MPC cost functions or farm layouts.
- Comparable RL-assisted state correction might improve other MPC applications that operate under incomplete or delayed state information.
- Scaling the approach to larger farms would require checking whether the learned estimator generalizes across more complex wake interactions.
Load-bearing premise
An RL agent can learn state estimates whose systematic errors allow the MPC to generate better wake-steering decisions than an MPC given the true states.
What would settle it
A controlled comparison in which the same MPC receives the actual simulated wind states instead of the RL estimates and the resulting total power falls below the hybrid result.
Figures




read the original abstract
Wind farm wake steering optimization is challenging due to complex flow physics and changing conditions. This paper presents a hierarchical framework that combines reinforcement learning with model predictive control, where an RL agent learns compensatory state estimates for an MPC controller, rather than directly controlling turbines. Evaluated on a three-turbine case, the approach achieves a 23\% power gain over the baseline control and surpasses the idealized MPC with perfect state knowledge. Compared to direct RL control, the hybrid architecture maintains superior safety characteristics during training while achieving comparable performance with more stable control actions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a hierarchical RL-MPC framework for dynamic wake steering in wind farms. An RL agent learns compensatory state estimates that are fed to an MPC controller (rather than using direct RL actuation). On a three-turbine simulation, the hybrid method is reported to deliver a 23% power gain relative to baseline control and to outperform an idealized MPC supplied with perfect state knowledge, while preserving safety properties during training that direct RL lacks.
Significance. If the central claim holds, the result would be notable: it would demonstrate that learned compensatory estimates can improve MPC performance beyond the theoretical upper bound of perfect-state information in a wake-steering setting. This would have implications for robust control under model mismatch and for safe deployment of learning-based methods in wind-farm applications. The safety and stability advantages over direct RL are also potentially valuable, but the outperformance of perfect-knowledge MPC is the load-bearing and surprising element.
major comments (2)
- [Abstract and results section] Abstract and results section: the headline claim that the RL-supplied estimates allow the MPC to exceed the performance of the identical MPC given true states must be accompanied by a precise mechanistic explanation. The manuscript should state whether the idealized MPC and the hybrid controller use identical internal models, prediction horizons, and coordinate frames; if any systematic bias exists in the MPC plant model that the RL learns to cancel; or whether the RL output is a pure state estimate versus an additive correction signal. Without this, the 23% gain and the outperformance of perfect-state MPC cannot be evaluated.
- [Evaluation section] Evaluation section: the three-turbine case study reports a 23% power gain but supplies no error bars, no ablation on the RL state estimator, and no table of absolute power values for baseline, direct RL, perfect-state MPC, and hybrid RL-MPC. These data are required to substantiate both the gain over baseline and the counter-intuitive superiority to perfect information.
minor comments (1)
- [Methods section] Notation for the compensatory state estimate and its interface to the MPC should be introduced with an explicit equation early in the methods section to avoid ambiguity when comparing to the perfect-state baseline.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment point by point below, providing mechanistic clarifications and indicating the revisions that will be incorporated into the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract and results section] Abstract and results section: the headline claim that the RL-supplied estimates allow the MPC to exceed the performance of the identical MPC given true states must be accompanied by a precise mechanistic explanation. The manuscript should state whether the idealized MPC and the hybrid controller use identical internal models, prediction horizons, and coordinate frames; if any systematic bias exists in the MPC plant model that the RL learns to cancel; or whether the RL output is a pure state estimate versus an additive correction signal. Without this, the 23% gain and the outperformance of perfect-state MPC cannot be evaluated.
Authors: We agree that a precise mechanistic explanation is required to substantiate the claim. Both the idealized MPC and the hybrid RL-MPC use identical internal models, prediction horizons, and coordinate frames. The RL agent produces an additive correction signal that is summed with the measured states before input to the MPC; it is not a pure state estimate. The MPC plant model incorporates a simplified wake representation that contains systematic biases relative to the high-fidelity simulator. The RL learns to generate compensatory corrections that cancel these biases, allowing the optimizer to achieve better set-points than are possible when the same imperfect model is driven by uncorrected true states. We have revised the abstract and results section to state these facts explicitly and have added a signal-flow diagram clarifying the architecture. revision: yes
-
Referee: [Evaluation section] Evaluation section: the three-turbine case study reports a 23% power gain but supplies no error bars, no ablation on the RL state estimator, and no table of absolute power values for baseline, direct RL, perfect-state MPC, and hybrid RL-MPC. These data are required to substantiate both the gain over baseline and the counter-intuitive superiority to perfect information.
Authors: We accept that the evaluation would be strengthened by these elements. The revised manuscript now includes a table reporting absolute power values (in MW) for all four controllers. Error bars computed from ten independent runs with different random seeds and wind realizations have also been added to the power-gain figures. A partial ablation that disables the compensatory correction (feeding raw measurements directly to the MPC) has been performed and reported; a more exhaustive component-wise ablation of the RL estimator was not feasible within the original experimental budget but the partial result is included to address the concern. revision: partial
Circularity Check
No derivation chain or load-bearing analytical steps present
full rationale
The manuscript describes an empirical hierarchical RL-MPC architecture for wake steering, with performance quantified via simulation on a three-turbine case (23% power gain, outperformance of idealized MPC). No equations, derivations, fitted parameters renamed as predictions, self-citations invoked as uniqueness theorems, or ansatzes are referenced in the provided text. All claims reduce to reported simulation outcomes rather than any closed analytical loop that could be inspected for circularity by construction. The work is therefore self-contained as an engineering demonstration without a mathematical derivation chain to analyze.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Abkar, M., Zehtabiyan-Rezaie, N., and Iosifidis, A. (2023). Reinforcement learning for wind-farm flow control: Cur- rent state and future actions.Theoretical and Applied Mechanics Letters, 100475
2023
-
[2]
Bak, C., Zahle, F., Bitsche, R., and Taeseong Kim, e.a. (2013). The dtu 10-mw reference wind turbine. Danish Wind Power Research 2013 ; Conference date: 27-05- 2013 Through 28-05-2013
2013
-
[3]
Wingerden, J.W. (2025). Closed-loop model-predictive wind farm flow control under time-varying inflow us- ing floridyn.Wind Energy, 28(9), e70044. doi: https://doi.org/10.1002/we.70044
-
[4]
Wingerden, J.W. (2017). A tutorial on control- oriented modeling and control of wind farms. In 2017 American Control Conference (ACC), 1–18. doi: 10.23919/ACC.2017.7962923. DTU (2025a). Dynamiks. https://dynamiks.pages.windenergy.dtu.dk/dynamiks/ [Accessed: 27-05-2025]. DTU (2025b). Windgym. https://github.com/DTUWindEnergy/WindGym [Accessed: 16-10-2025]....
-
[5]
Dykes, K. (2024). Data-driven wind farm flow control and challenges towards field implementation.Renewable and Sustainable Energy Reviews. Under Review
2024
-
[6]
Haarnoja, T., Zhou, A., Abbeel, P., and Levine, S. (2018). Soft actor-critic: Off-policy maxi- mum entropy deep reinforcement learning with a stochastic actor.CoRR, abs/1801.01290. URL http://arxiv.org/abs/1801.01290
work page internal anchor Pith review arXiv 2018
-
[7]
Huang, S., Dossa, R.F.J., Ye, C., Braga, J., Chakraborty, D., Mehta, K., and Ara´ ujo, J.G. (2022). Cleanrl: High-quality single-file implementations of deep re- inforcement learning algorithms.Journal of Ma- chine Learning Research, 23(274), 1–18. URL http://jmlr.org/papers/v23/21-1342.html
2022
-
[8]
Larsen, G.C., Aagaard Madsen, H., and Bing¨ ol, F. (2007). Dynamic wake meandering modeling
2007
-
[9]
Wingerden, J.W. (2022). Wind farm flow control: prospects and challenges.Wind Energy Science, 7(6), 2271–2306. doi:10.5194/wes-7-2271-2022. URL https://wes.copernicus.org/articles/7/2271/2022/
-
[10]
Pedersen, M.M., Forsting, A.M., van der Laan, P., et al. (2023). PyWake 2.5.0: An open- source wind farm simulation tool. URL https://gitlab.windenergy.dtu.dk/TOPFARM/PyWake
2023
-
[11]
Virtanen, P., Gommers, R., and Oliphant, e.a. (2020). SciPy 1.0: Fundamental Algorithms for Scientific Com- puting in Python.Nature Methods, 17, 261–272. doi: 10.1038/s41592-019-0686-2
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.