Recognition: unknown
2D Pre-Training for 3D Pose Estimation
Pith reviewed 2026-05-10 06:03 UTC · model grok-4.3
The pith
Pre-training on 2D pose data before 3D data improves accuracy and efficiency in human pose estimation over 3D data alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
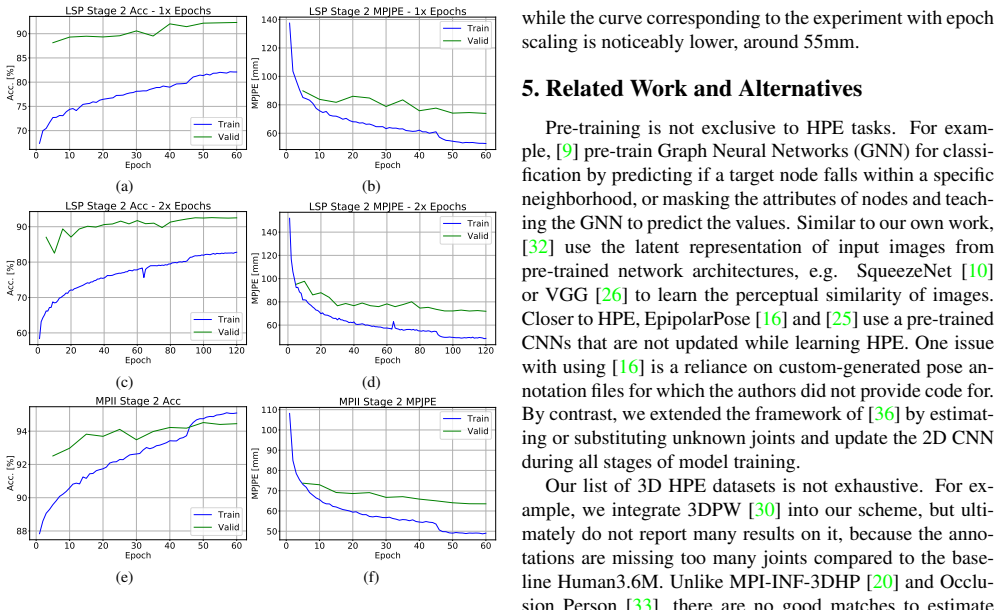
The central claim is that 2D pre-training consistently outperforms training on 3D data alone for 3D human pose estimation, particularly in computational efficiency, and that using MPII and Human3.6M yields MPJPE scores under 64.5 mm.
What carries the argument
An extended 3D human pose estimation scheme made compatible with additional 2D and 3D datasets, where the 2D pre-training step before 3D fine-tuning carries the performance gains.
If this is right
- 2D pre-training reduces the computation needed to reach strong 3D pose estimation results.
- The approach improves how well the model works on datasets it was not trained on directly.
- Varying model size during the 2D pre-training stage changes how well the final 3D model performs.
- The MPJPE threshold below 64.5 mm becomes reachable by combining the MPII 2D dataset with Human3.6M.
Where Pith is reading between the lines
- Large 2D pose datasets could reduce reliance on hard-to-collect 3D annotations for building effective models.
- The same pre-training pattern may transfer to other tasks that estimate 3D structure from images.
- Testing the method on more varied real-world scenes with heavy occlusion would check whether the efficiency gains hold outside controlled benchmarks.
Load-bearing premise
That expanding the 3D HPE scheme to extra 2D and 3D datasets preserves the claimed benefits without adding dataset-specific biases that would make the pre-training comparison unfair.
What would settle it
A side-by-side run of the identical model trained only on 3D data from the start that reaches the same or lower MPJPE on Human3.6M while using equal or less total compute than the 2D-pre-trained version.
Figures


read the original abstract
Pre-training is a general method that is used in a range of deep learning tasks. By first training a model on one task, and then further training on the downstream task used for final evaluation, the model is forced to learn a more general understanding of the input data. While pre-training has been applied to 3D Human Pose Estimation (HPE) previously, the scope of datasets used is typically very limited to some strong benchmarks, like Human3.6M. Therefore, in this project, we expand the scope of an existing 3D HPE scheme to be compatible with additional 2D and 3D HPE datasets, like Occlusion Person. We perform an extensive study on how aspects of 2D pre-training, such as model size, affect downstream performance, and to what extent pre-training can help the model generalize to different datasets. Experimental results show that 2D pre-training consistently outperforms training on 3D data alone, particularly in terms of computational efficiency. Finally, using MPII and Human3.6M, we are able to obtain an MPJPE score of under 64.5mm.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript extends an existing 3D human pose estimation (HPE) framework to support compatibility with additional 2D datasets (e.g., MPII) and 3D datasets (e.g., Occlusion Person). It conducts an empirical study on the effects of model size, 2D pre-training, and generalization, reporting that 2D pre-training consistently outperforms 3D-only training (particularly in computational efficiency) and achieves an MPJPE below 64.5 mm on MPII combined with Human3.6M.
Significance. If the reported empirical gains hold under rigorous controls, the work demonstrates that abundant 2D pose annotations can be leveraged for pre-training to improve both accuracy and efficiency in 3D HPE, addressing data scarcity in 3D settings. This could encourage broader adoption of cross-dimensional pre-training strategies in pose estimation pipelines.
major comments (1)
- Experimental section: The central claim of consistent outperformance and the specific MPJPE result of under 64.5 mm lack accompanying details on baseline implementations, number of training runs, statistical significance, or error bars, which are required to substantiate robustness given the empirical nature of the contribution.
minor comments (3)
- Abstract and §4: The exact MPJPE value, the precise train/test split, and direct numerical comparison to the 3D-only baseline should be stated explicitly rather than summarized as 'under 64.5 mm'.
- §3: Notation for the expanded dataset compatibility (e.g., how 2D keypoints are mapped into the 3D loss) is introduced without a clear equation or diagram, making the pre-training procedure harder to reproduce.
- Related work: Prior 2D-to-3D transfer methods are mentioned only briefly; adding 2-3 key citations would better situate the contribution.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and recommendation for minor revision. The feedback on experimental rigor is well-taken, and we address it directly below while committing to concrete improvements in the revised manuscript.
read point-by-point responses
-
Referee: Experimental section: The central claim of consistent outperformance and the specific MPJPE result of under 64.5 mm lack accompanying details on baseline implementations, number of training runs, statistical significance, or error bars, which are required to substantiate robustness given the empirical nature of the contribution.
Authors: We agree that additional experimental details are necessary to support the robustness claims. The baseline implementations follow the standard protocols and architectures from the original Human3.6M and MPII papers (as referenced in Section 4), with our extensions for 2D dataset compatibility described in Section 3. The reported MPJPE of under 64.5 mm and the outperformance trends are based on the primary training configuration detailed in the experimental setup. However, the manuscript does not currently include the number of independent runs, error bars, or statistical tests. In the revision, we will add: (i) explicit descriptions of baseline re-implementations with hyperparameters, (ii) results averaged over 3 random seeds with standard deviation error bars, and (iii) paired t-test p-values comparing 2D pre-training against 3D-only training to establish significance. These additions will be placed in an expanded Section 4 and the supplementary material. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is an empirical study on 2D pre-training for 3D human pose estimation. It expands an existing scheme to additional datasets, performs ablations on model size and generalization, and reports measured outcomes such as MPJPE under 64.5 mm on MPII + Human3.6M. No derivation chain, equations, fitted parameters renamed as predictions, or self-citation load-bearing uniqueness theorems appear in the provided text or abstract. All central claims rest on direct experimental comparisons rather than quantities defined by the model itself, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2d human pose estimation: New benchmark and state of the art analysis
Mykhaylo Andriluka, Leonid Pishchulin, Peter Gehler, and Bernt Schiele. 2d human pose estimation: New benchmark and state of the art analysis. InIEEE Conference on Com- puter Vision and Pattern Recognition (CVPR), June 2014. 2, 3, 4, 8
2014
-
[2]
Unipose: Unified hu- man pose estimation in single images and videos
Bruno Artacho and Andreas Savakis. Unipose: Unified hu- man pose estimation in single images and videos. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020. 4
2020
-
[3]
Long-term human motion prediction with scene context
Zhe Cao, Hang Gao, Karttikeya Mangalam, Qizhi Cai, Minh V o, and Jitendra Malik. Long-term human motion prediction with scene context. InECCV. 2020. 8
2020
-
[4]
Latent structured models for human pose estimation
Cristian Sminchisescu Catalin Ionescu, Fuxin Li. Latent structured models for human pose estimation. InInterna- tional Conference on Computer Vision, 2011. 1, 2, 3, 4, 8
2011
-
[5]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009. 2
2009
-
[6]
Combining local appearance and holistic view: Dual-source deep neural networks for human pose estimation
Xiaochuan Fan, Kang Zheng, Yuewei Lin, and Song Wang. Combining local appearance and holistic view: Dual-source deep neural networks for human pose estimation. InPro- ceedings of the IEEE conference on computer vision and pat- tern recognition, pages 1347–1355, 2015. 1
2015
-
[7]
Fast r-cnn
Ross Girshick. Fast r-cnn. InProceedings of the IEEE inter- national conference on computer vision, pages 1440–1448,
-
[8]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 2
2016
-
[9]
Pande, and Jure Leskovec
Weihua Hu, Bowen Liu, Joseph Gomes, Marinka Zitnik, Percy Liang, Vijay S. Pande, and Jure Leskovec. Strategies for pre-training graph neural networks. In8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020, 2020. 8
2020
-
[10]
Forrest N Iandola, Song Han, Matthew W Moskewicz, Khalid Ashraf, William J Dally, and Kurt Keutzer. Squeezenet: Alexnet-level accuracy with 50x fewer pa- rameters and¡ 0.5 mb model size.arXiv preprint arXiv:1602.07360, 2016. 8
-
[11]
Human3.6m: Large scale datasets and predic- tive methods for 3d human sensing in natural environments
Catalin Ionescu, Dragos Papava, Vlad Olaru, and Cristian Sminchisescu. Human3.6m: Large scale datasets and predic- tive methods for 3d human sensing in natural environments. IEEE Transactions on Pattern Analysis and Machine Intelli- gence, 36(7):1325–1339, jul 2014. 1, 2, 3, 4, 8
2014
-
[12]
Clustered pose and nonlinear appearance models for human pose estimation
Sam Johnson and Mark Everingham. Clustered pose and nonlinear appearance models for human pose estimation. In Proceedings of the British Machine Vision Conference, 2010. doi:10.5244/C.24.12. 3
-
[13]
Learning effective hu- man pose estimation from inaccurate annotation
Sam Johnson and Mark Everingham. Learning effective hu- man pose estimation from inaccurate annotation. InCVPR 2011, pages 1465–1472. IEEE, 2011. 1, 2, 3, 5, 8
2011
-
[14]
Adam: A method for stochastic optimization.International Conference on Learn- ing Representations, 12 2014
Diederik Kingma and Jimmy Ba. Adam: A method for stochastic optimization.International Conference on Learn- ing Representations, 12 2014. 5
2014
-
[15]
Muhammed Kocabas, Nikos Athanasiou, and Michael J. Black. Vibe: Video inference for human body pose and shape estimation. InThe IEEE Conference on Computer Vi- sion and Pattern Recognition (CVPR), June 2020. 1, 4
2020
-
[16]
Self- supervised learning of 3d human pose using multi-view ge- ometry
Muhammed Kocabas, Salih Karagoz, and Emre Akbas. Self- supervised learning of 3d human pose using multi-view ge- ometry. InThe IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2019. 1, 4, 8
2019
-
[17]
Learning multiple layers of features from tiny images.Technical Report, 2009
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images.Technical Report, 2009. 2
2009
-
[18]
2d/3d pose estimation and action recognition using multitask deep learn- ing
Diogo C Luvizon, David Picard, and Hedi Tabia. 2d/3d pose estimation and action recognition using multitask deep learn- ing. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5137–5146, 2018. 1
2018
-
[19]
Monocular 3d human pose estimation in the wild using improved cnn supervision
Dushyant Mehta, Helge Rhodin, Dan Casas, Pascal Fua, Oleksandr Sotnychenko, Weipeng Xu, and Christian Theobalt. Monocular 3d human pose estimation in the wild using improved cnn supervision. In3D Vision (3DV), 2017 Fifth International Conference on. IEEE, 2017. 4
2017
-
[20]
Single-shot multi-person 3d pose estimation from monocular rgb
Dushyant Mehta, Oleksandr Sotnychenko, Franziska Mueller, Weipeng Xu, Srinath Sridhar, Gerard Pons-Moll, and Christian Theobalt. Single-shot multi-person 3d pose estimation from monocular rgb. In3D Vision (3DV), 2018 Sixth International Conference on. IEEE, sep 2018. 2, 8
2018
-
[21]
Mills, Di Niu, Mohammad Salameh, Weichen Qiu, Fred X
Keith G. Mills, Di Niu, Mohammad Salameh, Weichen Qiu, Fred X. Han, Puyuan Liu, Jialin Zhang, Wei Lu, and Shangling Jui. Aio-p: Expanding neural performance predic- tors beyond image classification.Proceedings of the AAAI Conference on Artificial Intelligence, 37(8):9180–9189, 06
-
[22]
Stacked hour- glass networks for human pose estimation
Alejandro Newell, Kaiyu Yang, and Jia Deng. Stacked hour- glass networks for human pose estimation. InEuropean con- ference on computer vision, pages 483–499. Springer, 2016. 2
2016
-
[23]
Mills, Negar Hassanpour, Fred Han, Shuting Zhang, Wei Lu, Shangling Jui, Chunhua Zhou, Fengyu Sun, and Di Niu
Mohammad Salameh, Keith G. Mills, Negar Hassanpour, Fred Han, Shuting Zhang, Wei Lu, Shangling Jui, Chunhua Zhou, Fengyu Sun, and Di Niu. Autogo: Automated com- putation graph optimization for neural network evolution. In A. Oh, T. Neumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Process- ing Systems, volum...
2023
-
[24]
Modec: Multimodal de- composable models for human pose estimation
Benjamin Sapp and Ben Taskar. Modec: Multimodal de- composable models for human pose estimation. InIn Proc. CVPR, 2013. 1, 2, 4, 5, 8
2013
-
[25]
Monocular 3d human pose estimation by generation and ordinal ranking
Saurabh Sharma, Pavan Teja Varigonda, Prashast Bindal, Abhishek Sharma, and Arjun Jain. Monocular 3d human pose estimation by generation and ordinal ranking. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 2325–2334, 2019. 1, 4, 8
2019
-
[26]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Karen Simonyan and Andrew Zisserman. Very deep convo- lutional networks for large-scale image recognition.arXiv preprint arXiv:1409.1556, 2014. 8
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[27]
Xiao Sun, Chuankang Li, and Stephen Lin. An integral pose regression system for the eccv2018 posetrack chal- lenge.arXiv preprint arXiv:1809.06079, 2018. 4
-
[28]
Compositional human pose regression
Xiao Sun, Jiaxiang Shang, Shuang Liang, and Yichen Wei. Compositional human pose regression. InProceedings of the IEEE International Conference on Computer Vision, pages 2602–2611, 2017. 1
2017
-
[29]
Integral human pose regression.arXiv preprint arXiv:1711.08229,
Xiao Sun, Bin Xiao, Shuang Liang, and Yichen Wei. Integral human pose regression.arXiv preprint arXiv:1711.08229,
-
[30]
Recovering accurate 3d human pose in the wild using imus and a moving camera
Timo von Marcard, Roberto Henschel, Michael Black, Bodo Rosenhahn, and Gerard Pons-Moll. Recovering accurate 3d human pose in the wild using imus and a moving camera. InEuropean Conference on Computer Vision (ECCV), sep
-
[31]
Fast human pose estimation
Feng Zhang, Xiatian Zhu, and Mao Ye. Fast human pose estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3517– 3526, 2019. 1
2019
-
[32]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shecht- man, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 586–595, 2018. 8
2018
-
[33]
Adafuse: Adaptive multiview fusion for ac- curate human pose estimation in the wild.IJCV, pages 1–16,
Zhe Zhang, Chunyu Wang, Weichao Qiu, Wenhu Qin, and Wenjun Zeng. Adafuse: Adaptive multiview fusion for ac- curate human pose estimation in the wild.IJCV, pages 1–16,
-
[34]
Semantic graph convolutional networks for 3d human pose regression
Long Zhao, Xi Peng, Yu Tian, Mubbasir Kapadia, and Dim- itris N Metaxas. Semantic graph convolutional networks for 3d human pose regression. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3425–3435, 2019. 1
2019
-
[35]
Deep learning-based human pose estimation: A survey, 2020
Ce Zheng, Wenhan Wu, Taojiannan Yang, Sijie Zhu, Chen Chen, Ruixu Liu, Ju Shen, Nasser Kehtarnavaz, and Mubarak Shah. Deep learning-based human pose estimation: A survey, 2020. 1, 3, 4
2020
-
[36]
Towards 3d human pose estimation in the wild: A weakly-supervised approach
Xingyi Zhou, Qixing Huang, Xiao Sun, Xiangyang Xue, and Yichen Wei. Towards 3d human pose estimation in the wild: A weakly-supervised approach. InThe IEEE International Conference on Computer Vision (ICCV), Oct 2017. 1, 2, 3, 4, 5, 8
2017
-
[37]
Reconstructing nba players
Luyang Zhu, Konstantinos Rematas, Brian Curless, Steve Seitz, and Ira Kemelmacher-Shlizerman. Reconstructing nba players. InProceedings of the European Conference on Computer Vision (ECCV), August 2020. 8
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.