Recognition: unknown
Unified Multi-Foundation-Model Slide Representation for Pan-Cancer Recognition and Text-Guided Tumor Localization
Pith reviewed 2026-05-10 02:29 UTC · model grok-4.3
The pith
ASTRA unifies representations from multiple pathology foundation models into a shared slide-level space supervised by metadata for pan-cancer classification and text-guided tumor localization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ASTRA integrates heterogeneous foundation-model representations into a shared slide-level space by combining sparse mixture-of-experts contextualization, masked multi-model reconstruction, and contrastive alignment to structured pathology prompts derived from slide metadata; this enables strong performance on 4-category classification, 3-class solid tumor typing, 16-class cancer typing, and text-guided tumor localization on CHTN and TCGA cohorts without pixel supervision.
What carries the argument
The sparse mixture-of-experts contextualization, masked multi-model reconstruction, and contrastive alignment to structured pathology prompts that unify the representations and ground them using only classification category, cancer type, and anatomic site metadata.
If this is right
- ASTRA improves 4-category pan-cancer classification to 97.8% macro-AUC across four different foundation-model backbones.
- It reaches 99.7% AUC for 3-class solid tumor typing and 99.2% for 16-class cancer typing on the CHTN cohort.
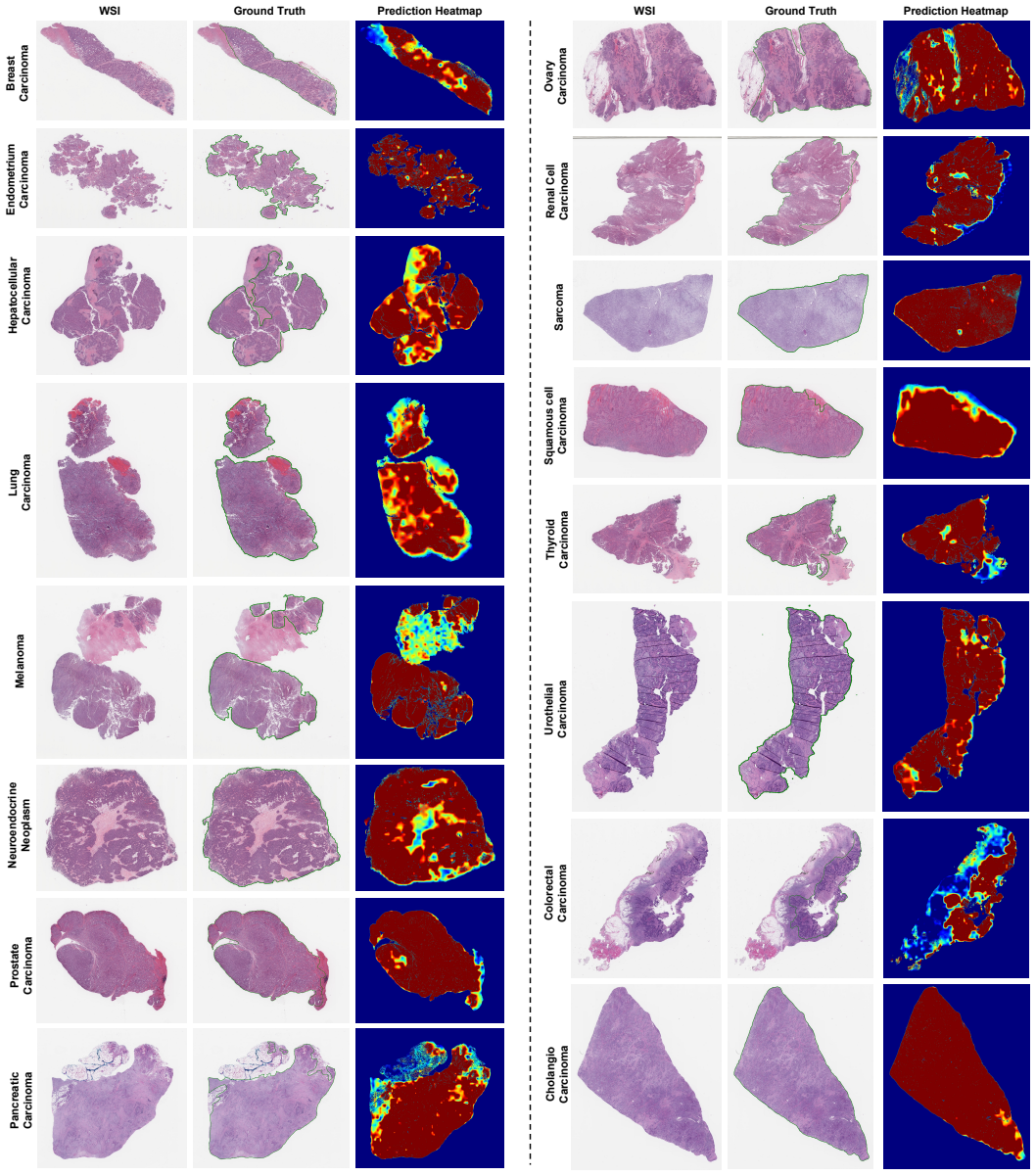
- Text-guided tumor localization achieves mean Dice of 0.897 on an in-domain annotated subset and 0.738 on an external TCGA cohort.
- The same trained representations support all tasks without requiring pixel-level supervision or task-specific retraining.
- Performance remains consistent when swapping among different pathology foundation models as backbones.
Where Pith is reading between the lines
- The unification step could let hospitals plug in newer foundation models as they appear without rebuilding the entire pipeline.
- Text-guided localization might let clinicians highlight regions by typing descriptions rather than drawing boxes.
- Similar metadata-driven alignment could be tested on radiology or other imaging domains that already have multiple competing foundation models.
- If metadata quality varies across institutions, the framework would need explicit robustness checks before wide deployment.
Load-bearing premise
Slide-level metadata fields such as classification category, cancer type, and anatomic site supply enough semantic signal to unify representations from different foundation models and drive both classification and localization.
What would settle it
Apply ASTRA to a new cohort where the metadata fields are randomly permuted or heavily noisy; if macro-AUC for classification falls below the best single backbone baseline and Dice for localization drops below 0.6, the claim that metadata provides effective supervision would be falsified.
Figures
read the original abstract
The expanding ecosystem of pathology foundation models has produced powerful but fragmented tile-level representations, limiting their use in clinical tasks that require unified slide-level reasoning and interpretable linkage to clinically meaningful information. We present ASTRA, a pan-cancer framework that integrates heterogeneous foundation-model representations into a shared slide-level representation space and semantically grounds that space using structured pathology annotation fields, including classification category, cancer type, and anatomic site. ASTRA combines sparse mixture-of-experts contextualization, masked multi-model reconstruction, and contrastive alignment to structured pathology prompts to learn slide representations that support 4-category classification, 3-class solid tumor typing, 16-class cancer typing, and text-guided tumor localization without pixel-level supervision. Developed on a CHTN cohort of 10,359 whole-slide images (WSIs) spanning 16 tumor types, ASTRA consistently improves pan-cancer classification across four pathology foundation-model backbones, achieving up to 97.8% macro-AUC for 4-category classification, 99.7% for 3-class solid tumor typing, and 99.2% for 16-class cancer typing. For tumor localization, ASTRA achieves a mean Dice of 0.897 on an annotated in-domain CHTN subset (n = 380) spanning 16 cancer types and 0.738 on an external TCGA cohort (n = 1,686) spanning four cancer types. These results demonstrate that minimal structured pathology annotation fields derived from slide-level metadata can provide effective semantic supervision for unified slide representation learning, enabling both pan-cancer prediction and weakly supervised tumor localization within a single framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ASTRA, a pan-cancer framework that unifies heterogeneous tile-level representations from multiple pathology foundation models into a shared slide-level space. It employs sparse mixture-of-experts contextualization, masked multi-model reconstruction, and contrastive alignment to structured prompts derived from slide-level metadata (classification category, cancer type, anatomic site) to support 4-category classification, 3-class solid tumor typing, 16-class cancer typing, and text-guided tumor localization without pixel-level supervision. Experiments on a CHTN development cohort of 10,359 WSIs report macro-AUCs up to 97.8% (4-category), 99.7% (3-class), and 99.2% (16-class), with mean Dice scores of 0.897 on an in-domain annotated subset (n=380) and 0.738 on an external TCGA cohort (n=1,686).
Significance. If the reported gains hold under the described controls, the work demonstrates that minimal structured pathology metadata can provide effective semantic supervision for multi-foundation-model slide representations, enabling both high-accuracy pan-cancer classification and usable weakly-supervised localization across 16 cancer types and external cohorts. The backbone-specific ablations, prompt controls, and external validation constitute concrete strengths that support the central claim of unification without circularity or leakage.
minor comments (2)
- [Abstract] Abstract: the phrase 'four pathology foundation-model backbones' should be expanded to name the specific models (e.g., UNI, Virchow, etc.) so readers can immediately assess the breadth of the unification claim.
- The manuscript would benefit from a single consolidated table listing all reported AUC and Dice values together with the exact cohort sizes, number of classes, and whether the metric is macro- or micro-averaged.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of ASTRA, the accurate summary of our contributions, and the recommendation for minor revision. We are pleased that the strengths in backbone ablations, prompt controls, and external validation were highlighted.
Circularity Check
No significant circularity; claims rest on held-out empirical metrics
full rationale
The paper's derivation consists of an architectural pipeline (sparse mixture-of-experts contextualization, masked multi-model reconstruction, and contrastive alignment to metadata-derived prompts) whose outputs are evaluated via standard classification AUC and Dice scores on explicitly held-out CHTN subsets and an external TCGA cohort. No equations or definitions reduce the reported performance numbers to quantities fitted from the same data by construction, and no load-bearing uniqueness theorems or self-citations are invoked to close the argument. The framework choices are independent of the final metrics, and the external validation provides an independent check, rendering the central claims self-contained rather than tautological.
Axiom & Free-Parameter Ledger
free parameters (1)
- mixture-of-experts routing and loss weighting hyperparameters
axioms (1)
- domain assumption Heterogeneous foundation-model tile representations can be effectively projected into a shared slide-level space via mixture-of-experts and contrastive alignment to metadata prompts.
Reference graph
Works this paper leans on
-
[1]
& Saha, S
Baxi, V ., Edwards, R., Montalto, M. & Saha, S. Digital pathology and artificial intelligence in translational medicine and clinical practice.Modern Pathology35, 23–32 (2022)
2022
-
[2]
Niazi, M. K. K., Parwani, A. V . & Gurcan, M. N. Digital pathology and artificial intelligence.The lancet oncology20, e253–e261 (2019)
2019
-
[3]
& Topol, E
Rajpurkar, P., Chen, E., Banerjee, O. & Topol, E. J. Ai in health and medicine.Nature medicine28, 31–38 (2022)
2022
-
[4]
Akbar, A. R.et al.Learning the language of histopathology images reveals prognostic subgroups in invasive lung adenocarcinoma patients.arXiv preprint arXiv:2508.16742(2025)
-
[5]
Streamlinepathologyfoundationmodelbycross-magnificationdistil- lation
Su, Z., Akbar, A. R., Sajjad, U., Parwani, A. V . & Niazi, M. K. K. Streamline pathology foundation model by cross-magnification distillation.arXiv preprint arXiv:2509.23097(2025)
-
[6]
J.et al.Towards a general-purpose foundation model for computational pathology.Nature Medicine(2024)
Chen, R. J.et al.Towards a general-purpose foundation model for computational pathology.Nature Medicine(2024)
2024
- [7]
-
[8]
Xu, H.et al.A whole-slide foundation model for digital pathology from real-world data.Nature(2024)
2024
-
[9]
Y .et al.A visual-language foundation model for computational pathology.Nature Medicine30, 863–874 (2024)
Lu, M. Y .et al.A visual-language foundation model for computational pathology.Nature Medicine30, 863–874 (2024)
2024
-
[10]
Chen, Y ., Su, Z., Khan, H. & Niazi, M. K. K. Ranger: Sparsely-gated mixture-of-experts with adaptive retrieval re-ranking for pathology report generation.arXiv preprint arXiv:2603.04348(2026)
-
[11]
Choi, J. H. & Ro, J. Y . The 2020 who classification of tumors of soft tissue: selected changes and new entities.Advances in anatomic pathology28, 44–58 (2021)
2020
-
[12]
& Brox, T
Ronneberger, O., Fischer, P. & Brox, T. U-net: Convolutional networks for biomedical image segmen- tation. InInternational Conference on Medical image computing and computer-assisted intervention, 234–241 (Springer, 2015)
2015
-
[13]
F., Kohl, S
Isensee, F., Jaeger, P. F., Kohl, S. A., Petersen, J. & Maier-Hein, K. H. nnu-net: a self-configuring method for deep learning-based biomedical image segmentation.Nature methods18, 203–211 (2021)
2021
-
[14]
& Ciompi, F
Van Rijthoven, M., Balkenhol, M., Silin ¸a, K., Van Der Laak, J. & Ciompi, F. Hooknet: Multi-resolution convolutional neural networks for semantic segmentation in histopathology whole-slide images.Medical image analysis68, 101890 (2021)
2021
-
[15]
Wang, Z.et al.Label cleaning multiple instance learning: Refining coarse annotations on single whole- slide images.IEEE transactions on medical imaging41, 3952–3968 (2022)
2022
-
[16]
Verghese, G.et al.Computational pathology in cancer diagnosis, prognosis, and prediction–present day and prospects.The Journal of pathology260, 551–563 (2023)
2023
-
[17]
Campanella, G.et al.Clinical-grade computational pathology using weakly supervised deep learning on whole slide images.Nature medicine25, 1301–1309 (2019)
2019
-
[18]
Y .et al.Data-efficient and weakly supervised computational pathology on whole-slide images
Lu, M. Y .et al.Data-efficient and weakly supervised computational pathology on whole-slide images. Nature biomedical engineering5, 555–570 (2021)
2021
-
[19]
& Welling, M
Ilse, M., Tomczak, J. & Welling, M. Attention-based deep multiple instance learning. InInternational conference on machine learning, 2127–2136 (PMLR, 2018). 25
2018
-
[20]
Shao, Z.et al.Transmil: Transformer based correlated multiple instance learning for whole slide image classification.Advances in neural information processing systems34, 2136–2147 (2021)
2021
- [21]
-
[22]
Combining foundation models in computational pathology: Unlocking multi-representational insights (2025)
Runevic, J. Combining foundation models in computational pathology: Unlocking multi-representational insights (2025)
2025
-
[23]
Chen, Y .et al.Histomet: A pan-cancer deep learning framework for prognostic prediction of metastatic progression and site tropism from primary tumor histopathology.arXiv preprint arXiv:2602.07608(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
Ding, T.et al.A multimodal whole-slide foundation model for pathology.Nature medicine1–13 (2025)
2025
-
[25]
A foundational multimodal vision language ai assistant for human pathology,
Lu, M. Y .et al.A foundational multimodal vision language ai assistant for human pathology.arXiv preprint arXiv:2312.07814(2023)
-
[26]
Skrede, O.-J.et al.Generalisation of automatic tumour segmentation in histopathological whole-slide images across multiple cancer types.npj Precision Oncology(2026)
2026
-
[27]
Cooperative human tissue network (CHTN).https://www.chtn.org (2024)
National Cancer Institute. Cooperative human tissue network (CHTN).https://www.chtn.org (2024)
2024
-
[28]
arXiv preprint arXiv:2502.06750 (2025)
Zhang, A., Jaume, G., Vaidya, A., Ding, T. & Mahmood, F. Accelerating data processing and benchmark- ing of ai models for pathology.arXiv preprint arXiv:2502.06750(2025)
-
[29]
Shazeer, N.et al.Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.arXiv preprint arXiv:1701.06538(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[30]
Tang, F.et al.Hi-end-mae: Hierarchical encoder-driven masked autoencoders are stronger vision learners for medical image segmentation.Medical Image Analysis103770 (2025)
2025
-
[31]
Kingma, D. P. & Ba, J. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980 (2014). 26
work page internal anchor Pith review Pith/arXiv arXiv 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.