Recognition: unknown
Perceptions and Utilization of GenAI Tools among Data Science Students and Faculty
Pith reviewed 2026-05-08 08:39 UTC · model grok-4.3
The pith
Survey of data science students and faculty finds heavy generative AI use paired with limited literacy and classroom integration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
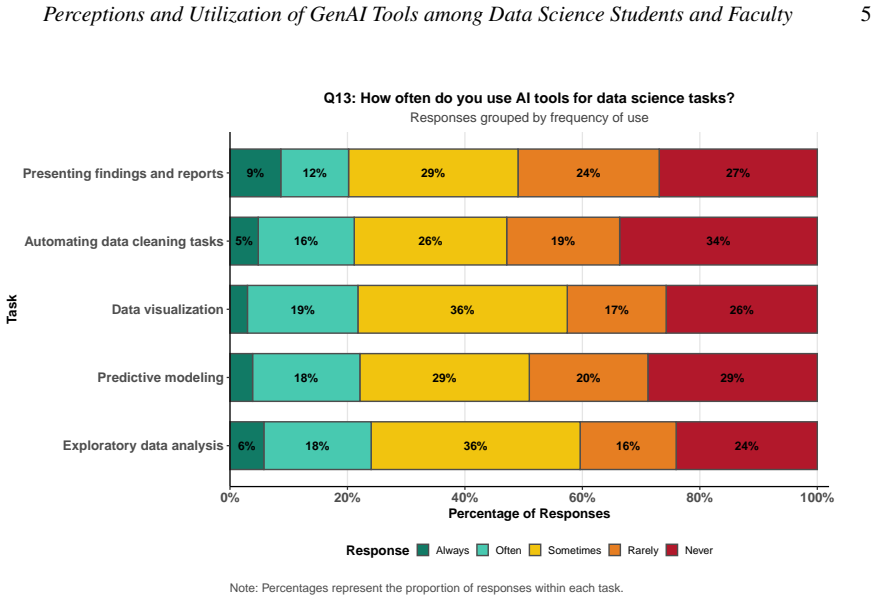
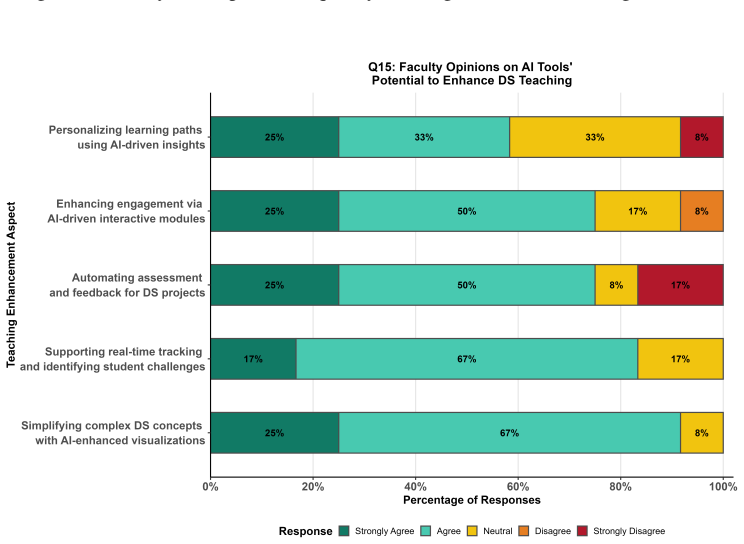
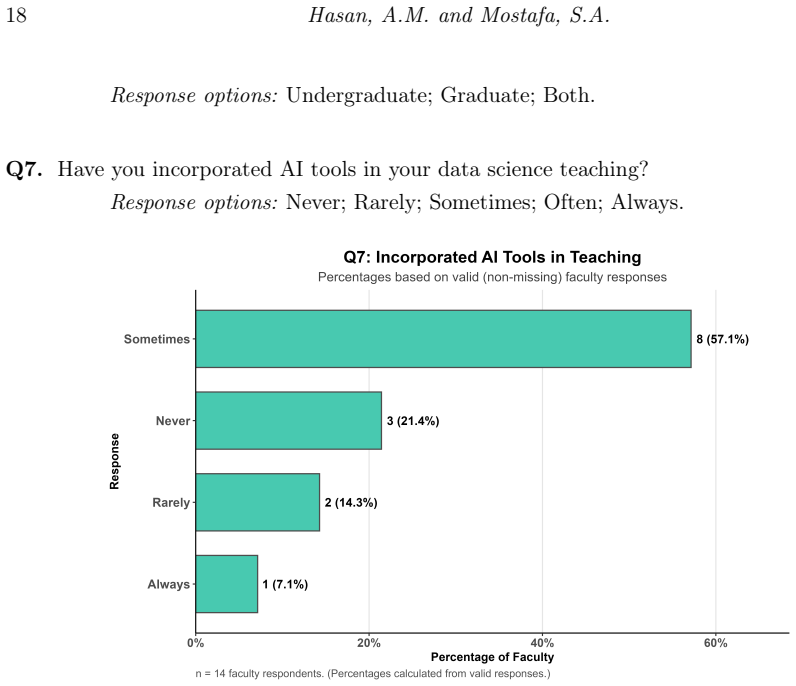
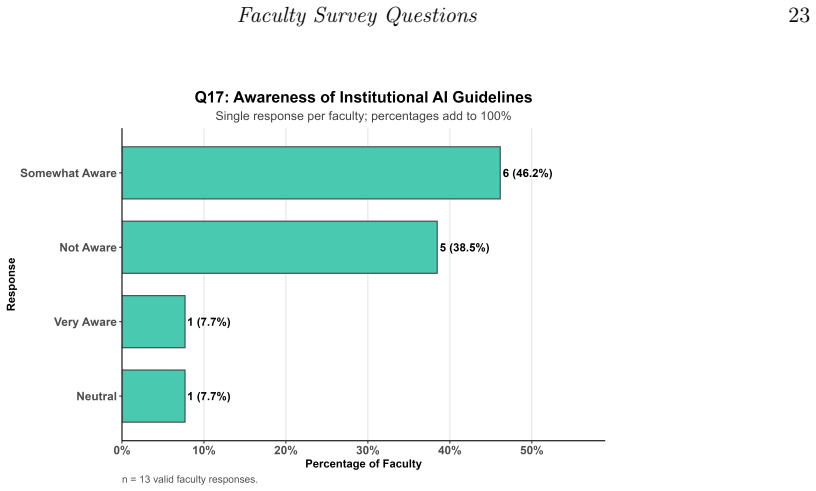
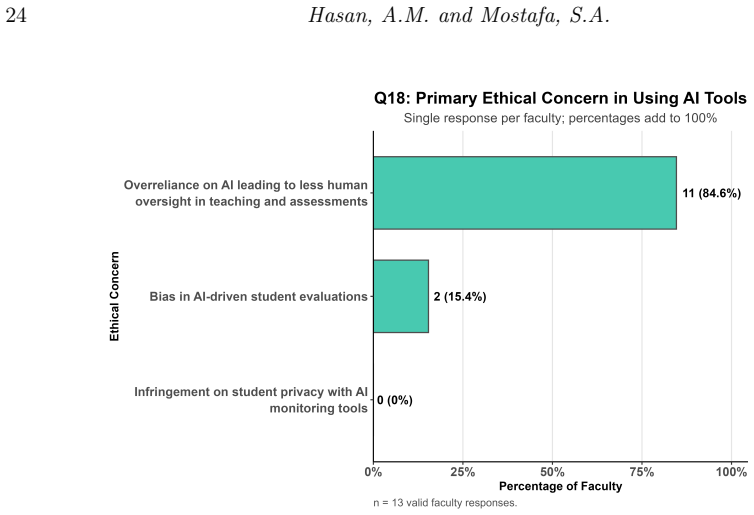
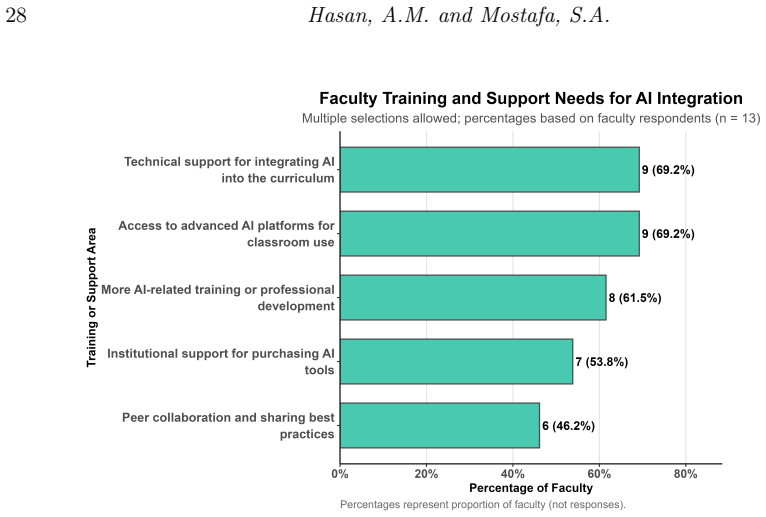
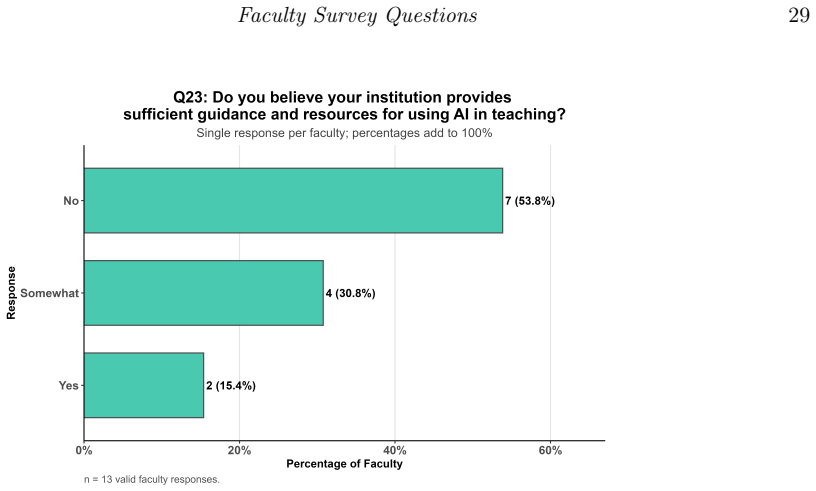
Students in data science programs use generative AI tools extensively, primarily ChatGPT for coding assistance and writing support, and hold positive perceptions of AI in their field and future careers, yet they demonstrate limited confidence in interpreting AI-generated outputs and raise concerns about accuracy, reliability, and over-reliance. Faculty members also view these tools favorably but report low self-rated proficiency and infrequent use in teaching. These patterns vary more by academic level than by gender, highlighting a disconnect between high adoption rates and insufficient AI literacy that calls for structured training, validation practices, and institutional policies for safe
What carries the argument
Survey responses from 119 students and 14 faculty on familiarity, usage patterns, perceived benefits, awareness of limitations, and instructional support needs, with subgroup comparisons by academic level and gender.
Load-bearing premise
Self-reported answers from one institution capture actual usage, perceptions, and teaching behaviors without major social desirability or non-response bias.
What would settle it
A follow-up that tracks real tool usage logs or tests participants' ability to spot errors in AI-generated code and analysis would contradict the reported confidence levels if actual skills prove lower.
Figures















read the original abstract
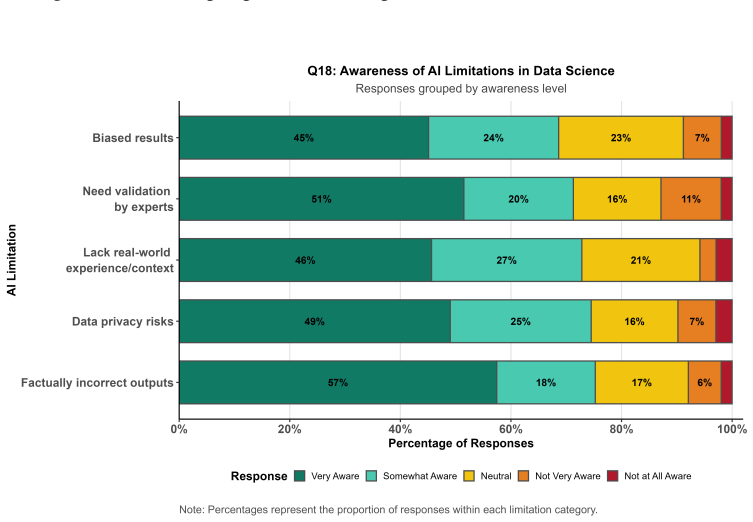
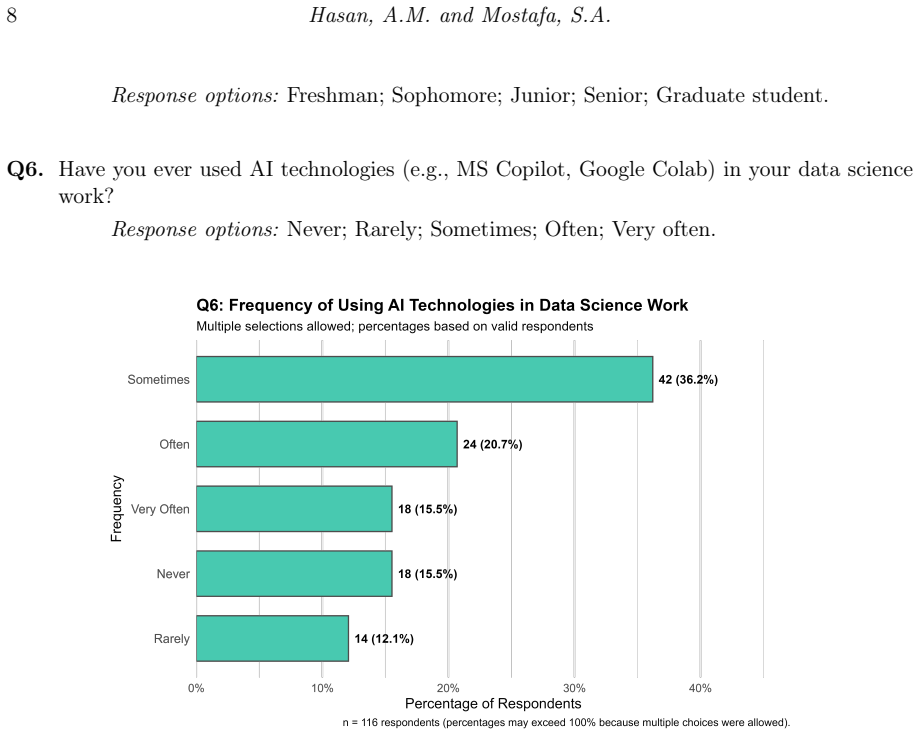
This study investigates perceptions and use of generative artificial intelligence (GenAI) tools among students and faculty in statistics and data science at a historically Black college or university. Survey data from 119 valid student responses and 14 faculty responses were used to examine familiarity, usage patterns, perceived benefits, awareness of limitations, and instructional support needs. Students reported substantial use of GenAI, with ChatGPT as the dominant tool, primarily for coding assistance and writing support. Although student perceptions of AI in data science workflows and careers were generally positive, confidence in interpreting AI-generated outputs was limited, and concerns about accuracy, reliability, and over-reliance were common. Faculty also viewed GenAI favorably, but self-rated proficiency and the frequency of classroom integration remained limited. Comparisons across student subgroups suggested that familiarity with GenAI and awareness of its limitations varied more by academic level than by gender. These findings highlight a gap between AI adoption and AI literacy and underscore the need for structured training, validation practices, and clearer institutional guidance for responsible AI integration in data science education.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This paper reports findings from a survey of 119 students and 14 faculty in statistics and data science at a single HBCU. It describes high GenAI adoption (ChatGPT dominant for coding/writing), generally positive perceptions of AI in workflows and careers, but limited student confidence in outputs and widespread concerns about accuracy/reliability/over-reliance. Faculty report favorable views yet limited self-rated proficiency and classroom integration. Subgroup patterns suggest greater variation by academic level than gender. The authors conclude there is a gap between adoption and literacy, calling for structured training, validation practices, and institutional guidance.
Significance. If the descriptive patterns hold under improved methodology, the work offers value by documenting AI perceptions in an underrepresented institutional setting (HBCU) and could usefully inform curriculum development in data science education. The explicit focus on an HBCU is a strength that adds diversity to the literature on responsible AI integration.
major comments (4)
- [Methods] Methods section: the manuscript provides no response rate, total invitations distributed, or non-response analysis, which directly weakens claims about usage patterns and the inferred adoption-literacy gap (Abstract and Methods).
- [Methods] Methods section: no details are given on questionnaire design, pilot testing, or validation (e.g., reliability metrics), so self-rated confidence and limitation-awareness items cannot robustly support the central claim of a literacy deficit.
- [Results] Results section: faculty analyses rest on n=14, rendering statements about limited proficiency and classroom integration statistically fragile and limiting the force of recommendations for institutional guidance.
- [Results] Results section: subgroup comparisons (academic level vs. gender) are presented descriptively without statistical tests, p-values, or effect sizes, so the assertion that variation is greater by academic level lacks evidential support.
minor comments (1)
- [Abstract] Abstract: '119 valid student responses' is stated without defining validity criteria or describing any data-cleaning steps.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below and indicate the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [Methods] Methods section: the manuscript provides no response rate, total invitations distributed, or non-response analysis, which directly weakens claims about usage patterns and the inferred adoption-literacy gap (Abstract and Methods).
Authors: We agree this information would improve assessment of sample representativeness. The survey was distributed anonymously through departmental email lists to all students and faculty in the relevant programs. Exact invitation counts were not logged, precluding calculation of a response rate or non-response analysis. In revision we will expand the Methods section to detail the recruitment approach, report the 119 valid student and 14 valid faculty responses obtained, and explicitly note the inability to compute a response rate as a limitation, thereby qualifying claims about adoption patterns. revision: partial
-
Referee: [Methods] Methods section: no details are given on questionnaire design, pilot testing, or validation (e.g., reliability metrics), so self-rated confidence and limitation-awareness items cannot robustly support the central claim of a literacy deficit.
Authors: We accept this critique. Questionnaire items were adapted from prior published surveys on AI and technology adoption in education; the instrument was reviewed by the research team and two additional faculty members for clarity and face validity but was not pilot-tested on a separate sample or subjected to formal reliability analysis. We will add a Methods subsection describing item sources, development process, and internal review, while noting the absence of formal validation as a limitation and discussing its implications for the literacy-deficit interpretation. revision: yes
-
Referee: [Results] Results section: faculty analyses rest on n=14, rendering statements about limited proficiency and classroom integration statistically fragile and limiting the force of recommendations for institutional guidance.
Authors: We concur that n=14 limits statistical robustness and generalizability. These responses represent a large fraction of the small faculty population in the targeted departments at this single institution. In revision we will frame all faculty results as purely descriptive, remove any language implying broader inference, and strengthen the limitations paragraph to caution against over-interpretation while qualifying institutional-guidance recommendations as preliminary and requiring confirmation in larger samples. revision: yes
-
Referee: [Results] Results section: subgroup comparisons (academic level vs. gender) are presented descriptively without statistical tests, p-values, or effect sizes, so the assertion that variation is greater by academic level lacks evidential support.
Authors: We agree that the comparative claim would be stronger with statistical support. Subgroup cell sizes are uneven and in some cases small, rendering standard parametric tests inappropriate. In the revised manuscript we will either conduct and report suitable non-parametric tests (e.g., chi-square) where assumptions can be met, or remove the explicit comparative assertion and present the patterns as descriptive observations only, accompanied by appropriate caveats. revision: partial
Circularity Check
No circularity in purely descriptive survey study
full rationale
The paper reports survey results on GenAI perceptions and usage among students and faculty with no equations, models, fitted parameters, predictions, or derivation steps of any kind. All claims derive directly from the collected self-reported responses without self-definitional loops, fitted-input predictions, load-bearing self-citations, imported uniqueness theorems, smuggled ansatzes, or renamings of prior results. As a self-contained empirical description with no mathematical chain to inspect, no circularity is present.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Self-reported survey answers reflect respondents' actual perceptions and behaviors
Reference graph
Works this paper leans on
-
[1]
Bauer E, Richters C, Pickal AJ, Klippert M, Sailer M, Stadler M (2025). Effects of AI-generated adaptive feedback on statistical skills and interest in statistics: A field experiment in higher education.British Journal of Educational Technology, 56: 1735–1757. Brynjolfsson E, Chandar B, Chen R (2025). Canaries in the coal mine? six facts about the recent ...
2025
-
[2]
Duah JE, McGivern P (2024). How generative artificial intelligence has blurred notions of authorial identity and academic norms in higher education, necessitating clear university usage policies.The International Journal of Information and Learning Technology, 41(2): 180–193. Glickman M, Yan J (2025). ASA members’ perspectives on the use of generative AI....
2024
-
[3]
Not at All Familiar
Prilop CN, Mah DK, Jacobsen LJ, Hansen RR, Weber KE, Hoya F (2025). Generative AI in teacher education: Educators’ perceptions of transformative potentials and the triadic nature of AI literacy explored through AI-enhanced methods.Computers and Education: Artificial Intelligence, 9: 100471. R Core Team (2024).R: A Language and Environment for Statistical ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.