0
Detectors for subspace signals in nonzero-mean clutter lose one DOF
Adaptive Subspace Signal Detection and Performance Analysis in Nonzero-Mean Clutter
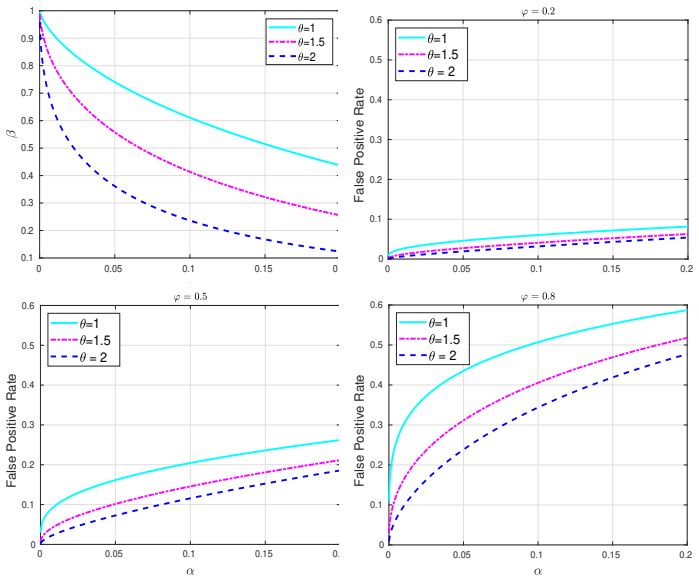
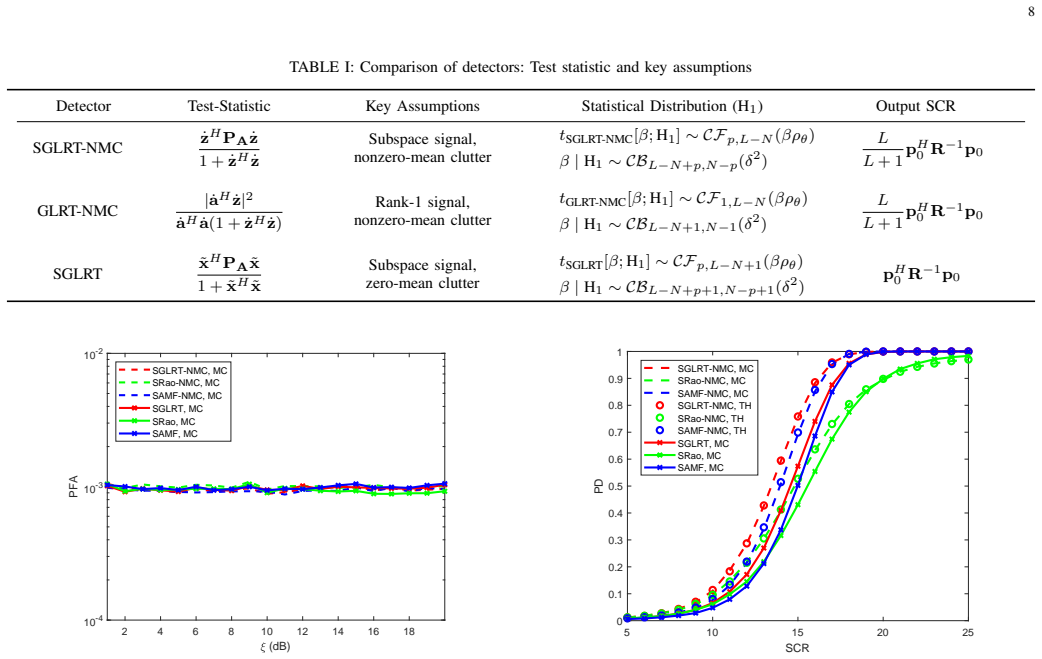
GLRT, Rao and Wald versions retain the same structure as zero-mean clutter but incur explicit DOF and SCR losses shown by closed-form PD and
 full image
full image
abstract click to expand
To solve the problem of detecting subspace signals in nonzero-mean clutter, we propose adaptive detectors, based on the strategies of generalized likelihood ratio test (GLRT), Rao test, Wald test, gradient test, and Durbin test. The results show that the detectors based on GLRT, Rao and Wald are structurally consistent with the subspace detectors in zero-means clutter. The analytic expressions for the probability of detection (PD) and probability of false alarm (PFA) of each detector are derived, and two major performance differences in the nonzero-mean clutter scenario are revealed. One is the loss of degree of freedom (DOF), which is reduced by 1 compared with the zero-mean clutter scenario. The second is the loss of signal-to-clutter (SCR) ratio. Simulation and measured data verify the effectiveness of the proposed detectors and demonstrate their practical value in real-world radar systems.