Recognition: unknown
K-Score: Kalman Filter as a Principled Alternative to Reward Normalization in Reinforcement Learning
Pith reviewed 2026-05-08 11:59 UTC · model grok-4.3
The pith
A 1D Kalman filter replaces reward normalization in policy gradient reinforcement learning by online estimation of the latent reward mean.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a 1D Kalman filter can be integrated into the reward pipeline to recursively estimate the latent reward mean from noisy returns, yielding an adaptive and variance-reduced signal that is fed directly into policy gradient updates without any changes to the policy network architecture.
What carries the argument
A 1D Kalman filter applied to the stream of observed returns, which maintains and updates estimates of the reward mean and its uncertainty through recursive prediction and correction steps.
If this is right
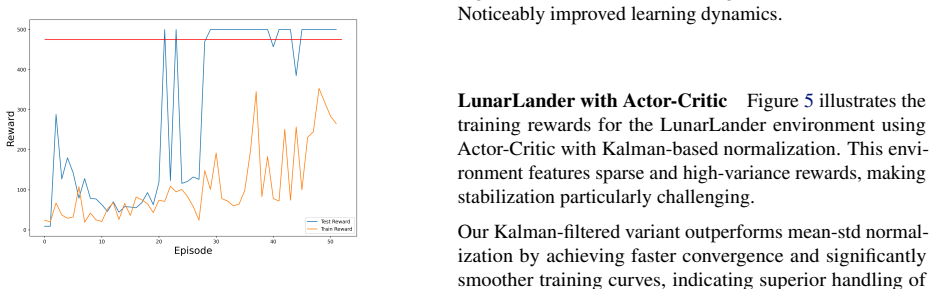
- Convergence occurs faster on LunarLander and CartPole than with conventional reward normalization.
- Training variance across runs decreases when the Kalman estimate is used in place of normalized rewards.
- The estimate adapts automatically to changes in reward scale without manual retuning of normalization parameters.
- No modifications to existing policy or value network architectures are required.
- Computational overhead stays negligible because the filter operates in one dimension with simple recursive updates.
Where Pith is reading between the lines
- The same filtering idea could be applied to advantage estimates or temporal-difference errors to reduce variance in other parts of the learning process.
- Environments with deliberately drifting or non-stationary rewards would serve as stronger tests of the adaptation property.
- Optimal Kalman noise parameters might be learned jointly with the policy rather than set by hand.
- Similar recursive smoothing could address noisy signals in sequential decision problems outside reinforcement learning.
Load-bearing premise
Observed returns behave as noisy measurements around a slowly varying latent reward mean that the filter can track accurately enough to improve policy updates without adding bias or instability.
What would settle it
Running the Kalman-filtered reward method on LunarLander and finding no faster convergence or no reduction in training variance compared with standard normalization would refute the claimed advantage.
Figures






read the original abstract
We propose a simple yet effective alternative to reward normalization in policy gradient reinforcement learning by integrating a 1D Kalman filter for online reward estimation. Instead of relying on fixed heuristics, our method recursively estimates the latent reward mean, smoothing high-variance returns and adapting to non-stationary environments. This approach incurs minimal overhead and requires no modification to existing policy architectures. Experiments on \textit{LunarLander} and \textit{CartPole} demonstrate that Kalman-filtered rewards significantly accelerate convergence and reduce training variance compared to standard normalization techniques. Code is available at https://github.com/Sumxiaa/Kalman_Normalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes K-Score, a method that integrates a 1D Kalman filter to recursively estimate the latent mean of observed rewards in policy-gradient RL. This is presented as a principled, low-overhead alternative to heuristic reward normalization that smooths variance and adapts to non-stationary reward scales without altering policy architectures. Experiments on LunarLander and CartPole are reported to show faster convergence and lower training variance than standard normalization.
Significance. If the central claim holds, the work supplies a simple, theoretically grounded filtering approach to reward scaling that could be broadly useful in non-stationary RL settings. Public code availability is a clear strength that supports reproducibility. The overall significance remains moderate because the empirical support is confined to two classic control tasks and the manuscript provides no quantitative metrics, run counts, or statistical tests.
major comments (2)
- [§2] §2 (online Kalman recursion and policy-gradient integration): The description states that the filter 'recursively estimates the latent reward mean' and that the estimate is 'fed into the policy gradient update.' It is not specified whether the measurement update at timestep t uses the reward r_t generated by the action a_t sampled from the current policy. This timing detail is load-bearing because any dependence between the baseline-like term and the sampled action risks introducing bias into the policy-gradient estimator, violating the usual independence requirement for unbiasedness.
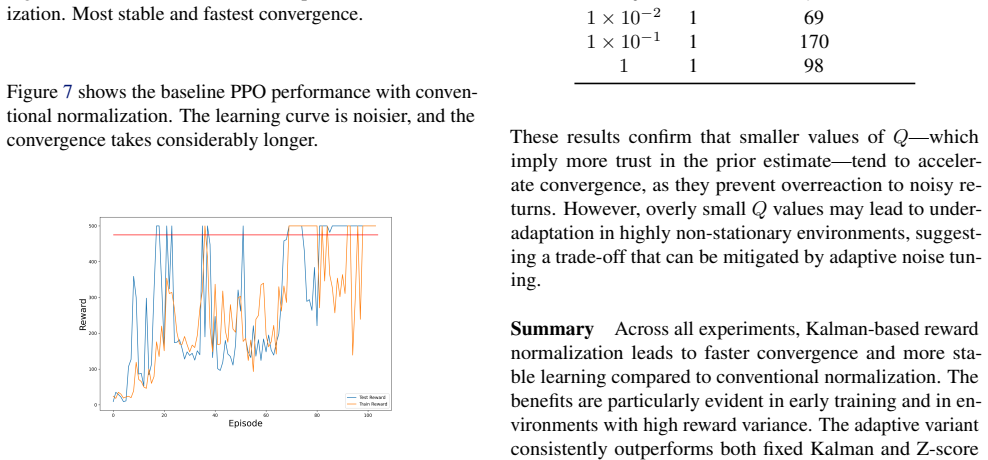
- [Experiments] Experiments section: The claims that Kalman-filtered rewards 'significantly accelerate convergence and reduce training variance' are presented without any numerical results, number of independent runs, exact baseline implementations (e.g., running-mean normalization), or statistical tests. Because the central empirical claim rests on these comparisons, the absence of such details prevents assessment of whether the reported gains are robust or merely anecdotal.
minor comments (2)
- [Abstract] The abstract and title use 'K-Score' and 'Kalman-filtered rewards' interchangeably; a single consistent term would improve clarity.
- [§2] The Kalman filter equations would benefit from explicit recursion formulas (including the roles of process-noise and measurement-noise variances) rather than high-level description only.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important clarifications needed for the algorithmic description and strengthens the empirical evaluation. We address each major comment below and will incorporate revisions to improve the manuscript.
read point-by-point responses
-
Referee: [§2] §2 (online Kalman recursion and policy-gradient integration): The description states that the filter 'recursively estimates the latent reward mean' and that the estimate is 'fed into the policy gradient update.' It is not specified whether the measurement update at timestep t uses the reward r_t generated by the action a_t sampled from the current policy. This timing detail is load-bearing because any dependence between the baseline-like term and the sampled action risks introducing bias into the policy-gradient estimator, violating the usual independence requirement for unbiasedness.
Authors: We appreciate the referee pointing out this critical implementation detail regarding unbiasedness. In the K-Score approach, the 1D Kalman filter follows a standard predict-then-update recursion. At timestep t, the policy gradient for action a_t is computed using the current predicted reward mean estimate (prior to the measurement update). The reward r_t is observed only after the action is taken and the gradient step is performed; the measurement update then incorporates r_t to refine the estimate for future timesteps. This ordering ensures the baseline term remains independent of a_t. We will revise §2 to include explicit pseudocode and a step-by-step timing diagram clarifying this sequence. revision: yes
-
Referee: [Experiments] Experiments section: The claims that Kalman-filtered rewards 'significantly accelerate convergence and reduce training variance' are presented without any numerical results, number of independent runs, exact baseline implementations (e.g., running-mean normalization), or statistical tests. Because the central empirical claim rests on these comparisons, the absence of such details prevents assessment of whether the reported gains are robust or merely anecdotal.
Authors: We agree that the experimental claims require quantitative support and statistical rigor to be fully convincing. In the revised manuscript, we will expand the Experiments section with tables reporting mean performance and standard deviation across a minimum of 10 independent random seeds for both LunarLander and CartPole. We will precisely describe the baseline normalization (including whether it uses a fixed-window running mean, exponential moving average, or other variant, along with all hyperparameters). Convergence will be quantified via metrics such as episodes to reach a target return threshold, and we will include statistical comparisons (e.g., Welch's t-test or Mann-Whitney U test with p-values) between K-Score and the baselines. All code for reproducing these results is already public, and we will add the exact run counts and seed values to the text. revision: yes
Circularity Check
No circularity; direct application of standard Kalman filter recursion.
full rationale
The paper proposes integrating a 1D Kalman filter to recursively estimate the latent reward mean as an alternative to heuristic reward normalization. This is a straightforward substitution of an established filtering algorithm into the policy gradient update, with no claimed mathematical derivation that reduces to a self-referential definition, a fitted parameter renamed as a prediction, or a load-bearing self-citation chain. The central claim rests on empirical results from LunarLander and CartPole rather than any closed-form equivalence to its inputs. The online nature of the filter is presented as a feature for non-stationary environments, without any internal equations that force the reported gains by construction.
Axiom & Free-Parameter Ledger
free parameters (2)
- process noise variance
- measurement noise variance
axioms (1)
- domain assumption The sequence of returns can be modeled as noisy observations of a latent constant or slowly varying mean.
Reference graph
Works this paper leans on
-
[1]
P., Mirza, M., Graves, A., Lillicrap, T., Harley, T., Silver, D., and Kavukcuoglu, K
Mnih, V ., Badia, A. P., Mirza, M., Graves, A., Lillicrap, T., Harley, T., Silver, D., and Kavukcuoglu, K. Asyn- chronous methods for deep reinforcement learning. In International conference on machine learning, pp. 1928–
1928
-
[2]
Painter-Wakefield, C. and Parr, R. Greedy algorithms for sparse reinforcement learning.arXiv preprint arXiv:1206.6485,
-
[3]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
Schulman, J., Levine, S., Abbeel, P., Jordan, M., and Moritz, P. Trust region policy optimization. InInternational conference on machine learning, pp. 1889–1897. PMLR, 2015a. Schulman, J., Moritz, P., Levine, S., Jordan, M., and Abbeel, P. High-dimensional continuous control using generalized advantage estimation.arXiv preprint arXiv:1506.02438, 2015b. Sc...
work page internal anchor Pith review arXiv 2025
- [4]
-
[5]
Deep reinforcement learning and the deadly triad
Van Hasselt, H., Doron, Y ., Strub, F., Hessel, M., Sonnerat, N., and Modayil, J. Deep reinforcement learning and the deadly triad.arXiv preprint arXiv:1812.02648,
-
[6]
Kalman Filter Enhanced GRPO for Reinforcement Learning-Based Language Model Reasoning
Wang, H., Ma, C., Reid, I., and Yaqub, M. Kalman filter enhanced grpo for reinforcement learning-based language model reasoning.arXiv preprint arXiv:2505.07527,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.