Recognition: unknown
Towards Automated Ontology Generation from Unstructured Text: A Multi-Agent LLM Approach
Pith reviewed 2026-05-08 08:21 UTC · model grok-4.3
The pith
A multi-agent LLM system with four specialized roles generates structurally superior ontologies from text by prioritizing upfront planning over single-agent fixes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A controlled experiment on domain-specific insurance contracts establishes that decomposing ontology construction into four artifact-driven LLM roles—Domain Expert, Manager, Coder, and Quality Assurer—significantly raises structural quality and modestly improves queryability relative to a single-agent baseline, with the gains attributable primarily to front-loaded planning that avoids common failure modes such as poor Ontology Design Pattern compliance, structural redundancy, and ineffective iterative repair.
What carries the argument
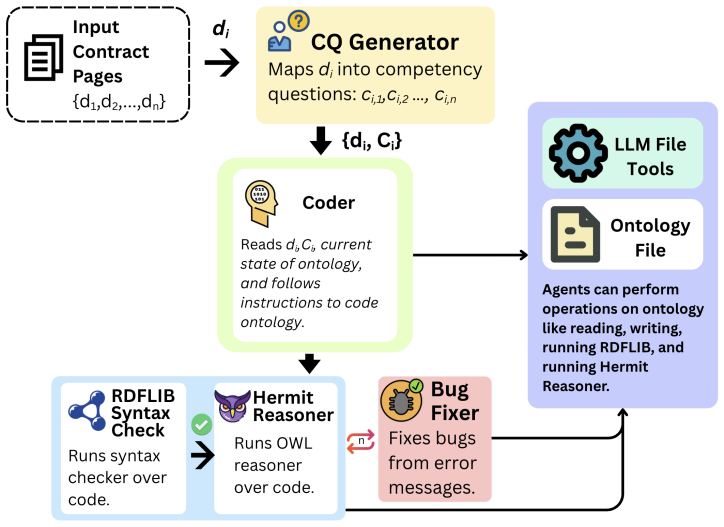
The multi-agent architecture that assigns four distinct artifact-driven roles (Domain Expert, Manager, Coder, Quality Assurer) to enforce sequential, auditable steps in ontology generation.
If this is right
- Front-loaded planning within multi-agent setups reduces structural redundancy and design-pattern violations that single agents produce.
- Artifact-driven role separation creates a more auditable workflow for automated ontology engineering.
- The modest gains in queryability indicate the resulting ontologies support more effective SPARQL-based retrieval augmented generation.
- The same planning-first decomposition could extend automated ontology work to other contract or report corpora beyond insurance.
Where Pith is reading between the lines
- Role specialization may help LLMs manage other complex generation tasks where single models lose coherence across steps.
- Applying the four-role pattern to scientific literature or legal statutes would test whether the planning benefit generalizes.
- Inserting a human review only at the Quality Assurer stage could raise reliability while preserving most of the automation.
Load-bearing premise
Evaluations by a panel of heterogeneous LLM judges together with competency-question SPARQL tests supply reliable and unbiased measures of structural quality and functional usability.
What would settle it
Human experts reviewing the generated ontologies and finding no meaningful difference in structural compliance or query success rates between the multi-agent and single-agent versions would falsify the reported improvement.
Figures


read the original abstract
Automatically generating formal ontologies from unstructured natural language remains a central challenge in knowledge engineering. While large language models (LLMs) show promise, it remains unclear which architectural design choices drive generation quality and why current approaches fail. We present a controlled experimental study using domain-specific insurance contracts to investigate these questions. We first establish a single-agent LLM baseline, identifying key failure modes such as poor Ontology Design Pattern compliance, structural redundancy, and ineffective iterative repair. We then introduce a multi-agent architecture that decomposes ontology construction into four artifact-driven roles: Domain Expert, Manager, Coder, and Quality Assurer. We evaluate performance across architectural quality (via a panel of heterogeneous LLM judges) and functional usability (via competency question driven SPARQL evaluation with complementary retrieval augmented generation based assessment). Results show that the multi-agent approach significantly improves structural quality and modestly enhances queryability, with gains driven primarily by front-loaded planning. These findings highlight planning-first, artifact-driven generation as a promising and more auditable path toward scalable automated ontology engineering.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports a controlled comparison of single-agent versus multi-agent LLM architectures for generating formal ontologies from unstructured insurance contract text. The multi-agent system decomposes the task into Domain Expert, Manager, Coder, and Quality Assurer roles with emphasis on front-loaded planning. Structural quality is assessed via a panel of heterogeneous LLM judges, and functional usability via competency-question SPARQL queries with RAG. The authors conclude that the multi-agent approach yields significant structural improvements and modest queryability gains primarily due to the planning component.
Significance. If substantiated, the results would support artifact-driven, planning-first multi-agent designs as a viable path for improving the reliability of LLM-generated ontologies. This has potential implications for scalable automated knowledge engineering in regulated domains, offering greater auditability than end-to-end prompting approaches.
major comments (2)
- [Abstract] The claim of significant improvement in structural quality is based on LLM-judge panel scores without any reported calibration to human experts, inter-rater reliability metrics (such as agreement statistics), or blinding. This undermines confidence in the causal link to front-loaded planning, as the gains could stem from stylistic preferences of the judge LLMs rather than objective ontological quality.
- [Results] No quantitative details are provided on effect sizes, statistical tests, or confidence intervals for the reported improvements. The SPARQL evaluation's objectivity is compromised by potential dependence on question selection and RAG quality that may favor the multi-agent outputs; full details on these aspects and raw data are needed to verify the modest enhancement in queryability.
minor comments (2)
- The manuscript should include the full set of prompts used for each agent role and the judge panel to enable reproducibility.
- Clarify the exact number and types of LLMs in the heterogeneous judge panel and any steps taken to mitigate bias.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help us improve the clarity and rigor of our evaluation. We address the major comments point by point below.
read point-by-point responses
-
Referee: [Abstract] The claim of significant improvement in structural quality is based on LLM-judge panel scores without any reported calibration to human experts, inter-rater reliability metrics (such as agreement statistics), or blinding. This undermines confidence in the causal link to front-loaded planning, as the gains could stem from stylistic preferences of the judge LLMs rather than objective ontological quality.
Authors: We recognize this as a valid point regarding the strength of our evidence. The structural quality assessment indeed uses scores from a panel of heterogeneous LLM judges, and we did not report calibration to human experts, inter-rater reliability, or blinding procedures. To address this, we will revise the manuscript to include a more detailed description of the judge panel composition and prompting strategy in the methods section. We will also add a limitations subsection explicitly discussing the potential for stylistic biases in LLM-based evaluation and the absence of human calibration. While we believe the multi-judge approach provides a reasonable proxy for quality assessment, we will tone down the language around 'significant' improvements to reflect the evaluation method more precisely and avoid implying statistical significance where none was computed. revision: partial
-
Referee: [Results] No quantitative details are provided on effect sizes, statistical tests, or confidence intervals for the reported improvements. The SPARQL evaluation's objectivity is compromised by potential dependence on question selection and RAG quality that may favor the multi-agent outputs; full details on these aspects and raw data are needed to verify the modest enhancement in queryability.
Authors: We agree that additional quantitative information and transparency are required. In the revised manuscript, we will expand the results section to report effect sizes, appropriate statistical tests (e.g., significance testing on score differences), and confidence intervals for the structural quality metrics. For the SPARQL-based queryability evaluation, we will provide complete details on the competency questions, their selection process, the RAG implementation, and any controls to ensure fairness across conditions. Furthermore, we will include or link to the raw data and query results to allow independent verification. These additions will substantiate the reported modest gains in queryability. revision: yes
Circularity Check
No circularity: empirical head-to-head evaluation on external data
full rationale
The paper conducts a controlled experimental comparison of single-agent versus multi-agent LLM architectures for generating ontologies from insurance contract text. It defines failure modes in the baseline, proposes an artifact-driven multi-agent decomposition, and measures outcomes via LLM-judge panels for structural quality plus SPARQL competency-question evaluation for usability. No equations, predictions, or first-principles claims are present that reduce by construction to fitted parameters, self-definitions, or self-citation chains; all results derive from independent runs on held-out text with externally defined metrics. The study is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A. S. Lippolis, M. J. Saeedizade, R. Keskis¨"arkk¨"a, S. Zuppiroli, M. Ceriani, A. Gangemi, E. Blomqvist, A. G. Nuzzolese, Ontology generation using large language models, in: European Semantic Web Conference, Springer, 2025, pp. 321–341
2025
-
[2]
M. J. Saeedizade, E. Blomqvist, Navigating ontology development with large language models, in: European Semantic Web Conference, Springer, 2024, pp. 143–161
2024
-
[3]
R. M. Bakker, D. L. Di Scala, M. de Boer, Ontology learning from text: an analysis on llm performance, in: Proceedings of the 3rd NLP4KGC International Workshop on Natural Language Processing for Knowledge Graph Creation, colocated with Semantics, 2024, pp. 17–19
2024
-
[4]
S. S. Norouzi, A. Barua, A. Christou, N. Gautam, A. Eells, P. Hitzler, C. Shimizu, Ontology population using llms, in: Handbook on Neurosymbolic AI and Knowledge Graphs, IOS Press, 2025, pp. 421–438
2025
-
[5]
Babaei Giglou, J
H. Babaei Giglou, J. D’Souza, S. Auer, LLMs4OL: Large Language Models for Ontology Learning, in: International Semantic Web Conference, Springer, 2023, pp. 408–427
2023
-
[6]
V. K. Kommineni, B. K¨"onig-Ries, S. Samuel, From human experts to machines: An llm supported approach to ontology and knowledge graph construction, CoRR (2024)
2024
-
[7]
A. Lo, A. Q. Jiang, W. Li, M. Jamnik, End-to-end ontology learning with large language models, Advances in Neural Information Processing Systems 37 (2024) 87184–87225
2024
-
[8]
R. R. Chowdhury, T. Goto, K. Tsuchida, T. Kirishima, A. Bandi, An automated framework of ontology generation for abstract concepts using llms, in: International Conference on Computers and Their Applications, Springer, 2025, pp. 170–180
2025
-
[9]
M. S. Abolhasani, R. Pan, Leveraging llm for automated ontology extraction and knowledge graph generation, CoRR (2024)
2024
-
[10]
Charalambous, A
M. Charalambous, A. Farao, G. Kalantzantonakis, P. Kanakakis, N. Salamanos, E. Kotsifakos, E. Froudakis, Analyzing coverages of cyber insurance policies using ontology, in: Proceedings of the 17th International Conference on Availability, Reliability and Security, 2022, pp. 1–7
2022
-
[11]
Ahaggach, L
H. Ahaggach, L. Abrouk, E. Lebon, Information extraction and ontology population using car insurance reports, in: International Conference on Information Technology-New Generations, Springer, 2023, pp. 405–411
2023
-
[12]
M. R. Naqvi, S. K. Shahzad, M. W. Iqbal, M. Al-Thawadi, Ontology-driven smart health insurance, in: Soft Computing Applications: Proceedings of the 9th International Workshop Soft Computing Applications (SOFA 2020), volume 1438, Springer Nature, 2023, p. 51
2020
-
[13]
Okikiola, A
F. Okikiola, A. Ikotun, A. Adelokun, P. Ishola, A systematic review of health care ontology, Asian J Res Comput Sci 5 (2020) 15–28
2020
-
[14]
Bezerra, F
C. Bezerra, F. Freitas, F. Santana, Evaluating ontologies with competency questions, in: 2013 IEEE/WIC/ACM International Joint Conferences on Web Intelligence (WI) and Intelligent Agent Technologies (IAT), volume 3, IEEE, 2013, pp. 284–285
2013
-
[15]
Araújo, G
W. Araújo, G. Lima, I. Pierozzi Jr, Data-driven ontology evaluation based on competency ques- tions: A study in the agricultural domain, in: Knowledge Organization for a Sustainable World: Challenges and Perspectives for Cultural, Scientific, and Technological Sharing in a Connected Society, Ergon-Verlag, 2016, pp. 326–332
2016
-
[16]
N. Noy, D. Mcguinness, Ontology development 101: A guide to creating your first ontology, Knowledge Systems Laboratory 32 (2001)
2001
- [17]
-
[18]
Horrocks, P
I. Horrocks, P. F. Patel-Schneider, H. Boley, S. Tabet, B. Grosof, M. Dean, et al., Swrl: A semantic web rule language combining owl and ruleml, W3C Member submission 21 (2004) 1–31
2004
-
[19]
El Ghosh, H
M. El Ghosh, H. Naja, H. Abdulrab, M. Khalil, Towards a legal rule-based system grounded on the integration of criminal domain ontology and rules, Procedia computer science 112 (2017) 632–642
2017
-
[20]
Amith, M
M. Amith, M. R. Harris, C. Stansbury, K. Ford, F. J. Manion, C. Tao, Expressing and executing informed consent permissions using swrl: the all of us use case, in: AMIA Annual Symposium Proceedings, volume 2021, 2022, p. 197
2021
-
[21]
Shimizu, Q
C. Shimizu, Q. Hirt, P. Hitzler, MODL: A modular ontology design library, in: Proceedings of the 10th Workshop on Ontology Design and Patterns (WOP 2019) co-located with 18th International Semantic Web Conference (ISWC 2019), volume 2459 ofCEUR Workshop Proceedings, 2019. URL: https://ceur-ws.org/Vol-2459/paper4.pdf
2019
-
[22]
Guizzardi, A
G. Guizzardi, A. Botti Benevides, C. M. Fonseca, D. Porello, J. P. A. Almeida, T. Prince Sales, Ufo: Unified foundational ontology, Applied ontology 17 (2022) 167–210
2022
-
[23]
A. S. Lippolis, M. Ceriani, S. Zuppiroli, A. G. Nuzzolese, Ontogenia: Ontology generation with metacognitive prompting in large language models, in: ESWC Satellite Events, 2024. URL: https: //api.semanticscholar.org/CorpusID:269756329
2024
-
[24]
J.-B. Lamy, Owlready: Ontology-oriented programming in python with automatic classification and high level constructs for biomedical ontologies, Artificial Intelligence in Medicine 80 (2017) 11–28. URL: https://www.sciencedirect.com/science/article/pii/S0933365717300271. doi:https: //doi.org/10.1016/j.artmed.2017.07.002
-
[25]
Shearer, B
R. Shearer, B. Motik, I. Horrocks, Hermit : A highly-efficient reasoner for description logics, 2008. URL: https://api.semanticscholar.org/CorpusID:1980435
2008
-
[26]
B. Mo, K. Yu, J. Kazdan, P. Mpala, L. Yu, C. I. Kanatsoulis, S. Koyejo, Kggen: Extracting knowledge graphs from plain text with language models, in: The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[27]
Yang, W.-t
Y. Yang, W.-t. Yih, C. Meek, WikiQA: A challenge dataset for open-domain question answering, in: Proceedings of the 2015 conference on empirical methods in natural language processing, 2015, pp. 2013–2018
2015
-
[28]
Robertson, S
S. Robertson, S. Walker, S. Jones, M. Hancock-Beaulieu, M. Gatford, Okapi at trec-3., 1994, pp. 0–
1994
-
[29]
Khattab, A
O. Khattab, A. Singhvi, P. Maheshwari, Z. Zhang, K. Santhanam, S. Haq, A. Sharma, T. T. Joshi, H. Moazam, H. Miller, et al., Dspy: Compiling declarative language model calls into self-improving pipelines, in: R0-FoMo: Robustness of Few-shot and Zero-shot Learning in Large Foundation Models, 2023
2023
-
[30]
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. Chi, Q. Le, D. Zhou, Chain-of-thought prompting elicits reasoning in large language models, 2023. URL: https://arxiv.org/abs/2201.11903. arXiv:2201.11903
work page internal anchor Pith review arXiv 2023
-
[31]
A. F. Hayes, K. Krippendorff, Answering the call for a standard reliability measure for coding data, Communication methods and measures 1 (2007) 77–89
2007
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.