Recognition: unknown
One Identity, Many Roles: Multimodal Entity Coreference for Enhanced Video Situation Recognition
Pith reviewed 2026-05-08 08:45 UTC · model grok-4.3
The pith
CineMEC unites text role mentions with visual entity clusters in videos without explicit supervision to improve situation recognition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CineMEC unites event role mention groups with visual clusters of entities without explicit grounding supervision during training by exploiting the synergy between visual grounding and captioning, where improving one influences the other and vice versa, resulting in gains on both captioning (+2.5% CIDEr, +7% LEA) and visual grounding (+18% HOTA) for video situation recognition on the extended VidSitu dataset.
What carries the argument
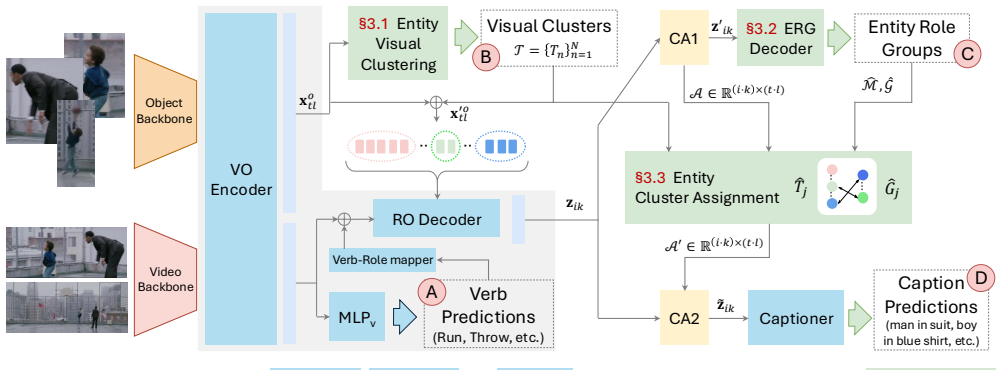
Multimodal Entity Coreference (MEC), which aligns groups of text mentions describing event roles with visual clusters of the same entities across video shots.
If this is right
- Captioning performance rises by 2.5 percent CIDEr and 7 percent LEA on the VidSitu dataset.
- Visual grounding performance rises by 18 percent HOTA through consistent entity identification across shots.
- Training requires no explicit spatio-temporal grounding labels because the two tasks reinforce each other.
- Entity consistency across multiple events supports more accurate answers to who-did-what-to-whom questions in video.
Where Pith is reading between the lines
- The same alignment idea could reduce the cost of creating training data for other video tasks that need both descriptions and localizations.
- Joint optimization of captioning and grounding may transfer to domains such as instructional videos or surveillance footage where entity tracking matters.
- If the synergy holds, similar coreference steps might help in settings with only weak or no cross-modal labels.
Load-bearing premise
Visual clusters of entities can be reliably aligned with text role mention groups through mutual synergy between grounding and captioning without any explicit grounding supervision or additional constraints during training.
What would settle it
No measurable gains in captioning or grounding metrics when the alignment step between text role groups and visual clusters is disabled during training.
Figures







read the original abstract
Video Situation Recognition (VidSitu) addresses the challenging problem of "who did what to whom, with what, how, and where" in a video. It tests thorough video understanding by requiring identification of salient actions and associated short descriptions for event roles across multiple events. Grounding with VidSitu requires spatio-temporal localization of key entities across shots and varied appearances. We posit that coherent video understanding requires consistent identification of entities that play different roles. We propose Multimodal Entity Coreference (MEC) to unite entity descriptions in text with grounding across the video. Towards this, we introduce CineMEC, a multi-stage approach that unites event role mention groups with visual clusters of entities, without explicit grounding supervision during training. Our approach is designed to exploit the synergy between visual grounding and captioning, where improving one influences the other and vice versa. For evaluation, we extend the VidSitu dataset with grounding annotations. While previous work focuses primarily on descriptions, CineMEC improves consistency across both: captioning (+2.5% CIDEr, +7% LEA) and visual grounding (+18% HOTA).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that coherent video situation recognition requires consistent entity identification across roles and appearances. It proposes Multimodal Entity Coreference (MEC) and introduces CineMEC, a multi-stage pipeline that aligns textual event role mention groups with visual entity clusters by exploiting synergy between captioning and grounding modules, without any explicit grounding supervision. The VidSitu dataset is extended with grounding annotations, and CineMEC is reported to improve captioning (+2.5% CIDEr, +7% LEA) and visual grounding (+18% HOTA).
Significance. If the unsupervised alignment via captioning-grounding synergy holds, the work would advance video understanding by reducing reliance on explicit grounding labels while improving cross-modal consistency for entity roles. The extension of VidSitu with grounding annotations is a concrete, reusable contribution. The reported metric gains indicate practical utility, but their attribution to the coreference mechanism (rather than dataset extension or backbone changes) requires verification to establish broader impact.
major comments (2)
- [Abstract / CineMEC description] Abstract and CineMEC pipeline description: the central claim that multi-stage training without explicit grounding supervision or additional constraints produces reliable alignment between event role mention groups and visual clusters rests on an unverified assumption of mutual synergy. No loss terms, correspondence objectives, or constraints are specified to enforce or guarantee this alignment, so the reported gains could arise from unrelated factors such as the dataset extension or stronger features.
- [Evaluation] Evaluation section: improvements are shown on the extended VidSitu dataset, but without ablations that isolate the MEC coreference component (e.g., comparing against a version using only the dataset extension or standard backbones), it is impossible to confirm that the +2.5% CIDEr, +7% LEA, and +18% HOTA gains are driven by the proposed entity coreference rather than confounding changes.
minor comments (1)
- [Method] The precise definitions of 'event role mention groups' and 'visual clusters of entities' (including how clusters are formed from appearance/motion features) should be stated explicitly early in the method section to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below with clarifications on the CineMEC pipeline and evaluation design, and we commit to revisions that strengthen the presentation of our contributions.
read point-by-point responses
-
Referee: [Abstract / CineMEC description] Abstract and CineMEC pipeline description: the central claim that multi-stage training without explicit grounding supervision or additional constraints produces reliable alignment between event role mention groups and visual clusters rests on an unverified assumption of mutual synergy. No loss terms, correspondence objectives, or constraints are specified to enforce or guarantee this alignment, so the reported gains could arise from unrelated factors such as the dataset extension or stronger features.
Authors: We appreciate the referee's point on the need for clearer specification of the alignment mechanism. CineMEC employs a multi-stage iterative process in which the captioning module first produces event role mention groups that are used to initialize and refine visual entity clusters in the grounding module; the resulting clusters then supply consistent entity identities to improve captioning coherence in subsequent stages. This creates the claimed synergy through shared multimodal representations and pseudo-label propagation across modules rather than through dedicated correspondence losses. We will revise the abstract and method sections to provide an expanded description of this iterative procedure and the implicit consistency enforcement it induces. revision: yes
-
Referee: [Evaluation] Evaluation section: improvements are shown on the extended VidSitu dataset, but without ablations that isolate the MEC coreference component (e.g., comparing against a version using only the dataset extension or standard backbones), it is impossible to confirm that the +2.5% CIDEr, +7% LEA, and +18% HOTA gains are driven by the proposed entity coreference rather than confounding changes.
Authors: We agree that isolating the contribution of the multimodal entity coreference is essential for attributing the observed gains. Our current experiments compare CineMEC against prior VidSitu methods on the extended dataset, but we acknowledge that this does not fully separate the MEC alignment from the dataset extension or backbone effects. In the revised manuscript we will add dedicated ablation studies, including (i) a baseline that uses the extended grounding annotations with standard captioning and grounding pipelines but without the MEC alignment stage, and (ii) variants that retain the original backbone while applying only the dataset extension, to demonstrate the specific impact of the coreference mechanism. revision: yes
Circularity Check
No significant circularity; method is a new multi-stage pipeline evaluated empirically on extended dataset
full rationale
The paper introduces CineMEC as a multi-stage training pipeline that exploits synergy between captioning and grounding modules to align text role mentions with visual entity clusters, without explicit grounding supervision. Reported gains (+2.5% CIDEr, +7% LEA, +18% HOTA) are presented as empirical outcomes on the extended VidSitu dataset with added grounding annotations. No equations, fitted parameters renamed as predictions, or self-citation chains that reduce the central claim to its own inputs are evident in the provided text. The derivation chain consists of a posited hypothesis about entity consistency, followed by a proposed architecture and experimental validation, which remains self-contained against external benchmarks rather than tautological.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Entities in a video maintain a single consistent identity despite changes in appearance, camera angle, or occlusion.
- domain assumption Improving visual grounding and text captioning are mutually reinforcing tasks.
invented entities (1)
-
CineMEC pipeline
no independent evidence
Reference graph
Works this paper leans on
-
[1]
https : / / github
CV AT Annotation Tool. https : / / github . com / openvinotoolkit/cvat. 3
-
[2]
One Token to Seg Them All: Language Instructed Reasoning Segmentation in Videos
Zechen Bai, Tong He, Haiyang Mei, Pichao Wang, Ziteng Gao, Joya Chen, Zheng Zhang, and Mike Zheng Shou. One Token to Seg Them All: Language Instructed Reasoning Segmentation in Videos. InAdvances in Neural Information Processing Systems (NeurIPS), 2024. 3
2024
-
[3]
Frozen in Time: A Joint Video and Image Encoder for End- to-End Retrieval
Max Bain, Arsha Nagrani, Gül Varol, and Andrew Zisserman. Frozen in Time: A Joint Video and Image Encoder for End- to-End Retrieval. InInternational Conference on Computer Vision (ICCV), 2021. 2
2021
-
[4]
XMem++: Production-Level Video Segmentation from Few Annotated Frames
Maksym Bekuzarov, Ariana Bermudez, Joon-Young Lee, and Hao Li. XMem++: Production-Level Video Segmentation from Few Annotated Frames. InInternational Conference on Computer Vision (ICCV), 2023. 2
2023
-
[5]
Corefer- ence Resolution through a Seq2Seq Transition-Based System
Bernd Bohnet, Chris Alberti, and Michael Collins. Corefer- ence Resolution through a Seq2Seq Transition-Based System. Transactions of the Association of Computational Linguistics (TACL), 11:212–226, 2023. 3
2023
-
[6]
Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset
Joao Carreira and Andrew Zisserman. Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. InCon- ference on Computer Vision and Pattern Recognition (CVPR),
-
[7]
Joint Multimedia Event Extraction from Video and Article
Brian Chen, Xudong Lin, Christopher Thomas, Manling Li, Shoya Yoshida, Lovish Chum, Heng Ji, and Shih-Fu Chang. Joint Multimedia Event Extraction from Video and Article. InFindings of the Association for Computational Linguistics (ACL), 2021. 2
2021
-
[8]
Shikra: Unleashing Multimodal LLM's Referential Dialogue Magic
Keqin Chen, Zhao Zhang, Weili Zeng, Richong Zhang, Feng Zhu, and Rui Zhao. Shikra: Unleashing Multi- modal LLM’s Referential Dialogue Magic.arXiv preprint arXiv:2306.15195, 2023. 3
work page internal anchor Pith review arXiv 2023
-
[9]
ShareGPT4Video: Improving Video Understand- ing and Generation with Better Captions
Lin Chen, Xilin Wei, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Zhenyu Tang, Li Yuan, et al. ShareGPT4Video: Improving Video Understand- ing and Generation with Better Captions. InAdvances in Neural Information Processing Systems (NeurIPS), 2024. 2
2024
-
[10]
V AST: A Vision-Audio- Subtitle-Text Omni-Modality Foundation Model and Dataset
Sihan Chen, Handong Li, Qunbo Wang, Zijia Zhao, Mingzhen Sun, Xinxin Zhu, and Jing Liu. V AST: A Vision-Audio- Subtitle-Text Omni-Modality Foundation Model and Dataset. InAdvances in Neural Information Processing Systems (NeurIPS), 2023. 2
2023
-
[11]
XMem: Long- Term Video Object Segmentation with an Atkinson-Shiffrin Memory Model
Ho Kei Cheng and Alexander G Schwing. XMem: Long- Term Video Object Segmentation with an Atkinson-Shiffrin Memory Model. InEuropean Conference on Computer Vision (ECCV), 2022. 2
2022
-
[12]
Segment and Track Anything.arXiv preprint arXiv:2305.06558, 2023
Yangming Cheng, Liulei Li, Yuanyou Xu, Xiaodi Li, Zongxin Yang, Wenguan Wang, and Yi Yang. Segment and Track Anything.arXiv preprint arXiv:2305.06558, 2023. 2
-
[13]
Zero-Shot Video Question Answering with Procedural Programs
Rohan Choudhury, Koichiro Niinuma, Kris M Kitani, and László A Jeni. Zero-Shot Video Question Answering with Procedural Programs. InECCV, 2024. 2
2024
-
[14]
Word-Level Coreference Resolu- tion
Vladimir Dobrovolskii. Word-Level Coreference Resolu- tion. InEmpirical Methods in Natural Language Processing (EMNLP), 2021. 3
2021
-
[15]
DAPS: Deep Action Proposals for Action Understanding
Victor Escorcia, Fabian Caba Heilbron, Juan Carlos Niebles, and Bernard Ghanem. DAPS: Deep Action Proposals for Action Understanding. InEuropean Conference on Computer Vision (ECCV), 2016. 2
2016
-
[16]
SlowFast Networks for Video Recognition
Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, and Kaiming He. SlowFast Networks for Video Recognition. In International Conference on Computer Vision (ICCV), 2019. 2, 5, 6
2019
-
[17]
Video Action Transformer Network
Rohit Girdhar, Joao Carreira, Carl Doersch, and Andrew Zis- serman. Video Action Transformer Network. InConference on Computer Vision and Pattern Recognition (CVPR), 2019. 2
2019
-
[18]
Semi-Supervised Multimodal Coreference Resolution in Im- age Narrations
Arushi Goel, Basura Fernando, Frank Keller, and Hakan Bilen. Semi-Supervised Multimodal Coreference Resolution in Im- age Narrations. InEmpirical Methods in Natural Language Processing (EMNLP), 2023. 2, 3
2023
-
[19]
Who Are You Referring To? Coreference Resolution in Image Narrations
Arushi Goel, Basura Fernando, Frank Keller, and Hakan Bilen. Who Are You Referring To? Coreference Resolution in Image Narrations. InInternational Conference on Computer Vision (ICCV), 2023. 2, 3
2023
-
[20]
AGQA: A Benchmark for Compositional Spatio-Temporal Reasoning
Madeleine Grunde-McLaughlin, Ranjay Krishna, and Ma- neesh Agrawala. AGQA: A Benchmark for Compositional Spatio-Temporal Reasoning. InConference on Computer Vision and Pattern Recognition (CVPR), 2021. 2
2021
-
[21]
Fast Temporal Activity Proposals for Efficient De- tection of Human Actions in Untrimmed Videos
Fabian Caba Heilbron, Juan Carlos Niebles, and Bernard Ghanem. Fast Temporal Activity Proposals for Efficient De- tection of Human Actions in Untrimmed Videos. InConfer- ence on Computer Vision and Pattern Recognition (CVPR),
-
[22]
VTIMELLM: Empower LLM to Grasp Video Mo- mentsVideo Action Transformer Network
Bin Huang, Xin Wang, Hong Chen, Zihan Song, and Wenwu Zhu. VTIMELLM: Empower LLM to Grasp Video Mo- mentsVideo Action Transformer Network. InConference on Computer Vision and Pattern Recognition (CVPR), 2024. 2
2024
-
[23]
Action Genome: Actions as Compositions of Spatio- Temporal Scene Graphs
Jingwei Ji, Ranjay Krishna, Li Fei-Fei, and Juan Carlos Niebles. Action Genome: Actions as Compositions of Spatio- Temporal Scene Graphs. InConference on Computer Vision and Pattern Recognition (CVPR), 2020. 2
2020
-
[24]
ReferItGame: Referring to Objects in Pho- tographs of Natural Scenes
Sahar Kazemzadeh, Vicente Ordonez, Mark Matten, and Tamara Berg. ReferItGame: Referring to Objects in Pho- tographs of Natural Scenes. InEmpirical Methods in Natural Language Processing (EMNLP), 2014. 2
2014
-
[25]
Grounded Video Situation Recognition
Zeeshan Khan, CV Jawahar, and Makarand Tapaswi. Grounded Video Situation Recognition. InAdvances in Neu- ral Information Processing Systems (NeurIPS), 2022. 1, 3, 4, 5, 6, 7, 2
2022
-
[26]
Kingma and Jimmy Ba
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. InInternational Conference on Learning Representations (ICLR), 2015. 6
2015
-
[27]
Visual Genome: Connecting Language and Vision Using Crowdsourced Dense Image Annotations.International Journal of Computer Vision (IJCV), 123(1):32–73, 2017
Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalan- tidis, Li-Jia Li, David A Shamma, et al. Visual Genome: Connecting Language and Vision Using Crowdsourced Dense Image Annotations.International Journal of Computer Vision (IJCV), 123(1):32–73, 2017. 2
2017
-
[28]
SRTube: Video-Language Pre-Training with Action-Centric Video Tube Features and Semantic Role Labeling
Ju-Hee Lee and Je-Won Kang. SRTube: Video-Language Pre-Training with Action-Centric Video Tube Features and Semantic Role Labeling. InConference on Computer Vision and Pattern Recognition (CVPR), 2024. 3
2024
-
[29]
TVQA: Localized, Compositional Video Question Answering
Jie Lei, Licheng Yu, Mohit Bansal, and Tamara Berg. TVQA: Localized, Compositional Video Question Answering. InEm- pirical Methods in Natural Language Processing (EMNLP),
-
[30]
BLIP- 2: Bootstrapping Language-Image Pre-Training with Frozen Image Encoders and Large Language Models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. BLIP- 2: Bootstrapping Language-Image Pre-Training with Frozen Image Encoders and Large Language Models. InInterna- tional Conference on Machine Learning (ICML), 2023. 6
2023
-
[31]
VILA: On Pre-training for Visual Language Models
Ji Lin, Hongxu Yin, Wei Ping, Pavlo Molchanov, Mohammad Shoeybi, and Song Han. VILA: On Pre-training for Visual Language Models. InConference on Computer Vision and Pattern Recognition (CVPR), 2024. 7
2024
-
[32]
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection. In European Conference on Computer Vision (ECCV), 2024. 2
2024
-
[33]
HOTA: A Higher Order Metric for Evaluating Multi-Object Tracking
Jonathon Luiten, Aljosa Osep, Patrick Dendorfer, Philip Torr, Andreas Geiger, Laura Leal-Taixé, and Bastian Leibe. HOTA: A Higher Order Metric for Evaluating Multi-Object Tracking. International Journal of Computer Vision (IJCV), 129(2):548– 578, 2021. 6, 1
2021
-
[34]
MoMA: Multi-Object Multi-Actor Activity Pars- ing
Zelun Luo, Wanze Xie, Siddharth Kapoor, Yiyun Liang, Michael Cooper, Juan Carlos Niebles, Ehsan Adeli, and Fei- Fei Li. MoMA: Multi-Object Multi-Actor Activity Pars- ing. InAdvances in Neural Information Processing Systems (NeurIPS), 2021. 2
2021
-
[35]
Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models
Muhammad Maaz, Hanoona Abdul Rasheed, Salman Khan, and Fahad Shahbaz Khan. Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models. InAssociation of Computational Linguistics (ACL), 2024. 3
2024
-
[36]
Major Entity Identification: A Generalizable Alternative to Coreference Resolution
Kawshik Manikantan, Shubham Toshniwal, Makarand Tapaswi, and Vineet Gandhi. Major Entity Identification: A Generalizable Alternative to Coreference Resolution. InEm- pirical Methods in Natural Language Processing (EMNLP),
-
[37]
arXiv preprint arXiv:2510.20579 (2025)
Jiahao Meng, Xiangtai Li, Haochen Wang, Yue Tan, Tao Zhang, Lingdong Kong, Yunhai Tong, Anran Wang, Zhiyang Teng, Yujing Wang, and Zhuochen Wang. Open-o3 Video: Grounded Video Reasoning with Explicit Spatio-Temporal Evidence.arXiv preprint arXiv:2510.20579, 2025. 2, 3, 8, 1
-
[38]
HowTo100M: Learning a Text-Video Embedding by Watching Hundred Million Narrated Video Clips
Antoine Miech, Dimitri Zhukov, Jean-Baptiste Alayrac, Makarand Tapaswi, Ivan Laptev, and Josef Sivic. HowTo100M: Learning a Text-Video Embedding by Watching Hundred Million Narrated Video Clips. In International Conference on Computer Vision (ICCV), 2019. 2
2019
-
[39]
Which Coref- erence Evaluation Metric Do You Trust? A Proposal for a Link-Based Entity Aware Metric
Nafise Sadat Moosavi and Michael Strube. Which Coref- erence Evaluation Metric Do You Trust? A Proposal for a Link-Based Entity Aware Metric. InAssociation of Computa- tional Linguistics (ACL), 2016. 2, 6, 1
2016
-
[40]
VideoGLAMM: A Large Multimodal Model for Pixel-Level Visual Grounding in Videos
Shehan Munasinghe, Hanan Gani, Wenqi Zhu, Jiale Cao, Eric Xing, Fahad Shahbaz Khan, and Salman Khan. VideoGLAMM: A Large Multimodal Model for Pixel-Level Visual Grounding in Videos. InConference on Computer Vision and Pattern Recognition (CVPR), 2025. 2, 3
2025
-
[41]
PG-Video-LLaV A: Pixel Grounding Large Video-Language Models.ArXiv 2311.13435, 2023
Shehan Munasinghe, Rusiru Thushara, Muhammad Maaz, Hanoona Abdul Rasheed, Salman Khan, Mubarak Shah, and Fahad Khan. PG-Video-LLaV A: Pixel Grounding Large Video-Language Models.ArXiv 2311.13435, 2023. 2, 3
-
[42]
HIG: Hierarchical Interlacement Graph Approach to Scene Graph Generation in Video Understanding
Trong-Thuan Nguyen, Pha Nguyen, and Khoa Luu. HIG: Hierarchical Interlacement Graph Approach to Scene Graph Generation in Video Understanding. InConference on Com- puter Vision and Pattern Recognition (CVPR), 2024. 2
2024
-
[43]
Identity- Aware Multi-Sentence Video Description
Jae Sung Park, Trevor Darrell, and Anna Rohrbach. Identity- Aware Multi-Sentence Video Description. InEuropean Con- ference on Computer Vision (ECCV), 2020. 3
2020
-
[44]
Kosmos-2: Grounding Multimodal Large Language Models to the World
Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, and Furu Wei. Kosmos-2: Grounding Multimodal Large Language Models to the World. InInterna- tional Conference on Learning Representations (ICLR), 2024. 3
2024
-
[45]
Qwen2.5-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution.Blog post: https://qwenlm.github.io/blog/qwen2.5-vl/, 2025
Qwen Team. Qwen2.5-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution.Blog post: https://qwenlm.github.io/blog/qwen2.5-vl/, 2025. 3
2025
-
[46]
MICAP: A Unified Model for Identity- Aware Movie Descriptions
Haran Raajesh, Naveen Reddy Desanur, Zeeshan Khan, and Makarand Tapaswi. MICAP: A Unified Model for Identity- Aware Movie Descriptions. InConference on Computer Vi- sion and Pattern Recognition (CVPR), 2024. 3, 4
2024
-
[47]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment Any- thing in Images and Videos.arXiv preprint arXiv:2408.00714,
work page internal anchor Pith review arXiv
-
[48]
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. InAdvances in Neural Informa- tion Processing Systems (NeurIPS), 2015. 6
2015
-
[49]
Movie Description.International Journal of Computer Vision (IJCV), 123:94–120, 2017
Anna Rohrbach, Atousa Torabi, Marcus Rohrbach, Niket Tandon, Christopher Pal, Hugo Larochelle, Aaron Courville, and Bernt Schiele. Movie Description.International Journal of Computer Vision (IJCV), 123:94–120, 2017. 2, 3
2017
-
[50]
Video Object Grounding using Semantic Roles in Language Description
Arka Sadhu, Kan Chen, and Ram Nevatia. Video Object Grounding using Semantic Roles in Language Description. InConference on Computer Vision and Pattern Recognition (CVPR), 2020. 2
2020
-
[51]
Visual Semantic Role Labeling for Video Understanding
Arka Sadhu, Tanmay Gupta, Mark Yatskar, Ram Nevatia, and Aniruddha Kembhavi. Visual Semantic Role Labeling for Video Understanding. InConference on Computer Vision and Pattern Recognition (CVPR), 2021. 1, 2, 3, 6, 7
2021
-
[52]
VELOC- ITI: Can Video-Language Models Bind Semantic Concepts through Time? InConference on Computer Vision and Pat- tern Recognition (CVPR), 2025
Darshana Saravanan, Darshan Singh, Varun Gupta, Zeeshan Khan, Vineet Gandhi, and Makarand Tapaswi. VELOC- ITI: Can Video-Language Models Bind Semantic Concepts through Time? InConference on Computer Vision and Pat- tern Recognition (CVPR), 2025. 1
2025
-
[53]
Effi- cient Parameter-Free Clustering Using First Neighbor Rela- tions
Saquib Sarfraz, Vivek Sharma, and Rainer Stiefelhagen. Effi- cient Parameter-Free Clustering Using First Neighbor Rela- tions. InConference on Computer Vision and Pattern Recog- nition (CVPR), 2019. 4, 6, 2
2019
-
[54]
End-to-End Generative Pretraining for Multimodal Video Captioning
Paul Hongsuck Seo, Arsha Nagrani, Anurag Arnab, and Cordelia Schmid. End-to-End Generative Pretraining for Multimodal Video Captioning. InConference on Computer Vision and Pattern Recognition (CVPR), 2022. 2
2022
-
[55]
Temporal Action Localization in Untrimmed Videos via Multi-Stage CNNs
Zheng Shou, Dongang Wang, and Shih-Fu Chang. Temporal Action Localization in Untrimmed Videos via Multi-Stage CNNs. InConference on Computer Vision and Pattern Recog- nition (CVPR), 2016. 2
2016
-
[56]
Actor-Centric Relation Network
Chen Sun, Abhinav Shrivastava, Carl V ondrick, Kevin Mur- phy, Rahul Sukthankar, and Cordelia Schmid. Actor-Centric Relation Network. InEuropean Conference on Computer Vision (ECCV), 2018. 2
2018
-
[57]
Unbiased Scene Graph Generation from Biased Training
Kaihua Tang, Yulei Niu, Jianqiang Huang, Jiaxin Shi, and 10 Hanwang Zhang. Unbiased Scene Graph Generation from Biased Training. InConference on Computer Vision and Pattern Recognition (CVPR), 2020. 6
2020
-
[58]
Long Term Spatio-Temporal Modeling for Action Detection.Com- puter Vision and Image Understanding (CVIU), 210, 2021
Makarand Tapaswi, Vijay Kumar, and Ivan Laptev. Long Term Spatio-Temporal Modeling for Action Detection.Com- puter Vision and Image Understanding (CVIU), 210, 2021. 2
2021
-
[59]
MovieQA: Un- derstanding Stories in Movies through Question-Answering
Makarand Tapaswi, Yukun Zhu, Rainer Stiefelhagen, Antonio Torralba, Raquel Urtasun, , and Sanja Fidler. MovieQA: Un- derstanding Stories in Movies through Question-Answering. InConference on Computer Vision and Pattern Recognition (CVPR), 2016. 2
2016
-
[60]
On Generalization in Coref- erence Resolution
Shubham Toshniwal, Patrick Xia, Sam Wiseman, Karen Livescu, and Kevin Gimpel. On Generalization in Coref- erence Resolution. InWorkshop on Computational Models of Reference, Anaphora and Coreference, 2021. 3
2021
-
[61]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muham- mad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, et al. SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localiza- tion, and Dense Features.arXiv preprint arXiv:2502.14786,
work page internal anchor Pith review arXiv
-
[62]
Lawrence Zitnick, and Devi Parikh
Ramakrishna Vedantam, C. Lawrence Zitnick, and Devi Parikh. CIDEr: Consensus-Based Image Description Evalua- tion. InConference on Computer Vision and Pattern Recogni- tion (CVPR), 2015. 6
2015
-
[63]
Effec- tively Leveraging CLIP for Generating Situational Summaries of Images and Videos.IJCV, 2024
Dhruv Verma, Debaditya Roy, and Basura Fernando. Effec- tively Leveraging CLIP for Generating Situational Summaries of Images and Videos.IJCV, 2024. 3, 6, 7
2024
-
[64]
MovieGraphs: Towards Understanding Human-Centric Situations from Videos
Paul Vicol, Makarand Tapaswi, Lluis Castrejon, and Sanja Fi- dler. MovieGraphs: Towards Understanding Human-Centric Situations from Videos. InConference on Computer Vision and Pattern Recognition (CVPR), 2018. 2
2018
-
[65]
Yoloe: Real-time seeing anything.arXiv preprint arXiv:2503.07465, 2025
Ao Wang, Lihao Liu, Hui Chen, Zijia Lin, Jungong Han, and Guiguang Ding. YOLOE: Real-Time Seeing Anything.arXiv preprint arXiv:2503.07465, 2025. 5, 6, 2
-
[66]
Temporal Segment Networks: Towards Good Practices for Deep Action Recog- nition
Limin Wang, Yuanjun Xiong, Zhe Wang, Yu Qiao, Dahua Lin, Xiaoou Tang, and Luc Van Gool. Temporal Segment Networks: Towards Good Practices for Deep Action Recog- nition. InEuropean Conference on Computer Vision (ECCV),
-
[67]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Jun- yang Lin. Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution.arXiv preprint arXiv:2409.12191, 2024. 7
work page internal anchor Pith review arXiv 2024
-
[68]
Demonstration Meets Typed Events: Type Specific Video Semantic Role Labeling via Multimodal Prompting and Retrieval
Hanxiao Wei, Bin Wu, Chunjia Wang, Guangyao Su, and Tao Zhou. Demonstration Meets Typed Events: Type Specific Video Semantic Role Labeling via Multimodal Prompting and Retrieval. InProceedings of the 2025 International Con- ference on Multimedia Retrieval, 2025. 3, 6, 7, 2
2025
-
[69]
Long-Term Feature Banks for Detailed Video Understanding
Chao-Yuan Wu, Christoph Feichtenhofer, Haoqi Fan, Kaim- ing He, Philipp Krahenbuhl, and Ross Girshick. Long-Term Feature Banks for Detailed Video Understanding. InConfer- ence on Computer Vision and Pattern Recognition (CVPR),
-
[70]
MSR-VTT: A Large Video Description Dataset for Bridging Video and Language
Jun Xu, Tao Mei, Ting Yao, and Yong Rui. MSR-VTT: A Large Video Description Dataset for Bridging Video and Language. InConference on Computer Vision and Pattern Recognition (CVPR), 2016. 2
2016
-
[71]
TubeDETR: Spatio-Temporal Video Grounding with Transformers
Antoine Yang, Antoine Miech, Josef Sivic, Ivan Laptev, and Cordelia Schmid. TubeDETR: Spatio-Temporal Video Grounding with Transformers. InConference on Computer Vision and Pattern Recognition (CVPR), 2022. 2
2022
-
[72]
Vid2Seq: Large-Scale Pretraining of a Visual Language Model for Dense Video Captioning
Antoine Yang, Arsha Nagrani, Paul Hongsuck Seo, An- toine Miech, Jordi Pont-Tuset, Ivan Laptev, Josef Sivic, and Cordelia Schmid. Vid2Seq: Large-Scale Pretraining of a Visual Language Model for Dense Video Captioning. InCon- ference on Computer Vision and Pattern Recognition (CVPR),
-
[73]
Video Event Extraction via Tracking Vi- sual States of Arguments
Guang Yang, Manling Li, Jiajie Zhang, Xudong Lin, Heng Ji, and Shih-Fu Chang. Video Event Extraction via Tracking Vi- sual States of Arguments. InAssociation for the Advancement of Artificial Intelligence (AAAI), 2023. 3, 6, 2
2023
-
[74]
Track anything: Segment anything meets videos.arXiv preprint arXiv:2304.11968, 2023
Jinyu Yang, Mingqi Gao, Zhe Li, Shang Gao, Fangjing Wang, and Feng Zheng. Track Anything: Segment Anything Meets Videos.arXiv preprint arXiv:2304.11968, 2023. 2
-
[75]
Panoptic Video Scene Graph Generation
Jingkang Yang, Wenxuan Peng, Xiangtai Li, Zujin Guo, Liangyu Chen, Bo Li, Zheng Ma, Kaiyang Zhou, Wayne Zhang, Chen Change Loy, et al. Panoptic Video Scene Graph Generation. InConference on Computer Vision and Pattern Recognition (CVPR), 2023. 2
2023
-
[76]
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui He, Qi-An Chen, Huarong Zhou, Zhensheng Zou, Haoye Zhang, Shengding Hu, Zhi Zheng, Jie Zhou, Jie Cai, Xu Han, Guoyang Zeng, Dahai Li, Zhiyuan Liu, and Maosong Sun. MiniCPM-V: A GPT-4V Level MLLM on Your Phone.arXiv preprint arXiv:2408.01800, 2024. 7
work page internal anchor Pith review arXiv 2024
-
[77]
ActivityNet-QA: A Dataset for Understanding Complex Web Videos via Question Answering
Zhou Yu, Dejing Xu, Jun Yu, Ting Yu, Zhou Zhao, Yueting Zhuang, and Dacheng Tao. ActivityNet-QA: A Dataset for Understanding Complex Web Videos via Question Answering. InAssociation for the Advancement of Artificial Intelligence (AAAI), 2019. 2
2019
-
[78]
VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding
Boqiang Zhang, Kehan Li, Zesen Cheng, Zhiqiang Hu, Yuqian Yuan, Guanzheng Chen, et al. VideoLLaMA 3: Fron- tier Multimodal Foundation Models for Image and Video Understanding.arXiv preprint arXiv:2501.13106, 2025. 3
work page internal anchor Pith review arXiv 2025
-
[79]
LLaV A-Grounding: Grounded Visual Chat with Large Multimodal Models
Hao Zhang, Hongyang Li, Feng Li, Tianhe Ren, Xueyan Zou, Shilong Liu, Shijia Huang, Jianfeng Gao, Leizhang, Chun- yuan Li, et al. LLaV A-Grounding: Grounded Visual Chat with Large Multimodal Models. InEuropean Conference on Computer Vision (ECCV), 2024. 3
2024
-
[80]
Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding
Hang Zhang, Xin Li, and Lidong Bing. Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding. InEMNLP Demo track, 2023. 3
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.