Recognition: unknown
A Multiplication-Free Spike-Time Learning Algorithm and its Efficient FPGA Implementation for On-Chip SNN Training
Pith reviewed 2026-05-08 06:58 UTC · model grok-4.3
The pith
A multiplication-free spike-time learning rule enables on-chip supervised training of spiking neural networks on FPGA hardware.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
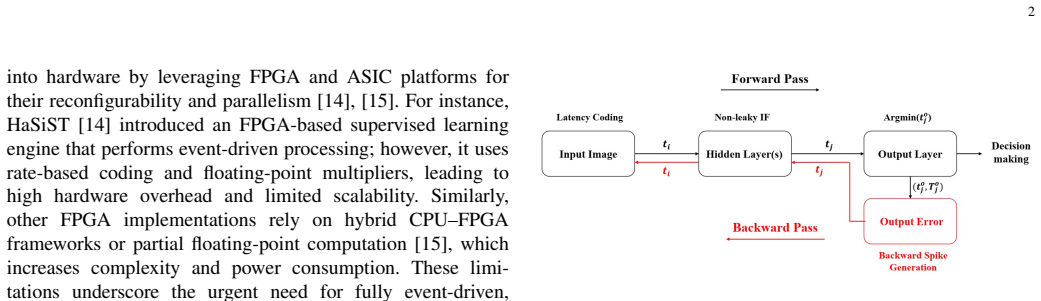
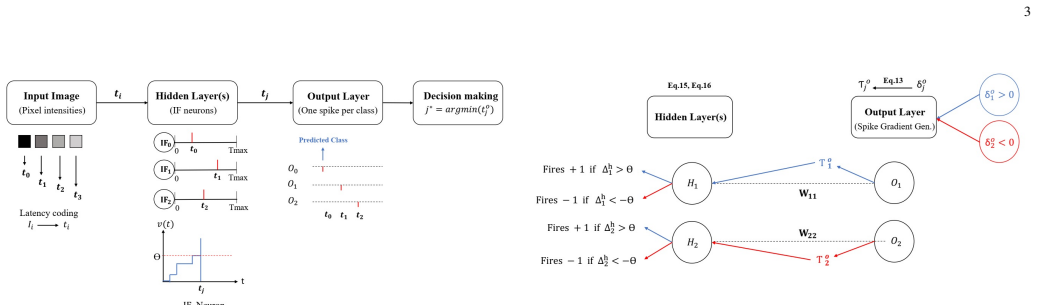
The central claim is that a spike-time-based supervised learning rule performs weight updates using only integer additions and comparisons triggered by spikes, eliminating multiplications and gradient buffers entirely. This rule maps directly onto a fully digital, event-driven hardware pipeline that the authors implement on FPGA, achieving high throughput with minimal resources while delivering competitive classification accuracy on standard image datasets.
What carries the argument
The multiplication-free spike-time learning rule that updates synaptic weights based solely on pre- and post-synaptic spike timings using simple integer arithmetic in an event-driven flow.
If this is right
- The training pipeline runs entirely in digital logic and event-driven mode without floating-point units or gradient memory.
- The FPGA design reaches high speed with low resource usage on a Xilinx Artix-7 device.
- Software simulations confirm 96.5 percent accuracy on MNIST and 84.8 percent on Fashion-MNIST.
- The approach supports scalable, real-time on-chip learning suitable for edge environments.
Where Pith is reading between the lines
- The same integer-only rule could be ported to custom neuromorphic ASICs for further power reduction.
- Pairing it with local unsupervised spike-timing rules might enable fully online, label-free learning on hardware.
- Absence of stored gradients removes a memory bottleneck that grows with network size in conventional methods.
- The design points toward training pipelines that stay entirely within the spike domain from sensor to output.
Load-bearing premise
A spike-time learning rule that avoids all multiplications and gradient storage can still achieve competitive accuracy on image classification tasks when implemented in digital hardware.
What would settle it
If direct FPGA experiments show MNIST accuracy falling below 90 percent or resource consumption exceeding that of standard SNN training circuits on the same device, the claim of practical efficiency would be disproved.
Figures



read the original abstract
Spiking Neural Networks (SNNs) offer a biologically inspired foundation for low-power, event-driven intelligence, yet their direct on-chip supervised training remains a key hardware challenge. This paper presents a multiplication-free, spike-time-based learning algorithm specifically designed for efficient FPGA realization. The proposed approach eliminates floating-point arithmetic and explicit gradient storage, enabling a fully event-driven, digital training pipeline. Implemented on a Xilinx Artix-7 FPGA, the architecture achieves high operating speed and minimal resource usage while maintaining competitive accuracy. These results demonstrate that the learning algorithm effectively maps onto reconfigurable hardware, achieving both computational and energy efficiency. Software simulations further validate scalability, with 96.5\% and 84.8\% accuracy on MNIST and Fashion-MNIST. With its spike-driven and multiplier-free operation, the proposed framework delivers a practical and scalable hardware solution for real-time, on-chip SNN learning in edge environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a multiplication-free spike-time learning algorithm for SNNs tailored for FPGA implementation. It eliminates floating-point operations and gradient storage for an event-driven training pipeline. Software simulations show 96.5% accuracy on MNIST and 84.8% on Fashion-MNIST. The Xilinx Artix-7 FPGA implementation is claimed to achieve high speed, low resource usage, and competitive accuracy.
Significance. If validated, the work could advance on-chip SNN training for low-power edge applications by providing a hardware-efficient alternative to traditional backpropagation. The multiplier-free design addresses key FPGA challenges, but the absence of on-device accuracy measurements weakens the central claim of maintaining competitive performance in hardware.
major comments (2)
- [Abstract] Abstract: The statement that the Artix-7 implementation 'maintains competitive accuracy' is unsupported by any reported classification accuracy, confusion matrices, or learning curves measured on the FPGA fabric; only speed and resource metrics are provided, leaving effects of fixed-point quantization, event jitter, and weight-update rounding unverified.
- [Results] Results (software simulations): Accuracies of 96.5% (MNIST) and 84.8% (Fashion-MNIST) are presented without error bars, baseline comparisons, ablation studies on the spike-time rule, or details on training procedure, undermining assessment of whether the multiplication-free rule delivers competitive supervised performance.
minor comments (1)
- [Abstract] Abstract: Explicitly state that reported accuracies are from software simulations only, to prevent misinterpretation of the hardware claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and have revised the manuscript to strengthen the presentation of our results and claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The statement that the Artix-7 implementation 'maintains competitive accuracy' is unsupported by any reported classification accuracy, confusion matrices, or learning curves measured on the FPGA fabric; only speed and resource metrics are provided, leaving effects of fixed-point quantization, event jitter, and weight-update rounding unverified.
Authors: We agree that the abstract overstates the hardware claim. Accuracy results (96.5% MNIST, 84.8% Fashion-MNIST) come exclusively from software simulations of the algorithm; no on-FPGA classification accuracy, confusion matrices, or learning curves were measured. The FPGA experiments report only resource utilization and throughput. We will revise the abstract to remove the phrase 'while maintaining competitive accuracy' and instead state that the implementation achieves high speed and low resource usage for the multiplication-free algorithm whose accuracy is validated in software. The design uses integer arithmetic and event-driven updates to reduce quantization sensitivity, but we acknowledge that direct hardware accuracy verification would be needed to fully address effects such as jitter and rounding. revision: yes
-
Referee: [Results] Results (software simulations): Accuracies of 96.5% (MNIST) and 84.8% (Fashion-MNIST) are presented without error bars, baseline comparisons, ablation studies on the spike-time rule, or details on training procedure, undermining assessment of whether the multiplication-free rule delivers competitive supervised performance.
Authors: We will expand the results section to include error bars from multiple runs, baseline comparisons against standard backpropagation and other spike-timing-dependent rules, and additional training-procedure details (network topology, hyperparameters, and simulation settings). Key ablation results on the spike-time components will also be added where space permits. These revisions will better substantiate the competitiveness of the multiplication-free approach. revision: partial
- Direct on-device accuracy measurements on the Artix-7 FPGA were not performed; providing quantitative FPGA accuracy figures, confusion matrices, or learning curves would require new hardware experiments that are outside the scope of the current manuscript.
Circularity Check
No circularity: new algorithm proposed without self-referential fitting or derivation reduction
full rationale
The manuscript introduces a novel multiplication-free spike-time learning rule for SNNs and maps it to an FPGA pipeline. No equations, parameter-fitting procedures, or uniqueness theorems are presented that reduce by construction to the paper's own inputs or prior self-citations. Software-reported accuracies (MNIST/Fashion-MNIST) and hardware resource claims stand as independent empirical results rather than tautological re-derivations. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Spikeatconv: an in- tegrated spiking-convolutional attention architecture for energy-efficient neuromorphic vision processing,
W. Liao, F. Chen, C. Liu, W. Wang, and H. Liu, “Spikeatconv: an in- tegrated spiking-convolutional attention architecture for energy-efficient neuromorphic vision processing,”Frontiers in Neuroscience, vol. 19, 2025
2025
-
[2]
Human activity recognition: suitability of a neuromorphic approach for on-edge aiot applications,
V . Fra, E. Forno, R. Pignari, T. Stewart, E. Macii, and G. Urgese, “Human activity recognition: suitability of a neuromorphic approach for on-edge aiot applications,”neuromorphic Computing and Engineering, vol. 2, p. 014006, 2022
2022
-
[3]
Sparse-firing regularization methods for spiking neural networks with time-to-first- spike coding,
Y . Sakemi, K. Yamamoto, T. Hosomi, and K. Aihara, “Sparse-firing regularization methods for spiking neural networks with time-to-first- spike coding,” 2023
2023
-
[4]
Temporal backpropagation for spiking neural networks with one spike per neuron,
S. R. Kheradpisheh and T. Masquelier, “Temporal backpropagation for spiking neural networks with one spike per neuron,” International Journal of Neural Systems, vol. 30, no. 06, p. 2050027, 2020, pMID: 32466691. [Online]. Available: https://doi.org/10.1142/S0129065720500276
-
[5]
BS4NN: Binarized Spiking Neural Networks with Temporal Coding and Learning,
S. R. Kheradpisheh, M. Mirsadeghi, and T. Masquelier, “BS4NN: Binarized Spiking Neural Networks with Temporal Coding and Learning,”Neural Processing Letters, vol. 54, no. 2, pp. 1255–1273,
-
[6]
Available: https://doi.org/10.1007/s11063-021-10680-x
[Online]. Available: https://doi.org/10.1007/s11063-021-10680-x
-
[7]
Stidi-bp: Spike time displacement based error backpropagation in multilayer spiking neural networks,
M. Mirsadeghi, M. Shalchian, S. R. Kheradpisheh, and T. Masquelier, “Stidi-bp: Spike time displacement based error backpropagation in multilayer spiking neural networks,”Neurocomputing, vol. 427, pp. 131–140, 2021. [Online]. Available: https://www.sciencedirect.com/ science/article/pii/S0925231220318452
2021
-
[8]
Spike time displacement-based error backpropagation in convolutional spiking neural networks,
——, “Spike time displacement-based error backpropagation in convolutional spiking neural networks,”Neural Computing and Applications, vol. 35, no. 21, pp. 15 891–15 906, 2023. [Online]. Available: https://doi.org/10.1007/s00521-023-08567-0
-
[9]
High-performance deep spiking neural networks with 0.3 spikes per neuron,
A. Stanojevic, S. Wo ´zniak, G. Bellec, G. Cherubini, A. Pantazi, and W. Gerstner, “High-performance deep spiking neural networks with 0.3 spikes per neuron,”Nature Communications, vol. 15, no. 1, p. 6793, 8
-
[10]
Available: https://doi.org/10.1038/s41467-024-51110-5
[Online]. Available: https://doi.org/10.1038/s41467-024-51110-5
-
[11]
Toward large-scale spiking neural networks: A comprehensive survey and future directions,
Y . Hu, Q. Zheng, G. Li, H. Tang, and G. Pan, “Toward large-scale spiking neural networks: A comprehensive survey and future directions,”
-
[12]
Available: https://arxiv.org/abs/2409.02111
[Online]. Available: https://arxiv.org/abs/2409.02111
-
[13]
A million spiking-neuron integrated circuit with a scalable communication network and interface,
P. A. Merolla, J. V . Arthur, R. Alvarez-Icaza, A. S. Cassidy, J. Sawada, F. Akopyan, B. L. Jackson, N. Imam, C. Guo, Y . Nakamura, B. Brezzo, I. V o, S. K. Esser, R. Appuswamy, B. Taba, A. Amir, M. D. Flickner, W. P. Risk, R. Manohar, and D. S. Modha, “A million spiking-neuron integrated circuit with a scalable communication network and interface,” Scien...
2014
-
[14]
Programming spiking neural networks on intel’s loihi,
C.-K. Lin, A. Wild, G. N. Chinya, Y . Cao, M. Davies, D. J. Lott, V . Nagaraja, and H. Wang, “Programming spiking neural networks on intel’s loihi,”Computer, vol. 51, no. 3, pp. 52–61, 2018
2018
-
[15]
Spinnaker: A 1-w 18-core system- on-chip for massively-parallel neural network simulation,
E. Painkras, L. A. Plana, J. Garside, S. Temple, S. Davidson, J. Pepper, D. Clark, C. Patterson, and S. Furber, “Spinnaker: A 1-w 18-core system- on-chip for massively-parallel neural network simulation,”IEEE Journal of Solid-State Circuits, vol. 48, no. 8, pp. 1943–1953, 2013
1943
-
[16]
Dynap-se2: a scalable multi-core dynamic neuromor- phic asynchronous spiking neural network processor,
O. Richter, C. Wu, A. M. Whatley, G. K ¨ostinger, C. Nielsen, N. Qiao, and G. Indiveri, “Dynap-se2: a scalable multi-core dynamic neuromor- phic asynchronous spiking neural network processor,”Neuromorphic Computing and Engineering, vol. 4, no. 1, p. 014003, 1 2024, open access article
2024
-
[17]
A. Siddique, M. I. Vai, and S. H. Pun, “A low cost neuromorphic learning engine based on a high performance supervised SNN learning algorithm,”Scientific Reports, vol. 13, no. 1, p. 6280, Apr. 2023. [Online]. Available: https://doi.org/10.1038/s41598-023-32120-7
-
[18]
A low-cost and high-speed hardware implementation of spiking neural network,
G. Zhang, J. Wu, L. Wang, T. Wang, C. Liu, and C. Li, “A low-cost and high-speed hardware implementation of spiking neural network,” Neurocomputing, vol. 382, pp. 106–115, 2020
2020
-
[19]
Membrane- dependent neuromorphic learning rule for unsupervised spike pattern detection,
S. Sheik, S. Paul, C. Augustine, and G. Cauwenberghs, “Membrane- dependent neuromorphic learning rule for unsupervised spike pattern detection,” pp. 164–167, 2016
2016
-
[20]
hardware implementation of convolutional stdp for on-line visual feature learning,
A. Yousefzadeh, T. Masquelier, T. Serrano-Gotarredona, and B. Linares- Barranco, “hardware implementation of convolutional stdp for on-line visual feature learning,” pp. 1–4, 2017
2017
-
[21]
hardware software co-design for leveraging stdp in a memristive neuroprocessor,
N. Chakraborty, S. Ameli, H. Das, C. Schuman, and G. Rose, “hardware software co-design for leveraging stdp in a memristive neuroprocessor,” neuromorphic Computing and Engineering, vol. 4, p. 024010, 2024
2024
-
[22]
Texel: A neuromorphic processor with on-chip learning for beyond-cmos device integration,
H. Greatorex, O. Richter, M. Mastella, M. Cotteret, P. Klein, M. Fabre, A. Rubino, W. S. Gir ˜ao, J. Chen, M. Ziegler, L. B ´egon-Lours, G. Indiveri, and E. Chicca, “Texel: A neuromorphic processor with on-chip learning for beyond-cmos device integration,” 2024. [Online]. Available: https://arxiv.org/abs/2410.15854
-
[23]
synaptic normalisation for on-chip learning in analog cmos spiking neural networks,
M. Mastella, H. Greatorex, M. Cotteret, E. Janotte, W. Gir ˜ao, O. Richter, and E. Chicca, “synaptic normalisation for on-chip learning in analog cmos spiking neural networks,” pp. 1–4, 2023
2023
-
[24]
deep unsupervised learning using spike-timing- dependent plasticity,
S. Lu and A. Sengupta, “deep unsupervised learning using spike-timing- dependent plasticity,”neuromorphic Computing and Engineering, vol. 4, p. 024004, 2024
2024
-
[25]
Neuromorphic nearest neighbor search using intel’s pohoiki springs,
E. P. Frady, G. Orchard, D. Florey, N. Imam, R. Liu, J. Mishra, J. Tse, A. Wild, F. T. Sommer, and M. Davies, “Neuromorphic nearest neighbor search using intel’s pohoiki springs,” inProceedings of the Neuro- Inspired Computational Elements Workshop (NICE), 2020, pp. 1–10, presented at the Neuro-Inspired Computational Elements Workshop
2020
-
[26]
A biologically plausible supervised learning method for spiking neural networks using the symmetric stdp rule,
Y . Hao, X. Huang, M. Dong, and B. Xu, “A biologically plausible supervised learning method for spiking neural networks using the symmetric stdp rule,”Neural Networks, vol. 121, pp. 387–395, 2020
2020
-
[27]
Towards spike-based machine intelligence with neuromorphic computing,
K. Roy, A. Jaiswal, and P. Panda, “Towards spike-based machine intelligence with neuromorphic computing,”Nature, 2019
2019
-
[28]
A solution to the learning dilemma for recurrent networks of spiking neurons,
G. Bellec, F. Scherr, E. Hajek, D. Salaj, R. Legenstein, and W. Maass, “A solution to the learning dilemma for recurrent networks of spiking neurons,”Nature Communications, 2020
2020
-
[29]
Surrogate gradient learning in spiking neural networks,
E. O. Neftci, H. Mostafa, and F. Zenke, “Surrogate gradient learning in spiking neural networks,”IEEE Signal Processing Magazine, 2019
2019
-
[30]
The remarkable robustness of surrogate gradient learning for instilling complex function in spiking neural networks,
F. Zenke and T. P. V ogels, “The remarkable robustness of surrogate gradient learning for instilling complex function in spiking neural networks,”Neural Computation, 2021
2021
-
[31]
Spikeprop: backpropagation for networks of spiking neurons,
S. M. Boht ´e, J. N. Kok, and H. L. Poutr ´e, “Spikeprop: backpropagation for networks of spiking neurons,” inThe European Symposium on Artificial Neural Networks, 2000. [Online]. Available: https: //api.semanticscholar.org/CorpusID:14069916
2000
-
[32]
Supervised learning based on temporal coding in spiking neural networks,
H. Mostafa, “Supervised learning based on temporal coding in spiking neural networks,”IEEE Transactions on Neural Networks and Learning Systems, 2017
2017
-
[33]
Temporal- coded deep spiking neural network with easy training and robust perfor- mance,
S. Zhou, X. Li, Y . Chen, S. Chandrasekaran, and A. Sanyal, “Temporal- coded deep spiking neural network with easy training and robust perfor- mance,”Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, pp. 11 143–11 151, 05 2021
2021
-
[34]
Spatio-temporal backpropagation for training high-performance spiking neural networks,
Y . Wu, L. Deng, G. Li, J. Zhu, and L. Shi, “Spatio-temporal backpropagation for training high-performance spiking neural networks,” Frontiers in Neuroscience, vol. 12, p. 331, 2018. [Online]. Available: https://doi.org/10.3389/fnins.2018.00331
-
[35]
B. Yin, F. Corradi, and S. M. Boht ´e, “Accurate and efficient time- domain classification with adaptive spiking recurrent neural networks,” Nature Machine Intelligence, vol. 3, no. 10, pp. 905–913, 2021. [Online]. Available: https://doi.org/10.1038/s42256-021-00397-w
-
[36]
Long short-term memory and learning-to-learn in networks of spiking neurons,
G. Bellec, D. Salaj, A. Subramoney, R. Legenstein, and W. Maass, “Long short-term memory and learning-to-learn in networks of spiking neurons,” inAdvances in Neural Information Processing Systems, S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa- Bianchi, and R. Garnett, Eds., vol. 31. Curran Associates, Inc.,
-
[37]
Available: https://proceedings.neurips.cc/paper files/ paper/2018/file/c203d8a151612acf12457e4d67635a95-Paper.pdf
[Online]. Available: https://proceedings.neurips.cc/paper files/ paper/2018/file/c203d8a151612acf12457e4d67635a95-Paper.pdf
2018
-
[38]
Superspike: Supervised learning in multilayer spiking neural networks,
F. Zenke and S. Ganguli, “Superspike: Supervised learning in multilayer spiking neural networks,”Neural computation, vol. 30, no. 6, pp. 1514– 1541, 2018
2018
-
[39]
Online spatio-temporal learning in deep neural networks,
T. Bohnstingl, S. Wo ´zniak, A. Pantazi, and E. Eleftheriou, “Online spatio-temporal learning in deep neural networks,”IEEE Transactions on Neural Networks and Learning Systems, vol. 34, no. 11, pp. 8894– 8908, 2023
2023
-
[40]
Towards memory- and time-efficient backpropagation for training spiking neural networks,
Q. Meng, M. Xiao, S. Yan, Y . Wang, Z. Lin, and Z.-Q. Luo, “Towards memory- and time-efficient backpropagation for training spiking neural networks,” in2023 IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 6143–6153
2023
-
[41]
A low-cost high-speed neuromorphic hardware based on spiking neural network,
E. Z. Farsa, A. Ahmadi, M. A. Maleki, M. Gholami, and H. N. Rad, “A low-cost high-speed neuromorphic hardware based on spiking neural network,”IEEE Transactions on Circuits and Systems II: Express Briefs, vol. 66, no. 9, pp. 1582–1586, 2019
2019
-
[42]
Algorithm and hardware design of discrete-time spiking neural networks based on back propagation with binary activations,
S. Yin, S. K. Venkataramanaiah, G. K. Chen, R. Krishnamurthy, Y . Cao, C. Chakrabarti, and J.-s. Seo, “Algorithm and hardware design of discrete-time spiking neural networks based on back propagation with binary activations,” in2017 IEEE Biomedical Circuits and Systems Conference (BioCAS), 2017, pp. 1–5
2017
-
[43]
Directly training temporal spiking neural network with sparse surrogate gradient,
Y . Li, F. Zhao, D. Zhao, and Y . Zeng, “Directly training temporal spiking neural network with sparse surrogate gradient,” 2024. [Online]. Available: https://arxiv.org/abs/2406.19645
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.