Recognition: unknown
Measuring Temporal Linguistic Emergence in Diffusion Language Models
Pith reviewed 2026-05-08 08:12 UTC · model grok-4.3
The pith
Denoising trajectories reveal that coarse linguistic labels become recoverable before exact token identities in diffusion language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
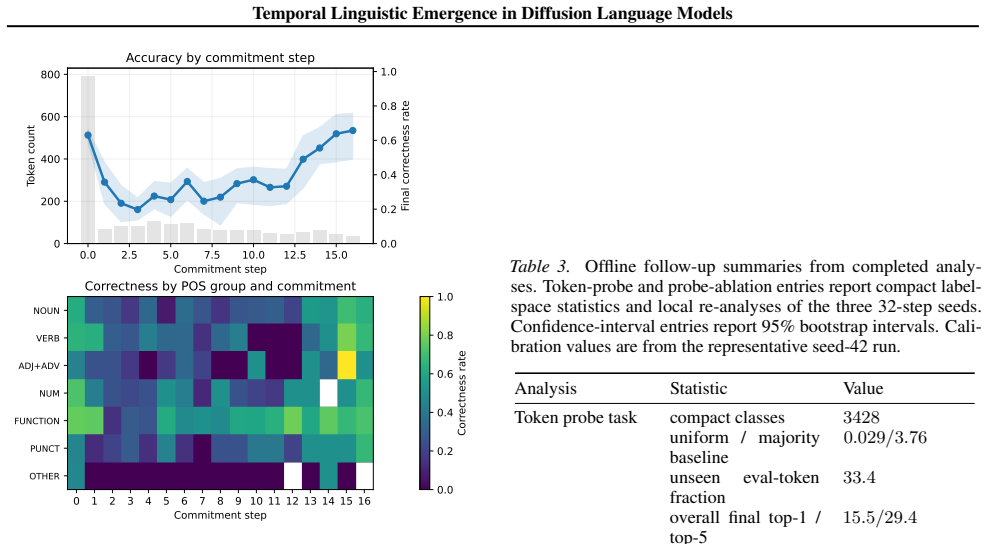
In three independent 32-step denoising runs of LLaDA-8B-Base on masked WikiText-103 sequences, the same ordering recurs across seeds: content categories stabilize earlier than function-heavy categories, POS and coarse semantic labels remain substantially more linearly recoverable than exact lexical identity, uncertainty remains higher for tokens that ultimately resolve incorrectly even though late confidence becomes less calibrated, and perturbation sensitivity peaks in the middle of the trajectory with the effect overwhelmingly local to the perturbed positions.
What carries the argument
Four temporal measurements extracted from saved denoising trajectories: token commitment, linear recoverability of POS/coarse semantic category/token identity via probes, confidence and entropy dynamics, and sensitivity to mid-trajectory re-masking.
If this is right
- Coarse labels are recovered earlier and more robustly than lexical identity.
- Trajectory-level uncertainty tracks eventual correctness.
- Mid-trajectory states are the most intervention-sensitive.
- The sensitivity peak is overwhelmingly local to the perturbed positions themselves.
Where Pith is reading between the lines
- Early uncertainty signals could support corrective interventions before the final output is produced.
- The same measurement approach might expose emergence timing in other iterative generation processes.
- Stage-specific control mechanisms could be designed once the points of highest changeability are known.
- The local character of interventions implies limited propagation of changes to neighboring tokens.
Load-bearing premise
Linear probes trained on the saved trajectories accurately capture the linguistic information present in the model's internal states, and the observed patterns are not artifacts of the specific 32-step schedule or the WikiText-103 subset.
What would settle it
Retraining the same probes on trajectories from a different diffusion model or a longer denoising schedule and finding that exact token identity becomes linearly recoverable at the same early stage as coarse semantic categories, or that mid-trajectory re-masking no longer produces the highest sensitivity.
Figures

read the original abstract
Diffusion language models expose an explicit denoising trajectory, making it possible to ask when different kinds of information become measurable during generation. We study three independent 32-step runs of LLaDA-8B-Base on masked WikiText-103 text, each with 1{,}000 probe-training sequences and 200 held-out evaluation sequences. From saved trajectories, we derive four temporal measurements: token commitment; linear recoverability of part-of-speech (POS), coarse semantic category, and token identity; confidence and entropy dynamics; and sensitivity under mid-trajectory re-masking. Across seeds, the same ordering recurs: content categories stabilize earlier than function-heavy categories, POS and coarse semantic labels remain substantially more linearly recoverable than exact lexical identity under our probe setup, uncertainty remains higher for tokens that ultimately resolve incorrectly even though late confidence becomes less calibrated, and perturbation sensitivity peaks in the middle of the trajectory. A direct/collateral decomposition shows that this peak is overwhelmingly local to the perturbed positions themselves. In this LLaDA+WikiText setting, denoising time is therefore a useful analysis axis: under our measurements, coarse labels are recovered earlier and more robustly than lexical identity, trajectory-level uncertainty tracks eventual correctness, and mid-trajectory states are the most intervention-sensitive.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper empirically examines when different types of linguistic information become measurable during the denoising process in diffusion language models. Using three independent 32-step trajectories of LLaDA-8B-Base on masked WikiText-103 (1,000 probe-training sequences and 200 held-out evaluation sequences per run), the authors compute token commitment, linear probe recoverability for POS tags, coarse semantic categories, and exact token identity; track confidence and entropy dynamics; and measure sensitivity to mid-trajectory re-masking interventions. They report that the same ordering of emergence recurs across seeds: content categories stabilize earlier than function-heavy ones, coarse labels are more recoverable than lexical identity, trajectory uncertainty correlates with final correctness, and perturbation sensitivity peaks mid-trajectory and is predominantly local (via direct/collateral decomposition).
Significance. If the reported patterns are robust, the work establishes denoising timestep as a productive analysis axis for diffusion LMs, revealing staged emergence of linguistic structure that could aid interpretability, error diagnosis, and targeted interventions. Credit is due for the multi-seed design, held-out evaluation, and explicit decomposition of intervention effects, which strengthen the empirical grounding. The contribution is primarily methodological and observational rather than theoretical, but it opens a clear direction for future work on temporal dynamics in non-autoregressive generation.
major comments (2)
- [§4] §4 (Linear probing setup): The central claim that coarse labels are 'substantially more linearly recoverable' than token identity depends on the probe results, yet the manuscript provides no details on probe regularization, optimization hyperparameters, per-timestep vs. pooled training, or control baselines (e.g., majority-class or random-feature probes). Without these, it is impossible to rule out that the observed gap is an artifact of probe capacity rather than information availability in the hidden states.
- [§5.3] §5.3 (Sensitivity analysis): The claim that mid-trajectory states are 'the most intervention-sensitive' and that the effect is 'overwhelmingly local' rests on the direct/collateral decomposition, but the text does not specify the exact perturbation magnitude, number of re-masking positions, or statistical test used to establish locality. This is load-bearing for the intervention-sensitivity conclusion.
minor comments (2)
- The abstract and results would benefit from at least one table or figure reporting concrete accuracy/entropy values, standard deviations across seeds, and p-values for the reported orderings.
- Notation for 'token commitment' and 'trajectory-level uncertainty' should be defined explicitly with equations in the methods section for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the careful reading, positive overall assessment, and constructive suggestions. We address the two major comments point by point below. Both points identify missing methodological details that we will supply in the revised manuscript.
read point-by-point responses
-
Referee: [§4] §4 (Linear probing setup): The central claim that coarse labels are 'substantially more linearly recoverable' than token identity depends on the probe results, yet the manuscript provides no details on probe regularization, optimization hyperparameters, per-timestep vs. pooled training, or control baselines (e.g., majority-class or random-feature probes). Without these, it is impossible to rule out that the observed gap is an artifact of probe capacity rather than information availability in the hidden states.
Authors: We agree that the linear-probing methodology requires fuller specification to support the recoverability claims. The probes were implemented as timestep-specific L2-regularized logistic regression models (C=1.0) trained independently on the 1,000 probe-training sequences using scikit-learn defaults; no cross-timestep pooling was performed. In the revision we will expand §4 with these hyperparameters, the exact training procedure, and results from majority-class and random-feature control probes. These controls will be reported alongside the main figures to confirm that the coarse-versus-lexical gap is not an artifact of probe capacity. revision: yes
-
Referee: [§5.3] §5.3 (Sensitivity analysis): The claim that mid-trajectory states are 'the most intervention-sensitive' and that the effect is 'overwhelmingly local' rests on the direct/collateral decomposition, but the text does not specify the exact perturbation magnitude, number of re-masking positions, or statistical test used to establish locality. This is load-bearing for the intervention-sensitivity conclusion.
Authors: We concur that the intervention protocol and statistical analysis must be stated explicitly. Re-masking was performed at 10 % of token positions chosen uniformly at random within each of the 200 held-out sequences; the direct/collateral decomposition compared the change in final-token identity at perturbed versus unperturbed sites. Locality was assessed with paired t-tests across sequences (p < 0.001). We will insert these parameters, the exact number of re-masked positions per sequence, and the statistical procedure into §5.3 of the revised manuscript. revision: yes
Circularity Check
No significant circularity in empirical measurements
full rationale
The paper reports purely empirical observations from linear probes trained on saved denoising trajectories of LLaDA-8B-Base on WikiText-103. The four temporal measurements (token commitment, linear recoverability of POS/semantic/token identity, confidence/entropy dynamics, and perturbation sensitivity) are computed directly from model states and probe outputs across independent runs. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the derivation of the central claims about ordering of emergence or mid-trajectory sensitivity. The analysis remains self-contained against external benchmarks via direct experimental measurement, with no reduction of results to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2410.17891. He, Z., Sun, T., Wang, K., Huang, X., and Qiu, X. Diffusion- BERT: Improving generative masked language models with diffusion models.arXiv preprint arXiv:2211.15029,
-
[2]
Hemmat, A., Torr, P., Chen, Y ., and Yu, J
URLhttps://arxiv.org/abs/2211.15029. Hemmat, A., Torr, P., Chen, Y ., and Yu, J. TDGNet: Hallu- cination detection in diffusion language models via tem- poral dynamic graphs.arXiv preprint arXiv:2602.08048,
-
[3]
URLhttps://arxiv.org/abs/2602.08048. Hewitt, J. and Manning, C. D. A structural probe for find- ing syntax in word representations. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 4129–4138, 2019. URL https://aclanthology.org/N19-1419/. Karami, M. and Gho...
-
[4]
URLhttps://arxiv.org/abs/2308.12219. Zhang, Y ., He, S., Levine, D., Zhao, L., Zhang, D., Rizvi, S. A., Zhang, S., Zappala, E., Ying, R., and van Dijk, D. Non-markovian discrete diffusion with causal language models.arXiv preprint arXiv:2502.09767, 2025. URL https://arxiv.org/abs/2502.09767. 6 Temporal Linguistic Emergence in Diffusion Language Models Tab...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.