Recognition: unknown
Modular Sensory Stream for Integrating Physical Feedback in Vision-Language-Action Models
Pith reviewed 2026-05-08 08:08 UTC · model grok-4.3
The pith
A modular framework lets vision-language-action models incorporate multiple physical signals like touch and torque to improve robot action prediction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
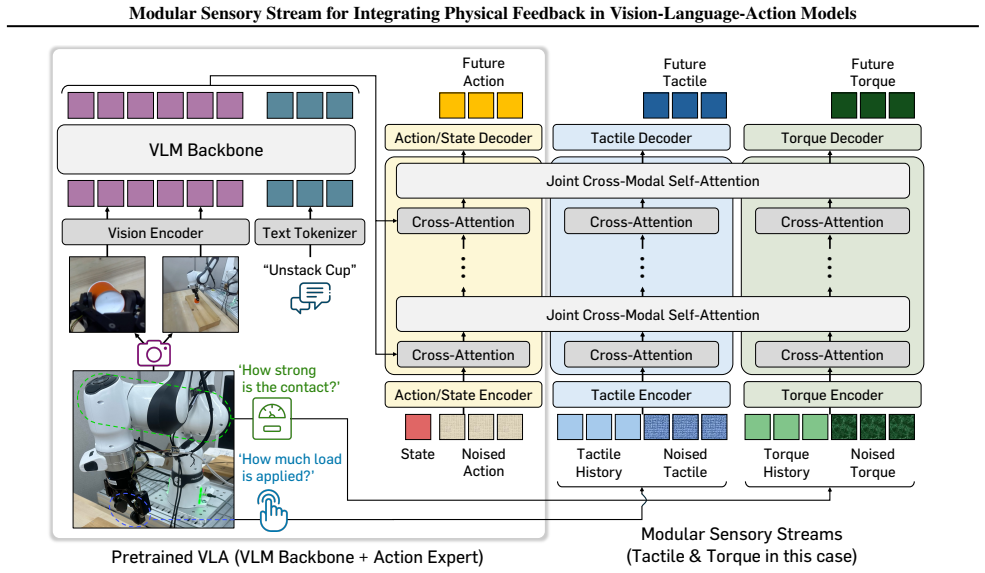
MoSS is a modular sensory stream framework that adapts pretrained Vision-Language-Action models to leverage multiple heterogeneous physical signals such as tactile and torque feedback for action prediction. It uses decoupled modality streams integrated via joint cross-modal self-attention, adopts a two-stage training scheme that freezes pretrained VLA parameters initially to allow stable addition of new signals, and adds an auxiliary task predicting future physical signals to capture contact interaction dynamics. Extensive real-world experiments demonstrate that this approach successfully augments VLAs to integrate diverse signals and achieve synergistic performance gains.
What carries the argument
Decoupled modality streams integrated via joint cross-modal self-attention, which connects new physical signals to the action prediction stream while the two-stage training and auxiliary prediction task stabilize the addition of modalities.
Load-bearing premise
Heterogeneous physical signals are complementary and can be stably added to pretrained vision-language-action models without causing interference or performance drops.
What would settle it
A set of identical real-world robot manipulation trials run once with only single physical signals, once without the auxiliary prediction task, and once with full MoSS, where the combined version fails to show higher task success rates or efficiency than the single-signal baselines.
Figures







read the original abstract
Humans understand and interact with the real world by relying on diverse physical feedback beyond visual perception. Motivated by this, recent approaches attempt to incorporate physical sensory signals into Vision-Language-Action models (VLAs). However, they typically focus on a single type of physical signal, failing to capture the heterogeneous and complementary nature of real-world interactions. In this paper, we propose MoSS, a modular sensory stream framework that adapts VLAs to leverage multiple sensory signals for action prediction. Specifically, we introduce decoupled modality streams that integrate heterogeneous physical signals into the action stream via joint cross-modal self-attention. To enable stable incorporation of new modalities, we adopt a two-stage training scheme that freezes pretrained VLA parameters in the early stage. Furthermore, to better capture contact interaction dynamics, we incorporate an auxiliary task that predicts future physical signals. Through extensive real-world experiments, we demonstrate that MoSS successfully augments VLAs to leverage diverse physical signals (i.e., tactile and torque), integrating multiple signals to achieve synergistic performance gains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MoSS, a modular sensory stream framework for adapting pretrained Vision-Language-Action (VLA) models to incorporate heterogeneous physical signals such as tactile and torque feedback. It introduces decoupled modality streams integrated via joint cross-modal self-attention, a two-stage training scheme that freezes pretrained VLA parameters initially, and an auxiliary task predicting future physical signals to capture contact dynamics. The central claim is that this enables stable multi-signal integration and yields synergistic performance gains over single-signal or vision-only baselines, as shown in extensive real-world robot experiments.
Significance. If validated by detailed quantitative results, the work would be significant for embodied robotics and multi-modal learning, as it provides a practical modular approach to extending VLAs beyond vision to diverse physical feedback. This could improve robustness in contact-rich tasks where single modalities are insufficient, addressing a clear gap in current VLA literature.
major comments (2)
- Abstract: The claim that MoSS 'integrating multiple signals to achieve synergistic performance gains' is presented without any quantitative metrics, success rates, baselines, error bars, or task-specific results. This is load-bearing for the central contribution, as the soundness of the synergistic-gains assertion cannot be assessed from the provided description alone.
- The weakest assumption (heterogeneous signals are complementary and integrable without degradation via two-stage training plus auxiliary prediction) is stated but not supported by ablations or comparisons in the abstract; if the full results section lacks controls showing no performance drop when adding modalities, the stability claim remains unverified.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We agree that the abstract would benefit from greater specificity regarding quantitative results and have revised it accordingly. Below we respond point-by-point to the major comments.
read point-by-point responses
-
Referee: Abstract: The claim that MoSS 'integrating multiple signals to achieve synergistic performance gains' is presented without any quantitative metrics, success rates, baselines, error bars, or task-specific results. This is load-bearing for the central contribution, as the soundness of the synergistic-gains assertion cannot be assessed from the provided description alone.
Authors: We agree that the original abstract lacked specific quantitative support for the synergistic-gains claim. In the revised manuscript we have updated the abstract to include key metrics from our real-world experiments, such as average success rates across contact-rich tasks (with standard deviations from multiple trials), direct comparisons to vision-only and single-signal baselines, and the magnitude of improvement when combining tactile and torque signals. These additions make the central claim verifiable from the abstract while preserving its length and readability. revision: yes
-
Referee: The weakest assumption (heterogeneous signals are complementary and integrable without degradation via two-stage training plus auxiliary prediction) is stated but not supported by ablations or comparisons in the abstract; if the full results section lacks controls showing no performance drop when adding modalities, the stability claim remains unverified.
Authors: The full results section already contains the requested controls: we report ablations comparing single-modality, dual-modality, and vision-only configurations, showing that the two-stage training plus auxiliary future-signal prediction yields synergistic gains without any performance drop upon adding modalities. These experiments are quantified with success rates, failure-mode analysis, and statistical significance across multiple real-world tasks. To address the abstract-specific concern we have added a concise clause referencing the stability of integration. We therefore do not believe the stability claim is unverified in the manuscript, but the revision improves immediate accessibility. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper defines MoSS as a new modular architecture with decoupled modality streams, joint cross-modal self-attention, a two-stage training scheme that freezes pretrained VLA weights, and an auxiliary future-signal prediction task. These elements are introduced as design choices motivated by the problem of heterogeneous signal integration and are validated through independent real-world robot experiments on external tasks. No equation or claim reduces by construction to a fitted parameter, self-citation chain, or renamed input; the derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pretrained VLA parameters remain effective when frozen during initial integration of new sensory modalities.
Forward citations
Cited by 2 Pith papers
-
RLDX-1 Technical Report
RLDX-1 achieves 86.8% success on complex ALLEX humanoid manipulation tasks where prior VLAs reach only around 40%.
-
RLDX-1 Technical Report
RLDX-1 outperforms frontier VLAs such as π0.5 and GR00T N1.6 on dexterous manipulation benchmarks, reaching 86.8% success on ALLEX humanoid tasks versus around 40% for the baselines.
Reference graph
Works this paper leans on
-
[1]
Feel the force: Contact-driven learning from humans
Adeniji, A., Chen, Z., Liu, V ., Pattabiraman, V ., Bhirangi, R., Haldar, S., Abbeel, P., and Pinto, L. Feel the force: Contact-driven learning from humans.arXiv preprint arXiv:2506.01944,
-
[2]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923,
work page internal anchor Pith review arXiv
-
[3]
PaliGemma: A versatile 3B VLM for transfer
Beyer, L., Steiner, A., Pinto, A. S., Kolesnikov, A., Wang, X., Salz, D., Neumann, M., Alabdulmohsin, I., Tschan- nen, M., Bugliarello, E., et al. Paligemma: A versatile 3b vlm for transfer.arXiv preprint arXiv:2407.07726,
work page internal anchor Pith review arXiv
-
[4]
Bi, J., Ma, K. Y ., Hao, C., Shou, M. Z., and Soh, H. Vla-touch: Enhancing vision-language-action mod- els with dual-level tactile feedback.arXiv preprint arXiv:2507.17294,
-
[5]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Bjorck, J., Blukis, V ., Casta ˜neda, F., Cherniadev, N., Da, X., Ding, R., Fan, L., Fang, Y ., Fox, D., Hu, F., Huang, S., et al. Gr00t n1.5: An im- proved open foundation model for generalist hu- manoid robots. https://research.nvidia. com/labs/gear/gr00t-n1_5/, June 2025a. Ac- cessed: 2025-09-09. Bjorck, J., Casta˜neda, F., Cherniadev, N., Da, X., Ding...
work page internal anchor Pith review arXiv 2025
-
[6]
Thinkact: Vision- language-action reasoning via reinforced visual latent planning, 2025
Huang, C.-P., Wu, Y .-H., Chen, M.-H., Wang, Y .-C. F., and Yang, F.-E. Thinkact: Vision-language-action reason- ing via reinforced visual latent planning.arXiv preprint arXiv:2507.16815, 2025a. Huang, J., Wang, S., Lin, F., Hu, Y ., Wen, C., and Gao, Y . Tactile-vla: unlocking vision-language-action model’s physical knowledge for tactile generalization.A...
-
[7]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Khazatsky, A., Pertsch, K., Nair, S., Balakrishna, A., Dasari, S., Karamcheti, S., Nasiriany, S., Srirama, M. K., Chen, L. Y ., Ellis, K., et al. Droid: A large-scale in-the-wild robot manipulation dataset.arXiv preprint arXiv:2403.12945,
work page internal anchor Pith review arXiv
-
[8]
arXiv preprint arXiv:2411.04996 , year =
Liang, W., Yu, L., Luo, L., Iyer, S., Dong, N., Zhou, C., Ghosh, G., Lewis, M., Yih, W.-t., Zettlemoyer, L., et al. Mixture-of-transformers: A sparse and scalable architec- ture for multi-modal foundation models.arXiv preprint arXiv:2411.04996,
-
[9]
Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps
Lu, J., Clark, C., Zellers, R., Mottaghi, R., and Kembhavi, A. Unified-io: A unified model for vision, language, and multi-modal tasks.arXiv preprint arXiv:2206.08916,
-
[10]
Vtla: Vision- tactile-language-action model with preference learning for insertion manipulation,
Zhang, C., Hao, P., Cao, X., Hao, X., Cui, S., and Wang, S. Vtla: Vision-tactile-language-action model with prefer- ence learning for insertion manipulation.arXiv preprint arXiv:2505.09577, 2025a. Zhang, Z., Xu, H., Yang, Z., Yue, C., Lin, Z., Gao, H.-a., Wang, Z., and Zhao, H. Ta-vla: Elucidating the design space of torque-aware vision-language-action mo...
-
[11]
X-VLA: Soft-Prompted Transformer as Scalable Cross-Embodiment Vision-Language-Action Model
Zheng, J., Li, J., Wang, Z., Liu, D., Kang, X., Feng, Y ., Zheng, Y ., Zou, J., Chen, Y ., Zeng, J., et al. X-vla: Soft-prompted transformer as scalable cross- embodiment vision-language-action model.arXiv preprint arXiv:2510.10274,
work page internal anchor Pith review arXiv
-
[12]
Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
Zhou, C., Yu, L., Babu, A., Tirumala, K., Yasunaga, M., Shamis, L., Kahn, J., Ma, X., Zettlemoyer, L., and Levy, O. Transfusion: Predict the next token and dif- fuse images with one multi-modal model.arXiv preprint arXiv:2408.11039,
work page internal anchor Pith review arXiv
-
[13]
tactile sensor on the gripper, and for the torque modality, we use the joint torque measurements provided by the robot. Avg. denotes averaged success rates over entire tasks.Boldindicates best results. Unstack Cup Board Erase Plug Insertion Method Tactile Torque Small BigPnP EggLow Middle High Yellow White BlackAvg. GR00T N1.5 (Bjorck et al., 2025a)✗ ✗0.0...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.