Recognition: unknown
KAConvNet: Kolmogorov-Arnold Convolutional Networks for Vision Recognition
Pith reviewed 2026-05-08 08:28 UTC · model grok-4.3
The pith
A new Kolmogorov-Arnold Convolutional Layer integrates the representation theorem with convolution to produce KAConvNet, which outperforms prior KAN-convolution methods and matches mainstream CNNs and ViTs on vision tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the proposed Kolmogorov-Arnold Convolutional Layer deeply integrates the Kolmogorov-Arnold representation theorem with convolution, supplying stronger interpretability through its grounding in established mathematical theorems and theoretical alignment. From this layer the authors construct KAConvNet, which outperforms existing combinations of KAN and convolution while delivering competitive results against mainstream ViTs and CNNs on vision recognition tasks.
What carries the argument
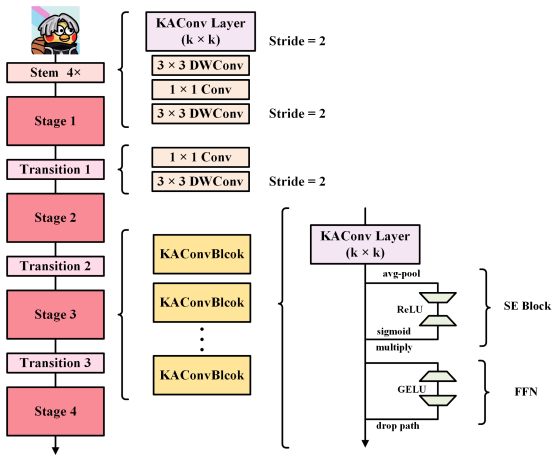
The Kolmogorov-Arnold Convolutional Layer, which embeds learnable nonlinear univariate functions on edges according to the Kolmogorov-Arnold theorem inside the convolutional summation structure.
If this is right
- KAConvNet can replace standard convolutional backbones in vision pipelines while preserving or improving accuracy.
- The layer design removes reliance on B-spline curves, thereby reducing computational cost and overfitting risk compared with earlier KAN variants.
- Networks built this way inherit theoretical guarantees from the Kolmogorov-Arnold theorem that standard CNNs lack.
- The architecture offers a concrete alternative to both pure CNNs and vision transformers on common recognition benchmarks.
Where Pith is reading between the lines
- If the layer generalizes, the same theorem-driven substitution could be applied to attention or pooling operations to create hybrid architectures with uniform mathematical grounding.
- Researchers could measure how much of the reported accuracy gain comes from the new activation functions versus the overall network depth or training recipe.
- The emphasis on interpretability suggests that feature visualizations or sensitivity maps derived from the univariate functions might reveal clearer semantic meanings than those from ordinary CNN filters.
Load-bearing premise
The premise that embedding the Kolmogorov-Arnold theorem directly into convolutional layers produces both performance gains and better interpretability without losing the spatial feature extraction power of ordinary convolution.
What would settle it
An experiment that trains KAConvNet on a standard benchmark such as ImageNet or CIFAR-10 and records accuracy or efficiency that falls below matched CNN and ViT baselines while also showing higher training time or memory use than claimed.
Figures




read the original abstract
The Convolutional Neural Networks (CNNs) have been the dominant and effective approach for general computer vision tasks. Recently, Kolmogorov-Arnold neural networks (KANs), based on the Kolmogorov-Arnold representation theorem, have shown potential to replace Multi-Layer Perceptrons (MLPs) in deep learning. KANs, which use learnable nonlinear activations on edges and simple summation on nodes, offer fewer parameters and greater explainability compared to MLPs. However, there has been limited exploration of integrating the Kolmogorov-Arnold representation theorem with convolutional methods for computer vision tasks. Existing attempts have merely replaced learnable activation functions with weights, undermining KANs' theoretical foundation and limiting their potential effectiveness. Additionally, the B-spline curves used in KANs suffer from computational inefficiency and a tendency to overfit. In this paper, we propose a novel Kolmogorov-Arnold Convolutional Layer that deeply integrates the Kolmogorov-Arnold representation theorem with convolution. This layer provides stronger method interpretability because it is based on established mathematical theorems and its design has theoretical alignment. Building on the Kolmogorov-Arnold Convolutional Layer, we design an efficient network architecture called KAConvNet, which outperforms existing methods combining KAN and convolution, and achieves competitive performance compared to mainstream ViTs and CNNs. We believe that our work offers valuable insight into the field of artificial intelligence and will inspire the development of more innovative CNNs in the 2020s. The code is publicly available at https://github.com/UnicomAI/KAConvNet.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a Kolmogorov-Arnold Convolutional Layer that integrates the Kolmogorov-Arnold representation theorem with convolution operations, avoiding B-spline issues from prior KANs. It builds an efficient KAConvNet architecture on this layer, claiming stronger interpretability due to theoretical alignment, outperformance over existing KAN-convolution hybrids, and competitive results against mainstream ViTs and CNNs for vision recognition tasks. Code is released publicly.
Significance. If the theoretical integration is rigorously shown to preserve the theorem's exact representation properties and the performance gains are substantiated with ablations and baselines, this could advance interpretable alternatives to standard CNNs and ViTs by grounding vision models in established mathematics. Public code supports reproducibility, which strengthens the contribution if experiments are detailed.
major comments (2)
- [Abstract and Kolmogorov-Arnold Convolutional Layer definition] The abstract and method description assert a 'deep integration' of the Kolmogorov-Arnold representation theorem with convolution that yields 'theoretical alignment' and stronger interpretability. However, no explicit derivation is provided showing how the layer (with its convolutional weight sharing and local operations) preserves the theorem's exact univariate-sum representation without introducing approximations on patches. This is load-bearing for the central interpretability claim, as convolution's translation equivariance may conflict with the theorem's global multivariate decomposition.
- [Experiments section] The performance claims (outperforming prior KAN-conv methods and competitive with ViTs/CNNs) are stated without reference to specific tables, error bars, statistical tests, or ablation studies on the layer components. The full manuscript must demonstrate these via quantitative results to support the architecture's efficiency and effectiveness assertions.
minor comments (1)
- [Abstract] The phrasing 'will inspire the development of more innovative CNNs in the 2020s' in the abstract is temporally imprecise; consider revising for clarity or specificity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below and will revise the paper to incorporate the suggested improvements where they strengthen the presentation of our contributions.
read point-by-point responses
-
Referee: [Abstract and Kolmogorov-Arnold Convolutional Layer definition] The abstract and method description assert a 'deep integration' of the Kolmogorov-Arnold representation theorem with convolution that yields 'theoretical alignment' and stronger interpretability. However, no explicit derivation is provided showing how the layer (with its convolutional weight sharing and local operations) preserves the theorem's exact univariate-sum representation without introducing approximations on patches. This is load-bearing for the central interpretability claim, as convolution's translation equivariance may conflict with the theorem's global multivariate decomposition.
Authors: We agree that the current manuscript would benefit from an explicit derivation to rigorously support the interpretability claim. While the layer is constructed to apply univariate functions in a manner consistent with the theorem's form (with summation at nodes), we acknowledge the absence of a step-by-step proof addressing weight sharing and local patches. In the revised manuscript, we will add a dedicated subsection deriving the preservation of the exact representation properties, including an explanation of how translation equivariance is compatible with the global decomposition by viewing the convolutional application as a structured restriction that still spans the required univariate basis over the input domain. revision: yes
-
Referee: [Experiments section] The performance claims (outperforming prior KAN-conv methods and competitive with ViTs/CNNs) are stated without reference to specific tables, error bars, statistical tests, or ablation studies on the layer components. The full manuscript must demonstrate these via quantitative results to support the architecture's efficiency and effectiveness assertions.
Authors: The experiments section presents comparative results against baselines, but we concur that the claims would be more robust with additional quantitative details. In the revision, we will explicitly reference the relevant tables in the text, add error bars to reported metrics, include statistical significance tests, and expand the ablation studies to isolate the contributions of the KAConv layer components, thereby providing clearer support for the efficiency and effectiveness assertions. revision: yes
Circularity Check
No circularity: derivation relies on external theorem and novel layer construction
full rationale
The paper's central step is the definition of a Kolmogorov-Arnold Convolutional Layer that integrates the Kolmogorov-Arnold representation theorem with convolution. This is presented as a new design choice motivated by the external theorem (not derived from or equivalent to the paper's own fitted results or prior self-citations). Performance claims are empirical comparisons, not predictions forced by construction. No self-definitional loop, fitted-input-as-prediction, or load-bearing self-citation chain appears in the provided abstract or description. The approach is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Kolmogorov-Arnold representation theorem
invented entities (1)
-
Kolmogorov-Arnold Convolutional Layer
no independent evidence
Reference graph
Works this paper leans on
-
[1]
LeCun, L
Y. LeCun, L. Bottou, Y. Bengio, P. Haffner, Gradient-based learning ap- plied to document recognition, Proceedings of the IEEE 86 (11) (1998) 2278–2324
1998
-
[2]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Un- terthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, et al., An image is worth 16x16 words: Transformers for image recognition at scale, arXiv preprint arXiv:2010.11929 (2020)
work page internal anchor Pith review arXiv 2010
-
[3]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, I. Polosukhin, Attention is all you need, Advances in neural information processing systems 30 (2017)
2017
-
[4]
Z. Liu, Y. Wang, S. Vaidya, F. Ruehle, J. Halverson, M. Soljačić, T. Y. Hou, M. Tegmark, Kan: Kolmogorov-arnold networks, arXiv preprint arXiv:2404.19756 (2024)
work page internal anchor Pith review arXiv 2024
- [5]
-
[6]
Kolmogorov-arnold convolutions: Design principles and empirical studies,
I. Drokin, Kolmogorov-arnold convolutions: Design principles and empiri- cal studies, arXiv preprint arXiv:2407.01092 (2024)
-
[7]
A. N. Kolmogorov, On the representation of continuous functions of several variables by superpositions of continuous functions of a smaller number of variables, American Mathematical Society, 1961
1961
-
[8]
J.Braun, M.Griebel, Onaconstructiveproofofkolmogorov’ssuperposition theorem, Constructive approximation 30 (2009) 653–675
2009
-
[9]
R. Genet, H. Inzirillo, Tkan: Temporal kolmogorov-arnold networks, arXiv preprint arXiv:2405.07344 (2024)
-
[10]
A. Kashefi, Pointnet with kan versus pointnet with mlp for 3d classification and segmentation of point sets, arXiv preprint arXiv:2410.10084 (2024). 18
-
[11]
A. Mahara, N. D. Rishe, L. Deng, The dawn of kan in image-to-image (i2i) translation: Integrating kolmogorov-arnold networks with gans for unpaired i2i translation, Conference on Algebraic Informatics (2024). doi:10.1109/CAI64502.2025.00134
-
[12]
C. Li, X. Liu, W. Li, C. Wang, H. Liu, Y. Liu, Z. Chen, Y. Yuan, U-kan makes strong backbone for medical image segmentation and generation, in: Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 39, 2025, pp. 4652–4660
2025
-
[13]
Fourierkan,https://github.com/GistNoesis/FourierKAN(2024)
2024
-
[14]
Wav-kan: Wavelet kolmogorov-arnold networks,
Z. Bozorgasl, H. Chen, Wav-kan: Wavelet kolmogorov-arnold networks, arXiv preprint arXiv:2405.12832 (2024)
-
[15]
Gkan: Graph kolmogorov-arnold networks,
M. Kiamari, M. Kiamari, B. Krishnamachari, Gkan: Graph kolmogorov- arnold networks, arXiv preprint arXiv:2406.06470 (2024)
-
[16]
Torchkan: Simplified kan model with variations.,https://github.com/ 1ssb/torchkan(2024)
2024
-
[17]
Jacobikan,https://github.com/SpaceLearner/JacobiKAN(2024)
2024
-
[18]
Very fast kolmogorov-arnold network via radial basis functions,https: //github.com/ZiyaoLi/fast-kan(2024)
2024
-
[19]
An efficient implementation of kolmogorov-arnold network,https:// github.com/Blealtan/efficient-kan(2024)
2024
-
[20]
Krizhevsky, I
A. Krizhevsky, I. Sutskever, G. E. Hinton, Imagenet classification with deep convolutional neural networks, Advances in neural information processing systems 25 (2012)
2012
-
[21]
Very Deep Convolutional Networks for Large-Scale Image Recognition
K. Simonyan, A. Zisserman, Very deep convolutional networks for large- scale image recognition, arXiv preprint arXiv:1409.1556 (2014)
work page internal anchor Pith review arXiv 2014
-
[22]
K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recog- nition, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778
2016
- [23]
-
[24]
A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, H. Adam, Mobilenets: Efficient convolutional neural net- works for mobile vision applications, arXiv preprint arXiv:1704.04861 (2017)
work page internal anchor Pith review arXiv 2017
-
[25]
Chollet, Xception: Deep learning with depthwise separable convolutions, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp
F. Chollet, Xception: Deep learning with depthwise separable convolutions, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 1251–1258. 19
2017
-
[26]
J. Dai, H. Qi, Y. Xiong, Y. Li, G. Zhang, H. Hu, Y. Wei, Deformable con- volutional networks, in: Proceedings of the IEEE international conference on computer vision, 2017, pp. 764–773
2017
-
[27]
Z. Liu, H. Mao, C.-Y. Wu, C. Feichtenhofer, T. Darrell, S. Xie, A convnet for the 2020s, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 11976–11986
2022
-
[28]
X. Ding, X. Zhang, N. Ma, J. Han, G. Ding, J. Sun, Repvgg: Making vgg- style convnets great again, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 13733–13742
2021
-
[29]
X. Ding, X. Zhang, J. Han, G. Ding, Scaling up your kernels to 31x31: Revisiting large kernel design in cnns, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 11963– 11975
2022
- [30]
-
[31]
X. Ding, Y. Zhang, Y. Ge, S. Zhao, L. Song, X. Yue, Y. Shan, Unire- plknet: A universal perception large-kernel convnet for audio video point cloud time-series and image recognition, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 5513– 5524
2024
-
[32]
H. Chen, X. Chu, Y. Ren, X. Zhao, K. Huang, Pelk: Parameter-efficient large kernel convnets with peripheral convolution, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 5557–5567
2024
-
[33]
J. Hu, L. Shen, G. Sun, Squeeze-and-excitation networks, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 7132–7141
2018
-
[34]
T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dol- lár, C. L. Zitnick, Microsoft coco: Common objects in context, in: Com- puter Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13, Springer, 2014, pp. 740–755
2014
-
[35]
Cordts, M
M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth, B. Schiele, The cityscapes dataset for semantic urban scene understanding, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 3213–3223
2016
-
[36]
D. Li, J. Hu, C. Wang, X. Li, Q. She, L. Zhu, T. Zhang, Q. Chen, In- volution: Inverting the inherence of convolution for visual recognition, in: 20 Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 12321–12330
2021
-
[37]
P. K. A. Vasu, J. Gabriel, J. Zhu, O. Tuzel, A. Ranjan, Mobileone: An im- proved one millisecond mobile backbone, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 7907– 7917
2023
-
[38]
Y. Li, G. Yuan, Y. Wen, J. Hu, G. Evangelidis, S. Tulyakov, Y. Wang, J. Ren, Efficientformer: Vision transformers at mobilenet speed, Advances in Neural Information Processing Systems 35 (2022) 12934–12949
2022
-
[39]
Hatamizadeh, H
A. Hatamizadeh, H. Yin, G. Heinrich, J. Kautz, P. Molchanov, Global con- text vision transformers, in: International Conference on Machine Learn- ing, PMLR, 2023, pp. 12633–12646
2023
-
[40]
Y. Liu, Y. Tian, Y. Zhao, H. Yu, L. Xie, Y. Wang, Q. Ye, J. Jiao, Y. Liu, Vmamba: Visual state space model, Advances in neural information pro- cessing systems 37 (2024) 103031–103063
2024
-
[41]
Hatamizadeh, J
A. Hatamizadeh, J. Kautz, Mambavision: A hybrid mamba-transformer vi- sion backbone, in: Proceedings of the Computer Vision and Pattern Recog- nition Conference, 2025, pp. 25261–25270
2025
-
[42]
K. Han, Y. Wang, Q. Tian, J. Guo, C. Xu, C. Xu, Ghostnet: More features from cheap operations, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 1580–1589
2020
-
[43]
H.Touvron, M.Cord, A.Sablayrolles, G.Synnaeve, H.Jégou, Goingdeeper with image transformers, in: Proceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 32–42
2021
-
[44]
L. Zhu, B. Liao, Q. Zhang, X. Wang, W. Liu, X. Wang, Vision mamba: Efficientvisualrepresentationlearningwithbidirectionalstatespacemodel, arXiv preprint arXiv:2401.09417 (2024)
work page internal anchor Pith review arXiv 2024
-
[45]
N. Ma, X. Zhang, H.-T. Zheng, J. Sun, Shufflenet v2: Practical guide- lines for efficient cnn architecture design, in: Proceedings of the European conference on computer vision (ECCV), 2018, pp. 116–131
2018
-
[46]
Chiley, V
V. Chiley, V. Thangarasa, A. Gupta, A. Samar, J. Hestness, D. DeCoste, Revbifpn: the fully reversible bidirectional feature pyramid network, Pro- ceedings of Machine Learning and Systems 5 (2023) 625–645
2023
- [47]
-
[48]
Decoupled Weight Decay Regularization
I. Loshchilov, F. Hutter, Decoupled weight decay regularization, arXiv preprint arXiv:1711.05101 (2017). 21
work page internal anchor Pith review arXiv 2017
-
[49]
H. Zhao, J. Shi, X. Qi, X. Wang, J. Jia, Pyramid scene parsing network, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 2881–2890
2017
- [50]
-
[51]
K. Chen, J. Wang, J. Pang, Y. Cao, Y. Xiong, X. Li, S. Sun, W. Feng, Z. Liu, J. Xu, Z. Zhang, D. Cheng, C. Zhu, T. Cheng, Q. Zhao, B. Li, X. Lu, R. Zhu, Y. Wu, J. Dai, J. Wang, J. Shi, W. Ouyang, C. C. Loy, D. Lin, MMDetection: Open mmlab detection toolbox and benchmark, arXiv preprint arXiv:1906.07155 (2019)
-
[52]
M. Tan, Q. Le, Efficientnet: Rethinking model scaling for convolutional neural networks, in: International conference on machine learning, PMLR, 2019, pp. 6105–6114
2019
- [53]
-
[54]
J. Fein-Ashley, E. Feng, M. Pham, Hvt: A comprehensive vision frame- work for learning in non-euclidean space, arXiv preprint arXiv:2409.16897 (2024)
-
[55]
S. Mehta, M. Rastegari, Mobilevit: light-weight, general-purpose, and mobile-friendly vision transformer, arXiv preprint arXiv:2110.02178 (2021)
-
[56]
W. Wang, E. Xie, X. Li, D.-P. Fan, K. Song, D. Liang, T. Lu, P. Luo, L. Shao, Pyramid vision transformer: A versatile backbone for dense pre- diction without convolutions, in: Proceedings of the IEEE/CVF interna- tional conference on computer vision, 2021, pp. 568–578
2021
-
[57]
Zhang, X
P. Zhang, X. Dai, J. Yang, B. Xiao, L. Yuan, L. Zhang, J. Gao, Multi- scale vision longformer: A new vision transformer for high-resolution image encoding, in: Proceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 2998–3008
2021
-
[58]
Howard, M
A. Howard, M. Sandler, G. Chu, L.-C. Chen, B. Chen, M. Tan, W. Wang, Y. Zhu, R. Pang, V. Vasudevan, et al., Searching for mobilenetv3, in: Pro- ceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 1314–1324. 22 Appendix A. Visualization Results in Semantic Segmentation Fig. A.6. Visual comparison of semantic segmentation perform...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.